Pratique de la capacité de planification par lots 4-Volcano dans le scénario HPC
Le partage d'aujourd'hui comprend principalement 4 parties :
-
Qu'est-ce que le CHP
-
Introduire l'application HPC de champ météorologique typique WRF
-
Comment Volcano prend en charge les tâches HPC traditionnelles
-
Comment exécuter un exemple sur Volcano
Qu'est-ce que le CHP

HPC est le calcul haute performance (High Performance Computing, en abrégé HPC) fait référence à l'utilisation de la puissance de calcul agrégée pour traiter des tâches informatiques gourmandes en données qui ne peuvent pas être effectuées par des postes de travail standard . D'une manière générale, HPC fait référence à un cluster HPC complet. Lorsqu'il s'agit d'un cluster, nous devons être clairs sur le fait qu'il s'agit généralement de plusieurs machines, et qu'un cluster est un ensemble de logiciels ou de matériel informatiques lâches connectés pour effectuer des travaux informatiques de manière très étroitement coordonnée.
Le calcul parallèle fait référence à un mode de calcul dans lequel de nombreuses instructions peuvent être exécutées en même temps. Sous la prémisse de l'exécution simultanée, le processus de calcul peut être décomposé en petites parties, et finalement le problème peut être résolu de manière concurrente.
Les hautes performances mettent principalement l' accent sur les performances , comprenant généralement une série de matériels tels que les unités de calcul, la mémoire et les réseaux de stockage, et ont des exigences de performances élevées pour ces ressources. Par conséquent, les systèmes informatiques à hautes performances impliqueront également une informatique hétérogène, des systèmes de fichiers parallèles, des réseaux à haut débit, etc.
Si nous voulons exécuter une tâche de calcul parallèle dans le cluster, nous devons impliquer trois parties :

- PBS : Resource Manager, responsable de la gestion des ressources de tous les nœuds du cluster
- Maui : planificateur de tâches tiers, prend en charge la réservation de ressources, prend en charge diverses politiques de priorité complexes, prend en charge le mécanisme de préemption, etc.
- OpenMPI : environnement de communication de couche supérieure, prenant en compte les fonctions de bibliothèque de communication, de compilation et de tâches de démarrage distribué
