DolphinDB fournit les 4 fonctions suivantes pour importer des données texte dans la mémoire ou la base de données:
- loadText: Importez un fichier texte en tant que table mémoire.
- ploadText: importation parallèle de fichiers texte en tant que tables de mémoire de partition. Comparé à la fonction loadText, il est plus rapide.
- loadTextEx: Importez des fichiers texte dans des bases de données, y compris des bases de données distribuées, des bases de données de disque local ou des bases de données de mémoire.
- textChunkDS: divisez le fichier texte en plusieurs petites sources de données, puis utilisez la fonction mr pour un traitement flexible des données.
L'importation de données texte de DolphinDB n'est pas seulement flexible, riche en fonctions et très rapide. Par rapport aux systèmes populaires dans l'industrie tels que Clickhouse, MemSQL, Druid, Pandas, DolphinDB, l'importation monothread est plus rapide, jusqu'à un avantage d'un ordre de grandeur; dans le cas de l'importation parallèle multithread, l'avantage de la vitesse est plus évident .
Ce didacticiel présente les problèmes courants, les solutions correspondantes et les précautions lors de l'importation de données texte.
1. Identifiez automatiquement le format des données
Dans la plupart des autres systèmes, lors de l'importation de données texte, l'utilisateur doit spécifier le format des données. Pour la commodité des utilisateurs, DolphinDB peut reconnaître automatiquement le format des données lors de l'importation de données.
Le format de données d'identification automatique comprend deux parties: l'identification du nom de champ et l'identification du type de données. Si aucune colonne de la première ligne du fichier ne commence par un nombre, le système considère que la première ligne est l'en-tête du fichier et contient les noms de champ. DolphinDB extrait une petite quantité de données sous forme d'échantillons et déduit automatiquement le type de données de chaque colonne. Comme il est basé sur des données partielles, l'identification du type de données de certaines colonnes peut être erronée. Mais pour la plupart des fichiers texte, vous n'avez pas besoin de spécifier manuellement le nom du champ et le type de données de chaque colonne, vous pouvez l'importer correctement dans DolphinDB.
Remarque: les versions antérieures à la 1.20.0 ne prennent pas en charge l'importation des trois types de données INT128, UUID et IPADDR. Si ces trois types de données sont inclus dans le fichier csv, veuillez vous assurer que la version utilisée n'est pas inférieure à 1.20.0.
loadTextLa fonction est utilisée pour importer des données dans la table mémoire DolphinDB. L'exemple suivant appelle la fonction loadText pour importer des données et afficher la structure de la table de données générée. Veuillez vous référer à l' annexe pour les fichiers de données impliqués dans l'exemple .
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath);Affichez les 5 premières lignes de données du tableau de données:
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000Appelez la schemafonction pour afficher la structure de la table (nom de champ, type de données, etc.):
tmpTB.schema().colDefs;
name typeString typeInt comment
---------- ---------- ------- -------
symbol SYMBOL 17
exchange SYMBOL 17
cycle INT 4
tradingDay DATE 6
date DATE 6
time INT 4
open DOUBLE 16
high DOUBLE 16
low DOUBLE 16
close DOUBLE 16
volume INT 4
turnover DOUBLE 16
unixTime LONG 5
2. Spécifiez le format d'importation des données
Dans les 4 fonctions de chargement de données décrites dans ce didacticiel, vous pouvez utiliser le paramètre schema pour spécifier une table, qui contient le nom, le type, le format et les colonnes à importer pour chaque champ. Le tableau peut contenir les 4 colonnes suivantes:

Parmi eux, les deux colonnes nom et type sont obligatoires et doivent être les deux premières colonnes. Le format et col à deux colonnes sont facultatifs et il n'y a aucune exigence de hiérarchisation.
Par exemple, nous pouvons utiliser la table de données suivante comme paramètre de schéma:
2.1 Extraire le schéma du fichier texte
extractTextSchemaLa fonction est utilisée pour obtenir le schéma du fichier texte, y compris des informations telles que les noms de champ et les types de données.
Par exemple, utilisez la fonction extractTextSchema pour obtenir la structure de table de l'exemple de fichier dans ce didacticiel:
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
name type
---------- ------
symbol SYMBOL
exchange SYMBOL
cycle INT
tradingDay DATE
date DATE
time INT
open DOUBLE
high DOUBLE
low DOUBLE
close DOUBLE
volume INT
turnover DOUBLE
unixTime LONG
2.2 Spécifiez le nom et le type du champ
Lorsque le nom de champ ou le type de données automatiquement reconnu par le système ne répond pas aux attentes ou aux exigences, vous pouvez modifier la table de schéma générée par extractTextSchema ou créer directement une table de schéma pour spécifier le nom de champ et le type de données pour chaque colonne du fichier texte.
