1. Surveillance des services
Avant de commencer à optimiser les performances du service SpringBoot, nous devons faire quelques préparatifs pour exposer certaines données du service SpringBoot.
Par exemple, si votre service utilise un cache, vous devez collecter des données telles que le taux de réussite du cache ; si vous utilisez un pool de connexions à la base de données, vous devez exposer les paramètres du pool de connexions.
L'outil de surveillance que nous utilisons ici est Prometheus, qui est une base de données de séries chronologiques qui peut stocker nos métriques. SpringBoot peut être facilement connecté à Prometheus.
Après avoir créé un projet SpringBoot, commencez par ajouter des dépendances maven.
org.springframework.boot spring-boot-starter-actuator io.micrometer micrometer-registry-prometheus io.micrometer micrometer-core Ensuite, nous devons ouvrir l'interface de surveillance appropriée dans le fichier de configuration application.properties.management.endpoint.metrics.enabled=true
management.endpoints.web.exposure.include=*
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
Après le démarrage, nous pouvons accéder à http: // localhost:8080/actuator/prometheus pour obtenir les données de surveillance.

Il est également relativement simple de surveiller les données d'entreprise. Vous devez injecter une instance MeterRegistry. Voici un exemple de code :
Registre @Autowired
MeterRegistry ;
@GetMapping("/test")
@ResponseBody
public String test() { register.counter(“test”, “from”, “127.0.0.1”, “method”, “test” ).increment();
return "ok";
}
À partir de la connexion de surveillance, nous pouvons trouver les informations de surveillance qui viennent d'être ajoutées.
test_total{from="127.0.0.1",method="test",} 5.0
Voici une brève introduction au populaire système de surveillance Prometheus. Prometheus utilise la méthode pull pour obtenir des données de surveillance. Ce processus d'exposition des données peut être confié à Telegraf avec des fonctions plus complètes.

Comme le montre la figure, nous utilisons généralement Grafana pour afficher les données de surveillance et utilisons le composant AlertManager pour l'alerte précoce. La construction de cette partie n'est pas notre objectif, et les étudiants qui sont intéressés peuvent l'étudier par eux-mêmes. L'image suivante est une image de surveillance typique, vous pouvez voir le taux de réussite du cache de Redis, etc.

2. Java génère un graphique de flamme
Un graphique de flamme est un outil utilisé pour analyser les goulots d'étranglement dans l'exécution du programme. Dans le sens vertical, il indique la profondeur de la pile d'appels ; dans le sens horizontal, il indique le temps écoulé. Ainsi, plus la largeur de la grille est grande, plus il est probable qu'il s'agisse d'un goulot d'étranglement.
Les graphiques de flamme peuvent également être utilisés pour analyser les applications Java. Vous pouvez télécharger le package compressé de async-profiler depuis github pour les opérations associées.
Par exemple, extrayons-le dans le répertoire /root/. Démarrez ensuite l'application Java à la manière de javaagent. La ligne de commande est la suivante :
java -agentpath:/root/build/libasyncProfiler.so=start,svg,file=profile.svg -jar spring-petclinic-2.3.1.BUILD-SNAPSHOT.jar
Après avoir exécuté pendant un certain temps, arrêtez le processus, vous peut voir que le courant Dans le répertoire, le fichier profile.svg est généré. Ce fichier peut être ouvert avec un navigateur, et vous pouvez parcourir couche par couche pour trouver la cible qui doit être optimisée.
3. Skywalking
Pour un service Web, la partie la plus lente concerne les opérations de base de données. Par conséquent, l'utilisation du cache local et de l'optimisation du cache distribué peut obtenir la plus grande amélioration des performances.
Pour le problème de comment se localiser dans un environnement distribué complexe, je voudrais partager un autre outil : Skywalking.
Skywalking est implémenté à l'aide de la technologie de sonde (JavaAgent). En ajoutant le package Jar de javaagent aux paramètres de démarrage Java, les données de performances et les données de la chaîne d'appels peuvent être encapsulées et envoyées au serveur Skywalking.
Téléchargez le package d'installation correspondant (si vous utilisez le stockage ES, vous devez télécharger un package d'installation dédié), après avoir configuré le stockage, vous pouvez le démarrer en un clic.