Dans ces trois parties, PBS et Maui s'apparentent à un logiciel de gestion de plateforme, en effet, les utilisateurs n'ont pas besoin de comprendre les détails pratiques de ce logiciel de gestion de plateforme, mais seulement de savoir utiliser PBS pour soumettre des travaux Maui. Cependant , cette partie d'OpenMPI nécessite que les utilisateurs comprennent ses détails, car les utilisateurs doivent écrire leurs propres programmes exécutables selon la bibliothèque fournie par MPI pour réaliser le calcul parallèle.
Comment fonctionnent les tâches MPI
Comment fonctionnent les jobs MPI ? Nous utilisons la commande mpirun comme exemple pour illustrer.
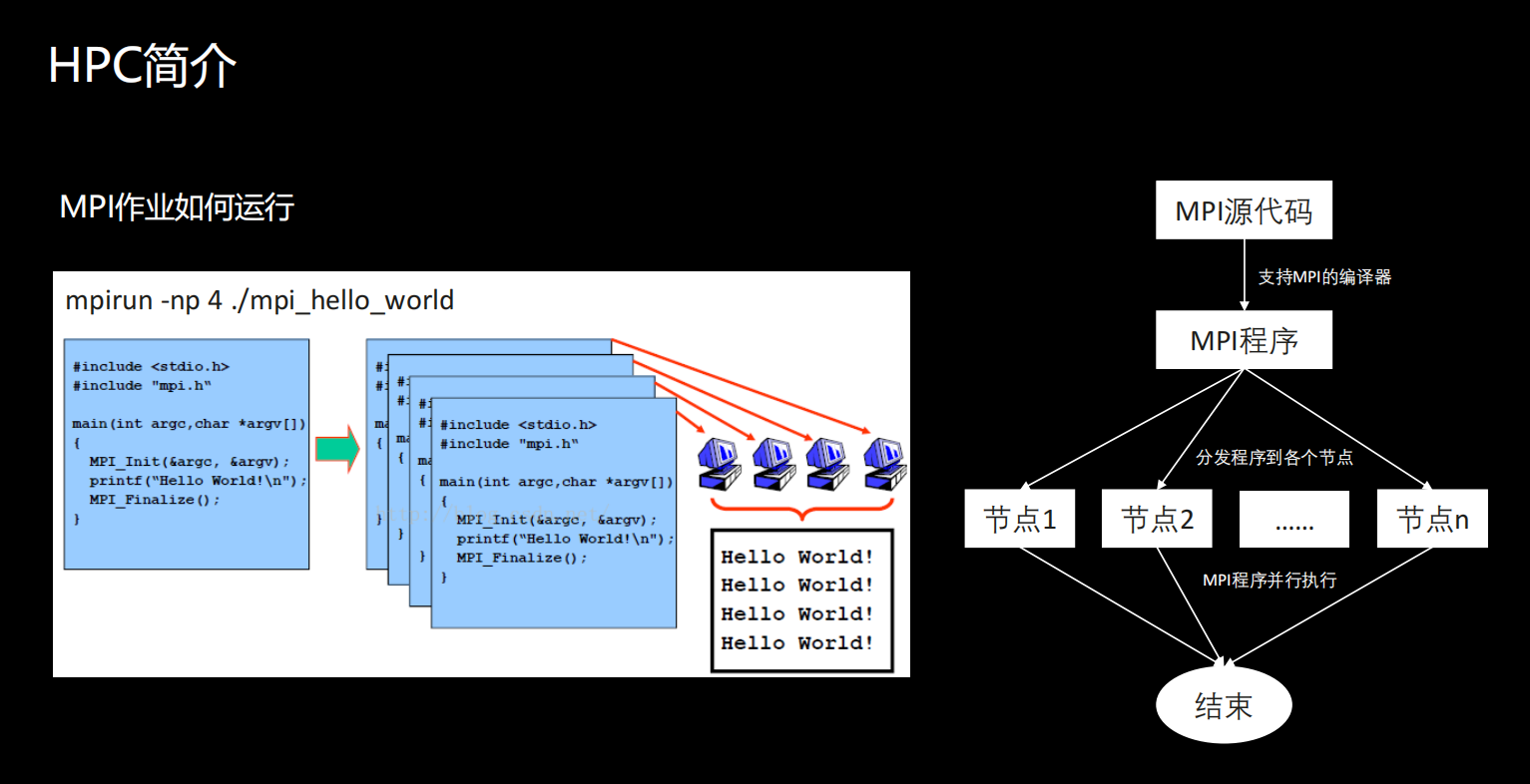
Les utilisateurs doivent appeler la bibliothèque MPI pour écrire leur propre code source. L'exemple que nous avons vu est qu'après avoir appelé la bibliothèque MPI, un mot bonjour est sorti. Ici, l'utilisateur doit utiliser un compilateur prenant en charge MPI pour compiler le code source dans un programme exécutable MPI.Après la compilation, en fait, une chose que l'utilisateur doit faire est de distribuer le programme à chaque machine. Après la distribution, les utilisateurs peuvent appeler directement la commande mpirun pour exécuter le programme de calcul parallèle écrit.
Qu'est-ce que WRF
WRF (Weather Research and Forecasting Model) est un système de prévision météorologique numérique à méso-échelle conçu pour la recherche atmosphérique et les applications de prévision opérationnelle, qui peut être simulé en fonction de conditions atmosphériques réelles ou de conditions idéales.
WRF, abréviation de Weather Research and Forecast Model, est un système de prévision météorologique numérique à méso -échelle conçu pour la recherche atmosphérique et les applications de prévision opérationnelle, qui peut être simulé en fonction des conditions atmosphériques réelles ou des conditions idéales. Pour le dire franchement, il s'agit d'une application HPC typique qui peut effectuer des prévisions météorologiques ou des prévisions de catastrophe. Le but de l'introduire est de faire passer cela, afin que chacun puisse ressentir intuitivement l'application de HTC.
La figure suivante répertorie brièvement le flux de traitement de WRF. Ce à quoi nous devons prêter attention, c'est que parce qu'il existe de nombreux modules avancés dans WRF, différents modules sont utilisés pour réaliser différentes simulations ou prévisions.
