Répertoire d'articles
Un planificateur de cluster Web commun
1. Les planificateurs de cluster Web courants actuels sont divisés en logiciel et matériel
2. Le logiciel utilise généralement LVS, Haproxy et Nginx open source
- LVS a les meilleures performances, mais il est relativement compliqué à construire; le module en amont de Nginx prend en charge la fonction de cluster, mais la fonction de vérification de l'état des nœuds de cluster n'est pas forte, et les performances de concurrence élevée ne sont pas aussi bonnes que Haproxy.
3. Le matériel le plus couramment utilisé est F5, et de nombreuses personnes utilisent certains produits nationaux, tels que Barracuda, NSFOCUS, etc.
Deux, analyse de l'application Haproxy
1. LVS a une forte capacité anti-charge dans les applications d'entreprise, mais il y a des lacunes
- LVS ne prend pas en charge le traitement régulier et ne peut pas réaliser de séparation dynamique et statique
- Pour les grands sites Web, la mise en œuvre et la configuration de LVS sont compliquées et le coût de maintenance est relativement élevé
2. Haproxy est un logiciel qui peut fournir une haute disponibilité, un équilibrage de charge et un proxy basé sur des applications TCP et HTTP
- Convient aux sites Web avec de lourdes charges
- L'exécution sur du matériel peut prendre en charge des dizaines de milliers de demandes de connexion simultanées
Troisièmement, principe de l'algorithme de planification Haproxy
(1) Haproxy prend en charge plusieurs algorithmes de planification, les plus couramment utilisés sont trois
1 、 RR (ronde préliminaire)
- L'algorithme RR est l'algorithme le plus simple et le plus couramment utilisé, à savoir l'ordonnancement à tour de rôle
2 、 LC (Moins de connexions)
- L'algorithme du nombre minimum de connexions alloue dynamiquement les requêtes frontales en fonction du nombre de connexions de nœuds back-end
3 、 SH (Hachage de la source)
- Basé sur l'algorithme de planification d'accès à la source, il est utilisé dans certains scénarios où les sessions de session sont enregistrées sur le serveur. La planification du cluster peut être basée sur l'IP source, le cookie, etc.
Quatre étapes de déploiement du cluster Haproxy
Configuration de l'environnement:
Serveur Haproxy (centos7-1): 192.168.200.10
Serveur Nginx 1 (centos7-2): 192.168.200.20
Serveur Nginx 2 (centos7-3):
Client 192.168.200.30 (Windows 10 virtuel): 192.168.200.136
------------------------------------- Déploiement du serveur Haproxy ---------- ----------------------------
1. Désactivez le pare-feu et téléchargez le paquet haproxy-1.5.19.tar.gz requis par Haproxy Allez dans le répertoire / opt
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
2. Compilez et installez Haproxy
yum install -y pcre-devel bzip2-devel gcc gcc-c++ make
tar zxvf haproxy-1.5.19.tar.gz
cd haproxy-1.5.19/
make TARGET=linux2628 ARCH=x86_64
make install
