Puisqu'il s'agit de "Classement sur la sous-base de données et la sous-table", nous devons déterminer de quoi nous voulons parler et de quoi ne pas parler.
- Tout d'abord, nous ne discutons pas de l'implémentation et du code source du cadre de sous-table de sous-base de données spécifique, ce qui n'est pas le cadre de notre discussion.
- Nous discutons des idées, discutons principalement des routines de la façon de diviser la base de données et la table, quels sont les pièges, et quelle expérience avez-vous. Nous ne discuterons pas des détails spécifiques. Bien sûr, mes propres capacités sont limitées, mais j'espère juste pouvoir en attirer d'autres.
- Nous devons préciser que la sous-base de données et la sous-table ne sont pas une solution miracle , c'est juste un moyen pour nous d'économiser des coûts lorsque les performances autonomes de MySQL ne sont pas suffisantes. Pour le patron, il veut faire des économies, mais aussi soutenir l'entreprise et offrir des performances stables et durables.
Les programmeurs exercent leur ingéniosité, se creusent la cervelle, travaillent dur et s'entraînent jour après jour, et enfin produisent deux méthodes principales:
- Le mode intégré d'agent utilise un package jar pour s'intégrer dans notre code. Le code utilise des règles de routage et des clés de partitionnement pour diviser la base de données et les tables, ce qui est un mode intégré.
- Le mode cs (mode client-serveur) fournit un composant tripartite, tel que mycat, le mode proxy dans sharding -sphere, similaire à mycat; il y a centralisation, et la haute disponibilité des composants tripartites doit être garantie .
S'il y a une meilleure sélection technique, nous préférerions ne pas sous-bibliothèque et sous-table, car c'est une solution compliquée en soi. C'est juste un compromis.NewSQL et les bases de données commerciales sont plus adaptés (par exemple, Oracle, dans la plupart des scénarios, les performances sont suffisantes, mais le coût est élevé).
Si un jour, il y a un excellent newSQL économique, comme oceanbase, tidb, alors nous pouvons dire adieu à la sous-base de données et à la sous-table.
La raison pour laquelle nous choisissons d'utiliser la stratégie de base de données et de table est fondamentalement parce que, d'une part, notre coût d'utilisation ne peut pas être trop élevé; d'une part, les performances de la base de données DB autonome ne sont pas suffisantes; d'autre part part, newSQL est actuellement immature et trop cher, n'osez pas l'utiliser.
Il existe de nombreux fabricants de sous-bibliothèques et de sous-tables, de riches frameworks open source, de communautés et de cas matures, nous adoptons donc,
La raison directe est qu'Ali est sur la plate-forme. Notre philosophie nationale est que j'utilise ce qu'Ali utilise et comment Ali le fait. Je suis la tendance si sérieusement. Mon idée est que nous avons encore une vision prospective de notre propre technologie, et il vaut mieux ne pas compter sur Ali, uniquement sur la technologie.
Cela dit, nous revenons au sujet et commençons à examiner le problème.
1. Est-il acceptable de créer uniquement des sous-tableaux? Vous devez encore diviser la table et diviser la bibliothèque, si elle est divisée, la bibliothèque est sur plusieurs serveurs? Comment considérer cela
Je veux dire, ou regarder l'échelle de l'entreprise , seulement pour voir l'échelle actuelle des opérations, mais aussi regarder vers les 3 à 5 prochaines années de tendances commerciales.
En ce qui concerne la sélection de la technologie, notre objectif est de toujours choisir celle qui convient le mieux à l'activité actuelle, le coût le plus bas, le profit le plus élevé et ce qui est approprié est le meilleur.
La meilleure solution que nous choisissons est celle que l'équipe technique peut simplement détenir. Si la sélection n'est plus adaptée au développement commercial actuel, vous pouvez en choisir une plus adaptée. C'est la loi inévitable du développement des choses.
Ou bien, l'entreprise ne s'est pas développée à un niveau supérieur, elle est déjà GG, alors c'est juste, ne gaspillez pas d'argent pour acheter de meilleures installations, arrêtez simplement la perte;
Ou, le plan actuel n'est vraiment pas suffisant, nous avons changé un ensemble de plus puissant, même si cela coûtera plus d'argent, s'il vous plaît plus de gens, mais ce n'est pas dans notre esprit, notre objectif En soi, il soutient le développement commercial grâce à une architecture technique appropriée et un meilleur code.
