multithreading java
- Threads et processus
- Cycle de vie du fil
- Concept de pool de threads et scénarios d'utilisation multi-thread
- Analyse des paramètres du pool de threads
- Plusieurs méthodes d'implémentation du pool de threads JDK Executors
- Schéma de paramétrage du pool de threads
- Résumé et réflexion
- Spring Boot utilise un pool de threads
- Référence
Threads et processus
Le processus est l'unité de base du système pour la planification et l'allocation des ressources, et la base du système d'exploitation. Le fil est la plus petite unité de planification du système et l'unité de calcul du processus. Un processus peut contenir un ou plusieurs threads.
Cycle de vie du fil
Il existe six cycles de vie des threads: nouveau, prêt et en cours d'exécution, blocage, attente, minutage, attente et destruction
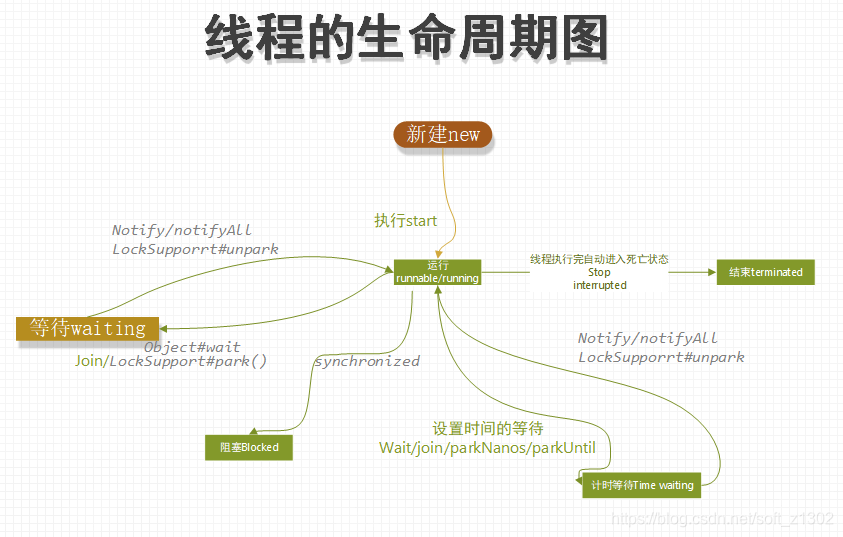
Nouveau
Il existe plusieurs façons de créer des threads: création de classe de thread, implémentation de l'interface Runnable, création Callable et Future
# 1、thread
new Thread() {
@Override
public void run() {
}
}.start();
# runnable
public class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println("runnable thread");
}
public static void main(String[] args){
Thread t = new Thread(new RunnableThread());
t.start();
}
}
# Callable&Future
public class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Callable Thread return value");
return 0;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> future = new FutureTask<Integer>(new CallableThread());
new Thread(future).start();
System.out.println(future.get());
}
}
En fait, si vous le regardez attentivement, il est finalement implémenté dans Runnable. Interprétons ensemble une partie du code source de Thread:
1. Pourquoi le thread a-t-il les six états décrits ci-dessus? C'est le java.lang défini par le thread Objet Thread .Thread.State enumeration properties
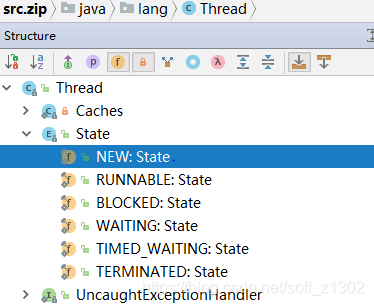
La signification et l'implémentation de chaque état sont clairement décrites en anglais. En fait, lorsque j'ai commencé à apprendre les threads pour la première fois, j'avais encore des questions. Pourquoi avez-vous besoin d'utiliser des threads et la différence entre les méthodes de démarrage et d'exécution des threads? Ensuite, interprétons personnellement le flux de code source:
线程初始化方法:
/**
* Initializes a Thread.
