1. Connaissance de base de l'entrée C++ Qu'est-ce que C++ ?
En 1982, le Dr Bjarne Stroustrup a introduit et élargi le concept d'orienté objet sur la base du langage C, et a inventé un nouveau langage de programmation. Afin d'exprimer la relation entre le langage et le langage C, il est nommé C++. Par conséquent : C++ est basé sur le langage C, il peut non seulement effectuer la programmation procédurale du langage C, mais peut également effectuer la programmation basée sur des objets caractérisée par des types de données abstraits, et peut également effectuer la programmation orientée objet .
Les connaissances de base de la version PDF d'entrée C++, du didacticiel d'amélioration C++, des livres électroniques C++ peuvent être obtenues comme suit
Attention au compte public WeChat : "C et C plus" Répondre au mot-clé : "C++" pour recevoir

Deuxièmement, les connaissances de base de l'entrée C++ regardent la version historique de C++
-
C avec classes classes et classes dérivées, membres publics et privés, construction et destructeur de classe, amis, fonctions en ligne, surcharge d'opérateur d'affectation, etc.
-
C++ 1.0 ajoute le concept de fonctions virtuelles, de surcharge de fonctions et d'opérateurs, de références, de constantes, etc.
-
Prise en charge plus parfaite de C++ 2.0 pour les nouveaux membres protégés orientés objet, l'héritage multiple, l'initialisation des objets, les classes abstraites, les membres statiques et les fonctions membres const
-
C ++ 3.0 est encore amélioré en introduisant des modèles pour résoudre le problème d'ambiguïté causé par l'héritage multiple et le traitement de la construction et de la destruction correspondantes
-
La première version de la norme C++98 C++, prise en charge par la plupart des compilateurs, a été reconnue par l'Organisation internationale de normalisation (ISO) et l'American Standardization Association, a réécrit la bibliothèque standard C++ à la manière d'un modèle et a introduit STL (Standard Bibliothèque de modèles)
-
C++03 Deuxième version du standard C++, les fonctionnalités du langage n'ont pas beaucoup changé, principalement : correction des erreurs, réduction de la diversité
-
Le comité des normes C++05 C++ a publié un rapport technique (TR1), officiellement renommé C++0x, c'est-à-dire : prévu pour être publié au cours de la première décennie de ce siècle
-
C++ 11 ajoute de nombreuses fonctionnalités qui font de C++ un nouveau langage, telles que : expressions régulières, boucles for basées sur des plages, mots-clés automatiques, nouveaux conteneurs, initialisation de liste, bibliothèque de threading standard, etc.
-
L'extension de C++14 à C++11 consiste principalement à corriger les vulnérabilités et les améliorations de C++11, telles que : les expressions lambda génériques, la déduction automatique du type de valeur de retour, les constantes littérales binaires, etc.
-
C++17 a apporté quelques améliorations mineures à C++11, en ajoutant 19 nouvelles fonctionnalités, telles que : des informations textuelles facultatives pour static_assert(), des expressions de pliage pour les modèles de variables, des initialiseurs d'instructions if et switch, etc.
Trois mots clés de connaissances de base en C++
Il y a un total de 63 mots clés en C++ :
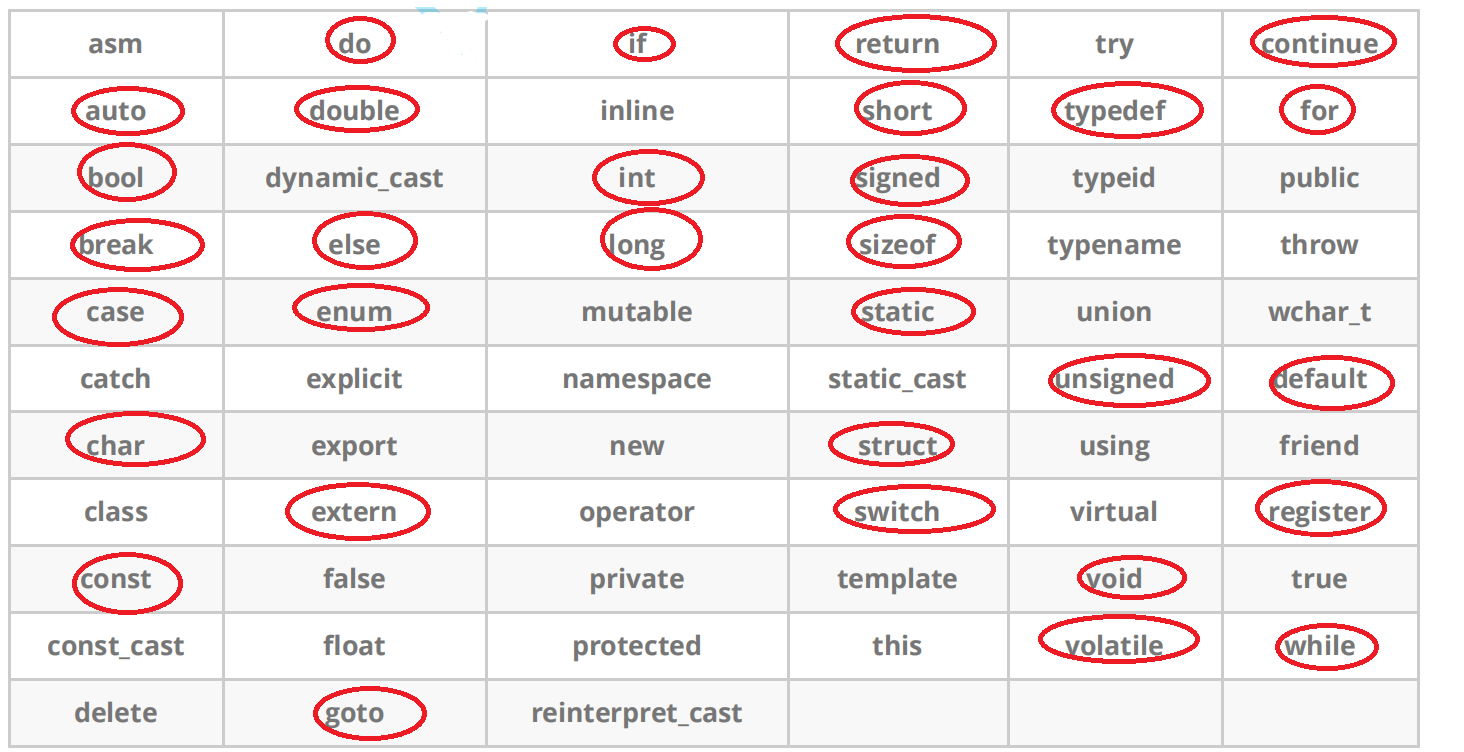
Les encerclés sont les mots-clés du langage C.这里要注意了:false和true并不是C语言的关键字。
Quatrièmement, l'espace de noms C++ de la base d'entrée C++
En C/C++, les variables, fonctions et classes existent en grand nombre, et les noms de ces variables, fonctions et classes seront appliqués à la portée globale, ce qui peut entraîner de nombreux conflits de nommage.
Le but de l'utilisation des espaces de noms est de localiser les identificateurs et les noms afin d'éviter les conflits de noms ou la pollution des noms. Le mot-clé namespace semble résoudre ce problème.
Pour définir un espace de noms, vous devez utiliser le mot-clé namespace, suivi du nom de l'espace de noms, puis d'une paire de {}, où {} est le nom
membres de l'espace.
Remarque : Un espace de noms définit une nouvelle portée et tout ce qui se trouve dans l'espace de noms est limité à cet espace de noms.
1. Définition commune de l'espace de noms