Le résumé en une phrase est que puisque vous devez dépenser de l'argent, dépensez-le.
Discussion par scène
Une image vaut mille mots. Examinons ces deux scénarios séparément.
Pour les scénarios d'analyse de données hors ligne
Seul le sous-tableau suffit, car vous êtes principalement utilisé pour analyser les données et les données après les données d'analyse peuvent être supprimées. Les tâches asynchrones suppriment plusieurs mois / jours de données.
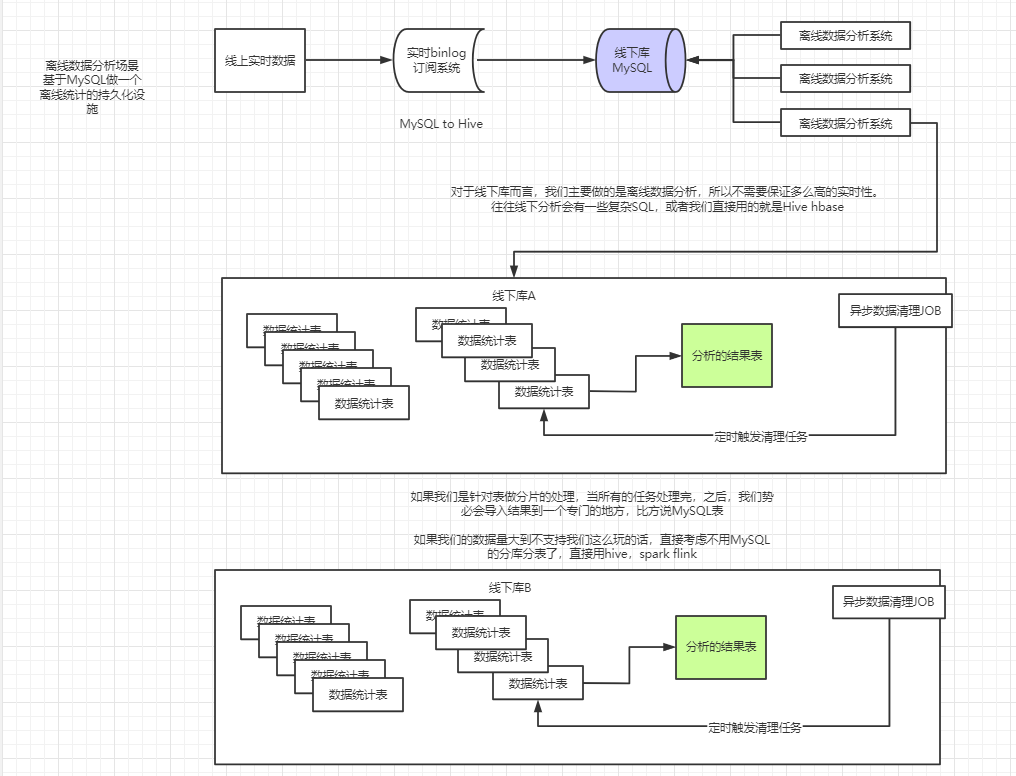
Pour les systèmes d'entreprise en temps réel
S'il s'agit d'un système commercial distribué 2C, qui a besoin de transporter une quantité énorme de trafic, il est recommandé de considérer à la fois la base de données et la table .
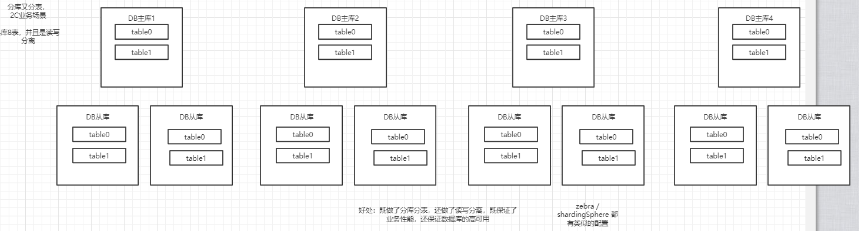
Prérequis pour la sous-bibliothèque, volume d'activité estimé
Le principe de la sous-base de données et du sous-tableau est d'estimer le volume d'activité. Nous fournissons une valeur empirique, qui ne représente pas la plus appropriée, mais qui n'est qu'une analyse qualitative:
QPS 500-1000以下, 那么采用主从读写分离,基本上足够支撑业务了;
QPS 1000-10000,考虑分布分表是一个比较合适的事情
12000TPS 30000QPS 32库 1024表
1000多万 16000QPS 16库512表
Essentiellement: la sous-base de données et la sous-table constituent une vente unique . La conception initiale est très importante et détermine la difficulté d'une expansion ultérieure et de la migration des données. Dans la conception préliminaire, il y a une forte probabilité que nous ayons besoin de planifier pour les 3 à 5 prochaines années. À court terme, nous devons planifier sur 1 à 2 ans. Selon le plan, déterminer s'il faut diviser la base de données et la table, ainsi que le nombre de bibliothèques et de tables.