Extrayez le package compressé de l'agent dans le répertoire correspondant.
tar xvf skywalking-agent.tar.gz -C /opt/
Ajoutez le package de l'agent aux paramètres de démarrage du service. Par exemple, la commande de démarrage d'origine est :
java -jar /opt/test-service/spring-boot-demo.jar --spring.profiles.active=dev
La commande de démarrage modifiée est :
java -javaagent:/opt/skywalking-agent/skywalking-agent.jar -Dskywalking.agent.service_name=the-demo-name -jar /opt/test-service/spring-boot-demo.ja --spring.profiles. active=dev
pour accéder aux liens de certains services, ouvrez l'interface utilisateur de Skywalking et vous pouvez voir l'interface comme indiqué ci-dessous. Nous pouvons trouver l'interface avec une réponse relativement lente et un QPS élevé à partir de la figure, et effectuer une optimisation spéciale.

4. Idées d'optimisation
Pour un service Web ordinaire, examinons les principaux liens qui doivent être expérimentés pour accéder à des données spécifiques.
Comme indiqué dans la figure ci-dessous, entrez le nom de domaine correspondant dans le navigateur, qui doit être résolu en adresse IP spécifique via DNS. Afin d'assurer une haute disponibilité, nos services déploient généralement plusieurs copies, puis utilisent Nginx pour le proxy inverse et l'équilibrage de charge.
Selon les caractéristiques des ressources, Nginx assurera une partie de la fonction de séparation du dynamique et du statique. Parmi elles, la partie fonction dynamique fera son entrée dans notre service SpringBoot.

SpringBoot utilise le tomcat intégré comme conteneur Web par défaut et utilise le modèle MVC typique pour enfin accéder à nos données.
5. Optimisation HTTP
Prenons un exemple pour voir quelles actions peuvent accélérer l'acquisition de pages web. Pour la commodité de la description, nous ne discutons que du protocole HTTP1.1.
1. Utilisez CDN pour accélérer l'acquisition de fichiers
Pour les fichiers plus volumineux, essayez d'utiliser CDN (Content Delivery Network) pour la distribution. Même certains scripts frontaux, styles, images, etc. couramment utilisés peuvent être placés sur le CDN. Les CDN accélèrent souvent la récupération de ces fichiers et les pages Web se chargent plus rapidement.
2. Définissez raisonnablement la valeur Cache-Control
Le navigateur évaluera le contenu de l'en-tête HTTP Cache-Control pour décider d'utiliser ou non le cache du navigateur, ce qui est très utile lors de la gestion de certains fichiers statiques. L'information d'en-tête ayant le même effet est Expire. Cache-Control indique combien de temps il expirera et Expires indique quand il expirera.
Ce paramètre peut être défini dans le fichier de configuration Nginx.
location ~* ^.+.(ico|gif|jpg|jpeg|png)$ { # Cache pendant 1 an add_header Cache-Control: no-cache, max-age=31536000; } 3. Réduire le nombre de noms de domaine demandés sur une seule page
Réduisez le nombre de noms de domaine demandés par chaque page et essayez de le limiter à 4. En effet, chaque fois que le navigateur accède aux ressources principales, il doit d'abord interroger le DNS, puis trouver l'adresse IP correspondant au DNS, puis passer le véritable appel.
DNS a plusieurs couches de cache, telles que le cache du navigateur, le cache de l'hôte local, le cache du fournisseur de services ISP, etc. La transition du DNS à l'adresse IP prend généralement 20 à 120 ms. Réduire le nombre de noms de domaine peut accélérer l'acquisition de ressources.
4. Activer gzip
Lorsque gzip est activé, le contenu peut d'abord être compressé, puis le navigateur peut le décompresser. Étant donné que la taille de la transmission est réduite, l'utilisation de la bande passante sera réduite et l'efficacité de la transmission sera améliorée.
Il peut être facilement activé dans nginx. La configuration est la suivante :
gzip activé ; gzip_min_length 1 k
;
gzip_buffers 4 16 k ;
gzip_comp_level 6 ;
gzip_http_version 1.1 ;
gzip_types text/plain application/javascript text/css ;
5. Compresser les ressources
Compressez JavaScript et CSS, même HTML. La raison est similaire : le mode de séparation populaire entre le front-end et le back-end comprime généralement ces ressources.