2. Les espaces de noms peuvent être imbriqués

3. Plusieurs espaces de noms portant le même nom sont autorisés dans le même projet et le compilateur finira par les synthétiser dans le même espace de noms.

il sera fusionné avec l'espace de noms xjt ci-dessus
Cinq, l'utilisation de l'espace de noms de base d'entrée C++
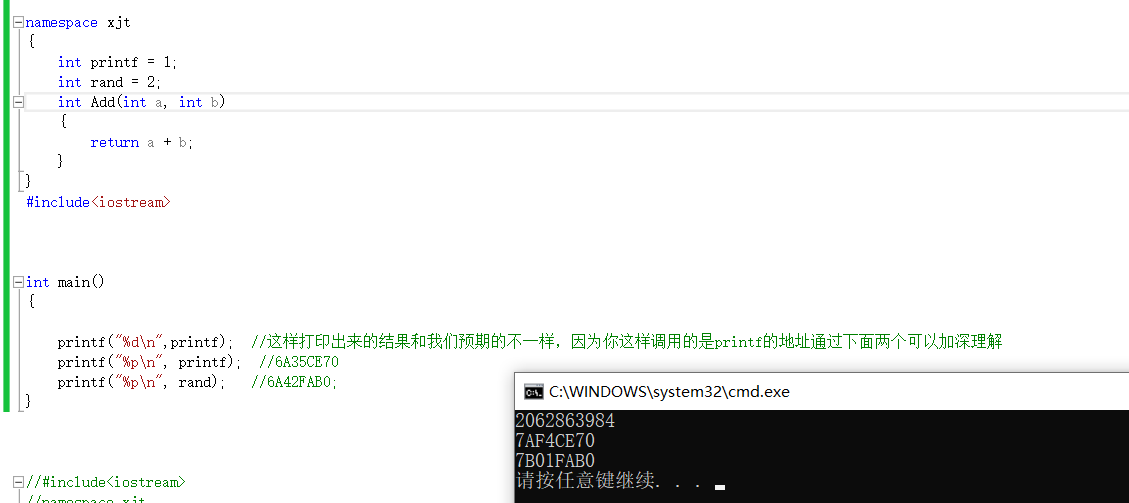
Évidemment, il est impossible d'imprimer directement printf, car vous appelez l'adresse de printf comme ceci, donc ce résultat apparaîtra.Les méthodes d'appel positives sont les trois suivantes.
1. Ajoutez le nom de l'espace de noms et le qualificateur de portée
Le symbole "::" est appelé un qualificateur de portée en C++, et nous pouvons accéder aux membres correspondants dans l'espace de noms via "nom de l'espace de noms :: membre de l'espace de noms"
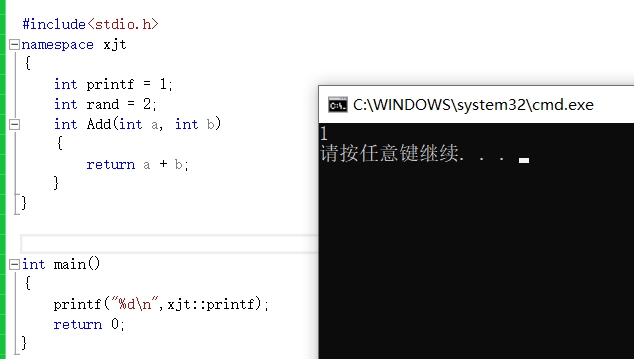
2. Présentation de l'utilisation de l'espace de noms nom de l'espace de noms
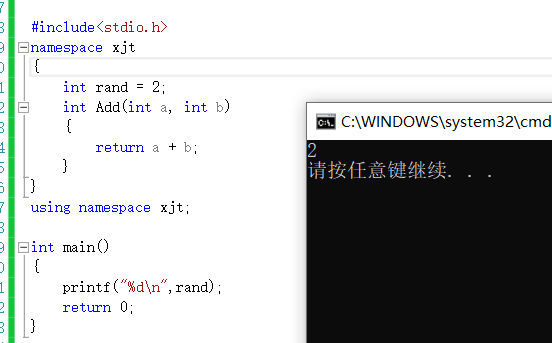
Mais il y a quelques inconvénients à cette méthode : si nous définissons une variable nommée printf dans l'espace de noms, alors si nous introduisons l'espace de noms xjt plus tard, cela causera une pollution de nommage.

Pour résoudre ce problème, une troisième méthode d'introduction a vu le jour.
3. Utilisez using pour introduire des membres dans l'espace de noms
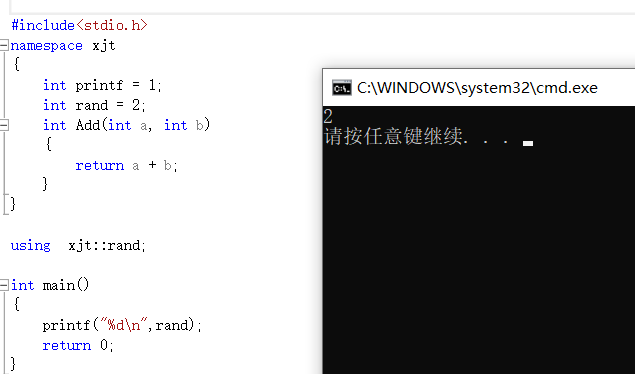
Cette approche évite de nommer la pollution, puisqu'elle n'en introduit qu'une partie.
6. Entrée et sortie des connaissances de base de l'entrée C++

Il existe des fonctions d'entrée et de sortie standard scanf et printf en langage C, tandis qu'en C++, il existe une entrée standard cin et une sortie standard cout. Pour utiliser les fonctions scanf et printf en langage C, le fichier d'en-tête stdio.h doit être inclus. Pour utiliser cin et cout en C++, vous devez inclure le fichier d'en-tête iostream et l'espace de noms standard std.
La méthode d'entrée et de sortie de C++ est plus pratique que le langage C, car l'entrée et la sortie de C++ n'ont pas besoin de contrôler le format, par exemple : le type entier est %d et le type caractère est %c.