*
* @param g 线程组,是维护线程树的对象,所有线程必须具备的属性要素,这里可以判断线程是否具有相应的权限,以及是否合法,线程状态,是否守护线程等;目标是维护一组线程和线程组,同时我们要注意的线程之前的通讯是局限于线程组,是一组线程中维护的线程**
* @param target 运行线程的对象,线程执行时拿到的run或者call方法的目标对象
* @param name 当前线程名称
* @param stackSize 新建线程时栈大小,当为0时可忽略
*
* @param acc 上下文权限控制
*/
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
// ………… 省略部分代码
/*获取安全管理策略,主要用来检查权限相关因素,若权限不满足时,抛出异常SecurityException,启动时是通过jvm参数设置[java.security.manager],具体可查看 [java API](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/lang/SecurityManager.html)*/
SecurityManager security = System.getSecurityManager();
if (g == null) { // 当java.security.manager不设置时,这里为空
// 若需要安全管理策略,直接取得线程组
if (security != null) {
g = security.getThreadGroup();
}
// 不存在父级树寻找
if (g == null) {
g = parent.getThreadGroup();
}
}
// 检查权限
g.checkAccess();
/*
* 检测是否能被实力构造和重写
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
// 以便垃圾回收,增加未启动线程数
g.addUnstarted();
// 设置是否守护线程,线程优先级,安全控制,执行目标,堆栈长度以及线程id等
………… 省略部分代码
}
Ensuite, j'expliquerai la différence entre l'exécution directe de run et la méthode start.L'exécution de run est le corps de la méthode d'exécution de thread actuelle de la JVM existante. L'exécution de start consiste à allouer des ressources au processus où se trouve le jvm et à créer un espace frame de pile pour créer une nouvelle unité d'exécution. Allouez l'espace de trame de pile et ainsi de suite, appelez la méthode d'exécution de Thread dans l'espace de cadre de pile actuel, puis exécutez appelle la méthode d'exécution de la cible entrante (si vous êtes intéressé, vous pouvez interpréter la méthode start0 de jdk ouvert).
# Thread#run
@Override
public void run() {
if (target != null) {
target.run(); // runnable
}
}
Runable & Runnging
Lorsque nous exécutons start après avoir créé un nouveau thread, nous entrons dans l'état Ready Runnable. Lorsque la méthode run est appelée à l'intérieur du thread, elle entre dans la phase d'exécution Running, mais l'exécution directe de la méthode run ne démarre pas le thread. La vérification spécifique est comme suit.
public class RunStartThread extends Thread {
public RunStartThread(String name) {
super(name);
}
@Override
public void run() {
System.out.println(System.currentTimeMillis());
try {
sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
RunStartThread rst = new RunStartThread("runThread");
rst.run(); // 主线程运行run方法
rst.start(); // 启动子线程运行run
}
}
Exécutez la méthode run du code ci-dessus pour récupérer le vidage du thread comme indiqué ci-dessous. Nous observons que le nom du thread est " main ".
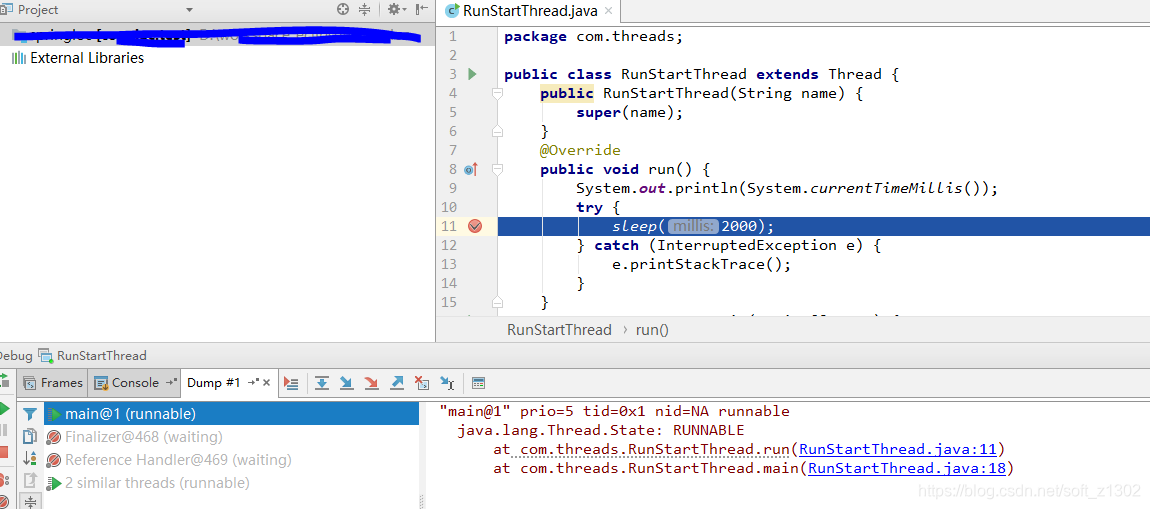
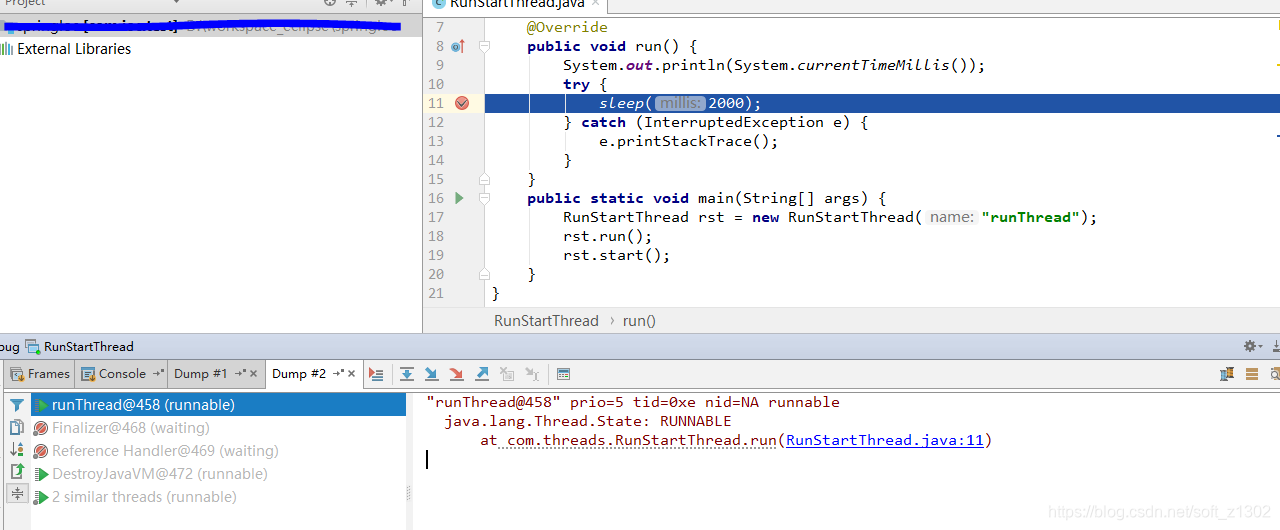
Lorsque nous exécutons la méthode start, lorsque nous récupérons le vidage, nous constatons que le nom du thread en cours d'exécution est mon nom de thread personnalisé runThread. De plus, nous avons constaté que start n'appelle pas directement l'exécution de runnable, mais appelle start0 dans la pile locale pour laisser jvm gérer la planification des threads.
Bloqué
Lorsqu'un thread entre dans l'état bloqué, il attend généralement automatiquement, puis entre dans l'état d'exécution ou meurt directement. En général, le bloc est synchronisé, comme illustré dans l'exemple de code suivant. Par conséquent, nous essayons principalement de ne pas utiliser synchronisé pendant le développement. La raison est que la libération automatique de la clé est incontrôlable. Opération monothread, le même objet ne peut pas s'exécuter en même temps, si vous avez vraiment besoin de contrôler la programmation de la sécurité des threads, essayez d'utiliser Lock:
public class BlockThreads {
public static void main(String[] args) throws InterruptedException {
TestThread th = new TestThread();
th.runThread(th,"Thread1");
th.runThread(th,"Thread2");
th.runThread(th,"Thread3");
System.out.println("111");
}
private static class TestThread {
public synchronized void sayHello() throws InterruptedException {
System.out.println(System.currentTimeMillis());
Thread.sleep(3000);
}
public void runThread(TestThread th, String threadName) {
new Thread(threadName) {
@Override
public void run() {
try {
th.sayHello();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}.start();
}
}
}
Attendre
Les méthodes qui provoquent l'attente du thread incluent Object # wait (Object # notify ou Object # notifyAll recovery), Thread # join et LockSupport # park (LockSupport # unpark), ce qui oblige le CPU à libérer des ressources en état d'attente.