Par exemple, si la colonne de volume des données importées est automatiquement reconnue comme le type INT et que le type de volume requis est le type LONG, vous devez modifier la table de schéma et spécifier le type de colonne de volume comme LONG.
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="LONG" where name="volume";Utilisez la fonction loadText pour importer un fichier texte et importer les données dans la base de données en fonction du type de données de champ spécifié par schemaTB.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);L'exemple ci-dessus présente la modification du type de données. Si vous souhaitez modifier le nom du champ dans la table, vous pouvez également utiliser la même méthode.
Veuillez noter que si l'analyse automatique des types de données liés à la date et à l'heure ne répond pas aux attentes, vous devez le résoudre via la méthode de la section 2.3 de ce didacticiel.
2.3 Spécifier le format des types de date et d'heure
Pour les données de colonne de date ou de colonne d'heure, si le type de données automatiquement reconnu ne répond pas aux attentes, vous devez non seulement spécifier le type de données dans la colonne type du schéma, mais également spécifier le format (indiqué par une chaîne) dans la colonne format , comme "MM / jj / aaaa". Veuillez vous référer au réglage et au format de la date et de l'heure pour savoir comment afficher le format de la date et de l'heure .
Voici un exemple de la manière de spécifier des types de données pour les colonnes de date et d'heure.
Exécutez le script suivant dans DolphinDB pour générer le fichier de données requis pour cet exemple.
dataFilePath="/home/data/timeData.csv"
t=table(["20190623 14:54:57","20190623 15:54:23","20190623 16:30:25"] as time,`AAPL`MS`IBM as sym,2200 5400 8670 as qty,54.78 59.64 65.23 as price)
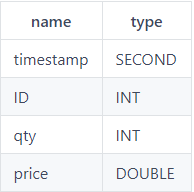
saveText(t,dataFilePath);Avant de charger les données, utilisez la fonction extractTextSchema pour obtenir le schéma du fichier de données:
schemaTB=extractTextSchema(dataFilePath)
schemaTB;
name type
----- ------
time SECOND
sym SYMBOL
qty INT
price DOUBLEDe toute évidence, le système reconnaît que le type de données de la colonne de temps ne répond pas aux attentes. Si vous chargez le fichier directement, les données de la colonne de temps seront vides. Afin de charger correctement les données de la colonne d'heure du fichier, vous devez spécifier le type de données de la colonne d'heure comme DATETIME et spécifier le format de la colonne comme "aaaaMMjj HH: mm: ss".
update schemaTB set type="DATETIME" where name="time"
schemaTB[`format]=["yyyyMMdd HH:mm:ss",,,];Importez les données et visualisez, les données s'affichent correctement:
tmpTB=loadText(dataFilePath,,schemaTB)
tmpTB;
time sym qty price
------------------- ---- ---- -----
2019.06.23T14:54:57 AAPL 2200 54.78
2019.06.23T15:54:23 MS 5400 59.64
2019.06.23T16:30:25 IBM 8670 65.23
2.4 Importer la colonne spécifiée
Lors de l'importation de données, vous pouvez spécifier de n'importer que certaines colonnes du fichier texte via le paramètre de schéma.
Dans l'exemple suivant, il vous suffit de charger les 7 colonnes de symbole, date, ouverture, hauteur, fermeture, volume et chiffre d'affaires dans le fichier texte.
Tout d'abord, appelez la fonction extractTextSchema pour obtenir la structure de table du fichier texte cible.
dataFilePath="/home/data/candle_201801.csv"
schemaTB=extractTextSchema(dataFilePath);Utilisez la fonction rowNo pour générer un numéro de colonne pour chaque colonne, affectez-le à la colonne col dans la table de schéma, puis modifiez la table de schéma pour ne conserver que les lignes qui représentent les champs qui doivent être importés.
update schemaTB set col = rowNo(name)
schemaTB=select * from schemaTB where name in `symbol`date`open`high`close`volume`turnover;mise en garde:
- Le numéro de colonne commence à 0. Dans l'exemple ci-dessus, le numéro de colonne correspondant à la colonne de symboles dans la première colonne est 0.