---------------------参数说明----------------------------
TARGET=linux2628 #内核版本
#使用uname -r 查看内核,如2.6.18-371.e15,此时该参数用TARGET=linux26;kernel大于2.6.28的用TARGET=linux2628
ARCH=x86_64 #系统位数,64位系统
-------------------------------------------------------
3. Configuration du serveur Haproxy
mkdir /etc/haproxy
cp /opt/haproxy-1.5.19/examples/haproxy.cfg /etc/haproxy/
cd /etc/haproxy/
vim haproxy.cfg
global
-----4~5行修改,配置日志记录,local0为日志设备,默认存放到系统日志--------
log /dev/log local0 info
log /dev/log local0 notice
#log loghost local0 info
maxconn 4096
----8行,注释,chroot运行路径,为该服务自设置的根目录,一般需将此行注释掉------
#chroot /usr/share/haproxy
uid 99 #用户UID
gid 99 #用户GID
daemon #守护进程模式
defaults
log global #定义日志为global配置中的日志定义
mode http #模式为http
option httplog #采用http日志格式记录日志
option dontlognull #不记录健康检查日志信息
retries 3 #检查节点服务器失败次数,连续达到三次失败,则认为节点不可用
redispatch #当服务器负载很高时,自动结束当前队列处理比较久的连接
maxconn 2000 #连接最大数
contimeout 5000 #连接超时时间
clitimeout 50000 #客户端超时时间
srvtimeout 50000 #服务器超时时间
----删除下面行所有listen项,添加-------
listen webcluster 0.0.0.0:80 #定义一个名为webcluster的应用
option httpchk GET /test.html #检查服务器的test.html文件
balance roundrobin #负载均衡调度算法使用轮询算法roundrobin
server inst1 192.168.200.20:80 check inter 2000 fall 3 #定义在线节点
server inst2 192.168.200.30:80 check inter 2000 fall 3
-----------------------参数说明-------------------------------------------------------------
balance roundrobin #负载均衡调度算法
#轮询算法:roundrobin;最小连接数算法:leastconn;来源访问调度算法:source,类似于nginx的ip_hash
check inter 2000 #表示haproxy服务器和节点之间的一个心跳频率
fall 3 #表示连续三次检测不到心跳频率则认为该节点失效
若节点配置后带有“backup”表示该节点只是个备份节点,只有主节点失效该节点才会上。不携带“backup”,表示为主节点,和其它主节点共同提供服务。
--------------------------------------------------------------------------------------------
4. Ajouter le service système Haproxy
cp /opt/haproxy-1.5.19/examples/haproxy.init /etc/init.d/haproxy
cd /etc/init.d/
chmod +x haproxy
chkconfig --add /etc/init.d/haproxy
ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy
service haproxy start 或 /etc/init.d/haproxy start
---------------------- Serveur de nœud -------------------------- ------------
systemctl stop firewalld.service
systemctl disable firewalld.service
setenforce 0
yum install -y pcre-devel zlib-devel gcc gcc-c++ make
useradd -M -s /sbin/nologin nginx
cd /opt
tar zxvf nginx-1.12.0.tar.gz #提前将nginx压缩包上传到/opt目录下
cd nginx-1.12.0/
./configure --prefix=/usr/local/nginx --user=nginx --group=nginx
make && make install
ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
----192.168.200.20----
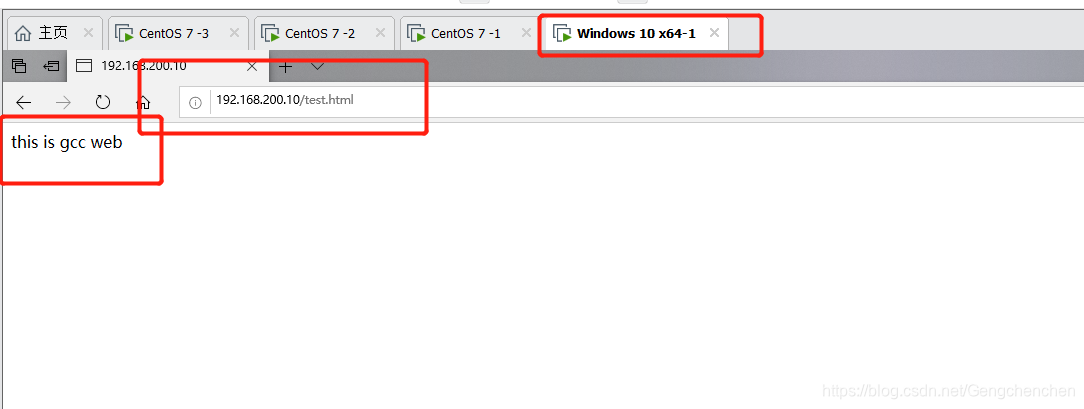
echo "this is gcc web" > /usr/local/nginx/html/test.html
----192.168.200.30----
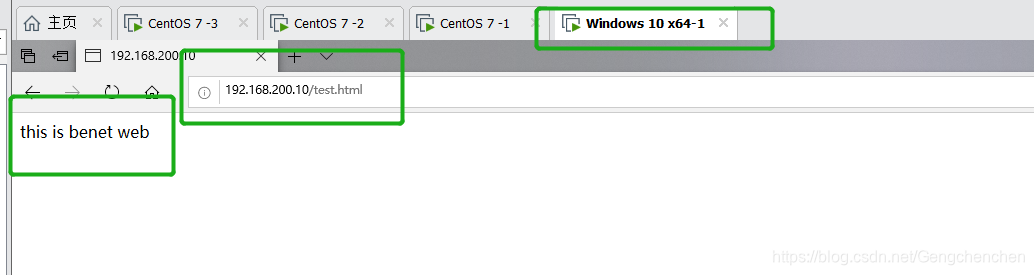
echo "this is benet web" > /usr/local/nginx/html/test.html
nginx #启动nginx 服务
-------------------------- Tester le cluster Web --------------------- -----------
Ouvrez http://192.168.200.10/test.html dans le navigateur sur le client et actualisez constamment le navigateur pour tester l'effet d'équilibrage de charge.