Temps d'attente
Object # wait (time), LockSupport # parkNanos et LockSupport # parkUntil wait time. En fait, nous utilisons le concept de temps d'attente dans de nombreux scénarios, tels que le réglage de nginx, le réglage du temps de destruction des threads et le paramètre de délai d'attente d'accès concurrentiel. Un réglage efficace de la période d'expiration est bénéfique pour augmenter le débit du système
Terminé
La destruction des threads comprend la destruction automatique et la destruction manuelle. La destruction automatique signifie qu'après l'exécution de la méthode d'exécution par le thread, la machine virtuelle Java détruira le thread. La destruction manuelle peut être détruite à l'aide de la méthode Thread # stop, mais cette méthode a été abandonnée car il s'agit d'un violente, et la JVM interne peut être. Les informations de surveillance ne peuvent pas non plus être surveillées. La méthode Thread # interrompue effectue un jugement de destruction. Si elle ne peut pas être détruite, une exception InterruptedException se produira.
Concept de pool de threads et scénarios d'utilisation multi-thread
Un thread est une unité d'exécution et un pool de threads est un collectif composé d'un groupe d'unités d'exécution, c'est-à-dire une façon d'utiliser les threads. Le pool de threads est utilisé pour maintenir le mécanisme de démarrage, de prise et de planification des threads. Dans le processeur multicœur et la planification multi-tâches, nous pouvons utiliser le pool de threads pour gérer le multi-threading, augmenter l'utilisation du processeur tout en contrôlant la haute pression du processeur, améliorer les performances et éviter le blocage. Par exemple, envoi de SMS, requête http, tâche chronométrée, appel asynchrone, etc.
Analyse des paramètres du pool de threads
L'objet de création de thread fourni avec JDK est ThreadPoolExecutor. Il existe plusieurs paramètres dans l'objet: numéro de thread principal, nombre maximum de threads, durée de survie des threads, fabrique de threads et stratégie de rejet de threads. Le code source suivant
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
Plusieurs significations spécifiques ont une introduction textuelle simple: le nombre de threads principaux corePoolSize est le nombre de threads en cours d'exécution. Lorsque le nombre de threads en même temps est supérieur au nombre de threads principaux, les threads entrent dans la file d'attente workQueue. la file d'attente dépasse la file d'attente, un nouveau thread non essentiel (maximumPoolSize -corePoolSize) est exécuté. Lorsque le nombre de threads est supérieur à maximumPoolSize + workQueue # size, une stratégie de rejet se produit. La stratégie de rejet spécifique sera discuté plus tard. L'équipe technique de Tumei Group citée de l'équipe technique de Meituan
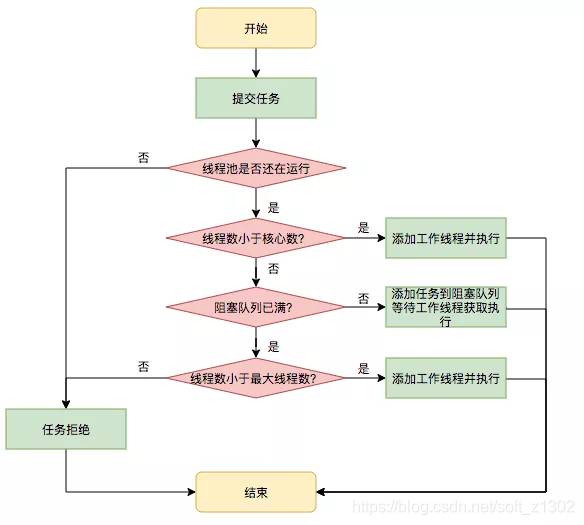
File d'attente de blocage de pool de threads BlockingQueue
Les files d'attente courantes fournies avec JDK sont LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue (en outre, il est mentionné que la longueur de la file d'attente peut être modifiée dynamiquement, par exemple, la capacité de LinkedBlockingQueue est définie sur volatile)
- LinkedBlockingQueue est un stockage de nœuds de liste liée, un modèle FIFO et, bien sûr, le stockage de type liste liée est illimité. Généralement, lorsque cela est défini, le nombre maximum de threads est fondamentalement invalide, car la longueur ne dépassera jamais, sauf si une exception OOM se produit. , il est recommandé dans les conditions de forte concurrence avec un grand nombre de threads en attente Utilisez cette file d'attente de blocage.
- ArrayBlockingQueue spécifie la longueur de la file d'attente. Ce point est de définir la file d'attente de données avec plus de précision pour réaliser la file d'attente.
- SynchronousQueue n'a pas de file d'attente de cache, et la file d'attente est toujours 0. Cette opération est généralement une opération illimitée et utilise pleinement l'utilisation du processeur. Par exemple, Executors # newCachedThreadPool est implémenté dans la deuxième méthode.