- Lors de l'importation de données, l'ordre des colonnes ne peut pas être modifié. Si vous avez besoin d'ajuster l'ordre des colonnes, vous pouvez utiliser la
reorderColumns!fonction après avoir chargé le fichier de données .
Enfin, utilisez la fonction loadText et configurez les paramètres de schéma pour importer les colonnes spécifiées dans le fichier texte.
tmpTB=loadText(filename=dataFilePath,schema=schemaTB);En regardant les 5 premières lignes du tableau, seules les colonnes requises sont importées:
select top 5 * from tmpTB
symbol date open high close volume turnover
------ ---------- ----- ----- ----- ------- ----------
000001 2018.01.02 13.35 13.39 13.38 2003635 2.678558E7
000001 2018.01.02 13.37 13.38 13.33 867181 1.158757E7
000001 2018.01.02 13.32 13.35 13.35 903894 1.204971E7
000001 2018.01.02 13.35 13.38 13.35 1012000 1.352286E7
000001 2018.01.02 13.35 13.37 13.37 1601939 2.140652E72.5 Passer les premières lignes de données texte
Lors de l'importation de données, si vous devez ignorer les n premières lignes du fichier (qui peut être une description de fichier), vous pouvez spécifier le paramètre skipRows comme n. Comme la description du fichier de description n'est généralement pas très longue, la valeur maximale de ce paramètre est 1024. Les 4 fonctions de chargement de données décrites dans ce didacticiel prennent toutes en charge les paramètres skipRows.
Dans l'exemple suivant, importez un fichier de données via la fonction loadText et affichez le nombre total de lignes de la table après l'importation du fichier et le contenu des 5 premières lignes.
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath)
select count(*) from tmpTB;
count
-----
5040
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000Spécifiez la valeur du paramètre skipRows sur 1000, ignorez les 1000 premières lignes du fichier texte pour importer le fichier:
tmpTB=loadText(filename=dataFilePath,skipRows=1000)
select count(*) from tmpTB;
count
-----
4041
select top 5 * from tmpTB;
col0 col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12
------ ---- ---- ---------- ---------- --------- ----- ----- ----- ----- ------ ---------- -------------
000001 SZSE 1 2018.01.08 2018.01.08 101000000 13.13 13.14 13.12 13.14 646912 8.48962E6 1515377400000
000001 SZSE 1 2018.01.08 2018.01.08 101100000 13.13 13.14 13.13 13.14 453647 5.958462E6 1515377460000
000001 SZSE 1 2018.01.08 2018.01.08 101200000 13.13 13.14 13.12 13.13 700853 9.200605E6 1515377520000
000001 SZSE 1 2018.01.08 2018.01.08 101300000 13.13 13.14 13.12 13.12 738920 9.697166E6 1515377580000
000001 SZSE 1 2018.01.08 2018.01.08 101400000 13.13 13.14 13.12 13.13 469800 6.168286E6 1515377640000Remarque: comme indiqué dans l'exemple ci-dessus, lorsque vous ignorez les n premières lignes pour l'importation, si la première ligne du fichier de données est un nom de colonne, cette ligne sera ignorée comme première ligne.
Dans l'exemple ci-dessus, une fois que le fichier texte a spécifié le paramètre skipRows à importer, car la première ligne des noms de colonne est ignorée, les noms de colonne deviennent les noms de colonne par défaut: col0, col1, col2, etc. Si vous devez conserver les noms de colonne et spécifier d'ignorer les n premières lignes, vous pouvez d'abord obtenir le schéma du fichier texte via la fonction extractTextSchema et spécifier le paramètre de schéma lors de l'importation:
schema=extractTextSchema(dataFilePath)
tmpTB=loadText(filename=dataFilePath,schema=schema,skipRows=1000)
select count(*) from tmpTB;
count
-----
4041
select top 5 * from tmpTB;
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- --------- ----- ----- ----- ----- ------ ---------- -------------
000001 SZSE 1 2018.01.08 2018.01.08 101000000 13.13 13.14 13.12 13.14 646912 8.48962E6 1515377400000
000001 SZSE 1 2018.01.08 2018.01.08 101100000 13.13 13.14 13.13 13.14 453647 5.958462E6 1515377460000
000001 SZSE 1 2018.01.08 2018.01.08 101200000 13.13 13.14 13.12 13.13 700853 9.200605E6 1515377520000
000001 SZSE 1 2018.01.08 2018.01.08 101300000 13.13 13.14 13.12 13.12 738920 9.697166E6 1515377580000
000001 SZSE 1 2018.01.08 2018.01.08 101400000 13.13 13.14 13.12 13.13 469800 6.168286E6 1515377640000
3. Importez des données en parallèle
3.1 Un seul fichier est chargé en mémoire dans plusieurs threads
La fonction ploadText peut charger un fichier texte en mémoire de manière multi-thread. La syntaxe de cette fonction est la même que celle de la fonction loadText. La différence est que la fonction ploadText peut charger rapidement des fichiers volumineux et générer une table de partition de mémoire. Il utilise pleinement les processeurs multicœurs pour charger des fichiers en parallèle.Le degré de parallélisme dépend du nombre de cœurs de processeurs du serveur et de la configuration localExecutors du nœud.