Revenons au problème lui-même, cela dépend principalement du volume d'affaires actuel et du taux de croissance du volume d'affaires.
Sur la base de ces dimensions, nous donnons un ensemble de formules:
某年数据增量M = (1 + 数据年增速K)^ n * 初始数据量 N
第一年增量 M1 = (1+k) * N
第二年增量 M2 = (1+K)^2 * N
第三年增量 M3 = (1+K)^3 * N
三年数据总量 M' = N + m1 + m2 + m3
Calculons avec un seul tableau contenant 10 millions de données. Il y a plusieurs tableaux au total. Actuellement, ce n'est pas nécessairement 1 000 W, mais 2 000 W-5000 W, c'est bien. Il s'agit d'une part d'une valeur empirique et d'autre part d'une analyse quantitative est nécessaire.
L'analyse quantitative nécessite des tests de pression. Nous devons utiliser une instance de bibliothèque pour effectuer des tests de résistance pour votre configuration en ligne. Dans cette configuration, sans affecter le débit du système, la capacité maximale d'un seul compteur est un lien sûr., Ce qui peut bien nous guider au début de la conception .
Nous discutons ensuite, quand avons-nous besoin de sous-base de données, devons-nous nous assurer que chaque base de données est une instance indépendante?
Non, nous devons encore analyser des problèmes spécifiques en détail.
S'il s'agit d'un environnement de développement, c'est-à-dire pour développer une bibliothèque pour RD afin d'écrire du code, plusieurs ensembles de bibliothèques peuvent être utilisés sur une machine. Après tout, l'environnement de développement n'a pas de concurrence et est utilisé au maximum pour le développement. tant qu'il n'est pas utilisé pour les tests de résistance, il n'y a pas de problème.
S'il s'agit d'un environnement en ligne, en plus de déployer la bibliothèque sur plusieurs machines, vous devez également tenir compte de la séparation de la lecture et de l'écriture et de la haute disponibilité de la bibliothèque. La principale différence entre en ligne et hors ligne est qu'il existe des exigences de haute disponibilité en ligne, mais pas hors ligne .
Pensez à la différence entre les deux, la différence réside dans le contrôle des coûts .
Nous concluons que lorsque nous voulons déployer la base de données sur une instance de machine, cela dépend du scénario, du coût et si nous en avons besoin. Analysez des problèmes spécifiques.
2. Comment générer des clés de routage? L'algorithme de flocon de neige peut-il être utilisé? Si la clé primaire de la base de données d'origine augmente automatiquement, il n'y a pas de contrainte métier unique, si après la migration, comment les données d'origine peuvent-elles être acheminées dans la sous-base de données et la sous-table?
bonne question.
Tout d'abord, comment générer la clé de routage?
Il s'agit essentiellement de savoir comment mettre en œuvre un émetteur distribué fiable . On ne parle que d'idées, car on peut en parler, mais ça fait longtemps qu'on en parle seul.
Idées:
Pour certains frameworks, ils ont leur propre générateur de clé primaire, comme l'algorithme SnowFlake de classe shardingSphere / ShardingJDBC;
- UUID: format de chaîne, certes unique, mais mauvaise lisibilité, difficile à faire des calculs mathématiques, pas intuitif, relativement long, et occupe un grand espace
- SNOWFLAKE: Il peut être utilisé, ou il peut être utilisé pour améliorer la feuille. Leaf lui-même est un ensemble complet d'émetteur de numéros distribués, et il a également une garantie de haute disponibilité.