Usine de pool de threads ThreadFactory
Les fabriques de pools de threads de projets open source les plus couramment utilisées incluent CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory. La méthode factory définit principalement la priorité et le nom du thread ainsi que d'autres attributs de thread. Je ne l'expliquerai pas en détail ici. Les principaux exemples pratiques simples sont les suivants:
ublic class ThreadFactoryTest implements ThreadFactory {
private final AtomicInteger threadCount = new AtomicInteger(0);
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(), new ThreadFactoryTest());
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
executor.submit(() -> {
System.out.println(String.format("thread-Name = %s,Thread priority = %d",
Thread.currentThread().getName(), Thread.currentThread().getPriority()));
});
}
/**
* @param r 传入的线程
**/
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setPriority(2);
th.setName("设置线程名前缀" + this.threadCount.incrementAndGet());
return th;
}
}
Stratégie de rejet du pool de threads RejectedExecutionHandler
Stratégies de rejet JDK courantes AbortPolicy abort policy, exécutez run lorsque CallerRunsPolicy dépasse, ignorez lorsque DiscardPolicy dépasse et DiscardOldestPolicy supprime le dernier de la file d'attente.
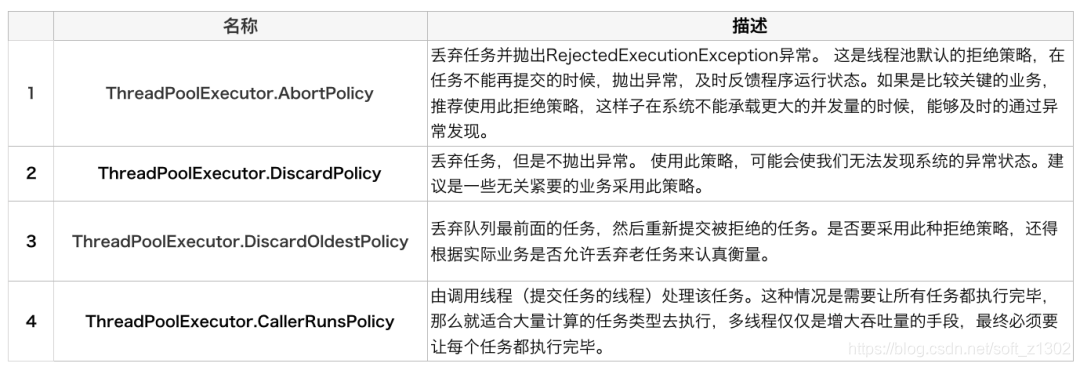
Plusieurs méthodes d'implémentation du pool de threads JDK Executors
Les exécuteurs sont des outils (généralement des outils, tels que des tableaux, des systèmes, des collections, des objets, etc.), absurdes, les exécuteurs créent des méthodes de thread newFixedThreadPool, newCachedThreadPool (analyse du code source principal de ThreadPoolExecutor) , newScheduledThreadPool, newSingleThreadExecutor, newSingleThreadSchedhread
Analyse simple du type de création
newCachedThreadPool
newCachedThreadPool fournit deux méthodes de construction à réaliser, l'une consiste à construire Executors # newCachedThreadPool (); sans paramètres, et l'autre à construire Executors # newCachedThreadPool (ThreadFactory threadFactory) avec des paramètres.
Avantages: Le nombre de threads principaux est défini sur 0, ce qui signifie que lorsque le processeur est inactif, les threads entrent immédiatement Entrez l'état d'exécution, la file d'attente est une file d'attente synchrone illimitée SynchronousQueue, qui est pleinement utilisée dans le cas de plusieurs CPU. En fait, la combinaison des deux facteurs ci-dessus montre que le thread maximum le paramètre de nombre équivaut à invalide, utilisez donc pleinement les caractéristiques des processeurs multicœurs.
