Le principe de fonctionnement du pool de connexion à la base de données:
1) Le pool de connexions à la base de données créera des connexions initialSize lors de son initialisation. Lorsqu'il y a une opération de base de données, une connexion sera retirée du pool; si le nombre de connexions actuellement utilisées dans le pool est égal à maxActive, il attendra un moment et attendra d'autres opérations
Si une connexion est libérée, si le temps d'attente dépasse maxWait, une erreur sera signalée;
si le nombre de connexions actuellement utilisées n'atteint pas maxActive, il est jugé si la connexion actuelle est inactive, s'il y en a, alors la connexion inactive est utilisée directement, sinon, une nouvelle est établie connexion.
Une fois la connexion utilisée, la connexion physique n'est pas fermée, mais elle est placée dans le pool pour attendre que d'autres opérations soient réutilisées.
2) En même temps, il existe un mécanisme à l'intérieur du pool de connexions pour déterminer que si le nombre total actuel de connexions est inférieur à miniIdle, une nouvelle connexion inactive sera établie pour garantir que le nombre de connexions obtient miniIdle.
Si une connexion dans le pool de connexions actuel n'est toujours pas utilisée après que timeBetweenEvictionRunsMillis soit inactif, elle sera physiquement fermée.
Certaines connexions à la base de données ont des restrictions de délai d'expiration (la connexion mysql est déconnectée après 8 heures), ou en raison d'une interruption du réseau et d'autres raisons, la connexion du pool de connexions échouera. À
ce stade, définissez un paramètre testWhileIdle sur true pour vous assurer que le pool de connexions est interne Détectez régulièrement la disponibilité des connexions, les connexions indisponibles seront supprimées ou reconstruites et, dans la
mesure du possible, pour garantir que l'objet Connection obtenu à partir du pool de connexions est disponible. Bien sûr, afin de garantir une disponibilité absolue, vous pouvez également utiliser testOnBorrow comme true (c'est-à-dire pour détecter la disponibilité de l'objet Connection lorsqu'il est obtenu), mais cela affectera les performances.
Points à noter sur le pool de connexions à la base de données
1. Problèmes de concurrence
Afin de maximiser la polyvalence des services de gestion de connexion, un environnement multithread doit être pris en compte, c'est-à-dire des problèmes de concurrence. Ce problème est relativement facile à résoudre, car chaque langage lui-même prend en charge la gestion de la concurrence telle que java, c #, etc., l'utilisation du mot clé synchronized (java) lock (C #) peut garantir que les threads sont synchronisés. La méthode d'utilisation peut faire référence à la littérature connexe.
2. Traitement des transactions
Nous savons que les transactions sont atomiques, à ce stade, le fonctionnement de la base de données doit respecter le principe "TOUT OU RIEN", c'est-à-dire que pour un groupe d'instructions SQL, tout ou rien n'est fait.
Nous savons que lorsque deux threads partagent un objet Connection Connection, et que chacun a sa propre transaction à traiter, c'est un casse-tête pour le pool de connexions, car même si la classe Connection fournit le support de transaction correspondant, nous ne pouvons toujours pas en être sûrs. L'opération de base de données correspond à cette transaction, qui est causée par le fait que nous avons 2 threads dans l'opération de transaction. A cette fin, on peut utiliser chaque transaction pour monopoliser une connexion à réaliser, bien que cette méthode soit un peu un gaspillage de ressources du pool de connexions mais peut grandement réduire la complexité de la gestion des transactions.
3. Allocation et libération du pool de connexions
L'allocation et la libération du pool de connexions ont un impact important sur les performances du système. Une allocation et une libération raisonnables peuvent augmenter la réutilisation des connexions, réduisant ainsi le surcoût lié à l'établissement de nouvelles connexions, et peuvent en même temps accélérer l'accès des utilisateurs.
Une liste peut être utilisée pour la gestion des connexions. Autrement dit, placez toutes les connexions qui ont été créées dans la liste pour une gestion unifiée. Chaque fois qu'un utilisateur demande une connexion, le système vérifie s'il existe des connexions pouvant être attribuées dans cette liste. S'il y en a une, attribuez-lui la connexion la plus appropriée (comment trouver la connexion la plus appropriée sera indiquée dans la rubrique clé); sinon, lancez une exception à l'utilisateur, si la connexion dans la liste peut être attribuée par un thread Après une gestion particulière, je présenterai l'implémentation spécifique de ce fil.