Bien sûr, il existe d'autres moyens:
Étant donné que vous avez déjà créé une sous-base de données et une sous-table, il y a une forte probabilité que votre système soit également distribué, donc l'utilisation de la numérotation en cours n'est pas un moyen idéal.
Si vous souhaitez simplement implémenter un service d'émission de numéros distribués, nous pouvons utiliser l'incrément redis pour implémenter un ensemble d'émetteur, ou utiliser l'identifiant unique auto-incrémenté de la base de données pour le faire, mais nous devons encore le développer nous-mêmes pour implémenter un système d'émission de numéros.
Utilisez simplement l'image précédente pour exprimer vos réflexions. Ce contenu sera écrit dans un article séparé plus tard.
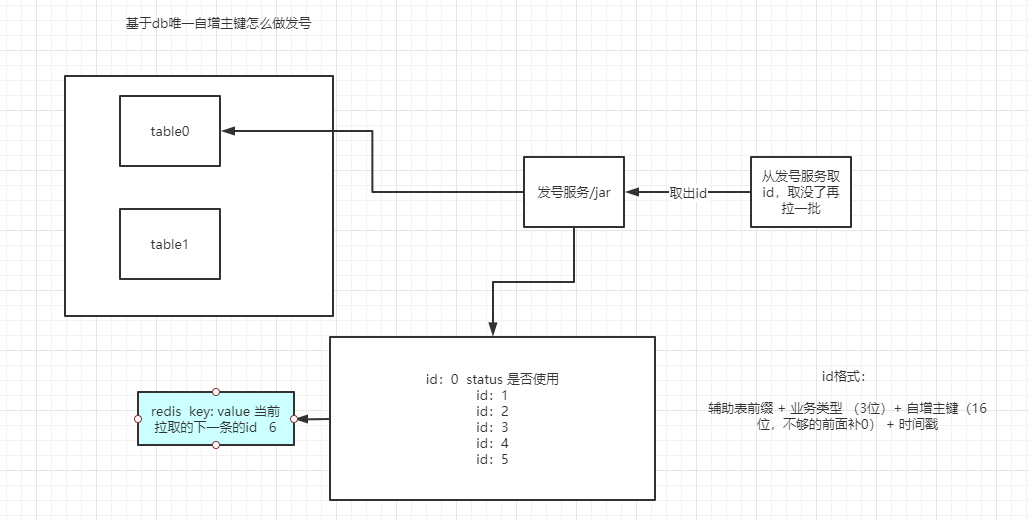
Pour résumer, il s'agit essentiellement de savoir comment mettre en œuvre un émetteur distribué fiable.
Par conséquent, la question de se fier à un mécanisme d'émission de numéro distribué spécifique n'a pas besoin d'être mêlée. Faites simplement attention à la sélection finale et faites plus de compromis.
3. S'il s'agit d'une seule base de données, qu'il n'y a pas de clé de routage et que la clé primaire est utilisée comme identifiant unique, comment puis-je jouer avec la sous-base de données et la table?
C'est très simple. Quel est votre identifiant unique d'origine? Vous pouvez l'utiliser après la sous-table de la sous-base de données.
Cependant, comme il n'y a pas de clé d'attribut métier, il est recommandé d'ajouter une clé primaire naturelle de l'attribut métier après la migration des données, et il est fort probable que vous deviez configurer de nouvelles règles de routage.
Le processus spécifique est:
- Migrer les données
- Modifiez la configuration de routage pour spécifier une nouvelle règle de requête, des règles de routage pour les sous-bases de données et les sous-tables
- Modifiez le code pour inclure le code CRUD dans le code, tel que le code contenu dans DAO et le référentiel, et ajoutez des règles de routage au code. En termes simples, vous pouvez toujours utiliser l'ID d'origine pour effectuer des requêtes, des insertions et des suppressions, mais principalement Le point de changement est que vous devez avoir une règle de routage.
Nous disons que le noyau de la migration de la base de données vers la table quelle que soit la table: pour garantir l'intégrité des données, le code doit être refactorisé, il est difficile d'avoir un programme complet qui n'a pas besoin de changer le code, nous pouvons seulement compromis et réduire le degré de complexité.