6. Utilisez keepalive
Il consomme des ressources en raison de la création et de la fermeture de connexions. Une fois que les utilisateurs auront accédé à nos services, il y aura plus d'interactions dans le suivi, donc le maintien d'une longue connexion peut réduire considérablement les interactions réseau et améliorer les performances.
Nginx permet de conserver le support avlide pour les clients par défaut. Vous pouvez ajuster son comportement avec les deux paramètres suivants.
http { keepalive_timeout 120s 120s; keepalive_requests 10000; } La connexion longue entre nginx et l'amont en amont doit être activée manuellement. La configuration de référence est la suivante :
emplacement ~ /{ proxy_pass http://backend ; proxy_http_version 1.1 ; proxy_set_header Connexion "" ; }
6. Optimisation Tomcat
L'optimisation de Tomcat lui-même est également une partie très importante.
Pourquoi le vieux chat tomcat peut-il vivre au-delà de l'âge des chats ordinaires ? Cela a quelque chose à voir avec sa construction légère, ainsi que ses excellentes performances. Maintenant tomcat, la version a grimpé à 10 ! .
Il existe de nombreux paramètres de configuration de tomcat, mais nous n'avons pas besoin de prêter attention à tous pour obtenir l'effet d'optimisation. Cet article présentera en détail certains paramètres de configuration principaux pour vous assurer que votre ancien chat fonctionne plus rapidement !
Généralement, le changement le plus courant consiste à modifier le port du serveur, qui est la partie Connecteur dans server.xml. Un exemple typique est illustré dans la figure suivante :
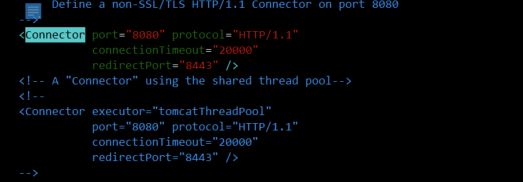
En fait, la plupart des optimisations se trouvent également dans l'onglet Connecteur, des ports, de la concurrence aux threads, peuvent être configurées ici.
1. 3 paramètres pour obtenir une configuration simultanée
En tant que conteneur Web capable d'effectuer de nombreuses requêtes Internet simultanées, bien sûr, la première chose qui en pâtit est l'impact des requêtes massives. Heureusement, Tomcat prend en charge NIO, et nous pouvons ajuster le nombre de threads et la configuration de la simultanéité pour qu'il affiche les meilleures performances.
maxThreads - le nombre maximal de threads que tomcat reçoit les demandes des clients, c'est-à-dire le nombre de tâches traitées en même temps, sa taille par défaut est de 200 ; en général, dans les applications intensives en E/S à haute simultanéité, cette valeur est définie à environ 1000
maxConnections plus raisonnable Ce paramètre fait référence au nombre maximum de connexions que tomcat peut accepter en même temps. Pour le BIO bloquant de Java, la valeur par défaut est la valeur de maxthreads ; si un exécuteur personnalisé est utilisé en mode BIO, la valeur par défaut sera la valeur de maxThreads dans l'exécuteur. Pour le nouveau mode NIO de Java, la valeur par défaut de maxConnections est 10000, nous gardons donc généralement ce paramètre inchangé et
acceptCount - lorsque le nombre de threads atteint la valeur définie ci-dessus, le nombre maximum de files d'attente pouvant être acceptées. Si cette valeur est dépassée, la demande sera rejetée. Je le règle généralement sur la même taille que maxThreads.Expliquez
brièvement la relation entre les trois paramètres ci-dessus :
Le nombre de connexions que le système peut maintenir
maxConnections+acceptCount, la différence est que les connexions dans maxConnections peuvent être planifiées pour le traitement ; les connexions dans acceptCount peuvent seulement attendre d'être mises en file d'attente
Le nombre de requêtes que le système peut traiter
La taille de maxThreads, le nombre réel de threads qui peuvent fonctionner.
Indice de bonheur : maxThreads > maxConnections > acceptCount.
Maintenant, certains articles sont également pleins de maxProcessors et minProcessors. Mais ces deux paramètres sont obsolètes depuis Tomcat5, et ont complètement disparu depuis 6.
