MF contre MLP
Auteur: Nine Yu, notes d'alchimie de Xiao Bian
Répertoire d'articles
Le modèle d'algorithme de recommandation basé sur Embedding a été un sujet de recherche brûlant ces dernières années, et les résultats de la recherche et de la pratique de l'industrie peuvent être consultés dans les principales revues de conférence internationales. La MF (factorisation matricielle), en tant que méthode traditionnelle basée sur le produit scalaire et l'intégration de combinaisons d'ordre élevé, est largement utilisée dans les systèmes de recommandation. MF est principalement utilisé pour modéliser l'interaction entre l'utilisateur et l'élément, et le calcul du produit interne est utilisé pour les fonctionnalités cachées de l'utilisateur et de l'élément, qui est une méthode linéaire.
L'introduction d'un biais d'utilisateur et d'article pour améliorer l'effet MF montre également que le produit interne n'est pas suffisant pour capturer les informations de structure complexe dans les données d'interaction utilisateur. Par conséquent, dans l'article NCF (Neural Collaborative Filtering), l'auteur introduit une méthode d'apprentissage en profondeur pour décrire la relation entre les caractéristiques de manière non linéaire est un moyen de résoudre ce problème.
Le contenu principal de cet article est le suivant:
1. Dans les mêmes conditions expérimentales, la factorisation matricielle (Matrix Factorization) peut-elle avoir une plus grande amélioration par rapport à MLP (Multi Layer Perceptron) après réglage des paramètres?
2. Bien que MLP puisse aborder n'importe quelle fonction en théorie, cet article compare et analyse la relation d'approximation entre MLP et la fonction de produit scalaire à travers des expériences;
3. Enfin, discutez du coût élevé de la fourniture de services par MLP dans l'environnement de génération en ligne réel.
Que sont les produits dot et MLP?

Produit scalaire
Produit scalaire du vecteur utilisateur UserEmbedding (p sur la figure) et du vecteur d'item ItemEmbedding (q sur la figure).
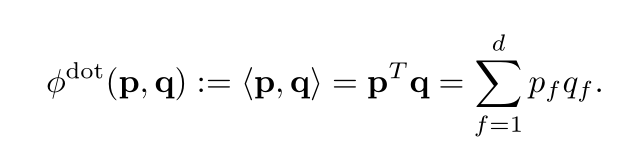
MLP (Perceptron multicouche) et NCF

Dans le document NCF, l'auteur remplace le produit scalaire par MLP et joint le vecteur utilisateur UserEmbedding et le vecteur d'élément ItemEmbedding en entrée.
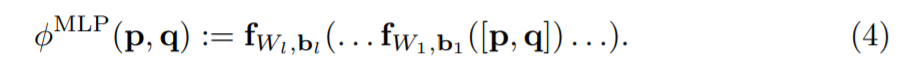
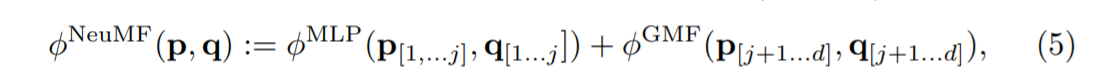
Le réseau NCF peut être décomposé en deux sous-réseaux, l'un est appelé Factorisation matricielle généralisée (GMF), et l'autre est Perceptron multicouche (MLP).

Parmi eux, GMF utilise le vecteur utilisateur UserEmbedding et le vecteur item ItemEmbedding, et utilise le produit Hadamard pour combiner (niveau élément - les éléments de position correspondants dans deux matrices de même taille sont multipliés par exemple: (3x3) ⊙ (3x3) = 3x3), puis Dans la couche entièrement connectée, une combinaison pondérée linéaire est effectuée, c'est-à-dire qu'un vecteur h (vecteur de poids) est entraîné.
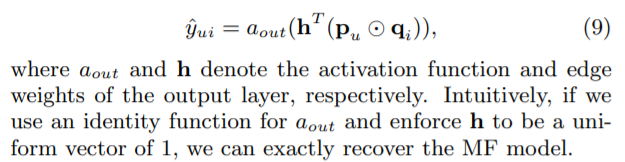
Dans la partie MLP, le vecteur utilisateur UserEmbedding et le vecteur d'élément ItemEmbedding sont assemblés, puis entrent plusieurs couches FC. Puisque l'opération d'épissage de <User, Item> passe à travers la couche FC, ces entités ont subi une combinaison non linéaire suffisante et la sortie finale utilise la fonction sigmoïde.
L'effet du modèle dans le papier d'origine est le suivant:

