FaaS et conteneurs
En raison de son innovation disruptive, les images de conteneurs sont devenues la norme de facto pour les formats de déploiement d'applications à l'ère du cloud natif. Les services FaaS (Function-as-a-Service) des principaux fournisseurs de cloud, tels que Alibaba Cloud Function Computing et AWS Lambda, prendront également en charge l'utilisation des fonctions de déploiement d'images de conteneurs en 2020, englobant pleinement l'écosystème des conteneurs. Depuis sa sortie, les développeurs ont successivement utilisé la mise en miroir pour rapidement plusieurs scénarios sans serveur tels que l'apprentissage automatique, le traitement audio et vidéo, le traitement de données hors ligne basé sur les événements et l'automatisation frontale pour améliorer l'efficacité et réduire les coûts. Cependant, le démarrage à froid a toujours été un problème que Serverless ne peut pas contourner. La mise en miroir de conteneurs doit télécharger et décompresser les données à distance via le réseau. Pour les miroirs de niveau Go, le temps d'extraction peut atteindre quelques minutes, ce qui amplifie objectivement l'effet secondaire du démarrage à froid et entrave l'évolution sans serveur des applications en temps réel.
Fonction d'accélération du miroir de calcul de la fonction
L'accélération traditionnelle de l'extraction d'image met l'accent sur la «responsabilité du développeur», comme la rationalisation de l'image, l'attribution raisonnable de la couche d'image, la construction en plusieurs étapes, l'utilisation d'outils (tels que docker-slim) pour supprimer les données inutiles et le respect des meilleures pratiques de construction. Ces tâches augmentent non seulement la charge des utilisateurs, mais ont également des effets d'accélération limités et des risques de stabilité à l'exécution. L'environnement de conteneurs à très grande échelle du groupe Alibaba avec des scénarios très complexes a une accumulation profonde de technologies de stockage d'images et d'accélération, et a réussi à relever le double onze, le double douze et la fête du printemps et d'autres défis à grande échelle pour tuer les pics . Alibaba Cloud Serverless coopère en profondeur avec des services tels que la mise en miroir et le stockage de conteneurs, et produit des innovations internes dans les calculs de fonctions: Hangzhou, Pékin, Shanghai, l'Amérique de l'Est et l'Amérique de l'Ouest ont officiellement publié des fonctions d'accélération de mise en miroir. Cette fonction transfère le fardeau de l'optimisation de la mise en miroir qui appartenait à l'origine aux développeurs à l'informatique fonctionnelle, et aide en outre les développeurs à améliorer l'efficacité de la production et à se concentrer sur l'innovation commerciale.
Effet d'accélération
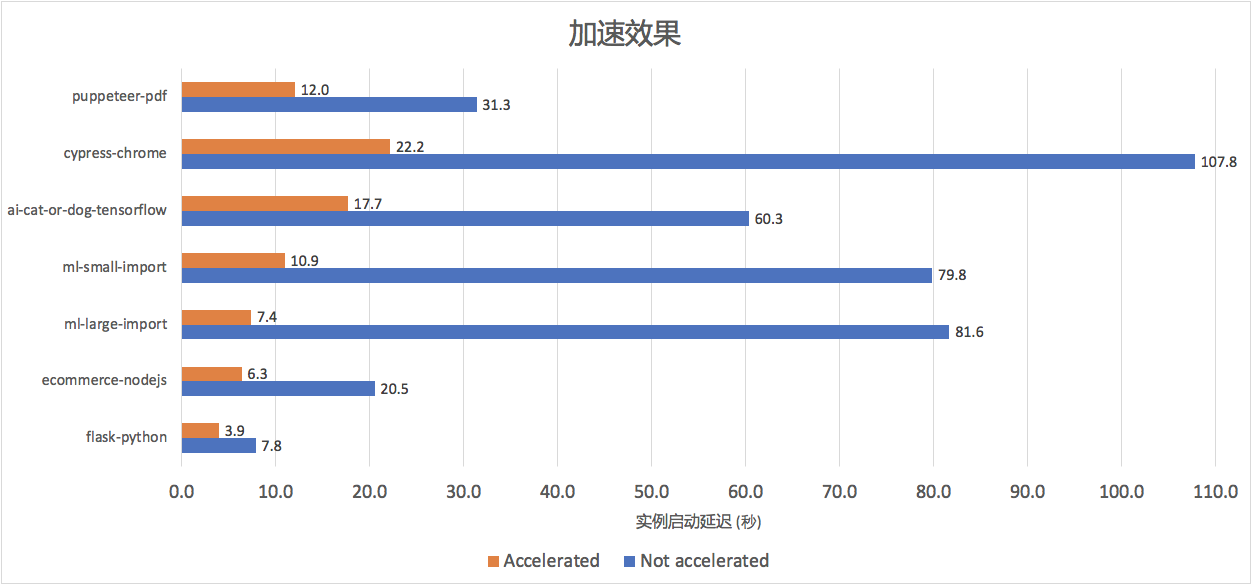
Nous avons sélectionné l'environnement de production interne et la charge de travail de la communauté open source, couvrant sept combinaisons différentes de tailles d'image, de modes d'accès IO et de commandes de démarrage, y compris l'apprentissage automatique, l'intelligence artificielle, l'automatisation frontale et les applications Web, comme référence. , et les a déployés dans la région du FC Beijing. Comme le montre la figure ci-dessous, l'accélération du calcul de la fonction après l'activation de la fonction d'accélération du miroir dépasse généralement 50%. Pour les miroirs gonflés courants dans les scénarios d'apprentissage automatique (par exemple, plusieurs équipes partageant des miroirs de base, ml-small-import, ml-large L'effet d'accélération -import, ai- chat-ou-chien) est plus évident (environ 70% -86%), plus l'image miroir est grande, plus l'espace d'optimisation est élevé.