L'ID de clé primaire d'origine a été migré vers la nouvelle sous-base de données et la nouvelle sous-table de la base de données. Il n'est plus continu, mais il doit être unique. La clé primaire à incrémentation automatique dans la nouvelle table de base de données doit toujours avoir, mais il n'y a pas d'attribut métier La raison de la sous-base de données Une fois la table divisée, une clé primaire auto-incrémentée est nécessaire, principalement pour améliorer l'efficacité de l'insertion et de la requête. Dans l'arborescence d'index de clé primaire, revenez à l'opération de table.
Cela équivaut au fait que vous utilisiez à l'origine l'identifiant d'auto-incrémentation pour avoir des attributs d'entreprise. Voici une digression, essayez de ne pas utiliser la clé primaire d'auto-incrémentation pour représenter la signification de l'entreprise .
3. Comment choisir la clé de partition
Notre réponse ne peut toujours pas donner une déclaration précise, je peux seulement dire que nous devons choisir en fonction des exigences du scénario commercial.
C'est trop général, exprimons-le à travers quelques exemples.
对于用户表,使用用户唯一标识, 如:userId作为分片键;
对于账户表,使用账户唯一标识,如:accountId作为分片键;
对于订单表,使用订单唯一标识, 如:orderId作为分片键;
对于商家相关信息表,使用商家唯一标识, 如:merchantId作为分片键;
......
Si nous voulons vérifier la commande d'un utilisateur, nous devons utiliser userId pour accéder à la table de routage et insérer la commande dans la table des commandes pour nous assurer que toutes les commandes d'un utilisateur peuvent être distribuées sur un fragment de table. Cela peut éviter l'introduction de transactions distribuées.
Si nous disons que la dimension n'est pas l'utilisateur, mais d'autres dimensions, par exemple, nous voulons interroger les commandes de tous les utilisateurs d'un certain marchand .
Ensuite, nous devrions utiliser le marchandId du marchand pour stocker une copie des données. Lors de l'acheminement, utilisez l'ID du marchand pour acheminer. Tant qu'il s'agit d'une commande utilisateur de ce marchand, nous l'écrivons dans la table des commandes du marchand. Ensuite, pour la commande auquel appartient le marchand, nous Il peut être obtenu à partir d'un éclat.
Utilisez un diagramme pour exprimer clairement la description ci-dessus:
Pour les utilisateurs, la fonction de la clé de partitionnement est la suivante:
usertable.pngPour les marchands, la fonction de la clé de
partition est la suivante: merchanttable.png
Notre conclusion est donc la suivante: nous devons choisir en fonction des exigences du scénario d'entreprise, analyser les problèmes spécifiques en détail et essayer de nous assurer qu'aucune transaction distribuée n'est introduite pour améliorer l'efficacité des requêtes.
De plus, pour l'approche standard, si vous avez besoin d'avoir des requêtes complexes, soit en double écriture basée sur différentes dimensions, soit vous pouvez directement interroger en introduisant une méthode hétérogène, telle que l'utilisation de la recherche élastique ou de la ruche.
4. Lors de l'insertion de données par lots, il insérera dans chaque sous-base de données, s'il faut faire des transactions distribuées dans les affaires réelles
La troisième question mentionnait plus ou moins aussi la réponse à cette question.
Dans le processus de mise en œuvre de la sous-base de données et de la table, nous devons essayer d'éviter d'introduire des transactions distribuées .
Parce qu'à partir de la troisième question ci-dessus, vous constaterez que si nous avons une clé de routage, le problème est beaucoup plus simple: dans la plupart des cas, nous n'avons pas besoin d'introduire des transactions distribuées, mais ce sera douloureux si nous ne le faisons pas.
Pour les encarts dans le désordre et la nécessité de garantir des scénarios transactionnels d'insertion, des transactions distribuées sont requises. Mais c'est trop inefficace et inapproprié.
Premièrement, il n'y a pas beaucoup de scénarios d'insertion dans le désordre. Deuxièmement, si des transactions distribuées sont introduites, la force des transactions n'est pas faible et cela a un impact significatif sur les performances de l'insertion. Pas le meilleur moyen.
Ma suggestion est de le faire sur la base d'une cohérence éventuelle. Sinon, l'introduction de transactions distribuées affectera trop l'efficacité et augmentera la complexité du système. Je pense que le but de notre système de conception est que nous n'avons pas besoin de solutions compliquées. Si vous avez le temps de boire du thé, pourquoi ne pas faire autre chose.