4. Configuration et maintenance du
pool de connexions Combien de connexions doivent être placées dans le pool de connexions afin de maximiser les performances du système? Le système peut définir des paramètres tels que le nombre minimum de connexions (minConnection) et le nombre maximum de connexions (maxConnection) pour contrôler les connexions dans le pool de connexions. Par exemple, le nombre minimum de connexions est le nombre de connexions créées par le pool de connexions au démarrage du système. Si vous en créez trop, le système démarrera lentement, mais le système répondra rapidement après la création; si vous en créez trop peu, le système démarrera rapidement, mais la réponse sera lente. De cette façon, vous pouvez définir un nombre minimum de connexions plus petit pendant le développement, et le développement sera plus rapide, et en définir un plus grand lorsque le système est réellement utilisé, car il sera plus rapide pour les clients en visite. Le nombre maximal de connexions correspond au nombre maximal de connexions autorisées dans le pool de connexions. Le paramètre spécifique dépend de la quantité d'accès au système et peut être obtenu via la configuration logicielle requise.
Comment garantir le nombre minimum de connexions dans le pool de connexions? Il existe deux stratégies, dynamique et statique. Dynamique signifie que le pool de connexions est vérifié à chaque fois. Si le nombre de connexions s'avère inférieur au nombre minimum de connexions, un nombre correspondant de nouvelles connexions sera ajouté pour garantir le fonctionnement normal du pool de connexions. Statique est de vérifier quand la connexion inactive n'est pas suffisante.
Le type de pool de connexion à la base de données
Les pools de connexions de première et de deuxième génération: distinguer si un pool de connexions à une base de données appartient au produit de première génération ou au produit de deuxième génération a l'une des caractéristiques les plus importantes est de regarder le modèle de thread adopté dans son architecture et sa conception, car cela affecte directement la concurrence Accès aux performances de connexion à la base de données dans l'environnement.
De manière générale, la conception de l'architecture de synchronisation à un seul thread appartient au pool de connexions de première génération, et l'architecture asynchrone multi-thread de deuxième génération appartient à la deuxième génération. Le plus représentatif est Apache Commons DBCP. Dans la version 1.x, le mode de conception monothread a été poursuivi et le modèle multithread a été adopté dans la version 2.x.
Utiliser le temps de publication de la version pour distinguer deux générations de produits est un bon moyen d'être paresseux. Voici la date de publication de la dernière version de ces pools de connexions de base de données communs:
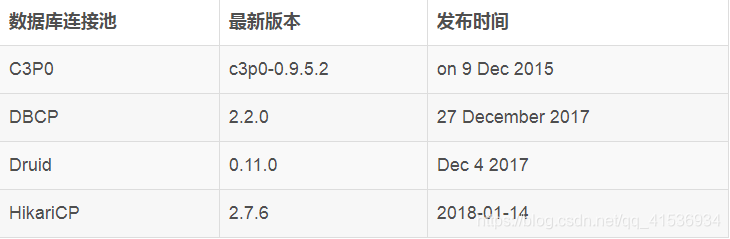
Comme le montre le tableau, C3P0 n'a pas été mis à jour depuis longtemps. La vitesse de mise à jour DBCP est très lente, fondamentalement inactive, tandis que Druid et HikariCP sont en mise à jour active, c'est ce dont nous parlons de la deuxième génération de produits.
Le dépassement du produit de deuxième génération par rapport au produit de première génération est subversif. Sauf pour certaines "raisons historiques", il est difficile de trouver une deuxième raison pour se convaincre de ne pas choisir le produit de deuxième génération, mais tout succès n'est pas accidentel. Le succès du produit de deuxième génération Dans une large mesure, grâce aux bases posées par la génération précédente de produits, reposant sur les épaules de géants, les concepteurs de la nouvelle génération de pools de connexion ont poussé ce produit «outillé» à l'extrême. Parmi eux, les deux produits les plus représentatifs sont: HikariCP et Druid
C3P0 (complètement mort)
C3P0 est le premier pool de connexion de base de données que j'ai utilisé. Pendant longtemps, il a été synonyme de pool de connexion de base de données dans le domaine Java. Hibernate l'a utilisé comme pool de connexion de base de données intégré pendant longtemps. Sa stabilité est reconnue. La fonction C3P0 est simple et facile à utiliser, une bonne stabilité, ce qui est son avantage, mais les défauts de performances la rendent complètement dans le froid. Les performances du C3P0 sont très médiocres, si médiocres qu'il est au fond même par rapport à ses contemporains, sans oublier Druid, HikariCP, etc. Normalement, il est normal d'avoir un problème, et il peut être corrigé, mais le problème le plus fatal de c3p0 est que la conception de l'architecture est trop compliquée, ce qui rend la refactorisation impossible. Avec l'essor de l'Internet domestique, le c3p0, avec ses défauts de performances, s'est complètement retiré de la scène de l'histoire.