Les éléments suivants comparent les performances de la fonction loadText et de la fonction ploadText lors de l'importation du même fichier.
Tout d'abord, générez un fichier texte d'environ 4 Go via le script:
filePath="/home/data/testFile.csv"
appendRows=100000000
t=table(rand(100,appendRows) as int,take(string('A'..'Z'),appendRows) as symbol,take(2010.01.01..2018.12.30,appendRows) as date,rand(float(100),appendRows) as float,00:00:00.000 + rand(86400000,appendRows) as time)
t.saveText(filePath);Chargez le fichier via loadText et ploadText respectivement. Le nœud utilisé dans cet exemple est un processeur avec 6 cœurs et 12 hyperthreads.
timer loadText(filePath);
Time elapsed: 12629.492 ms
timer ploadText(filePath);
Time elapsed: 2669.702 msLes résultats montrent que dans cette configuration, les performances de ploadText sont environ 4,5 fois supérieures à celles de loadText.
3.2 Importation parallèle de plusieurs fichiers
Dans le domaine des applications Big Data, l'importation de données n'est souvent pas seulement l'importation d'un ou deux fichiers, mais l'importation par lots de dizaines voire de centaines de fichiers volumineux. Afin d'obtenir de meilleures performances d'importation, il est recommandé d'importer des fichiers de données par lots en parallèle.
La fonction loadTextEx peut importer des fichiers texte dans une base de données spécifiée, y compris des bases de données distribuées, des bases de données de disque local ou des bases de données de mémoire. Étant donné que la table de partition de DolphinDB prend en charge la lecture et l'écriture simultanées, elle peut prendre en charge l'importation de données multi-thread.
Utilisez loadTextEx pour importer des données texte dans une base de données distribuée. La réalisation concrète est que les données sont d'abord importées dans la mémoire, puis écrites dans la base de données à partir de la mémoire. Ces deux étapes sont complétées par la même fonction pour garantir une efficacité élevée.
L'exemple suivant montre comment écrire par lots plusieurs fichiers sur le disque dans la table de partition DolphinDB. Tout d'abord, exécutez le script suivant dans DolphinDB pour générer 100 fichiers, soit un total d'environ 778 Mo, dont 10 millions d'enregistrements.
n=100000
dataFilePath="/home/data/multi/multiImport_"+string(1..100)+".csv"
for (i in 0..99){
trades=table(sort(take(100*i+1..100,n)) as id,rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5)
trades.saveText(dataFilePath[i])
};Créez la base de données et la table:
login(`admin,`123456)
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,1..10000)
tb=db.createPartitionedTable(trades,`tb,`id);Les cutfonctions de DolphinDB peuvent regrouper des éléments dans un vecteur. Ensuite, appelez la fonction de coupe pour regrouper les chemins de fichiers à importer, puis appelez la submitJobfonction pour affecter des tâches d'écriture à chaque thread et importer les données par lots.
def writeData(db,file){
loop(loadTextEx{db,`tb,`id,},file)
}
parallelLevel=10
for(x in dataFilePath.cut(100/parallelLevel)){
submitJob("loadData"+parallelLevel,"loadData",writeData{db,x})
};Remarque: la table de partition de DolphinDB ne permet pas à plusieurs threads d'écrire des données sur une partition en même temps. Dans l'exemple ci-dessus, la valeur de la colonne de partition (colonne id) dans chaque fichier est différente, donc cela n'entraînera pas l'écriture de plusieurs threads sur la même partition. Lors de la conception de lectures et d'écritures simultanées de la table de partition, assurez-vous qu'aucun thread n'écrit sur la même partition en même temps.