La conclusion de cette question est donc: essayez d'éviter les transactions distribuées, si vous devez les introduire, vous devez minimiser la portée et l'intensité des transactions. Par compromis, réfléchissez davantage à la faisabilité du système. Les
performances sont très importantes. Cela peut être fait sans transactions distribuées. La façon de le faire passe par la cohérence éventuelle.
Cependant, si vous dites "Je ne peux pas éviter les transactions distribuées, que dois-je faire". Ensuite, utilisez-le, si ce n'est pas nécessaire, n'augmentez pas l'entité. Si vous devez l'utiliser, utilisez-le, rien à dire.
5. S'il y a plusieurs tables dans une bibliothèque, et qu'une table est divisée en tables, comment placer les tables sans diviser les tables et les tables Est-elle affectée à une certaine bibliothèque dans la branche?
Essentiellement: Il s'agit d'un problème de distribution des données de non-sous-base de données et de sous-table et des données de sous-base de données et de sous-table.
En fait, les intergiciels pour les sous-bases de données et les sous-tables ont souvent des fonctions correspondantes. Cette fonction est souvent appelée règles de routage par défaut . Comment la comprenez-vous?
C'est-à-dire que pour ces tables sans sous-bases de données et sous-tables, les règles de routage par défaut sont suffisantes, de sorte qu'elle sera toujours acheminée vers la DataSource par défaut.
C'est équivalent à une liste blanche. Recherchez la documentation du middleware pour voir comment les règles de routage par défaut sont configurées. Fondamentalement, le middleware considère ce problème. Pour ShardingSphere, un exemple de configuration est le suivant:
CustomerNoShardingDBAlgorithm
default-table-strategy: (缺省表分区策略)
complex:
sharding-columns: db_sharding_id
algorithm-class-name: com.xxx.XxxClass
tables:
ops_account_info: (必须要配置这个,才能使用缺省分表策略)
actual-data-nodes: db-001.ops_account_info
Pour donner un exemple détaillé, par exemple:
Lorsqu'un service est une sous-base de données dans la base de données d'origine (par exemple, la base de données utilisateur est divisée en utilisateur01 et utilisateur02), force-t-il les tables non distribuées à être acheminées vers une certaine base de données (par exemple, acheminer les tables non distribuées tables à user01)?
L'essence mentionnée ici est la suivante: Règles de routage par défaut, nous n'avons besoin que de configurer certaines tables pour suivre les règles de routage par défaut. Par exemple, nous avons maintenant la table des utilisateurs, la table des commandes et la table de configuration. Parmi elles, la table des utilisateurs et la commande sous-table de sous-base de données, et config n'a pas de sous-base de données et de sous-table.
Ensuite, il suffit de mettre la table de configuration dans la bibliothèque 0, 1 bibliothèque, 2 bibliothèque de la bibliothèque utilisateur, n'importe où,
Après l'avoir mis en place, il suffit de configurer les règles de routage par défaut dans le fichier de configuration de la sous-base de données et du middleware de sous-table, et de configurer spécialement la table de configuration. Il suffit de vérifier la table de configuration et d'accéder à la bibliothèque spécifiée.
D'autres sont similaires, tant qu'il y a une telle demande, ajoutez la configuration correspondante.
Vous devez explicitement indiquer au middleware quelles tables ne respectent pas les règles de routage et lui indiquer où ces tables sont placées.
Il est préférable de les placer dans une bibliothèque avec un petit nombre de requêtes, ou vous pouvez créer une bibliothèque séparément. La bibliothèque met des tables qui n'effectuent pas de sous-tables de sous-base de données,
et ne configure aucune règle de routage à faire, en fait, il s'agit toujours des règles de routage par défaut.
Pourquoi fais-tu cela? Quelle est l'intention?
Ma compréhension est la suivante: la raison pour laquelle nous divisons la base de données et les tables est que la demande est très grande et que la concurrence doit être réduite; et pour les tables à faible fréquence de demande, nous pouvons utiliser la table sans diviser la base de données et la table ou utilisez-le dans une seule table, alors nous pouvons simplement le configurer comme règle de routage par défaut.
8. Processus de migration des données et comment garantir la cohérence des données
Dans un résumé simple, la migration des données repose sur une double écriture des données; la cohérence des données repose sur la vérification de l'intégrité des données.