DBCP (poisson salé retourné)
DBCP (DataBase Connection Pool) fait partie du sous-projet principal de Commons, le projet Apache de premier niveau (il était le premier à Jakarta Commons), et il a une influence considérable sur l'écosystème Apache. Par exemple, le Tomcat le plus connu est intégré en interne. DBCP, OpenJPA qui implémente la spécification JPA, est également intégré à DBCP par défaut. Cependant, DBCP n'implémente pas indépendamment la fonction de pool de connexions. Il repose en interne sur un autre pool de sous-projets dans Commons. Le "pool" principal du pool de connexions est fourni par le composant Pool. Par conséquent, les performances de DBCP sont en fait celles de Pool. Performances, la relation de dépendance entre DBCP et Pool est la suivante: On
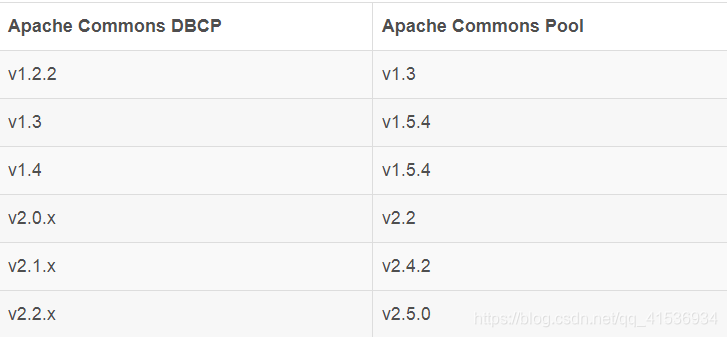
peut voir que, comme les fonctions de base dépendent de Pool, DBCP lui-même ne peut être mis à jour que dans une petite version, et le changement de la vraie grande version dépend entièrement du pool. Pendant longtemps, le pool est resté à la version 1.x, ce qui a directement conduit à l'absence de mise à jour de DBCP. De nombreuses applications qui s'appuient sur DBCP n'ont pas d'autre choix que de les remplacer après avoir rencontré des goulots d'étranglement de performance.Le fidèle partisan de DBCP Tomcat est dans sa version tomcat 7.0, et a repensé et développé un ensemble de pools de connexions (Tomcat JDBC). Bassin). Heureusement, les choses ont finalement marqué un tournant en 2013. La version Commons-Pool 2.0 est sortie en septembre 2013. En février 2014, DBCP a finalement inauguré sa propre version 2.0, un "pool" nouvellement conçu basé sur le nouveau modèle de threading. Laissez DBCP rajeunir. Bien qu'il y ait encore un certain écart par rapport à la nouvelle génération de pools de connexions, l'écart n'est pas grand. La version DBCP 2.x a régulièrement atteint le même niveau d'indicateurs de performance que la nouvelle génération de produits (voir la figure ci-dessous).
DBCP s'est finalement retourné avec Salted Pool et s'est battu pour un beau redressement, mais la longue attente a complètement épuisé la patience des utilisateurs. Par rapport à la nouvelle génération de projets de produits, DBCP n'a aucun avantage. Il suffit de demander, qui aurait le choix Sous le principe de choisir celui qui n'est pas bon? Peut-être que la seule raison de choisir DBCP2 maintenant est les sentiments.