Grâce à la getRecentJobsfonction, l'état des n derniers travaux par lots sur le nœud local actuel peut être obtenu. En utilisant l'instruction select pour calculer le temps nécessaire pour importer des fichiers batch en parallèle, il a fallu environ 1,59 seconde pour obtenir un processeur avec 6 cœurs et 12 hyperthreads.
select max(endTime) - min(startTime) from getRecentJobs() where jobId like "loadData"+string(parallelLevel)+"%";
max_endTime_sub
---------------
1590Exécutez le script suivant pour importer séquentiellement 100 fichiers dans la base de données dans un seul thread et enregistrez le temps requis, qui prend environ 8,65 secondes.
timer writeData(db, dataFilePath);
Time elapsed: 8647.645 msLes résultats montrent que dans cette configuration, la vitesse d'importation de 10 threads en parallèle est environ 5,5 fois celle de l'importation de thread unique.
Affichez le nombre d'enregistrements dans le tableau de données:
select count(*) from loadTable("dfs://DolphinDBdatabase", `tb);
count
------
10000000
4. Prétraitement avant l'importation de la base de données
Avant d'importer les données dans la base de données, si vous avez besoin de prétraiter les données, comme la conversion de types de données de date et d'heure, le remplissage de valeurs vides, etc., vous pouvez loadTextExspécifier le paramètre de transformation lors de l' appel de la fonction. Le paramètre tansform accepte une fonction en tant que paramètre et exige que la fonction n'accepte qu'un seul paramètre. L'entrée de la fonction est une table mémoire non partitionnée et la sortie est également une table mémoire non partitionnée. Il convient de noter que seule la fonction loadTextEx fournit le paramètre de transformation.
4.1 Spécifier le type de données des données de date et d'heure
4.1.1 Convertir la date et l'heure représentées par le type numérique dans le type spécifié
Les données représentant l'heure dans le fichier de données peuvent être un entier ou un entier long, et pendant l'analyse des données, il est souvent nécessaire de forcer ces données à être converties dans un format de type heure et importées et stockées dans la base de données. Pour ce scénario, vous pouvez spécifier le type de données correspondant pour les colonnes de date et d'heure dans le fichier texte via le paramètre de transformation de la fonction loadTextEx.
Commencez par créer une base de données et des tables distribuées.
login(`admin,`123456)
dataFilePath="/home/data/candle_201801.csv"
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="TIME" where name="time"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb1,`date);La fonction personnalisée i2t est utilisée pour prétraiter les données et renvoyer la table de données traitées.
def i2t(mutable t){
return t.replaceColumn!(`time,time(t.time/10))
}Remarque: lorsque vous traitez des données dans le corps d'une fonction personnalisée, essayez d'utiliser des modifications locales (fonctions se terminant par!) Pour améliorer les performances.
Appelez la fonction loadTextEx et spécifiez le paramètre de transformation comme fonction i2t. Le système exécutera la fonction i2t sur les données du fichier texte et enregistrera le résultat dans la base de données.
tmpTB=loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=i2t);Affichez les 5 premières lignes de données du tableau. On peut voir que la colonne de temps est stockée dans le type TIME, pas le type INT dans le fichier texte:
select top 5 * from loadTable(dbPath,`tb1);
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- ------------------ ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01.02 2018.01.02 02:35:10.000000000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:20.000000000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:30.000000000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:40.000000000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01.02 2018.01.02 02:35:50.000000000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000
4.1.2 Conversion entre les types de données de date ou d'heure
Si la date dans le fichier texte est stockée dans le type DATE, vous souhaitez la stocker sous la forme MONTH lors de l'importation de la base de données. Dans ce cas, vous pouvez également convertir le type de données de la colonne de date via le paramètre de transformation du Fonction loadTextEx. Les étapes sont les mêmes que dans la section précédente.