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Inconvénients: une concurrence élevée entraîne une occupation du processeur à 100%, d'autres tâches de thread ne peuvent pas être traitées et la pression élevée à long terme du processeur se réchauffe et provoque des températures élevées. Notre système recommande que l'utilisation du processeur ne dépasse pas 80% et que l'utilisation normale ne dépasse pas 60%. Introduisons deux des méthodes d'exécution et une analyse supplémentaire du code source
newFixedThreadPool (analyse supplémentaire du code source)
Executors # newFixedThreadPool pool de threads de taille fixe, c'est-à-dire que le nombre de threads principaux doit être le même que le nombre maximum de threads. La file d'attente est une file d'attente linéaire illimitée. Un avantage ici est de tirer pleinement parti de la réutilisation des threads. Quant à savoir pourquoi, bien sûr, il s'agit d'interpréter le témoignage du code source: la
méthode AbstractExecutorService # submit crée la tâche FutureTask et appelle ThreadPoolExecutor # execute:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null); // 新建future任务
execute(ftask);
return ftask;
}
Ensuite, nous nous concentrerons sur l'analyse de la méthode d'exécution dans ThreadPoolExecutor # executor, qui est divisée en trois étapes ( un point mentionné ici, le nombre de threads et l'état sont passés par le CTL 32 bits d'AtomicInteger, les trois bits supérieurs sont conservation de l'état, et le faible 29 est le nombre maximal de pools de threads ):
int c = ctl.get();/* 获取主线程状态控制29位变量 */
if (workerCountOf(c) < corePoolSize) { /* 前29位作为统计线程数,判断worker是否大于核心线程数 */
if (addWorker(command, true)) /* 添加worker工作线程,若新建成功则执行线程,并返回true */
return;
c = ctl.get(); /* 再次检测当前线程地位29 */
}
if (isRunning(c) && workQueue.offer(command)) { // worker无法获取和创建,插入等待队列
int recheck = ctl.get(); // 再次检测线程池worker大小
if (! isRunning(recheck) && remove(command)) // 若线程池不可运行状态,且移除当前线程成功,则拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0) // 若当前没有线程worker,即核心线程为0,则立即执行队列
addWorker(null, false);
}
else if (!addWorker(command, false)) // 队列已经满了,则直接添加非核心线程并运行
reject(command); // 运行或者创建非核心线程失败,则拒绝策略
À partir de l'analyse ci-dessus, on peut voir que l'état du pool de threads est enregistré dans les trois bits supérieurs et que les 29 bits inférieurs sauvegardent le nombre de threads en cours d'exécution.
Ensuite, concentrez-vous sur le travailleur et la tâche
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
// ……………… 省略部分代码
for (;;) {
// ……………… 省略部分代码
// 这里判断最大worker数,查看是核心线程还是最大线程,若超出范围直接返回创建worker失败
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 创建worker前检测后并增加运行线程数
break retry;
}
}
// …………
Worker w = null;
try {
// 新建worker,同时调用ThreadFactory的newThread进而线程池的参数,比如参数名称等
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock; // 获取线程池锁
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 判断是否有效范围内
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 创建worker成功后直接调用线程的start方法执行线程,并且返回成功,调用worker启动后将会执行run方法。
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Après l'analyse du code, les nœuds de calcul sont ultimement responsables de la planification des tâches. Lorsque le nombre de threads est supérieur au nombre de threads principaux, le thread transmis par le worker est vide et les tâches à exécuter sont placées dans la file d'attente de travail. ( ie nouveau Worker-> start worker -> runWork -> getTask -> runTask ), la vérité réside dans notre méthode runWorker comme suit. Il existe un " concept de priorité de soumission ", la tâche principale du thread est exécutée en premier! = Null et ensuite getTask () est exécuté, ce qui signifie que le thread avec le débordement de file d'attente est en fait exécuté en premier. Parce que le code ci-dessus, execute explique la file d'attente de débordement et directement addworker a la priorité sur l'ajout de la file d'attente.
/*
worker启动时,委托给主线程的runWorker
*/
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
// ………省略部分代码
// 获取当前任务,当时非核心时且添加进队列时为null,需要从队列中获取
Runnable task = w.firstTask;
// …………
/* 当任务为空,且队列也不为空是,不执行 */
while (task != null || (task = getTask()) != null) {
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null; //这个地方非常关键,执行完后队列中查找。
w.completedTasks++;
w.unlock();
}
}
Schéma de paramétrage du pool de threads
Les deux facteurs que nous prenons généralement en compte sont le processeur et les E / S. Les paramètres généraux concernent les ressources CPU et E / S, mais il doit être analysé en combinaison avec des scénarios commerciaux réels, tels que la consommation de temps, les tps et d'autres facteurs à allouer threads principaux raisonnablement Il est préférable de définir dynamiquement les paramètres (JDK prend en charge l'ajustement dynamique du nombre de threads principaux, du nombre maximum de threads et de la longueur de la file d'attente, combiné à la mise à jour dynamique du centre de configuration apollo, tel que le Meituan équipe technique ).