On peut seulement dire que les articles que vous voyez peuvent vraiment être publiés par des opérateurs qui ne comprennent pas la technologie.
Représentés par 8, les paramètres de configuration spécifiques se trouvent dans :
https://tomcat.apache.org/tomcat-8.0-doc/config/http.html
Deuxièmement, la configuration des threads
En termes de configuration de concurrence, vous pouvez voir que nous n'avons que minSpareThreads, mais pas de maxSpareThreads. En effet, depuis que Tomcat 6 a ajouté des nœuds Executor, ce paramètre n'est plus utile.
Puisque le thread est un pool, sa configuration satisfait toutes les caractéristiques du pool.
référence:
https://tomcat.apache.org/tomcat-8.0-doc/config/executor.html
namePrefix – le préfixe du nom de chaque thread nouvellement ouvert maxThreads –
le nombre maximum de threads dans le pool de threads
minSpareThreads – le nombre de threads qui sont toujours actif
maxIdleTime – Le temps d'inactivité du thread, lorsque le temps d'inactivité est dépassé, ces threads seront détruits
threadPriority – La priorité du thread dans le pool de threads, la valeur par défaut est 5
Troisièmement, obtenez la configuration JVM
tomcat est une application Java, donc la configuration de la JVM affectera également ses performances. Les paramètres de configuration les plus importants sont les suivants.
2.1 La taille de la zone mémoire
La première chose à ajuster est la taille de chaque partition, mais celle-ci doit aussi être divisée dans le ramasse-miettes, nous ne regardons que quelques paramètres globaux.
-XX:+UseG1GC Spécifiez d'abord le ramasse-miettes utilisé par la JVM. Essayez de ne pas vous fier à la valeur par défaut pour garantir, pour en spécifier explicitement une.
-Xmx définit la taille maximale du tas, généralement 2/3 de la taille du système d'exploitation.
-Xms Définit la valeur initiale du tas, généralement définie sur la même taille que Xmx pour éviter l'expansion dynamique.
-Taille de la jeune génération Xmn, la jeune génération par défaut occupe 1/3 de la taille du tas. Dans les scénarios avec une simultanéité élevée et une mort rapide, cette zone peut être augmentée de manière appropriée. Moitié-moitié ou plus, ça va. Mais sous G1, il n'est pas nécessaire de définir cette valeur, elle sera ajustée automatiquement.
-XX:MaxMetaspaceSize Limite la taille du métaspace, généralement 256M suffisent. C'est généralement la même que la taille initiale **-XX:MetaspaceSize .
-XX:MaxDirectMemorySize Définissez la valeur maximale de la mémoire directe et limitez la mémoire demandée via DirectByteBuffer.
-XX:ReservedCodeCacheSize Définit la taille de la zone de stockage du code après compilation JIT.Si vous constatez que cette valeur est limitée, vous pouvez l'ajuster en conséquence, ce qui est généralement suffisant.
-Xss Définit la taille de la pile, la valeur par défaut est 1M, ce qui est suffisant.
2.2.
Réglage de la mémoire -XX :+AlwaysPreTouch initialisera toute la mémoire mentionnée dans les paramètres au démarrage. Le temps de démarrage sera plus lent, mais la vitesse de fonctionnement augmentera.
-XX:SurvivorRatio La valeur par défaut est 8. Indique le rapport entre la zone Eden et la zone survivante.
-XX:MaxTenuringThreshold Cette valeur par défaut est 6 sous CMS et 15 sous G1. Cette valeur est liée à l'amélioration de l'objet que nous avons mentionnée précédemment, et l'effet du changement sera plus évident. La répartition par âge des sujets peut être utilisée-XX:+PrintTenuringDistribution** print, si la taille des générations suivantes est toujours la même, ce qui prouve que les objets après un certain âge peuvent toujours être promus à l'ancienne génération, le seuil de promotion peut être défini plus petit.
Les objets dont PretenureSizeThreshold dépasse une certaine taille seront alloués directement dans l'ancienne génération. Cependant, ce paramètre est peu utilisé.
2.3. Optimisation
du ramasse-miettes Garbage collector G1
-XX:MaxGCPauseMillis Définissez le temps de pause cible, G1 essaiera de l'atteindre.
