Environnement d'installation
vérification
127.0.0.1:6379> info
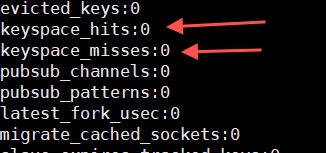
Interroger une clé qui n'existe pas
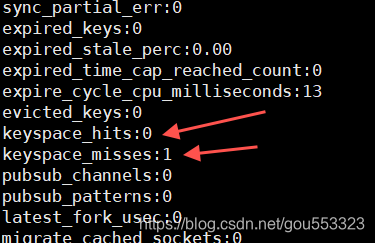
127.0.0.1:6379> get test
(nil)
En regardant le taux de réussite,
insérez un nouveau nom de valeur
127.0.0.1:6379> set name JackMA
OK
Nom de la requête
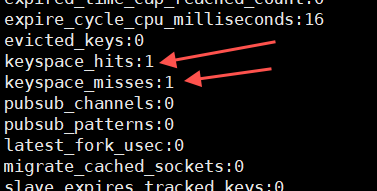
127.0.0.1:6379> get name
"JackMA"
Regardez le taux de réussite
Pour résumer
Le calcul du taux de réussite hit / (hit + miss) A partir de ce seul calcul, tant que toutes les données à interroger sont dans le cache, alors il est de 100%, et il n'est pas nécessaire de faire la distinction entre haute fréquence et basse la fréquence. Dans le cas où certaines données ne sont pas trouvées, plus la molécule est grosse, plus le taux de succès est élevé, c'est-à-dire plus les touches à haute fréquence sont nécessaires, ce qui peut augmenter le taux de succès relativement. Ce que je souhaite clarifier, c'est s'il n'est pas nécessaire de mettre en cache les données d'accès basse fréquence. Auparavant, toutes les données du centre de produits des grandes usines et des centres de produits orientés C étaient mises en cache. Maintenant, dans les petites entreprises, tout d'abord, les données la structure est un ensemble, il n'y a pas de différence entre orienté B et orienté C, et certaines données liées à l'utilisateur, la fréquence d'accès sera certainement très faible, car elle est liée à un seul utilisateur, ces données doivent-elles être mises en cache , ou si elle est simultanée Il est nécessaire de mettre le cache dans de gros cas, et la récupération depuis le cache est nettement plus rapide que mysql.