login(`admin,`123456)
dbPath="dfs://DolphinDBdatabase"
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
schemaTB=extractTextSchema(dataFilePath)
update schemaTB set type="MONTH" where name="tradingDay"
tb=table(1:0,schemaTB.name,schemaTB.type)
tb=db.createPartitionedTable(tb,`tb1,`date)
def d2m(mutable t){
return t.replaceColumn!(`tradingDay,month(t.tradingDay))
}
tmpTB=loadTextEx(dbHandle=db,tableName=`tb1,partitionColumns=`date,filename=dataFilePath,transform=d2m);Affichez les 5 premières lignes de données du tableau. On peut voir que la colonne tradingDay est stockée dans le type MONTH, pas dans le type DATE dans le fichier texte:
select top 5 * from loadTable(dbPath,`tb1);
symbol exchange cycle tradingDay date time open high low close volume turnover unixTime
------ -------- ----- ---------- ---------- -------- ----- ----- ----- ----- ------- ---------- -------------
000001 SZSE 1 2018.01M 2018.01.02 93100000 13.35 13.39 13.35 13.38 2003635 2.678558E7 1514856660000
000001 SZSE 1 2018.01M 2018.01.02 93200000 13.37 13.38 13.33 13.33 867181 1.158757E7 1514856720000
000001 SZSE 1 2018.01M 2018.01.02 93300000 13.32 13.35 13.32 13.35 903894 1.204971E7 1514856780000
000001 SZSE 1 2018.01M 2018.01.02 93400000 13.35 13.38 13.35 13.35 1012000 1.352286E7 1514856840000
000001 SZSE 1 2018.01M 2018.01.02 93500000 13.35 13.37 13.35 13.37 1601939 2.140652E7 1514856900000
4.2 Remplissez les valeurs vides
Le paramètre transform peut appeler les fonctions intégrées de DolphinDB. Lorsque la fonction intégrée nécessite plusieurs paramètres, nous pouvons utiliser certaines applications pour convertir la fonction multi-paramètres en une fonction à un paramètre. Par exemple, appelez une nullFill!fonction pour remplir des valeurs vides dans un fichier texte.
db=database(dbPath,VALUE,2018.01.02..2018.01.30)
tb=db.createPartitionedTable(tb,`tb1,`date)
tmpTB=loadTextEx(dbHandle=db,tableName=`pt,partitionColumns=`date,filename=dataFilePath,transform=nullFill!{,0});
5. Utilisez Map-Reduce pour importer des données personnalisées
DolphinDB prend en charge l'utilisation de Map-Reduce pour importer des données personnalisées, diviser les données en lignes et importer les données divisées dans DolphinDB via Map-Reduce.
Vous pouvez utiliser des textChunkDSfonctions pour diviser des fichiers en plusieurs sources de données de petits fichiers, puis les mrécrire dans la base de données via la fonction. Avant d'appeler la fonction mr pour stocker les données dans la base de données, les utilisateurs peuvent également effectuer un traitement de données flexible pour répondre à des exigences d'importation plus complexes.
5.1 Stocker les données sur les stocks et les contrats à terme dans le fichier dans deux tableaux de données différents
Exécutez le script suivant dans DolphinDB pour générer un fichier de données d'une taille d'environ 1 Go, qui comprend des données boursières et des données futures.
n=10000000
dataFilePath="/home/data/chunkText.csv"
trades=table(rand(`stock`futures,n) as type, rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,take(2000.01.01..2000.06.30,n) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4,rand(10000,n) as qty5,rand(10000,n) as qty6)
trades.saveText(dataFilePath);Créez des bases de données et des tables distribuées pour stocker respectivement les données de stock et les données à terme:
login(`admin,`123456)
dbPath1="dfs://stocksDatabase"
dbPath2="dfs://futuresDatabase"
db1=database(dbPath1,VALUE,`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S)
db2=database(dbPath2,VALUE,2000.01.01..2000.06.30)
tb1=db1.createPartitionedTable(trades,`stock,`sym)
tb2=db2.createPartitionedTable(trades,`futures,`date);Définissez les fonctions suivantes pour diviser les données et écrire des données dans différentes bases de données.
def divideImport(tb, mutable stockTB, mutable futuresTB)
{
tdata1=select * from tb where type="stock"
tdata2=select * from tb where type="futures"
append!(stockTB, tdata1)
append!(futuresTB, tdata2)
}Ensuite, divisez le fichier texte par la fonction textChunkDS, avec 300 Mo comme unité pour diviser le fichier en 4 parties.
ds=textChunkDS(dataFilePath,300)
ds;
(DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment, DataSource<readTableFromFileSegment)Appelez la fonction mr, spécifiez le résultat de la fonction textChunkDS comme source de données et importez le fichier dans la base de données. Étant donné que la fonction de carte (spécifiée par le paramètre mapFunc) n'accepte qu'une table en tant que paramètre, nous utilisons ici certaines applications pour convertir une fonction multi-paramètres en une fonction à un paramètre.
mr(ds=ds, mapFunc=divideImport{,tb1,tb2}, parallel=false);
Veuillez noter que différentes sources de données de petits fichiers peuvent contenir des données de la même partition. DolphinDB ne permet pas à plusieurs threads d'écrire simultanément sur la même partition, donc le
mr
paramètre de fonction parallèle est défini sur false, sinon il lèvera une exception.