Remarque : endl, le l dans this n'est pas le chiffre arabe 1, mais le l de 26 lettres anglaises, ce qui équivaut à une nouvelle ligne.
Ici, nous devons également prêter attention aux caractéristiques de cin. Il est similaire à gets en langage C. Gets s'arrête lorsqu'il rencontre une nouvelle ligne, tandis que cin utilise un espace, une tabulation ou une nouvelle ligne comme séparateur, alors entrez hello world ici. sont séparés par des espaces.
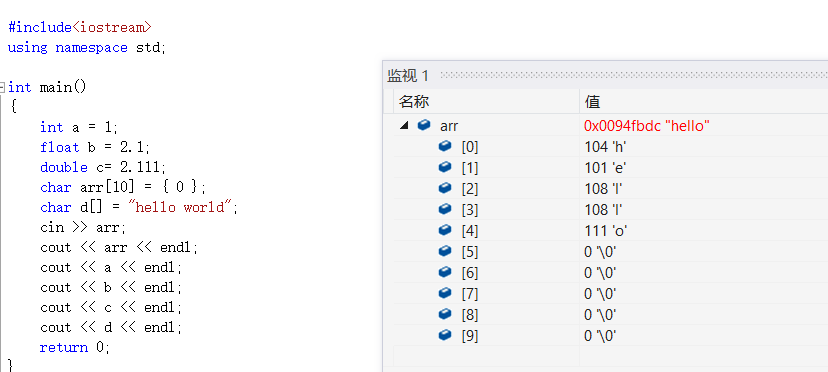
Ici, je saisis hello world, mais comme il y a un espace lors de la saisie, le contenu qui suit ne sera pas lu, donc hello est stocké dans arr.
7. Connaissance de base de l'entrée C++ - paramètres par défaut
Un paramètre par défaut est lorsqu'une fonction est déclarée ou définie pour spécifier une valeur par défaut pour les paramètres d'une fonction. Lors de l'appel de la fonction, la
valeur par défaut est utilisée si aucun argument n'est spécifié, sinon les arguments spécifiés sont utilisés.
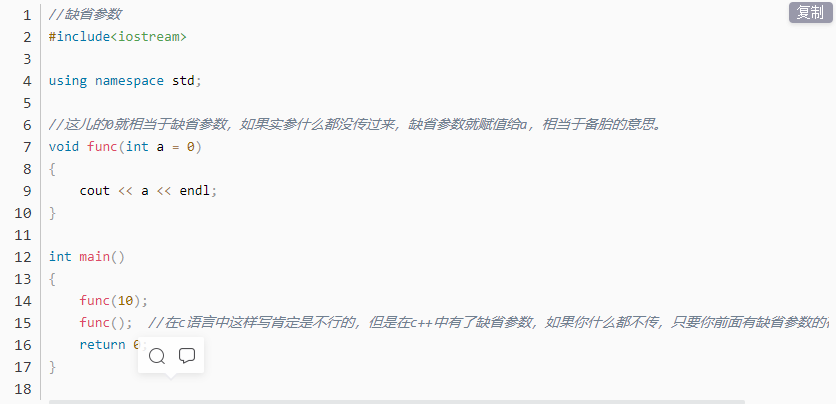
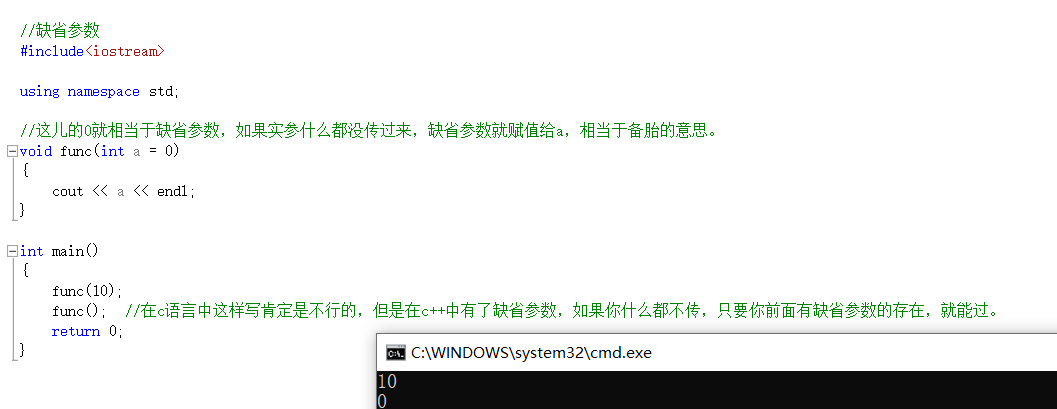
1. Tous par défaut
Tous les paramètres par défaut, c'est-à-dire tous les paramètres formels de la fonction, sont définis sur les paramètres par défaut.

2. Paramètres semi-par défaut

Remarquer:
-
Les paramètres semi-par défaut doivent être donnés séquentiellement de droite à gauche et ne peuvent pas être donnés à intervalles.

-
Les paramètres par défaut ne peuvent pas apparaître à la fois dans la déclaration et la définition de la fonction

Parce que : si la déclaration et la définition se produisent en même temps, et que les deux endroits fournissent des valeurs différentes, le compilateur ne peut pas déterminer quelle valeur par défaut utiliser.
-
La valeur par défaut doit être une constante ou une variable globale.

Huit, les bases du C++ - surcharge de fonctions C++
1. Surcharge de fonctions
La surcharge de fonctions est un cas particulier de fonctions. C++ permet de déclarer plusieurs fonctions de même nom avec des fonctions similaires dans la même portée . Les listes de paramètres formels (nombre ou type ou ordre des paramètres) de ces fonctions de même nom doivent être Implémentation de fonctions similaires avec différents types de données

Remarque : si seule la valeur de retour est différente et que tout le reste est identique, cela ne constitue pas une surcharge de fonction.