Comment utiliser
L'accélération d'image peut être activée via la console, l'outil CLI ou le SDK FC. Pour connaître les étapes détaillées, reportez-vous au document d'accélération d'extraction d'image.
• Méthode 1: sélectionnez «Activer l'accélération du miroir» dans la configuration des fonctions de la console de calcul des fonctions.

• Méthode 2: utiliser l’outil Funcraft pour déployer
Ajouter AccelerationType: Default sous la configuration CustomContainerConfig existante, configurez AccelerationType:
None si vous souhaitez le fermer
CustomContainerConfig:
Image: registry-vpc.cn-beijing.aliyuncs.com/fc-demo/python-flask:v0.1
AccelerationType: DefaultFonctionnalités
L'accélération du miroir FC présente les caractéristiques suivantes:
- Facile à utiliser: il suffit d'activer l'accélération d'image sur la fonction, et le calcul de la fonction créera automatiquement une image accélérée et un cache.Une fois la conversion terminée (dans les 5 minutes), la fonction utilise automatiquement le cache d'image accélérée.
- Concentrez-vous sur l'innovation métier: les développeurs n'ont pas besoin de passer du temps à simplifier et à optimiser délibérément la taille de l'image ou à distinguer strictement les méthodes de construction des images d'application Serverless et Serverfull. FC est responsable de l'extraction et de la décompression des données en fonction de l'utilisation réelle de l'application.
- L'accélération est gratuite et le seuil d'utilisation est bas: il n'y a pas de frais supplémentaires encourus lorsque l'accélération d'image est activée, et il n'est pas nécessaire pour les développeurs d'acheter ou de mettre à niveau d'autres services. En fait, à mesure que le temps d'extraction d'image devient plus court, les frais de demande correspondants sont également réduits.
- Élasticité extrêmement rapide, mise à l'échelle à 0, déclenchement d'événements: FaaS combiné à la mise en miroir de conteneurs a grandement simplifié la migration des applications vers Serverless, et la fonction d'accélération a encore débloqué les charges de travail en temps réel et quasi-temps réel. Conteneurs qui nécessitaient autrefois des minutes pour démarrer peut maintenant être démarré rapidement en quelques secondes. Démarrez et réalisez vraiment la réduction à 0.
Pourquoi la traction du miroir est-elle lente?
Une image de conteneur OCI V1 contient plusieurs couches, et chaque couche est un système de fichiers compressé (dossier), généralement stocké dans un service distant (tel que le stockage d'objets et de fichiers) au format tar.gz. Les étapes pour extraire l'image sont les suivantes:
- Téléchargez le fichier tar.gz correspondant à chaque couche sur le local
- Décompressez chaque couche séquentiellement
- Combinez chaque couche (comme Overlay) en tant que conteneur de démarrage rootfs
Bien que les étapes ci-dessus soient simples, ce sont les principales raisons de la lenteur de l'extraction de l'image:
• Défauts de format de fichier, superposition de données grossières et décompression séquentielle: la couche gzip empêche la lecture aléatoire fine des données réellement nécessaires à l'application , et nécessite que tous les calques soient à thread unique Décompressez séquentiellement. L'observation réelle a révélé que la couche d'image peut augmenter la vitesse grâce au téléchargement simultané, mais le lien de décompression est difficile à optimiser au format gzip.
