Plusieurs choses que nous négligeons souvent lors du déploiement d'applications sur Kubernetes
Entretien Scofield novice sur le fonctionnement et la maintenance
D'après mon expérience, la plupart des gens (utilisant Helm ou yaml manuel) déploient des applications sur Kubernetes, puis pensent qu'ils peuvent toujours fonctionner de manière stable.
Cependant, ce n'est pas le cas. Le processus d'utilisation actuel rencontrait encore des "pièges". J'espère lister ces "pièges" ici pour vous aider à comprendre certains problèmes auxquels vous devez faire attention avant de lancer une application sur Kubernetes.
Introduction à la planification Kubernetes
Le planificateur utilise le mécanisme de surveillance de kubernetes pour découvrir les pods nouvellement créés dans le cluster qui n'ont pas encore été planifiés sur le nœud. Le planificateur planifiera chaque pod non planifié trouvé sur un nœud approprié à exécuter. En tant que planificateur par défaut du cluster, kube-scheduler sélectionnera un nœud optimal pour exécuter le pod pour chaque pod nouvellement créé ou pod non planifié. Cependant, chaque conteneur du pod a des exigences différentes en matière de ressources, et le pod lui-même a également des besoins en ressources différents. Par conséquent, avant que le pod ne soit planifié sur le nœud, il est nécessaire de filtrer les nœuds du cluster en fonction de ces exigences de planification des ressources spécifiques.
Dans un cluster, tous les nœuds qui satisfont une demande de planification de pod sont appelés nœuds programmables. Si aucun nœud ne peut satisfaire la demande de ressources du pod, le pod restera dans l'état non planifié jusqu'à ce que le planificateur trouve un nœud approprié.
Les facteurs à prendre en compte lors de la prise de décisions de planification comprennent: les demandes de ressources individuelles et globales, les restrictions matérielles / logicielles / politiques, les exigences d'affinité et d'anti-affinité, la localité des données, les interférences entre les charges, etc. Veuillez consulter le site officiel pour plus d'informations sur la planification
Requêtes et limites de pod
Regardons un exemple simple, ici seulement intercepter une partie des informations yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
resources:
limits:
memory: "100Mi"
cpu: 100m
requests:
memory: "1000Mi"
cpu: 100mPar défaut, nous créons un fichier de déploiement de service. Si vous n'écrivez pas le champ de ressources, le cluster Kubernetes utilisera la stratégie par défaut et n'imposera aucune restriction de ressources sur le pod, ce qui signifie que le pod peut utiliser la mémoire et les ressources du processeur. du nœud Node à volonté. Mais cela posera un problème: la contention des ressources.
Par exemple: un nœud Node a une mémoire 8G et deux pods y sont exécutés.
Au début de l'opération, les deux pods n'ont besoin que de mémoire 2G pour fonctionner. Il n'y a pas de problème pour le moment, mais si l'un des pods augmente soudainement à 7G en raison d'une fuite de mémoire ou si le processus augmente soudainement, la mémoire 8G de Node est évidemment pas assez pour le moment. Cela entraînera des services extrêmement lents ou indisponibles.
Par conséquent, dans des circonstances normales, lorsque nous déployons des services, nous devons limiter les ressources du pod pour éviter des problèmes similaires.
Comme indiqué dans l'exemple de fichier, des ressources doivent être ajoutées;
requests: 表示运行服务所需要的最少资源,本例为需要内存100Mi,CPU 100m
limits: 表示服务能使用的最大资源,本例最大资源限制在内存1000Mi,CPU 100mQu'est-ce que cela signifie? Une image vaut mieux que mille mots.
PS: @@@ 画图 J'ai vraiment fait de mon mieux @@@
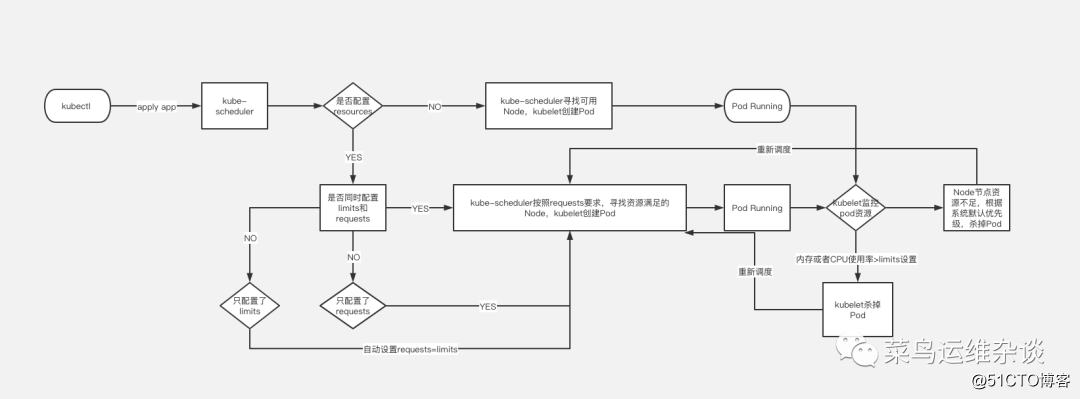
Sondes de vivacité et de préparation
Un autre sujet brûlant souvent discuté dans la communauté Kubernetes. La maîtrise des sondes de vivacité et de préparation est très importante car elles fournissent un mécanisme permettant d'exécuter des logiciels tolérants aux pannes et de minimiser les temps d'arrêt. Cependant, si la configuration n'est pas correcte, ils peuvent avoir un impact sérieux sur les performances de votre application. Voici un résumé de ces deux sondes et comment les raisonner:
Sonde de vivacité: détecte si le conteneur est en cours d'exécution. Si la sonde d'activité échoue, le kubelet tuera le conteneur et le conteneur acceptera sa stratégie de redémarrage. Si le "conteneur" ne fournit pas de sonde d'activité, l'état par défaut est "succès".