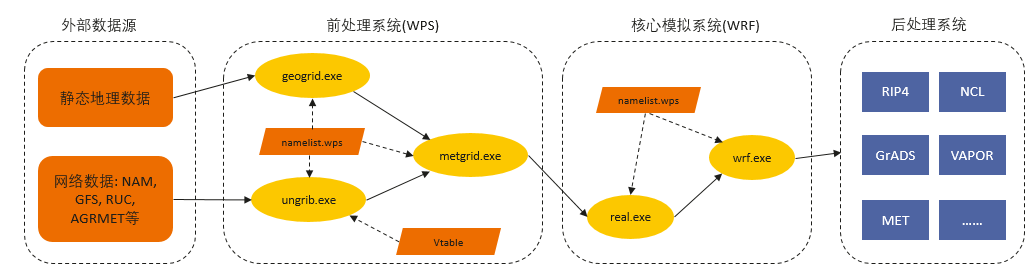
La partie ovale jaune est l'outil compilé WRF et le parallélogramme est le fichier de configuration qui doit être utilisé lorsque le programme est exécuté. Un flux de traitement WRF complet comprend 4 parties : source de données externe, système de prétraitement, système de simulation de base, système de post-traitement (le transfert de données doit être effectué manuellement) .
real.exe et wrf.exe
eal.exe et wrf.exe prennent en charge le calcul parallèle MPI, ces deux sont des simulations de base.
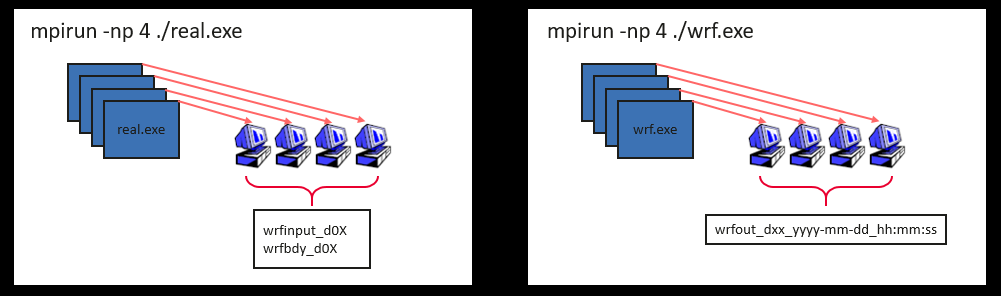
Nous pouvons voir qu'après l'exécution de real.exe, deux types de fichiers seront générés.Ces deux types de fichiers seront éventuellement utilisés par le processus derrière wrf.exe.En simulant ces données, un résultat est finalement généré.
Un exemple simple d'un calcul Conus 2,5 km est répertorié, afin que chacun puisse ressentir intuitivement les résultats générés après l'exécution du WRF.
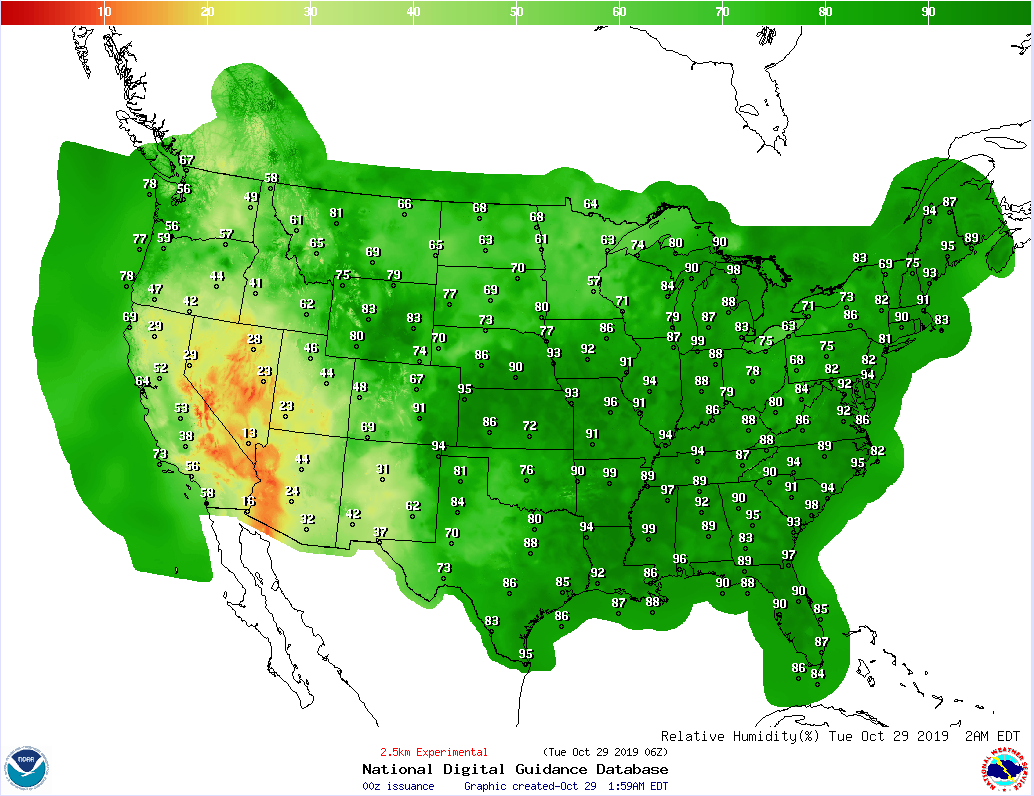
Conus 2,5 correspond aux données météorologiques de la zone continentale des États-Unis. Sa résolution est de 2,5 kilomètres. Le point simple est qu'il divise la zone sur la carte en une petite grille de 2,5 × 2,5 × 2,5. Les informations météorologiques sont considérées comme cohérentes, puis des déductions sont faites dans ce cas.
HPC sur le volcan
Ce qui suit décrit comment Volcano prend en charge cette opération HPC traditionnelle. Nous venons de mentionner qu'un système HPC traditionnel impliquera trois parties, et certains changements ont eu lieu dans la relation correspondante dans Volcano.

Dans la partie gestionnaire de ressources , nous sommes passés de PBS à nos K8, et le planificateur tiers est en fait notre Volcano.