Pour la migration, nous avons les étapes suivantes:
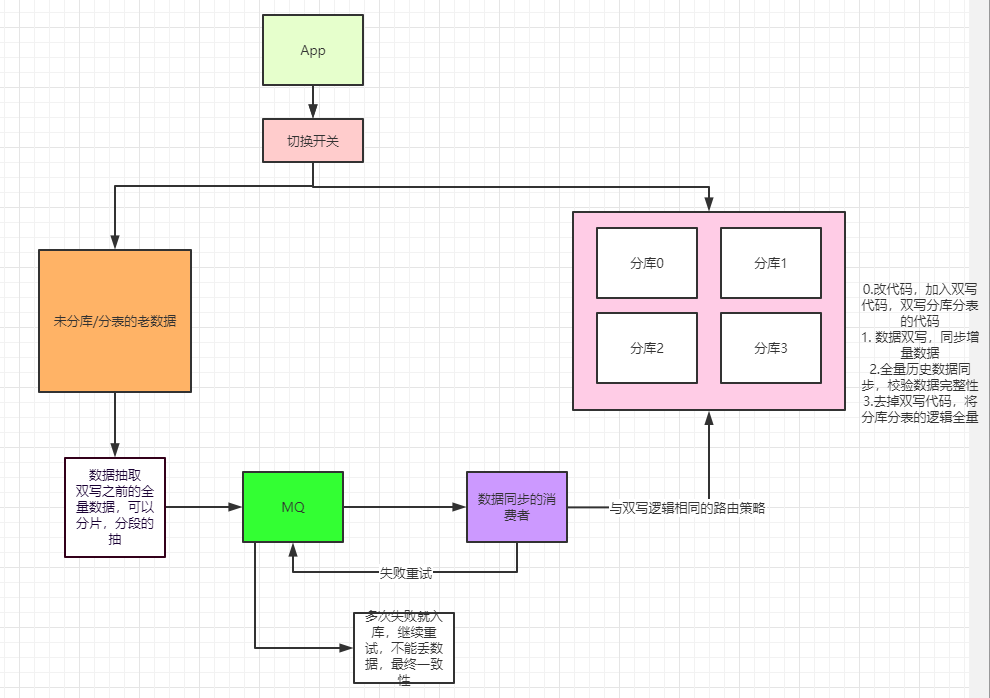
- Modifiez d'abord le code, ajoutez le code de sous-table de sous-base de données à double écriture; allez en ligne
- Démarrez les données en double écriture, données incrémentielles synchrones; double écriture, le but principal est de rattraper les données en temps réel, une date limite pour la quantité totale de données synchrones, pour garantir que les données après cette heure sont complètes (à la même temps, grâce à un contrôle asynchrone de l'intégrité des données Le programme vérifie l'intégrité des données, mais si nous pouvons assurer la fiabilité de la double écriture, cette comparaison peut être faite ou non. Il vaut mieux le faire)
- Synchronisez la totalité des données historiques et vérifiez l'intégrité des données. En règle générale, la totalité des données est synchronisée et n'a pas besoin d'être écrite de manière synchrone. La raison en est que l'écriture synchrone a un degré élevé de couplage de code et un impact sur le système. Par conséquent, nous écrivons souvent de manière asynchrone, et ce processus est illustré dans le texte suivant;
- Supprimez le code de double écriture et interrogez la logique complète de la sous-base de données et de la sous-table;
via le commutateur, passez à la logique de sous-base de données et de sous-table en lecture-écriture complète une fois la synchronisation complète des données terminée. Pour le moment, l'ancienne logique n'a pas d'acheminement des demandes. Il suffit de trouver une fenêtre de lancement pour mettre hors ligne l'ancienne logique. À ce stade, la ligne a été complètement migrée vers le flux de code de la sous-base de données et de la sous-table.
Enfin, je veux dire que nous devons revenir, nous devons revenir, nous devons revenir! ! !
Lien original: http://wuwenliang.net/2021/01/09/Distributed Routines: Discuting the Sub-database and Sub-table /
Si vous pensez que cet article vous est utile, vous pouvez suivre mon compte officiel et répondre au mot-clé [Interview] pour obtenir une compilation des points de connaissances de base Java et un coffret cadeau d'entrevue! Il y a plus d'articles techniques de produits secs et de matériaux connexes à partager, laissez tout le monde apprendre et progresser ensemble!