2. Le principe de surcharge des fonctions C++
Pourquoi C++ prend-il en charge la surcharge de fonctions, mais pas le langage C ?
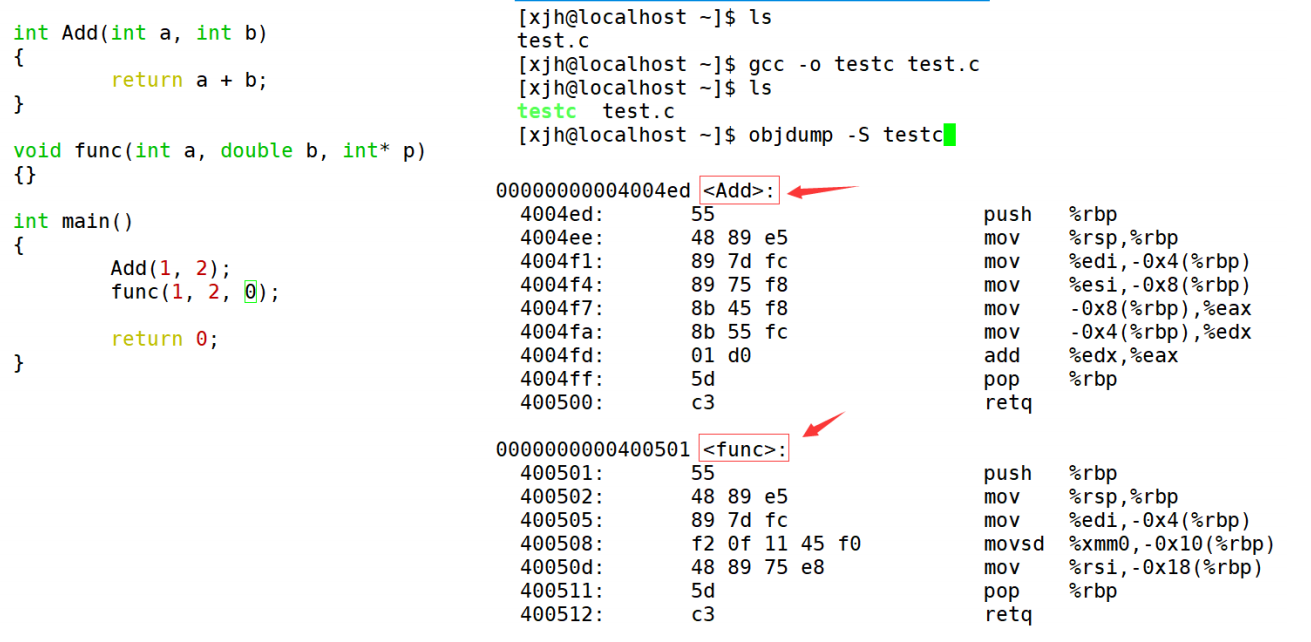
Ici nous allons revoir les connaissances précédentes, avant de passer à l'exécutable, il faut passer par : précompiler, compiler, assembler, lier ces étapes
En fait, le problème réside dans l'étape d'assemblage après la compilation, car les langages C++ et C sont ici légèrement différents.
Après compilation avec le compilateur de langage C
Après compilation avec le compilateur C++
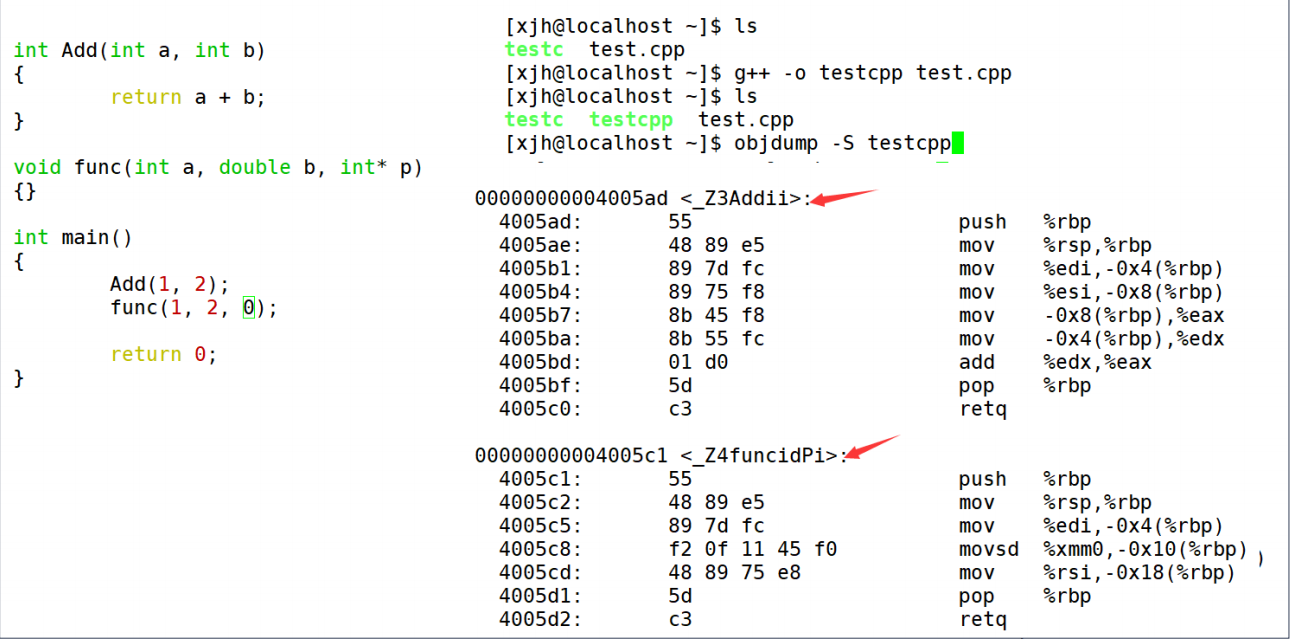
Résumer:
-
En fait, en dernière analyse, c'est parce que le compilateur C et le compilateur C++ décorent différemment les noms de fonction. Les règles de modification sous gcc sont : [_Z + longueur de la fonction + nom de la fonction +
première lettre du type]. -
Cela nous indique en fait pourquoi le type de retour de la fonction est différent et ne constitue pas une surcharge de la fonction, car les règles de décoration ne sont pas affectées par la valeur de retour.
3, "C" externe
Parfois, dans un projet C++, il peut être nécessaire de compiler certaines fonctions selon le style C, en ajoutant extern "C" avant la fonction, ce qui signifie dire au compilateur,
Cette fonction est compilée selon les règles du langage C. Par exemple : tcmalloc est un projet implémenté par google en C++, qui fournit tcmallc() et tcfree
Deux interfaces sont utilisées, mais s'il s'agit d'un projet C, il ne peut pas être utilisé, il utilise donc un "C" externe pour le résoudre.
Nine, les bases de l'entrée C++ - référence
1. Devis
La référence n'est pas de définir une nouvelle variable, mais de prendre un alias pour la variable existante Le compilateur n'ouvrira pas d'espace mémoire pour la variable de référence, il partage le même espace mémoire avec
la variable qu'il référence .
type & nom de la variable de référence (nom de l'objet) = entité de référence ;