-XX:G1HeapRegionSize Définit la petite taille de tas. Cette valeur est une puissance de 2, ni trop grande ni trop petite. Si vous ne savez pas comment le configurer, conservez la valeur par défaut.
-XX:InitiatingHeapOccupancyPercent Lorsque l'utilisation totale de la mémoire du tas atteint un certain pourcentage (45 % par défaut), la phase de marquage simultané démarre.
-XX:ConcGCThreads Le nombre de threads utilisés par le garbage collector simultané. La valeur par défaut varie en fonction de la plate-forme sur laquelle la JVM s'exécute. Les modifications ne sont pas recommandées.
4. Autre configuration importante
Examinons quelques paramètres importants configurés dans Connector.
enableLookups - appelez la requête, getRemoteHost() pour effectuer une recherche DNS afin de renvoyer le nom d'hôte de l'hôte distant, ou renvoyez directement l'adresse IP si elle est définie sur false. Cela dépend de la demande
URIEncoding - le codage de caractères utilisé pour décoder l'URL, s'il n'est pas spécifié, la valeur par défaut est ISO-8859-1
connectionTimeout - le délai de connexion (en millisecondes)
redirectPort - le serveur spécifié a reçu un SSL lors du traitement d'une requête http numéro de port à rediriger après transmission de la requête
V. Résumé
Tomcat est le conteneur Web le plus couramment utilisé et fournit des centaines de paramètres de configuration. Mais dans notre utilisation normale, nous n'avons pas besoin de comprendre tous les paramètres, nous nous concentrons simplement sur les plus importants.
7. Conteneur Web personnalisé
Si votre projet a une simultanéité élevée et que vous souhaitez modifier les informations de configuration telles que le nombre maximal de threads et le nombre maximal de connexions, vous pouvez personnaliser le conteneur Web. Le code est le suivant.
@SpringBootApplication(proxyBeanMethods = false) L'
application de classe publique implémente WebServerFactoryCustomizer { public static void main(String[] args) { SpringApplication.run(PetClinicApplication.class, args); } @Override public void customize(ConfigurableServletWebServerFactory factory) { TomcatServletWebServerFactory f = (TomcatServletWebServerFactory) factory ; f.setProtocol("org.apache.coyote.http11.Http11Nio2Protocol");
f.addConnectorCustomizers(c -> { Protocole Http11NioProtocol = (Http11NioProtocol) c.getProtocolHandler(); protocol.setMaxConnections(200); protocol.setMaxThreads(200); protocol.setSelectorTimeout(3000); protocol.setSessionTimeout(3000); protocol. setConnectionTimeout(3000); }); } } Notez le code ci-dessus, nous définissons son protocole sur org.apache.coyote.http11.Http11Nio2Protocol, ce qui signifie que Nio2 est activé. Ce paramètre n'est disponible qu'après Tomcat 8.0, et il augmentera certaines performances après son activation. La comparaison est la suivante :
défaut.
[root@localhost wrk2-master]# ./wrk -t2 -c100 -d30s -R2000 http://172.16.1.57:8080/owners?lastName=
Exécution du test 30s @ http://172.16.1.57:8080/owners? lastName=
2 threads et 100 connexions Étalonnage des threads : lat. moyenne : 4 588,131
ms, intervalle d'échantillonnage de la fréquence : 16 277 ms Étalonnage
des threads : lat. moyenne : 4 647,927 ms, intervalle d'échantillonnage de la fréquence : 16 285 ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 16,49 s 4,98 s 27,34 s 63,90 %
Req/Sec 106,50 1,50 108,00 100,00 %
6471 requêtes en 30,03 s, 39,31 Mo de lecture
Erreurs de socket : connexion 0, lecture 0, écriture 0, timeout 60
Requêtes/s : 215,51
Transfert/s : 1,31
Mo Nio2。
[root@localhost wrk2-master]# ./wrk -t2 -c100 -d30s -R2000 http://172.16.1.57:8080/owners?lastName=
Exécution du test 30s @ http://172.16.1.57:8080/owners? lastName=
2 threads et 100 connexions Étalonnage des threads : lat.