Produit dot vs MLP
La partie intéressante de cet article est que l'auteur a soulevé une question, le modèle MLP est-il vraiment meilleur que le produit scalaire?
Sur la base de l'introduction ci-dessus, nous aurons une compréhension potentielle que le remplacement du produit scalaire par MLP peut améliorer la capacité d'expression du modèle.Après tout, MLP a la capacité d'adapter des fonctions arbitraires. Dans l'article "Neural Collaborative Filtering vs. Matrix Factorization Revisited", l'expérience NCF a été reproduite, et sur le même ensemble de données, la méthode de suppression a été utilisée pour conserver le dernier clic de chaque utilisateur comme vérification. Et par le biais de HR et NDCG pour évaluer les effets de Dot Product et NCF comme suit:

Par l'effet de l'image, est-il douteux de la cognition originale? Bien sûr, qu'il s'agisse du test de comparaison dans le texte original ou de ce que cet article veut exprimer, cela n'annule pas le rôle positif du champ de recommandation Deep Learning. En tant qu'alchimiste en apprentissage profond, il est plus intéressant de réfléchir à une partie de la signification du contraste. La partie de réglage dans le texte original est plus détaillée et mérite d'être apprise.L'auteur a présenté son processus d'alchimie et comment rechercher les paramètres optimaux pour le modèle de factorisation matricielle (MF).
Processus d'alchimie de factorisation matricielle
Papier original
D'après notre expérience passée avec les modèles de factorisation matricielle, si les autres hyperparamètres sont choisis correctement, plus la dimension d'enrobage est grande, meilleure est la qualité - nos expériences de la figure 2 le confirment. Pour les autres hyperparamètres: le taux d'apprentissage et le nombre d'époques d'apprentissage influencent les courbes de convergence. Habituellement, plus le taux d'apprentissage est bas, meilleure est la qualité, mais aussi plus il faut d'époques. Nous définissons un budget de calcul allant jusqu'à 256 époques et recherchons le taux d'apprentissage dans ce paramètre. Dans le premier passage d'hyperparamètres, nous recherchons une grille grossière des taux d'apprentissage η ∈ {0,001, 0,003, 0,01} et du nombre de négatifs m = {4, 8, 16} en fixant la régularisation à λ = 0. Ensuite, nous avons fait une recherche pour la régularisation en {0.001, 0.003, 0.01} autour des candidats prometteurs. Pour accélérer la recherche, ces premières passes grossières ont été faites avec 128 époques et une dimension fixe de d = 64 (Movielens) et d = 128 (Pinterest). Nous avons affiné davantage les valeurs les plus prometteuses du taux d'apprentissage, du nombre de négatifs et de la régularisation en utilisant d = 128 et 256 époques.
Tout au long des expériences, nous initialisons les plongements à partir d'une distribution gaussienne avec un écart type de 0,1; nous avons testé une certaine variation de l'écart type, mais n'avons pas constaté beaucoup d'effet. Les hyperparamètres finaux pour Movielens sont: taux d'apprentissage η = 0,002, nombre de négatifs m = 8, régularisation λ = 0,005, nombre d'époques 256. Pour Pinterest: taux d'apprentissage η = 0,007, nombre d'échantillons négatifs m = 10, régularisation λ = 0,01, nombre d'époques 256.
Notes d'alchimie
(1) L'ensemble d'apprentissage, l'ensemble de validation et l'ensemble de tests sont divisés. Le dernier clic de l'utilisateur est l'ensemble de tests et l'avant-dernier clic est l'échantillon positif de l'ensemble de vérification.
(2) Super réglage des paramètres. Liste des paramètres réglables:
| paramètre | sens |
|---|---|
| époques | Nombre de rondes d'entraînement |
| m | Taux d'échantillonnage négatif |
| la | Taux d'apprentissage SGD |
| ré | Dimensions d'intégration |
| std | Écart type des coefficients initiaux du modèle (distribution normale standard) |
| λ | Coefficient de régularisation |
(3) Utilisez Grid Search pour ajuster le taux d'apprentissage η ∈ {0,001, 0,003, 0,01} et le taux d'échantillonnage négatif m = {4,8,16} pour une sélection grossière des résultats de premier niveau, puis sélectionnez le meilleure paire de résultats λ = {0,001, 0,003, 0,01} pour le deuxième niveau de résultats pour la sélection fine. Dans le même temps, corrigez les époques, la dimension d'intégration et l'écart type.
(4) Ajustez le nombre de tours de formation, le taux d'échantillonnage négatif, etc.
références
1 、 《Le filtrage collaboratif neuronal et la factorisation matricielle revisités》
https://arxiv.org/abs/2005.09683
Filtrage vs factorisation matricielle revisité
https://arxiv.org/abs/2005.09683
2. Reproduisez le code https://github.com/hexiangnan/neural_collaborative_filtering