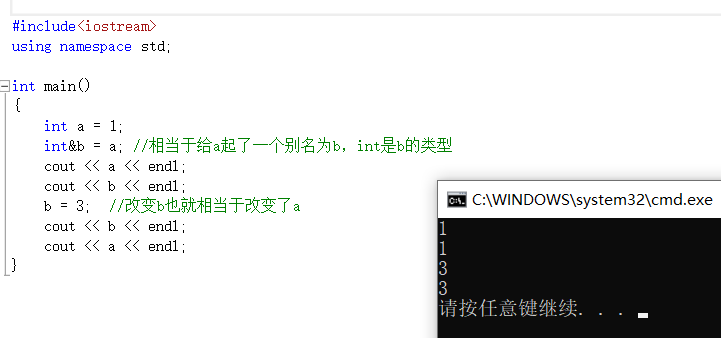
Remarque : Le type de référence doit être du même type que l'entité de référence
2. Caractéristiques de référence
-
Les références doivent être initialisées lorsqu'elles sont définies

-
Une variable peut avoir plusieurs références

-
Une fois qu'une référence fait référence à une entité, elle ne peut pas faire référence à une autre entité

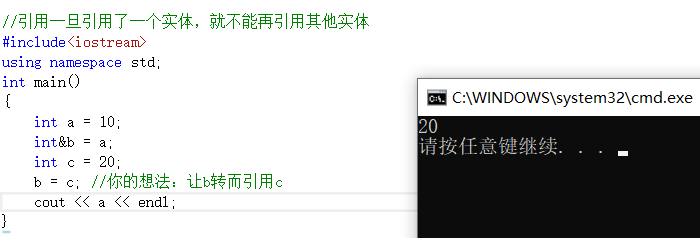
Mais l'effet réel est que la valeur de c est bien assignée à b, et parce que b est une référence à a, la valeur de a devient 20.
3. Souvent cité
Comme mentionné ci-dessus, le type de référence doit être du même type que l'entité de référence. Mais le même type ne garantit pas le succès de la référence. Ici, nous devons également faire attention à la question de savoir si elle peut être modifiée.

Ici a, b, d sont tous des constantes, et les constantes ne peuvent pas être modifiées, mais si vous utilisez int&ra pour faire référence à a, le a référencé peut être modifié, il y aura donc des problèmes.
Regardons ce bout de code :

Cette citation est-elle correcte ? Pour comprendre ce problème, nous devons d'abord comprendre le problème de la promotion de type ermite. Ici, il y a une promotion de type ermite de int à double, et pendant le processus de promotion, le système créera une zone constante pour stocker le résultat d'une promotion de type . Donc ici, ce code est faux à première vue, car a est stocké dans la zone constante lorsque votre type ermite est promu, et la zone constante n'est pas modifiable, et vous utilisez double&ra pour y faire référence, la référence de ra peut être modifiée .
L'ajout d'un const peut résoudre ce problème.

Remarque : Il n'est pas possible de faire référence à une quantité non modifiable comme une quantité lisible et inscriptible, mais l'inverse est possible, et il est possible de faire référence à une quantité lisible et inscriptible comme une quantité lisible.
4. Scénarios d'utilisation de référence
-
référence comme paramètre
Rappelez-vous la fonction d'échange dans le langage C. Lors de l'apprentissage du langage C, la fonction d'échange est souvent utilisée pour illustrer la différence entre le passage par valeur et le passage par référence. Maintenant que nous avons appris les références, nous pouvons utiliser des pointeurs comme paramètres. Parce qu'ici a et b sont des références aux arguments entrants, nous échangeons les valeurs de a et b, ce qui équivaut à échanger les deux arguments entrants.