CPU à haute intensité, le nombre de fils de base est réglé sur le nombre effectif de processeurs 1 et le nombre maximal de fils est fixé à 2 × le nombre effectif de CPU 1, ce qui peut provoquer une certaine animation suspendue.
Le type IO-intensive signifie que le nombre de threads de cœur est de 2 × le nombre effectif de processeurs , et le nombre maximum de threads est de 25 × le nombre effectif de processeurs , comme suit
Paramètres définis dynamiquement
La définition dynamique de la taille du pool de threads permet de gérer les problèmes de pointe et d'ajuster les données du pool de threads. La méthode adoptée est ThreadPoolExecutor # setCorePoolSize pour définir dynamiquement le nombre de threads principaux. InterruptIdleWorkers peut effacer les nœuds de calcul inactifs afin d'occuper les ressources, comme indiqué dans le code suivant:
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize; // 设置的核心线程数和原来的差值
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize) // 工作worker是否大于设置的核心线程数,如果大于则当worker空余时清空。
interruptIdleWorkers(); // 这方法其实很重要,我们可以用来设置回收没有使用的核心线程数,
else if (delta > 0) { // 若设置线程数大于原有线程数,则看队列是否有等待线程,如果有则直接循环创建worker并执行task任务,知道worker大于最大线程数或者队列已空
// We don't really know how many new threads are "needed".
// As a heuristic, prestart enough new workers (up to new
// core size) to handle the current number of tasks in
// queue, but stop if queue becomes empty while doing so.
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
Résumé et réflexion
1. addWorker (Runnable firstTask, boolean core) Créer un nouveau worker. Lorsque le paramètre firstTask de cette méthode est vide, la fonction de préchauffage est similaire au chargement
différé par ressort. 2. setCorePoolSize définit dynamiquement le nombre de threads de base
3. setMaximumPoolSize dynamiquement définit le nombre maximum de threads
4, CPU-intensive et IO-intensive
5, runWorker worker execution tasks
6, interruptIdleWorkers destroy idle core threads
7, Executors create thread methods newFixedThreadPool, newCachedThreadPool, newScheduledThreadPool, newSingleThreadExecutor
8, exécutent et soumettent la priorité d'exécution et la soumission priorité, et deux La différence est qu'il existe des valeurs de retour et ainsi de suite.
9. Plusieurs façons de créer des threads: Thread, runnable, Callable et future, et l'état des threads, l'utilisation du débogage de la pile JVM
10. Thread de blocage courants LinkedBlockingQueue, ArrayBlockingQueue, SynchronousQueue
11. Usines de threads communes CustomizableThreadFactory, ThreadFactoryBuilder, BasicThreadFactory et objectif
12. Plusieurs classes d'implémentation courantes de RejectedExceptionHandler AbortPolicy, CallerRunsPolicy, DiscardPolicy, DiscardOldestPolicy
13. Comment définir dynamiquement le nombre de threads principaux et le nombre maximum de threads et la file d'attente de blocage
14. Quelles sont les significations de ThreadGroup et securityManager
15. Ajout de suivi ............. .....
Spring Boot utilise un pool de threads
La production ici est simple et pratique, et l'utilisation détaillée doit être combinée avec la scène réelle:
@SpringBootTest
@EnableAsync
class PoolApplicationTests {
@Autowired
private PoolService poolService;
@Test
void contextLoads() {
poolService.say1();
poolService.say2();
}
}
@Service
public class PoolService {
@Value("${spring.pool.core.size:5}")
private int coreSize;
@Value("${spring.pool.max.size:10}")
private int maxNumSize;
/**
* 自定义线程池
*
* @return
*/
@Bean("executor")
public Executor executor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize);
executor.setMaxPoolSize(maxNumSize);
executor.setQueueCapacity(20);
executor.initialize();
return executor;
}
/**
* 在目标线程池执行任务
*/
@Async(value = "executor")
public void say1() {
System.out.println(Thread.currentThread().getName());
}
@Async(value = "executor")
public void say2() {
System.out.println(Thread.currentThread().getName());
}
}
Référence
[1] Code source JDK 1.8
[2] Équipe technique Meituan (citations partielles d'images et points de connaissance)
[3] Enfiler et traiter l'Encyclopédie Baidu