HikariCP (performance invincible)
HikariCP est connu sous le nom de "Performance Killer" (c'est plus rapide). Comment fonctionne-t-il? Examinons d'abord les données fournies par le site officiel:
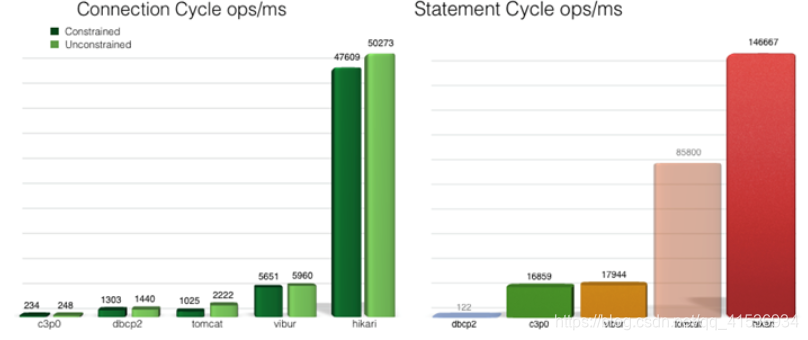
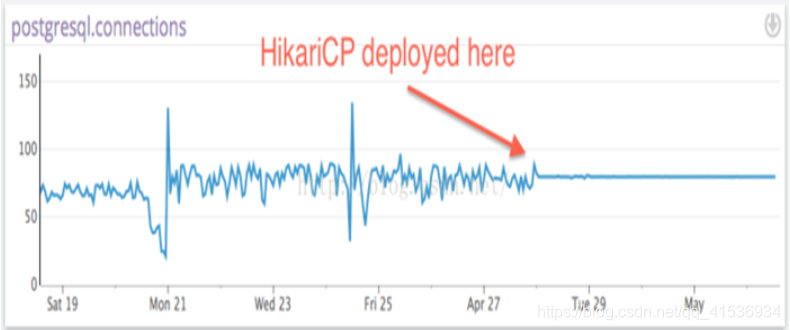
non seulement les performances sont fortes, mais la stabilité n'est pas mauvaise, comme le montre la figure suivante:
Comment obtient-il une performance aussi forte Qu'en est-il de? Les instructions données sur le site officiel sont les suivantes:
Bytecode simplifié: optimisez le code jusqu'à ce que le bytecode compilé soit le moins
élevé , afin que le cache du processeur puisse charger plus de code de programme; proxy et intercepteur optimisés: réduisez le code, par exemple, le proxy Statement de HikariCP ne contient que 100 lignes de code;
personnalisé Type de tableau (FastStatementList) au lieu de ArrayList: éviter la vérification de plage à chaque appel de get (), éviter l'analyse du début à la fin lors de l'appel à remove ();
type de collection personnalisé (ConcurrentBag): améliorer l'efficacité de la lecture et de l'écriture simultanées;
autres Optimisation des défauts, comme l'étude des appels de méthode qui prennent plus d'une tranche de temps CPU (mais n'a pas dit comment l'optimiser).
On peut voir qu'à partir des optimisations ci-dessus et des informations qui peuvent être trouvées maintenant, les avantages de performance de HakariCP devraient être convenus, couplés à son propre corps compact, à l'ère actuelle du cloud, des microservices «En arrière-plan, HakariCP sera sûrement favorisé par plus de gens.
Druide (fonction complète)
Ces dernières années, Ali a souvent agi sur des projets open source. Outre des projets tels que fastJson et dubbo, il existe également des logiciels à grande échelle comme AliSQL. Aujourd'hui, Druid est l'un des nombreux projets open source remarquables d'Ali. En plus de fournir d'excellentes fonctions de pool de connexion, il intègre également la surveillance SQL, l'interception de liste noire et d'autres fonctions. Selon ses propres termes, Druid est «né pour la surveillance». Grâce à l'attrait de la plate-forme d'Ali, le produit a gagné un grand nombre de fans d'utilisateurs une fois qu'il a été publié. À en juger par les commentaires des utilisateurs, Druid n'a pas déçu les utilisateurs.
Par rapport aux autres produits, un autre gros avantage de Druid est que la documentation chinoise est plus complète (est-ce un projet chinois après tout?). Sur la page wiki de github, les problèmes qui peuvent être rencontrés dans l'utilisation quotidienne sont répertoriés. Pour un nouvel utilisateur En parlant, le contenu fourni ci-dessus suffit à le guider pour terminer la configuration et l'utilisation du produit.