• Algorithme de compression / décompression inefficace: gzip utilisé dans la couche image, la vitesse de décompression gzip de référence est près de 9 fois plus lente que lz4 en moyenne.
• Téléchargement complet des données: également en raison de la superposition à gros grains et du format gzip (la recherche n'est pas prise en charge), les données en miroir doivent être téléchargées vers le local, qu'elles soient réellement utiles ou non.
En résumé, le temps d'extraction de l'image est directement proportionnel à la taille de l'image, lors de l'exécution d'apt / yum install pendant la construction de l'image du conteneur, des tests et des fichiers de données inutiles et l'exécution de commandes telles que chmod / chown pendant le processus de construction provoque plusieurs copies des mêmes données. Il est facile d'introduire des données qui ne sont pas nécessaires à un grand nombre d'applications.
Principe d'accélération
L'informatique fonctionnelle applique la technologie d'accélération d'image mature du Groupe Alibaba aux services de cloud public. La technologie d'accélération s'articule autour de deux idées fondamentales:
• Chargement à la demande: ne lit que les données réellement nécessaires à l'application, ce qui réduit considérablement la quantité de transmission de données
• Stockage plus efficace Algorithme de somme: même taille de données, décompression plus rapide
Charge à la demande
Le taux de chargement des données du miroir inclus dans Benchmark est compris entre 12% et 84%. À l'exception des applications Web avec des miroirs plus petits, le taux d'utilisation des données de la plupart des scènes est inférieur à 50%. L'image d'origine avec la couche comme unité de distribution de données est convertie en un format de données qui prend en charge la lecture à la demande à granularité fine, et est stockée dans un stockage avec une meilleure latence et un meilleur débit.

Décompression efficace
En plus des économies de retard dans l'étape de téléchargement apportées par le chargement à la demande, la technologie d'accélération d'image a également été largement optimisée dans l'étape de décompression des données. La figure ci-dessous montre que même lorsque plus de 70% des données complètes sont chargées, l'effet d'optimisation dépasse toujours 60%.

plan d'avenir
Function Computing a officiellement lancé l'accélération d'image de conteneur, qui accélère de 50% à 80% dans différents scénarios grâce à la lecture à la demande et à une technologie de décompression plus efficace. Même les images de niveau Go peuvent être démarrées de bout en bout en quelques secondes. La fonction d'accélération, combinée à l'extrême flexibilité du calcul des fonctions et aux caractéristiques de déclenchement d'événements, débloque davantage de charges de travail avec des exigences élevées en temps réel. Les applications de conteneur peuvent plus facilement profiter de la fonctionnalité sans serveur, réduire à zéro et s'étendre rapidement à grande échelle. À l'avenir, FC continuera d'optimiser tous les aspects du démarrage à froid pour offrir une flexibilité extrême, assumer davantage de responsabilités d'utilisateur et permettre aux développeurs de se concentrer sur l'innovation commerciale.
Annexe: Données de la scène expérimentale
| Référence | Scènes | Taille de compression d'image | Taille après décompression |
|---|---|---|---|
| flacon python | application Web | 46 Mo | 118 Mo |
| ecommerce-nodejs | Commerce électronique, nodejs express | 130 Mo | 371 Mo |
| ml-petite-import / ; ml-grande-import | Apprentissage automatique, utilisant numpy, pandas, pystan et d'autres bibliothèques | 728 Mo | 2,392 Go |
| ai-chat-ou-chien | Apprentissage automatique, intelligence artificielle, inférence et prédiction tensorflow, keras et autres bibliothèques | 790 Mo | 1,824 Go |
| marionnettiste-pdf | Chrome sans tête, convertir des pages Web en PDF, utiliser marionnettiste, nodejs express | 332 Mo | 894 Mo |
| cyprès-chrome | Automatisation de l'interface utilisateur frontale, cyprès, chrome sans tête | 980 Mo | 2,608 Go |
référence
• Processus sans serveur d'application d'accélération d'image de conteneur de prise en charge de la fonction informatique
• Nouveau pour AWS Lambda - Prise en charge de l'image de conteneur
• Document d'accélération de l'extraction d'image de calcul de fonction
• Docker Slim: Conteneurs Minify et Secure Docker (gratuits et open source!)
• christopher-talke / node - exemple-express-marionnettiste-pdf
• awesome-fc / custom-container-docs
Informations sur l'auteur: Shuai Chang, expert technique senior de l'équipe Serverless native d'Alibaba Cloud, a dirigé l'intégration écologique de l'informatique fonctionnelle et de la technologie des conteneurs et de l'observabilité native du cloud FaaS.
Cet article est le contenu original d'Alibaba Cloud et ne peut être reproduit sans autorisation.