---------------------------- Définition du journal -------------------- --------------
#默认 haproxy 的日志是输出到系统的 syslog 中,查看起来不是非常方便,为了更好的管理haproxy的日志,我们在生产环境中一般单独定义出来。需要将haproxy的info及notice日志分别记录到不同的日志文件中。
vim /etc/haproxy/haproxy.cfg
global
log /dev/log local0 info
log /dev/log local0 notice
service haproxy restart
#需要修改 rsyslog 配置,为了便于管理。将haproxy相关的配置独立定义到 haproxy.conf,并放到/etc/rsyslog.d/ 下,rsyslog启动时会自动加载此目录下的所有配置文件。
vim /etc/rsyslog.d/haproxy.conf
if ($programname == 'haproxy' and $syslogseverity-text == 'info')
then -/var/log/haproxy/haproxy-info.log
&~
if ($programname == 'haproxy' and $syslogseverity-text == 'notice')
then -/var/log/haproxy/haproxy-notice.log
&~
#说明:
这部分配置是将haproxy的info日志记录到/var/log/haproxy/haproxy-info.log下,
将notice日志记录到/var/log/haproxy/haproxy-notice.log下。
“&~”表示当日志写入到日志文件后,rsyslog停止处理这个信息。
systemctl restart rsyslog.service
mkdir /var/log/haproxy
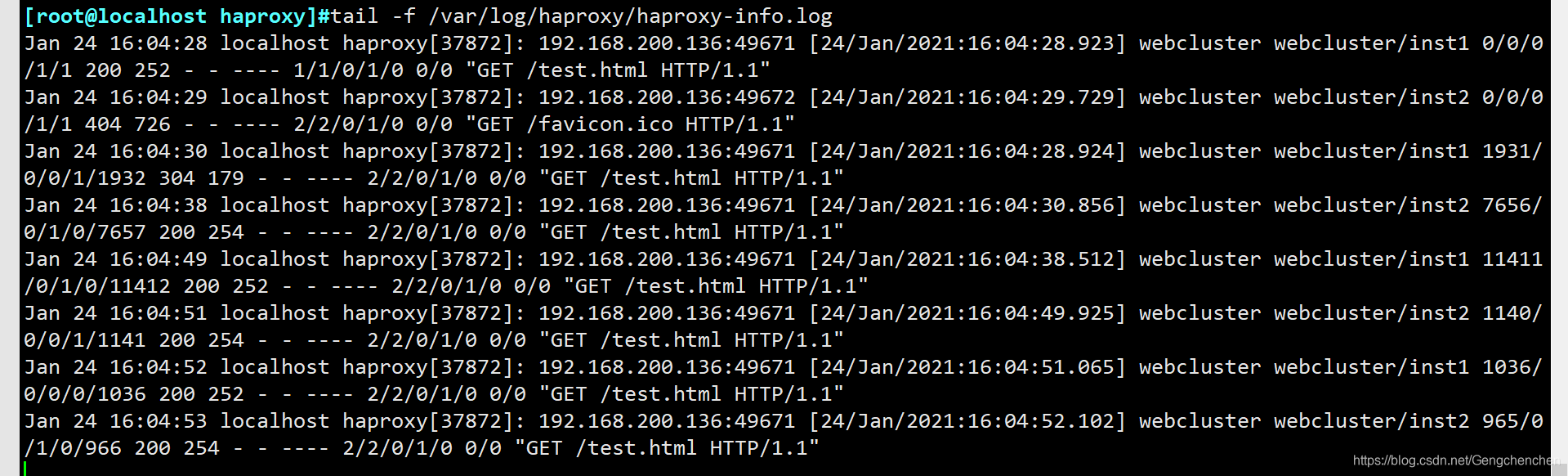
tail -f /var/log/haproxy/haproxy-info.log #查看haproxy的访问请求日志信息
Cinq, optimisation des paramètres Haproxy
1. maxconn: le nombre maximum de connexions, ajusté en fonction de la situation réelle de l'application, 10240 est recommandé
2. démon: mode de processus démon, Haproxy peut être démarré en mode de processus non démon, il est recommandé d'utiliser le mode de processus démon pour démarrer
3. nbproc: nombre de processus simultanés pour l'équilibrage de charge. Il est recommandé d'être égal ou égal à 2 fois le nombre de cœurs de processeur du serveur actuel.
4. tentatives: le nombre de tentatives, principalement utilisé pour vérifier les nœuds du cluster. S'il y a beaucoup de nœuds et que le niveau de concurrence est élevé, définissez-le sur 2 ou 3 fois.
5. option http-server-close: ferme activement l'option de requête http, il est recommandé d'utiliser cette option dans un environnement de production
6. timeout http-keep-alive: long délai d'expiration de la connexion, définissez le long délai d'expiration de la connexion, qui peut être défini sur 10 s
7. timeout http-request: délai d'expiration de la requête http, il est recommandé de définir cette durée sur 5 ~ 10s pour augmenter la vitesse de libération de la connexion http
8. timeout client: délai d'expiration du client. Si le trafic est trop important et que la réponse du noeud est lente, vous pouvez définir ce délai plus court et il est recommandé de le définir sur environ 1 min