Dans ce cas, Volcano fait plus qu'un simple programme. Nous savons que dans les K8, les travaux et les applications sont exécutés dans des conteneurs, mais si les travaux MPI natifs s'exécutent dans des conteneurs, il y aura des problèmes.
Par conséquent, en plus d'exécuter la fonction de planification, Volcano traitera également les problèmes rencontrés, afin que le travail MPI puisse s'exécuter sans problème dans l'environnement K8s. La troisième partie est que l'utilisateur doit compléter lui-même l'écriture de l'application.
Exécuter des tâches MPI dans des conteneurs
Pour exécuter une tâche MPI dans Volcano, nous divisons le conteneur global en deux parties. Une partie s'appelle le conteneur Master et l'autre partie est le conteneur Worker. Le conteneur Master peut être simplement compris comme le conteneur qui exécute la commande mpirun, et le conteneur Worker est le conteneur qui exécute réellement le processus MPI.

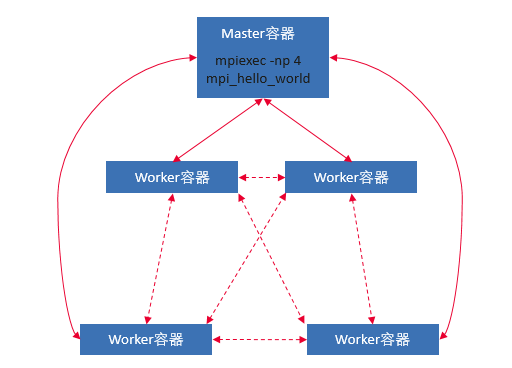
Comment Volcano prend en charge les travaux MPI :
- Le travail Volcano prend en charge la définition de plusieurs modèles de pod
- Prise en charge de la planification des gangs
- Mappage IP de l'hôte interne du conteneur maître/travailleur (service sans tête)
- Connexion SSH sans mot de passe entre les conteneurs Master/Worker
- Gestion du cycle de vie des travaux
Configuration des tâches MPI
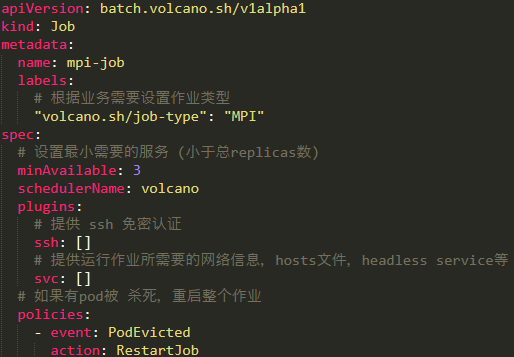
Quelle configuration devons-nous faire si nous voulons exécuter un travail MPI dans l'environnement ? De manière générale, nous pouvons définir un type de travail Volcano. Mais il y a quelques points auxquels il faut prêter attention lors de la définition :
- Le type d'emploi doit être ajouté au label label , ce n'est qu'ainsi que Volcano le considérera comme un emploi MPI à mobiliser;