Étant donné que la sonde Liveness s'exécute plus fréquemment, les paramètres sont aussi simples que possible. Par exemple, si vous la définissez pour qu'elle s'exécute une fois par seconde, une demande supplémentaire sera ajoutée par seconde, vous devez donc prendre en compte les ressources supplémentaires requises pour cela. demander. Habituellement, nous fournissons une interface de vérification de l'état de Liveness, qui renvoie un code de réponse de 200 pour indiquer que votre processus a démarré et peut traiter les demandes.
Sonde de disponibilité: détecte si le conteneur est prêt à traiter la demande. Si la sonde prête échoue, le point de terminaison supprimera l'adresse IP du pod des points de terminaison de tous les services qui correspondent au pod.
Les exigences d'inspection de la sonde Readiness sont relativement élevées, car elles indiquent que l'application entière est en cours d'exécution et prête à recevoir des demandes. Pour certaines applications, la demande ne sera acceptée qu'une fois l'enregistrement renvoyé de la base de données. En utilisant des sondes de préparation bien pensées, nous sommes en mesure d'atteindre des niveaux de disponibilité plus élevés et un déploiement sans temps d'arrêt.
Les méthodes de détection des sondes de vivacité et de préparation sont les mêmes, il existe trois
- Définissez la commande de survie:
si la commande est exécutée avec succès et que la valeur de retour est égale à zéro, Kubernetes considère que cette détection est réussie; si la valeur de retour de la commande est différente de zéro, cette détection de vivacité échoue. - Définissez une interface de requête HTTP en direct;
envoyez une requête HTTP et retournez tout code de retour supérieur ou égal à 200 et inférieur à 400 pour indiquer le succès, et les autres codes de retour indiquent un échec. - Définissez la détection de survie TCP
pour envoyer une requête tcpSocket au port d'exécution, si elle peut être connectée, cela signifie succès, sinon elle échoue.
Regardons un exemple, voici la détection de survie TCP courante à titre d'exemple
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10livenessProbe 部分定义如何执行 Liveness 探测:
1. 探测的方法是:通过tcpSocket连接nginx的80端口。如果执行成功,返回值为零,Kubernetes 则认为本次 Liveness 探测成功;如果命令返回值非零,本次 Liveness 探测失败。
2. initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 探测,一般会根据应用启动的准备时间来设置。比如应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
3. periodSeconds: 10 指定每 10 秒执行一次 Liveness 探测。Kubernetes 如果连续执行 3 次 Liveness 探测均失败,则会杀掉并重启容器。
readinessProbe 探测一样,但是 readiness 的 READY 状态会经历了如下变化:
1. 刚被创建时,READY 状态为不可用。
2. 20 秒后(initialDelaySeconds + periodSeconds),第一次进行 Readiness 探测并成功返回,设置 READY 为可用。
3. 如果Kubernetes连续 3 次 Readiness 探测均失败后,READY 被设置为不可用。Définir la stratégie réseau par défaut pour le pod
Kubernetes utilise une topologie de réseau "plate". Par défaut, tous les pods peuvent communiquer directement entre eux. Mais dans certains cas, nous ne voulons pas de cela, ou même inutile. Il y aura des risques de sécurité potentiels. Par exemple, si une application vulnérable est utilisée, elle peut fournir au pirate un accès complet pour envoyer du trafic à tous les pods du réseau. Comme dans de nombreux domaines de la sécurité, la stratégie d'accès minimum s'applique également à cela. Idéalement, une stratégie réseau sera créée pour spécifier clairement les connexions de conteneur à conteneur autorisées.