moyenne : 4 358,805 ms, intervalle d'échantillonnage de la fréquence : 15 835 ms Étalonnage
des threads : lat. moyenne : 4 622,087 ms, intervalle d'échantillonnage de la fréquence : 16 293 ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 17,47s 4,98 s 26,90 s 57,69 %
Req/Sec 125,50 2,50 128,00 100,00 %
7469 requêtes en 30,04 s, 45,38 Mo de lecture
Erreurs de socket : connexion 0, lecture 0, écriture 0, timeout 4
Requêtes/s
: 248,64 Transfert/s : 1,51 Mo
Vous pouvez même Remplacez tomcat par ressac. Undertow est également un conteneur Web, qui est plus léger, occupe moins de contenu et démarre moins de processus démons. Les changements sont les suivants :
Étant donné que le contrôleur n'agit que comme une combinaison de fonctions et un rôle de routage similaires, l'impact de cette partie sur les performances se reflète principalement dans la taille de l'ensemble de données. Si le jeu de résultats est très volumineux, le composant d'analyse JSON passera plus de temps à analyser.
Les ensembles de résultats volumineux affectent non seulement le temps d'analyse, mais entraînent également un gaspillage de mémoire. Si le jeu de résultats occupe 10 Mo de mémoire avant d'être analysé en JSON, pendant le processus d'analyse, 20 Mo ou plus de mémoire peuvent être utilisés pour effectuer ce travail. J'ai vu de nombreux cas où l'utilisation de la mémoire augmente en raison d'objets renvoyés profondément imbriqués, référençant des objets qui ne devraient pas être référencés (tels que des objets byte[] très volumineux).
Par conséquent, pour les services généraux, il est très nécessaire de garder le jeu de résultats compact, ce qui est également nécessaire pour l'existence de DTO (objet de transfert de données). Si votre projet renvoie une structure de résultats complexe, il est nécessaire d'effectuer une conversion sur le jeu de résultats.
De plus, la couche contrôleur peut être optimisée à l'aide de servlets asynchrones. Son principe est le suivant : une fois que la servlet a reçu la requête, elle transfère la requête à un thread asynchrone pour effectuer le traitement métier, et le thread lui-même retourne dans le conteneur. Une fois que le thread asynchrone a traité le métier, il peut directement générer des données de réponse, ou continuer à transmettre la demande à d'autres servlets. .
Couche de
service La couche de service est utilisée pour traiter des affaires spécifiques, et la plupart des exigences fonctionnelles sont remplies ici. La couche de service utilise généralement le modèle singleton (prototype), enregistre rarement l'état et peut être réutilisée par le contrôleur.
L'organisation du code de la couche de service a un impact important sur la lisibilité et les performances du code. La plupart des modèles de conception dont nous parlons souvent visent la couche de service.
Le point à souligner ici est celui des transactions distribuées.

Comme indiqué ci-dessus, les quatre opérations sont réparties sur trois ressources différentes. Atteindre la cohérence nécessite trois ressources différentes pour se coordonner à l'unisson. Leurs protocoles sous-jacents et leurs méthodes de mise en œuvre sont tous différents. Cela ne peut pas être résolu par l'annotation Transaction fournie par Spring, et cela doit être fait à l'aide de composants externes.
Beaucoup de gens l'ont expérimenté, ajoutant du code pour assurer la cohérence, et après un test de résistance, les performances ont chuté et leur mâchoire est tombée. Les transactions distribuées nuisent aux performances car elles utilisent des étapes supplémentaires pour assurer la cohérence. Les méthodes courantes incluent : schéma de validation en deux phases, TCC, table de messages locale, message de transaction MQ, middleware de transaction distribuée, etc.

Comme le montre la figure ci-dessus, les transactions distribuées doivent être prises en compte de manière globale en termes de coût de transformation, de performances et d'efficacité. Il existe un terme entre les transactions distribuées et les non-transactions, appelées transactions flexibles. L'idée des transactions flexibles est de déplacer la logique métier et les opérations mutuellement exclusives de la couche ressource vers la couche métier.
Concernant les transactions traditionnelles et les transactions flexibles, comparons-les brièvement.
ACIDE
La plus grande caractéristique des bases de données relationnelles est le traitement des transactions, c'est-à-dire pour répondre à ACID.
Atomicité : soit toutes les opérations d'une transaction, soit aucune, sont effectuées.