- Il y a une valeur minAvailable dans la spécification, qui est en fait inférieure au nombre total de conteneurs de travail dans le conteneur principal derrière nous ;
- Deux plugins doivent être ajoutés au travail, l'un est ssh et l'autre est svc ; ssh fournit la fonction d'authentification sans mot de passe entre chaque nœud et svc fournit les informations réseau requises lorsque le travail est en cours d'exécution ;
- Configurez les politiques du travail. Lorsqu'un pod est tué, le travail entier sera redémarré pour s'exécuter à nouveau ;
Configuration du conteneur de travail
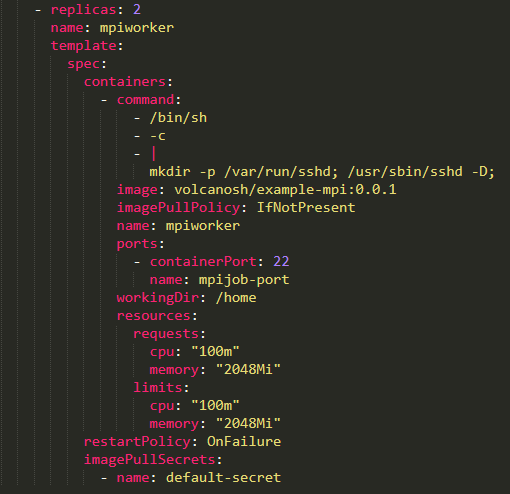
Comme il ne s'agit que d'un conteneur Worker, nous n'avons qu'à démarrer un service ssh ici, et aucune autre opération n'a besoin d'être effectuée. Après le démarrage, attendez que le conteneur Master soumette le travail.
Configuration du conteneur principal
Il y en aura un peu plus dans le conteneur Master. Tout d'abord, vous devez configurer une stratégie, ce qui signifie que lorsque le processus maître se termine, il considérera que l'ensemble du travail est terminé . Deuxièmement, la commande start est différente de Worker, elle obtiendra la liste des nœuds de tous les travailleurs. De plus, un service ssh est démarré pour exécuter mpirun directement.
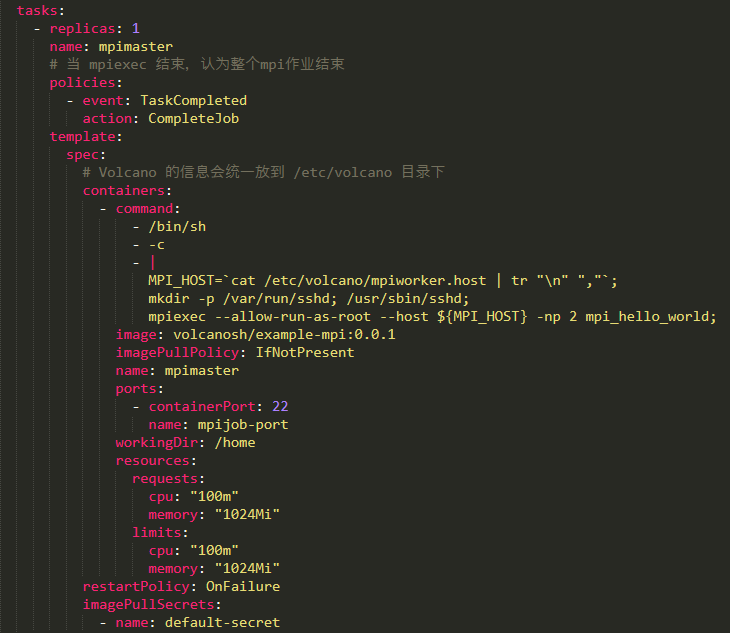
Configuration des tâches WRF
Configuration du conteneur principal
Quelle configuration ou préparation devons-nous faire si nous voulons exécuter un travail WRF sur Volcano ? Voici une liste de ce qui doit être modifié dans le fichier yaml lorsque le travail est soumis :
①Les utilisateurs doivent définir leur propre fichier image , qui inclut l'environnement d'exploitation complet de WRF.