Affichez les 5 premières lignes des tableaux dans les deux bases de données. La base de données boursière contient toutes les données boursières et la base de données à terme contient toutes les données à terme.
table de stock:
select top 5 * from loadTable("dfs://DolphinDBTickDatabase", `stock);
type sym date price1 price2 price3 price4 price5 price6 qty1 qty2 qty3 qty4 qty5 qty6
----- ---- ---------- --------- ---------- ----------- ------------ ------------ ------------ ---- ---- ---- ---- ---- ----
stock AMZN 2000.02.14 11.224234 112.26763 1160.926836 11661.418403 11902.403305 11636.093467 4 53 450 2072 9116 12
stock AMZN 2000.03.29 10.119057 111.132165 1031.171855 10655.048121 12682.656303 11182.317321 6 21 651 2078 7971 6207
stock AMZN 2000.06.16 11.61637 101.943971 1019.122963 10768.996906 11091.395164 11239.242307 0 91 857 3129 3829 811
stock AMZN 2000.02.20 11.69517 114.607763 1005.724332 10548.273754 12548.185724 12750.524002 1 39 270 4216 8607 6578
stock AMZN 2000.02.23 11.534805 106.040664 1085.913295 11461.783565 12496.932604 12995.461331 4 35 488 4042 6500 4826avenirs 表 :
select top 5 * from loadTable("dfs://DolphinDBFuturesDatabase", `futures);
type sym date price1 price2 price3 price4 price5 price6 qty1 qty2 qty3 qty4 qty5 ...
------- ---- ---------- --------- ---------- ----------- ------------ ------------ ------------ ---- ---- ---- ---- ---- ---
futures MSFT 2000.01.01 11.894442 106.494131 1000.600933 10927.639217 10648.298313 11680.875797 9 10 241 524 8325 ...
futures S 2000.01.01 10.13728 115.907379 1140.10161 11222.057315 10909.352983 13535.931446 3 69 461 4560 2583 ...
futures GM 2000.01.01 10.339581 112.602729 1097.198543 10938.208083 10761.688725 11121.888288 1 1 714 6701 9203 ...
futures IBM 2000.01.01 10.45422 112.229537 1087.366764 10356.28124 11829.206165 11724.680443 0 47 741 7794 5529 ...
futures TSLA 2000.01.01 11.901426 106.127109 1144.022732 10465.529256 12831.721586 10621.111858 4 43 136 9858 8487 ...
5.2 Charger rapidement certaines données au début et à la fin d'un gros fichier
Vous pouvez utiliser textChunkDS pour diviser un fichier volumineux en plusieurs petites sources de données (blocs), puis charger les première et dernière sources de données. Exécutez le script suivant dans DolphinDB pour générer des fichiers de données:
n=10000000
dataFilePath="/home/data/chunkText.csv"
trades=table(rand(`IBM`MSFT`GM`C`FB`GOOG`V`F`XOM`AMZN`TSLA`PG`S,n) as sym,sort(take(2000.01.01..2000.06.30,n)) as date,10.0+rand(2.0,n) as price1,100.0+rand(20.0,n) as price2,1000.0+rand(200.0,n) as price3,10000.0+rand(2000.0,n) as price4,10000.0+rand(3000.0,n) as price5,10000.0+rand(4000.0,n) as price6,rand(10,n) as qty1,rand(100,n) as qty2,rand(1000,n) as qty3,rand(10000,n) as qty4, rand(10000,n) as qty5, rand(1000,n) as qty6)
trades.saveText(dataFilePath);Ensuite, divisez le fichier texte par la fonction textChunkDS et divisez-le en unités de 10 Mo.
ds=textChunkDS(dataFilePath, 10);Appelez la fonction mr pour charger les données des deux premiers et derniers blocs. Étant donné que les données de ces deux blocs sont très petites, la vitesse de chargement est très rapide.
head_tail_tb = mr(ds=[ds.head(), ds.tail()], mapFunc=x->x, finalFunc=unionAll{,false});Affichez le nombre d'enregistrements dans la table head_tail_tb:
select count(*) from head_tail_tb;
count
------
192262
6. Autres questions nécessitant une attention particulière
6.1 Traitement de différentes données codées
Les chaînes DolphinDB étant encodées en UTF-8, si le fichier chargé n'est pas encodé en UTF-8, il doit être converti après l'importation. DolphinDB fournit convertEncode, fromUTF8et des toUTF8fonctions pour convertir le codage de chaîne après l' importation de données.