Cohérence : le système doit toujours être dans un état fortement cohérent.
Isolation : l'exécution d'une transaction ne peut pas être perturbée par d'autres transactions.
Durabilité : une transaction validée apporte des modifications permanentes aux données de la base de données.
BASE
L'approche BASE améliore la disponibilité et les performances du système en sacrifiant la cohérence et l'isolation.
BASE est l'abréviation de Basically Available, Soft-state, Eventuellement cohérent, où BASE signifie :
Disponible de base : le système peut fonctionner et fournir des services à tout moment.
Soft-state : le système n'a pas besoin d'un état fortement cohérent tout le temps.
Cohérence éventuelle : le système doit atteindre la cohérence après un certain temps.
Pour les services Internet, il est recommandé d'utiliser des transactions de compensation pour parvenir à une éventuelle cohérence. Par exemple, grâce à une série de tâches chronométrées, la restauration des données est terminée. Pour plus de détails, veuillez consulter l'article suivant.
Quelles sont les transactions distribuées couramment utilisées ? Lequel dois-je utiliser ?
Couche Dao
Après un cache de données raisonnable, nous essaierons d'éviter que les requêtes ne pénètrent dans la couche Dao. À moins que vous ne soyez particulièrement familiarisé avec les fonctionnalités de mise en cache fournies par l'ORM lui-même, il est recommandé d'utiliser une approche plus générale de la mise en cache des données.
Couche Dao, principalement dans l'utilisation du cadre ORM. Par exemple, dans JPA, si une relation de mappage un-à-plusieurs ou plusieurs-à-plusieurs est ajoutée, mais que le chargement paresseux n'est pas activé, il est facile de provoquer une récupération en profondeur lors de requêtes en cascade, ce qui entraîne une surcharge de mémoire élevée et une exécution lente. . .
Dans certaines entreprises disposant d'une quantité de données relativement importante, la méthode de la sous-base de données et de la sous-table est souvent utilisée. Dans ces composants de sous-base de données et de sous-table, de nombreuses instructions de requête simples seront ré-analysées et distribuées à chaque nœud pour l'opération, et enfin les résultats seront fusionnés.
Par exemple, la simple instruction count de select count(*) à partir de a peut acheminer la requête vers plus d'une douzaine de tables pour le calcul, et finalement effectuer des statistiques au nœud de coordination.L'efficacité d'exécution est concevable. À l'heure actuelle, les middleware les plus représentatifs pour la sous-base de données et la sous-table sont ShardingJdbc dans la couche pilote et MyCat dans la couche proxy, qui ont tous deux de tels problèmes. Les vues fournies aux utilisateurs par ces composants sont cohérentes, mais nous devons faire attention à ces différences lors du codage.
Fin
Résumons ci-dessous.
Nous avons brièvement examiné les idées d'optimisation courantes de SpringBoot. Nous introduisons trois nouveaux outils d'analyse de performance. L'un est le système de surveillance Prometheus, vous pouvez voir des indicateurs spécifiques ; l'un est le graphique de la flamme, vous pouvez voir les points chauds de code spécifiques ; l'autre est Skywalking, qui peut analyser la chaîne d'appels dans l'environnement distribué. Lorsque nous avons des doutes sur les performances, nous utiliserons une méthode similaire au goût des herbes de Shennong et analyserons les résultats de divers outils d'évaluation.
Le propre conteneur Web de SpringBoot est Tomcat, nous pouvons alors obtenir une amélioration des performances en ajustant Tomcat. Bien sûr, nous fournissons également une série d'idées d'optimisation pour l'équilibrage de charge Nginx au niveau de la couche supérieure du service.
Enfin, nous avons examiné certaines directions d'optimisation de Controller, Service et Dao sous l'architecture MVC classique, et nous nous sommes concentrés sur le problème des transactions distribuées de la couche Service.
En tant que cadre de service largement utilisé, SpringBoot a beaucoup travaillé sur l'optimisation des performances et sélectionné de nombreux composants à haute vitesse. Par exemple, le pool de connexions à la base de données utilise hikaricp par défaut, la structure de cache Redis utilise la laitue par défaut et le cache local fournit de la caféine. Pour un service Web commun interagissant avec une base de données, la mise en cache est l'optimiseur le plus important.