② Pour traiter les données météorologiques correspondantes, et la taille de ces données prend beaucoup d'espace disque, elles sont donc généralement utilisées comme un volume, montées dans le conteneur et utilisées directement dans le conteneur. Notez que les données montées à cet endroit doivent être disponibles sur chaque nœud de développement, sinon il y aura des problèmes.
③ Lors de son exécution, le travail WRF nécessite que le programme exécutable et ses données soient dans le même répertoire , puis par défaut, le fichier exécutable est lié à notre répertoire, et la simulation météo peut vraiment démarrer dans le conteneur.
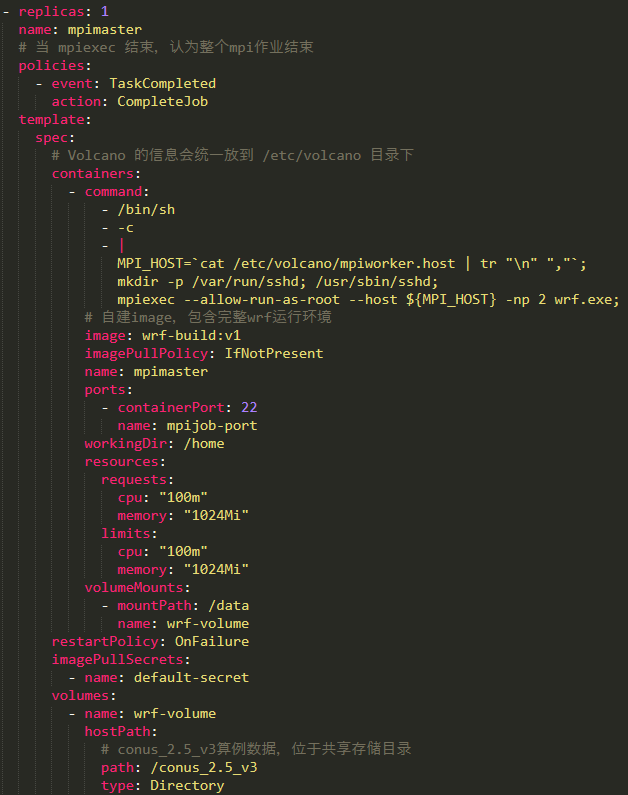
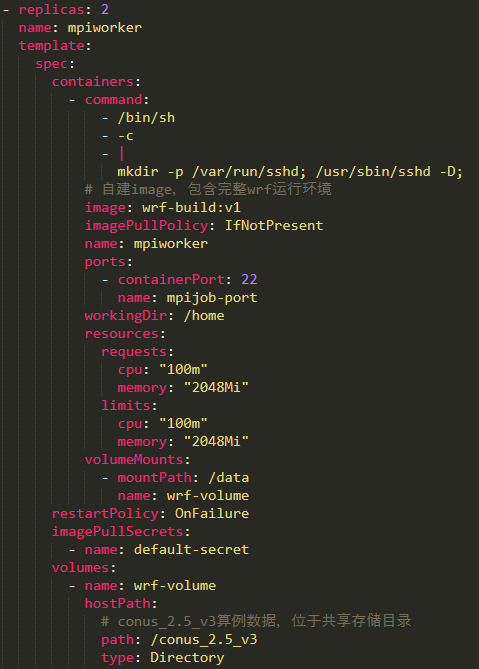
Configuration du conteneur de travail
La configuration Worker est très simple, il suffit de démarrer le service ssh et de conserver les données de mise en miroir et de montage cohérentes avec notre configuration Master.