-
référence comme valeur de retour
Bien sûr, les références peuvent également être utilisées comme valeurs de retour, mais nous devons prêter une attention particulière au fait que les données que nous retournons ne peuvent pas être des variables locales ordinaires créées à l'intérieur de la fonction, car les variables locales ordinaires définies à l'intérieur de la fonction seront détruites avec la fin de l'appel de la fonction. Les données que nous renvoyons doivent être modifiées statiquement ou créées dynamiquement ou des variables globales et d'autres données qui ne seront pas détruites à la fin de l'appel de fonction.
Conséquences de ne pas ajouter de statique
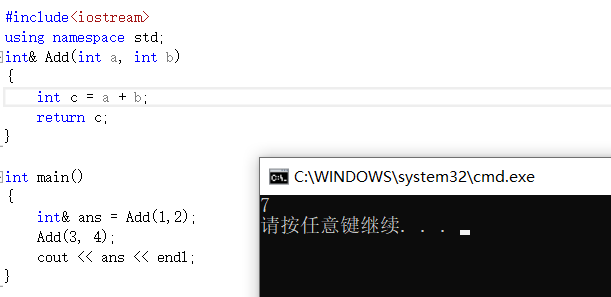
Vous vous demandez pourquoi il imprime 7 au lieu de 2 ?
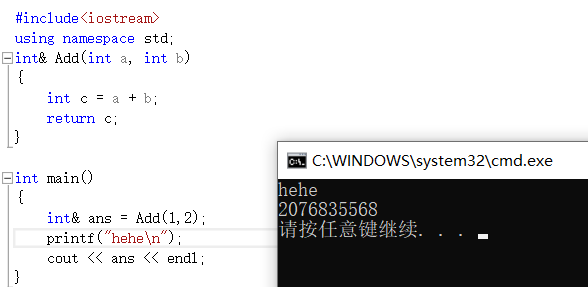
C'est encore plus étrange, pourquoi ajouter un printf au milieu pour imprimer des valeurs aléatoires ?
Voyons l'analyse :
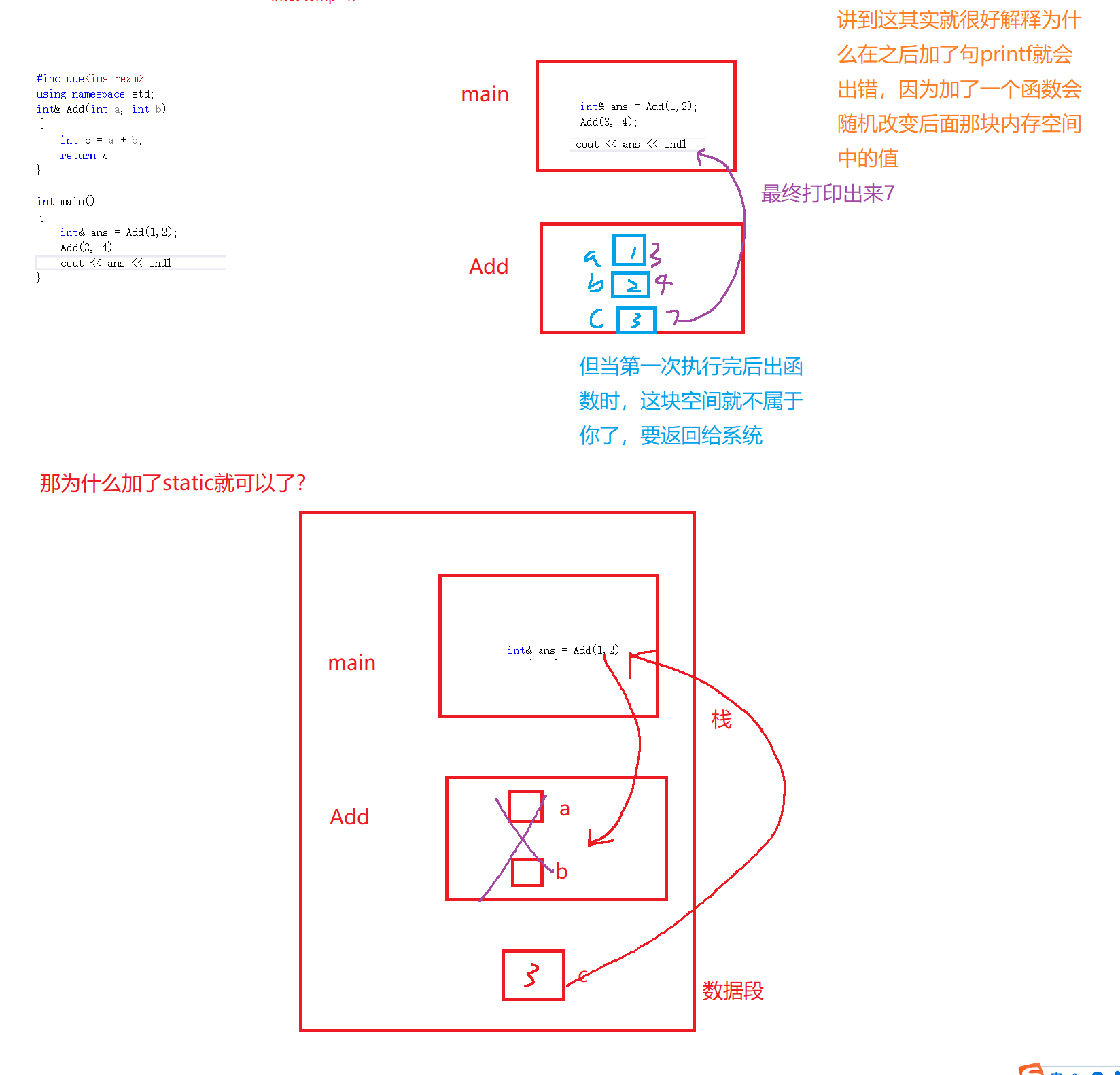
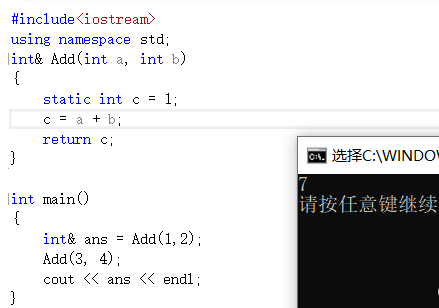
Pourquoi la valeur aléatoire apparaît-elle ? Parce que la variable que vous définissez dans la fonction est une variable temporaire et que la fonction sera détruite lorsqu'elle quittera la fonction. À ce moment, elle pointe au hasard vers un espace dans la mémoire . Par conséquent, il est préférable d'ajouter static aux variables définies dans la fonction lors du référencement en tant que valeur de retour de la fonction.
À ce stade, pensez-vous vraiment comprendre ce code ?


Peut-être serez-vous curieux ? Pourquoi est-il 3 ici? Voyons l'analyse

En fait, si vous changez la façon d'écrire, le résultat ici sera changé en 7. La raison est également très simple, c'est la raison mentionnée dans l'image ci-dessus.
Remarque : Si la fonction sort de la portée de la fonction et que l'objet renvoyé n'a pas été renvoyé au système, vous pouvez utiliser la référence à renvoyer ; s'il a été renvoyé au système, vous devez utiliser le retour par valeur.
Cette phrase dit l'exemple suivant :

Pensez-vous que ce retour par référence est bizarre à utiliser, analysons comment il est retourné.

Résumer:传值的过程中会产生一个拷贝,而传引用的过程中不会,其实在做函数参数时也具有这个特点。
5. Différence entre référence et pointeur
En termes de syntaxe, une référence est un alias, qui n'a pas d'espace indépendant et partage le même espace avec son entité de référence.


Il y a en fait de l'espace dans l'implémentation sous-jacente, car les références sont implémentées sous forme de pointeurs.

Jetons un coup d'œil à la comparaison du code assembleur des références et des pointeurs