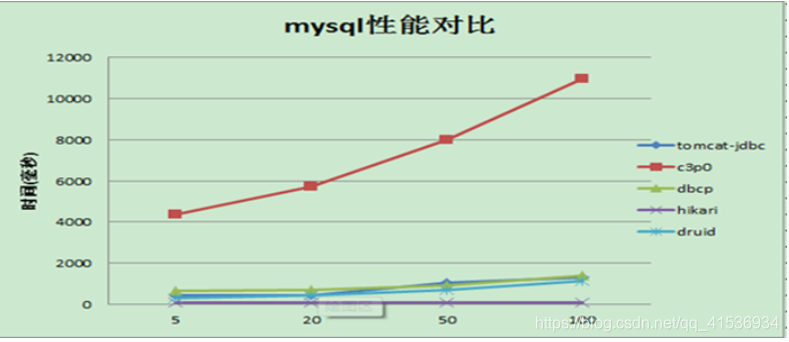
La figure suivante montre les données de test de performances fournies par Druid lui-même:
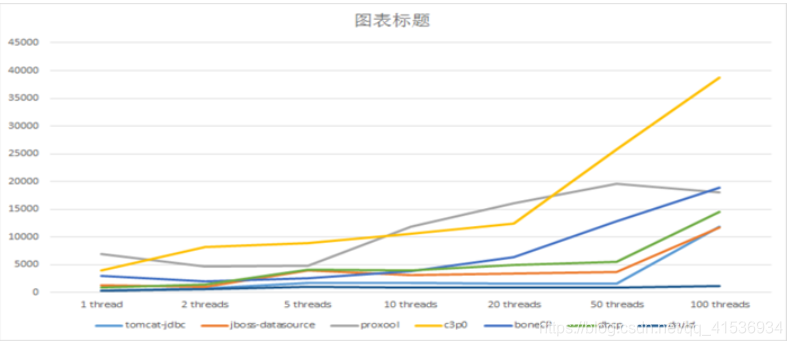
Dans le développement de projets, je préfère toujours utiliser Durid. Ce n'est pas seulement un pool de connexion à une base de données, il contient également un ProxyDriver, une série de bibliothèques de composants JDBC intégrées et un analyseur SQL. .
Avantages de Druid par rapport aux autres pools de connexion à la base de données Avec de
puissantes fonctionnalités de surveillance, grâce aux fonctions de surveillance fournies par Druid, vous pouvez clairement connaître les conditions de travail du pool de connexion et SQL.
a. Surveiller le temps d'exécution de SQL, le temps de maintien de ResultSet, les lignes renvoyées, les lignes mises à jour, les heures d'erreur, les informations de pile d'erreurs;
b. La distribution d'intervalle chronophage de l'exécution SQL. Quelle est la distribution d'intervalle chronophage? Par exemple, un certain SQL est exécuté 1000 fois, dont 50 fois dans l'intervalle de 0,1 milliseconde, 800 fois en 10 millisecondes, 100 fois en 100 millisecondes, 30 fois en 100 1000 millisecondes, 15 fois en 1 à 10 secondes et 5 fois en plus de 10 secondes. Grâce à la distribution d'intervalle chronophage, il est possible de connaître très clairement la situation chronophage d'exécution de SQL;
c. Surveiller le nombre de création et de destruction de connexions physiques du pool de connexions, le nombre d'applications et de fermetures de connexions logiques, le nombre d'attentes non vides et le taux de réussite de PSCache.
Facile à développer. Druid fournit une API étendue en mode Filter-Chain. Vous pouvez écrire votre propre filtre pour intercepter n'importe quelle méthode dans JDBC, et vous pouvez y faire n'importe quoi, comme la surveillance des performances, l'audit SQL, le cryptage du nom d'utilisateur et du mot de passe, les journaux, etc.
Druid intègre les excellentes fonctionnalités des pools de connexion aux bases de données open source et commerciales, et l'optimise avec l'expérience d'Alibaba dans les environnements de production à grande échelle et exigeants.
Résumé:
Aujourd'hui, bien que chaque application (nécessitant un SGBDR) soit indissociable du pool de connexions, en utilisation réelle, le pool de connexions peut déjà être "invisible". En d'autres termes, dans des circonstances normales, une fois la configuration initiale du pool de connexions terminée, il n'est pas nécessaire d'apporter des modifications. Que vous choisissiez Druid ou HikariCP, ou même DBCP, ils sont suffisamment stables et efficaces! Nous avons déjà discuté de nombreux problèmes concernant les performances du pool de connexions, mais ces différences de performances sont comparées à d'autres pools de connexions, pour l'ensemble de l'application système, le pool de connexions de deuxième génération connaît la différence dans le processus d'utilisation Il est minime. Il n'y a fondamentalement aucune dégradation des performances du système en raison des accessoires et de l'utilisation du pool de connexions, sauf lorsque la charge de la base de données d'une application à un seul point est suffisamment élevée (pendant les tests de résistance), mais même ainsi, général La méthode d'optimisation consiste à modifier le cluster en un seul point, plutôt que de se bloquer sur un seul point du pool de connexions.