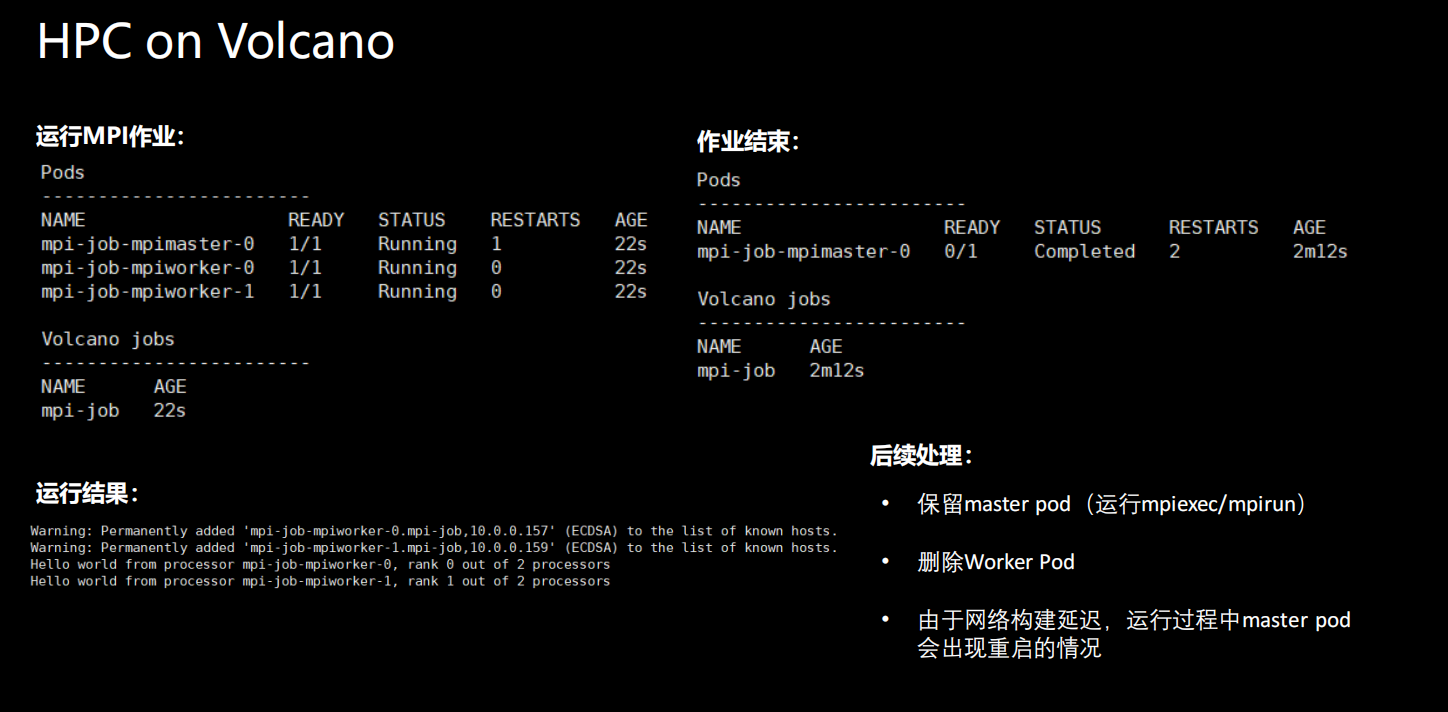
Pratique d'opération HPC
• Exécution de tâches MPI sur Volcano
• Entrepôt principal Fork Volcano (veuillez cliquer sur une étoile)
• Reportez-vous à la documentation pour déployer le volcan
C'est très simple, il suffit de démarrer le service ssh et de conserver les données de mise en miroir et de montage cohérentes avec notre configuration principale.
[Dumping d'image de lien externe...(img-T3nv4Yem-1649323545132)]
Pratique d'opération HPC
• Exécution de tâches MPI sur Volcano
• Entrepôt principal Fork Volcano (veuillez cliquer sur une étoile)
• Reportez-vous à la documentation pour déployer le volcan
• Pour exécuter une tâche MPI, reportez-vous à https://github.com/volcano-sh/volcano/blob/master/example/kubecon-2019-china/mpi-sample/mpi-example.yaml, modifiez le nom de la tâche et espace de noms