Différence entre référence et pointeur
-
Les références doivent être initialisées lorsqu'elles sont définies, les pointeurs ne sont pas nécessaires.
-
Une fois qu'une référence fait référence à une entité lorsqu'elle est initialisée, elle ne peut pas faire référence à d'autres entités et un pointeur peut pointer vers n'importe quelle entité du même type à tout moment.
-
Il n'y a pas de références NULL, mais il y a des pointeurs NULL.
-
La signification de sizeof est différente : le résultat de la référence est la taille du type de référence, mais le pointeur est toujours le nombre d'octets occupés par l'espace d'adressage (4 octets sur une plate-forme 32 bits).
-
L'opération d'auto-incrémentation de la référence équivaut à augmenter l'entité de 1, et l'opération d'auto-incrémentation du pointeur consiste à décaler le pointeur de la taille d'un type.
-
Il existe plusieurs niveaux de pointeurs, mais pas plusieurs niveaux de références.
-
Les entités sont accessibles différemment, les pointeurs doivent être déréférencés explicitement et les références sont gérées par le compilateur lui-même.
-
Les références sont relativement plus sûres à utiliser que les pointeurs.
10. Connaissance de base de l'entrée C++ - fonctions en ligne
1. Conception
Une fonction décorée avec inline est appelée une fonction inline. Lors de la compilation, le compilateur C++ développera l'endroit où la fonction inline est appelée , sans la surcharge de l'empilement de fonctions,
et la fonction inline améliore l'efficacité du fonctionnement du programme. (Quand vous verrez la partie en gras, vos amis penseront certainement, est-ce très similaire à la macro en langage c ?)
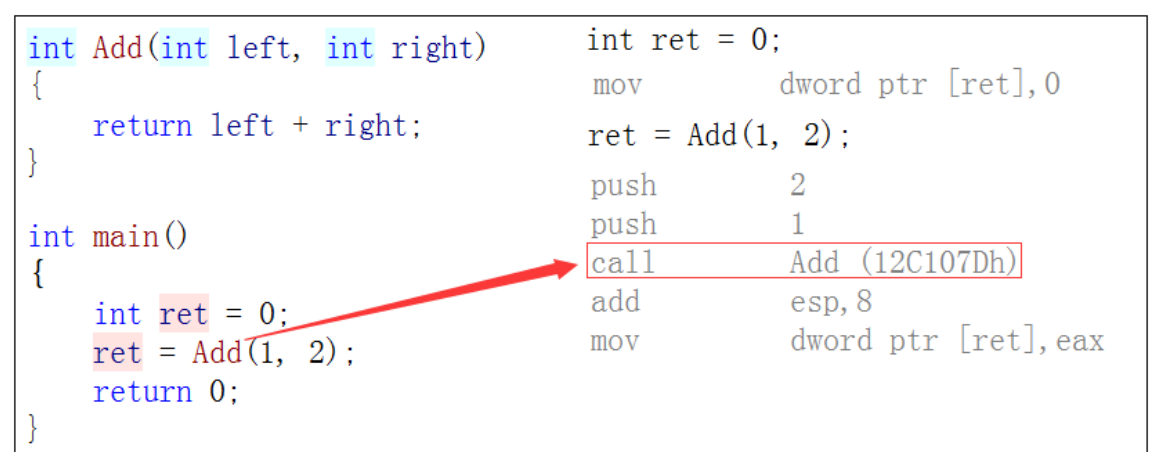
Si vous ajoutez le mot-clé inline avant la fonction ci-dessus pour la transformer en fonction inline, le compilateur remplacera l'appel de fonction par le corps de la fonction lors de la compilation
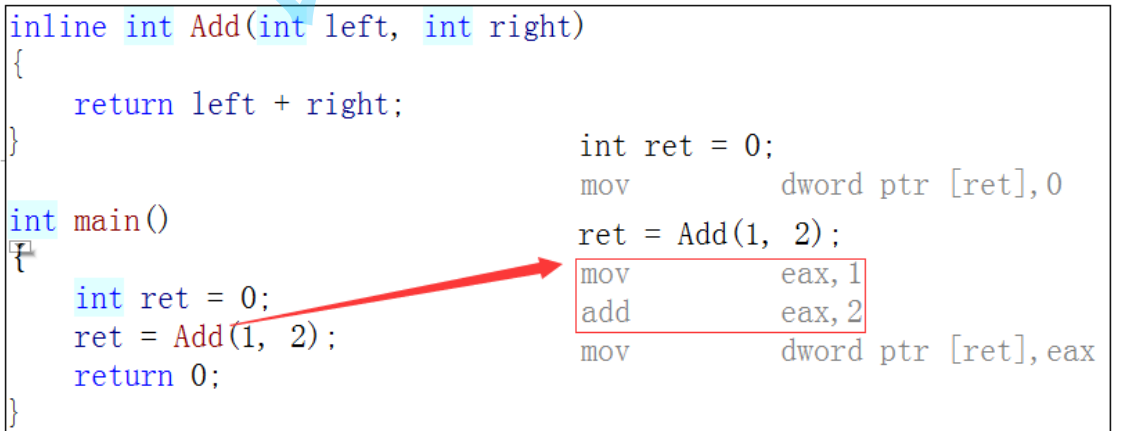
2. Caractéristiques
-
Inline est un moyen d'échanger de l'espace contre du temps, en éliminant la surcharge des fonctions d'appel. Ainsi, les fonctions de code/récursives longues ne conviennent pas à une utilisation en tant que fonctions en ligne.
-
Inline est juste une suggestion pour le compilateur, et le compilateur l'optimisera automatiquement. Si le code du corps de la fonction définie comme inline est relativement long/récursif, etc., le compilateur ignorera l'inline lors de l'optimisation.
-
Inline ne recommande pas la séparation des déclarations et des définitions, la séparation entraînera des erreurs de lien. Étant donné que l'inline est développé, il n'y a pas d'adresse de fonction et le lien ne sera pas trouvé.
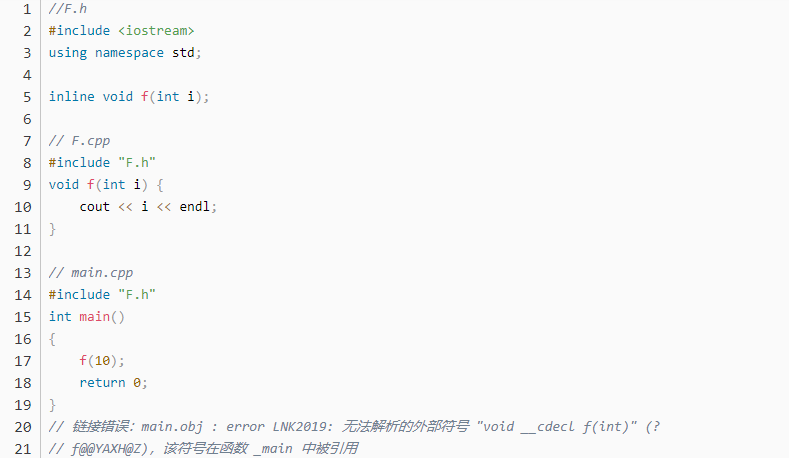
Quelles sont les techniques pour C++ pour remplacer les macros
-
Remplacer la définition constante par const
-
Remplacer les définitions de fonction par des fonctions en ligne
Onze, mot-clé auto (C++11)
Aux débuts du C/C++, le sens de auto était : une variable décorée avec auto est une variable locale à stockage automatique, mais malheureusement personne ne l'a jamais utilisée.
En C++11, le comité standard a donné à auto une nouvelle signification : auto n'est plus un indicateur de type de stockage, mais un nouvel indicateur de type pour indiquer au compilateur que les variables déclarées par auto doivent être compilées par le compilateur dérivé au fil du temps. Vous ne comprendrez peut-être pas rien qu'en lisant cette phrase. Donnons quelques exemples.
#include<iostream>
using namespace std;
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = TestAuto();
cout << typeid(b).name() << endl; //这个地方要学到后面类的时候才可以解释,这里打印出的是类型名
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << a << endl;
cout << b<< endl;
cout << c << endl;
cout << d << endl;
//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化
return 0;
}
Remarque : Lorsque vous utilisez auto pour définir une variable, celle-ci doit être initialisée. Lors de la phase de compilation, le compilateur doit déduire le type réel d'auto en fonction de l'expression d'initialisation. Par conséquent, auto n'est pas une déclaration de "type", mais un "espace réservé" lorsqu'un type est déclaré. Le compilateur remplacera auto par le
type réel de la variable au moment de la compilation.
1. Règles d'utilisation de l'auto
-
auto est utilisé conjointement avec des pointeurs et des références
Lors de la déclaration d'un type pointeur avec auto, il n'y a pas de différence entre auto et auto*, mais lors de la déclaration d'un type référence avec auto, vous devez ajouter &