Par exemple, utilisez la fonction convertEncode pour convertir le codage de la colonne d'échange dans la table tmpTB:
dataFilePath="/home/data/candle_201801.csv"
tmpTB=loadText(filename=dataFilePath, skipRows=0)
tmpTB.replaceColumn!(`exchange, convertEncode(tmpTB.exchange,"gbk","utf-8"));
6.2 Analyse des types numériques
La première section de ce didacticiel présente le mécanisme d'analyse automatique des types de données de DolphinDB lors de l'importation de données. Cette section explique l'analyse des données numériques (y compris les données CHAR, SHORT, INT, LONG, FLOAT et DOUBLE). Le système peut reconnaître les formes suivantes de données numériques:
- La valeur numérique représentée par un nombre, par exemple: 123
- Valeur numérique avec séparateur de milliers, par exemple: 100 000
- Une valeur avec une virgule décimale, c'est-à-dire un nombre à virgule flottante, par exemple: 1,231
- Valeur exprimée en notation scientifique, par exemple: 1.23E5
Si le type de données spécifié est de type numérique, DolphinDB ignorera automatiquement les lettres et autres symboles avant et après le nombre lors de l'importation. Si aucun nombre n'apparaît, il sera analysé comme une valeur NULL. Ce qui suit est une description spécifique avec des exemples.
Tout d'abord, exécutez le script suivant pour créer un fichier texte.
dataFilePath="/home/data/testSym.csv"
prices1=["2131","$2,131", "N/A"]
prices2=["213.1","$213.1", "N/A"]
totals=["2.658E7","-2.658e7","2.658e-7"]
tt=table(1..3 as id, prices1 as price1, prices2 as price2, totals as total)
saveText(tt,dataFilePath);Dans le fichier texte créé, il y a des nombres et des caractères dans les colonnes price1 et price2. Si le paramètre de schéma n'est pas spécifié lors de l'importation de données, le système reconnaîtra les deux colonnes en tant que type SYMBOL:
tmpTB=loadText(dataFilePath)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 $2,131 $213.1 -2.658E7
3 N/A N/A 2.658E-7
tmpTB.schema().colDefs;
name typeString typeInt comment
------ ---------- ------- -------
id INT 4
price1 SYMBOL 17
price2 SYMBOL 17
total DOUBLE 16Si vous spécifiez la colonne price1 comme type INT et la colonne price2 comme type DOUBLE, le système ignorera les lettres et autres symboles avant et après le nombre lors de l'importation. Si aucun nombre n'apparaît, il sera résolu comme une valeur NULL.
schemaTB=table(`id`price1`price2`total as name, `INT`INT`DOUBLE`DOUBLE as type)
tmpTB=loadText(dataFilePath,,schemaTB)
tmpTB;
id price1 price2 total
-- ------ ------ --------
1 2131 213.1 2.658E7
2 2131 213.1 -2.658E7
3 2.658E-7
6.3 Supprimer automatiquement les guillemets doubles
Dans les fichiers CSV, des guillemets doubles sont parfois utilisés pour traiter les champs contenant des caractères spéciaux (tels que des séparateurs de milliers) dans les valeurs. Lorsque DolphinDB traite ces données, il supprime automatiquement les guillemets doubles en dehors du texte. Ce qui suit est une description spécifique avec des exemples.
Dans le fichier de données utilisé dans l'exemple suivant, num est répertorié comme une valeur numérique exprimée en milliers de sections.
dataFilePath="/home/data/test.csv"
tt=table(1..3 as id, ["\"500\"","\"3,500\"","\"9,000,000\""] as num)
saveText(tt,dataFilePath);Importez des données et affichez les données dans le tableau. DolphinDB supprime automatiquement les guillemets doubles en dehors du texte.
tmpTB=loadText(dataFilePath)
tmpTB;
id num
-- -------
1 500
2 3500
3 9000000
appendice
Le fichier de données utilisé dans les exemples de ce tutoriel: candle_201801.csv .