Par exemple, ce qui suit est une stratégie simple qui refusera tout le trafic entrant dans un espace de noms spécifique
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-ingress-flow
spec:
podSelector: {}
policyTypes:
- IngressSchéma de principe de cette configuration
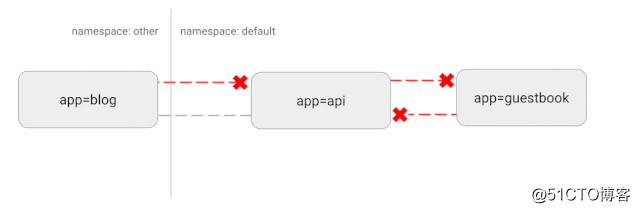
Comportement personnalisé via les Hooks et les conteneurs d'initialisation
L'un de nos principaux objectifs en utilisant le système Kubernetes est d'essayer de fournir aux développeurs prêts à l'emploi un déploiement aussi nul que possible. Cela est difficile en raison des différentes façons dont une application s'arrête et nettoie les ressources utilisées. Une application que nous avons rencontrée particulièrement difficile était Nginx. Nous avons remarqué que lorsque nous avons commencé le déploiement progressif de ces pods, les connexions actives ont été abandonnées avant d'être interrompues avec succès. Après des recherches approfondies en ligne, il s'avère que Kubernetes n'attend pas que Nginx vidange ses connexions avant de terminer le pod. En utilisant le crochet de pré-arrêt, nous avons pu injecter cette fonctionnalité et obtenu aucun temps d'arrêt avec ce changement.
Normalement, par exemple, nous souhaitons effectuer une mise à niveau progressive vers Nginx, mais Kubernetes n'attend pas que Nginx mette fin à la connexion avant d'arrêter le pod. Cela empêchera le nginx arrêté de fermer correctement toutes les connexions, ce qui est déraisonnable. Nous devons donc utiliser des crochets avant de nous arrêter pour résoudre de tels problèmes.
Nous pouvons ajouter un cycle de vie au fichier de déploiement
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
nginx-killer.sh
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
doneDe cette façon, Kubernetes exécutera le script nginx-killer.sh avant de fermer le pod pour fermer nginx de la manière que nous avons définie
Une autre situation consiste à utiliser le conteneur d'initialisation.
Le conteneur d'initialisation est le conteneur utilisé pour l'initialisation. Il peut y en avoir un ou plusieurs. S'il y en a plusieurs, ces conteneurs seront exécutés dans un ordre défini. Uniquement après l'exécution de tous les conteneurs d'initialisation. , Le conteneur principal démarre.
Par exemple:
initContainers:
- name: init
image: busybox
command: ["chmod","777","-R","/var/www/html"]
imagePullPolicy: Always
volumeMounts:
- name: volume
mountPath: /var/www/html
containers:
- name: nginx-demo
image: nginx
ports:
- containerPort: 80
name: port
volumeMounts:
- name: volume
mountPath: /var/www/htmlNous avons monté un disque de données dans / var / www / html de nginx. Avant que le conteneur principal ne s'exécute, nous avons changé l'autorisation de / var / www / html en 777 afin qu'il n'y ait aucun problème d'autorisation lorsque le conteneur principal était utilisé.
Bien sûr, ce n'est qu'un peu de châtaigne.Init Container a des fonctions plus puissantes, comme la configuration initiale. . .
Réglage du noyau (optimisation des paramètres du noyau)
Enfin, laissant à la fin des technologies plus avancées, haha
Kubernetes est une plate-forme très flexible conçue pour vous permettre d'exécuter des services comme bon vous semble. Habituellement, si nous avons des services hautes performances et que nous avons des exigences de ressources strictes, telles que les redis communs, les invites suivantes s'afficheront après le démarrage.
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.Cela nous oblige à modifier les paramètres du noyau du système. Heureusement, Kubernetes nous permet d'exécuter un conteneur privilégié qui peut modifier les paramètres du noyau qui ne sont applicables qu'à des pods en cours d'exécution spécifiques. Voici un exemple que nous avons utilisé pour modifier le paramètre / proc / sys / net / core / somaxconn.
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "echo 511 > /proc/sys/net/core/somaxconn"]Pour résumer
Bien que Kubernetes fournisse une solution prête à l'emploi, il vous oblige également à prendre certaines mesures clés pour assurer le fonctionnement stable du programme. Avant la mise en ligne du programme, assurez-vous de réaliser plusieurs tests, d'observer les indicateurs clés et d'effectuer des ajustements en temps réel.
Avant de déployer le service sur le cluster Kubernetes, nous pouvons nous poser quelques questions:
- De combien de ressources notre programme a-t-il besoin, comme la mémoire, le processeur, etc.?
- Quel est le trafic moyen du service et quel est le trafic de pointe?
- Combien de temps voulons-nous que le service se développe et combien de temps faudra-t-il aux nouveaux pods pour accepter le trafic?
- Notre Pod est-il arrêté normalement? Comment le faire sans affecter les services en ligne?
- Comment pouvons-nous nous assurer que les problèmes avec nos services n'affecteront pas les autres services et n'entraîneront pas de temps d'arrêt de service à grande échelle?
- Notre autorité est-elle trop grande? est-ce sûr?
Enfin fini, woo woo woo~ C'est si difficile~
Picture
PS: les articles de suivi seront synchronisés avec dev.kubeops.net
Remarque: les images de l'article proviennent d'Internet. En cas d'infraction, veuillez me contacter pour la supprimer à temps.