Remarque : Lorsque vous déclarez une référence avec auto, vous devez ajouter &, sinon, cela créera simplement une variable ordinaire du même type que l'entité, mais changera son nom.
-
Définir plusieurs variables sur la même ligne
Lors de la déclaration de plusieurs variables sur la même ligne, ces variables doivent être du même type, sinon le compilateur signalera une erreur, car le compilateur ne
déduit en fait que le premier type, puis définit d'autres variables avec le type déduit.

2. Scénarios que l'auto ne peut pas déduire
-
auto comme paramètre de fonction

-
auto ne peut pas être utilisé directement pour déclarer un tableau

Afin d'éviter toute confusion avec auto en C++98, C++11 ne retient que l'utilisation de auto comme indicateur de type
. L'avantage le plus courant d'auto en pratique est le nouveau style fourni par C++11, qui sera Les boucles For, les expressions lambda, etc. peuvent être utilisées ensemble.
12. Connaissance de base de la boucle for basée sur la plage d'entrées C++ (C++11)
1. La syntaxe de range pour
En C++98, si vous souhaitez parcourir un tableau, vous pouvez le faire comme suit :

Pour une collection étendue, il est redondant et parfois source d'erreurs pour le programmeur de spécifier l'étendue de la boucle. Donc en C++11
Une boucle for basée sur la plage a été introduite. Les parenthèses après la boucle for sont divisées en deux parties par les deux-points ":": : la première partie est la variable dans la plage utilisée pour l'itération, et la deuxième partie représente la plage à itérer.
Notez qu'il ne peut pas être écrit comme auto, sinon le tableau d'origine ne peut pas être modifié
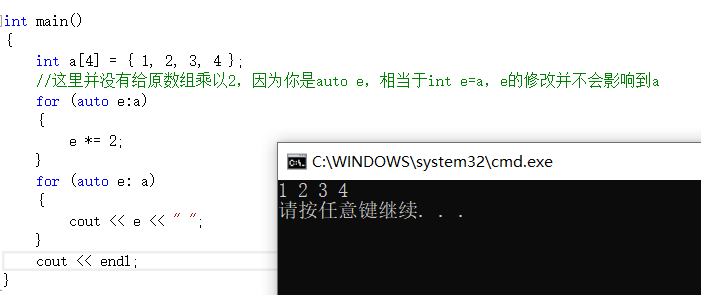
bonne orthographe

Remarque : Semblable aux boucles ordinaires, vous pouvez utiliser continue pour terminer la boucle en cours, et vous pouvez également utiliser break pour sortir de la boucle entière.
2. Conditions d'utilisation du champ d'application
-
La plage de l'itération de la boucle for doit être déterministe
Pour un tableau, il s'agit de la plage du premier élément et du dernier élément du tableau ; pour une classe, les
méthodes begin et end doivent être fournies, et begin et end sont la plage de l'itération de la boucle for.
Remarque : Le code suivant est problématique car la portée de for est indéterminée

-
L'objet itérable implémente les opérations de ++ et ==.
À propos de l'itérateur, j'en parlerai plus tard, mais maintenant vous pouvez le comprendre.
Treize, base d'entrée C++ - valeur nulle du pointeur nullptr
1. Valeur nulle du pointeur en C++98
Dans les bonnes pratiques de programmation C/C++, lors de la déclaration d'une variable, il est préférable de donner à la variable une valeur initiale appropriée, sinon des erreurs imprévisibles peuvent se produire. Par exemple, pour les pointeurs non initialisés, si un pointeur n'a pas de pointeur légal, nous l'initialisons essentiellement comme suit :

NULL est en fait une macro. Vous pouvez voir le code suivant dans le fichier d'en-tête C traditionnel (stddef.h) :

Comme vous pouvez le voir, NULL peut être défini comme une constante littérale 0, ou comme une constante avec un pointeur non typé (void*). Quelle que soit la définition que vous prenez, vous rencontrerez inévitablement des problèmes lors de l'utilisation de pointeurs avec des valeurs nulles, telles que :

L'intention originale du programme est d'appeler la version pointeur de la fonction Fun(int* p) via Fun(NULL), mais puisque NULL est défini comme 0, Fun(NULL) appelle finalement la fonction Fun(int p).
Remarque : En C++98, la constante littérale 0 peut être soit un nombre entier, soit une constante pointeur non typée (void*), mais le compilateur la traite comme une constante entière par défaut, si Pour l'utiliser comme pointeur, elle doit être jeté.
2. Valeur nulle du pointeur en C++11
Pour les problèmes de C++98, C++11 a introduit le mot-clé nullptr.
Lors de l'utilisation de nullptr pour représenter le pointeur null, aucun fichier d'en-tête n'a besoin d'être inclus car nullptr a été introduit en tant que mot-clé dans C++11.
En C++11, sizeof(nullptr) et sizeof((void*)0) occupent le même nombre d'octets, et les deux ont une taille de 4.
finalement
Les connaissances de base de la version PDF d'entrée C++, du didacticiel d'amélioration C++, des livres électroniques C++ peuvent être obtenues comme suit
Attention au compte public WeChat : "C et C plus" Répondre au mot-clé : "C++" pour recevoir