Répertoire d'articles
Préface
Dans l'article précédent, l'auteur a présenté que pour augmenter le débit RPC interne, la communauté Hadoop libère les ressources du gestionnaire côté serveur tôt en ajustant la réponse de réponse retardée, afin d'utiliser autant que possible les capacités de traitement du gestionnaire pour de vraies requêtes RPC. Le mécanisme d'édition de journal asynchrone actuellement utilisé par HDFS utilise cette optimisation et amélioration. L'écriture du journal d'édition asynchrone HDFS mentionnée ici n'est pas ce que tout le monde pense simplement que le NameNode écrit complètement le journal d'édition de manière asynchrone sur son service JournalNode, puis renvoie directement le résultat au client. Ensuite, lorsque le journal d'édition n'a pas pu être écrit de manière asynchrone, comment le client peut-il savoir ce qui s'est passé plus tard? Il ne peut accepter que les résultats "attendus" reçus précédemment pour les opérations suivantes. Nous disons donc que le retour différé peut jouer un rôle puissant dans cette scène. L'auteur de cet article expliquera en détail comment ce mécanisme de retour différé fonctionne dans le journal d'édition asynchrone de HDFS.
Traitement normal des requêtes RPC du HDFS existant
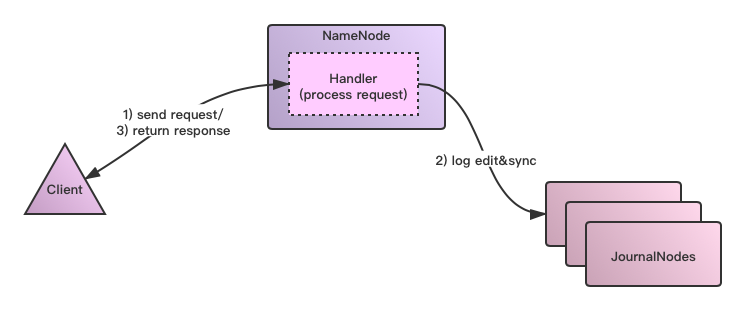
Avant de décrire le mécanisme d'édition asynchrone HDFS, examinons le processus de traitement normal des requêtes HDFS RPC:
- 1) Le client lance l'opération de demande.
- 2) Le NameNode reçoit la demande, puis exécute le traitement de la méthode de demande d'appel RPC correspondante, et si l'opération est traitée avec succès, il doit écrire les informations d'édition du journal de l'opération correspondante.
- 3) L'exécution de la requête NameNode se termine. À la fin de la méthode, l'opération logSync est exécutée et le journal d'édition correspondant à cette opération est écrit dans le JournalNode. À ce stade, une opération d'appel RPC complète se termine.
- 4) Le NameNode renvoie le résultat au client.
Le processus de diagramme simple est le suivant:
Voici un exemple de méthode de traitement de demande d'appel RPC dans NameNode:
boolean setReplication(final String src, final short replication)
throws IOException {
final String operationName = "setReplication";
boolean success = false;
checkOperation(OperationCategory.WRITE);
final FSPermissionChecker pc = getPermissionChecker();
FSPermissionChecker.setOperationType(operationName);
try {
writeLock();
// 1)执行设置副本具体操作
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot set replication for " + src);
success = FSDirAttrOp.setReplication(dir, pc, blockManager, src,
replication);
} finally {
writeUnlock(operationName, getLockReportInfoSupplier(src));
}
} catch (AccessControlException e) {
logAuditEvent(false, operationName, src);
throw e;
}
if (success) {
// 3)如果执行成功,执行logSync操作,写出editlog到JN中
getEditLog().logSync();
logAuditEvent(true, operationName, src);
}
return success;
}
La méthode interne setReplication ci-dessus:
static boolean setReplication(
FSDirectory fsd, FSPermissionChecker pc, BlockManager bm, String src,
final short replication) throws IOException {
bm.verifyReplication(src, replication, null);
final boolean isFile;
fsd.writeLock();
try {
final INodesInPath iip = fsd.resolvePath(pc, src, DirOp.WRITE);
if (fsd.isPermissionEnabled()) {
fsd.checkPathAccess(pc, iip, FsAction.WRITE);
}
final BlockInfo[] blocks = unprotectedSetReplication(fsd, iip,
replication);
isFile = blocks != null;
if (isFile) {
// 2)执行到此处,setReplication操作成功,写出setReplication对应的editlog信息
fsd.getEditLog().logSetReplication(iip.getPath(), replication);
}
} finally {
fsd.writeUnlock();
}
return isFile;
}
Mécanisme d'édition de journal asynchrone basé sur le retour retardé d'appel RPC
Après avoir compris l'appel RPC pour écrire le journal d'édition de manière synchrone, voyons comment le journal d'édition asynchrone est effectué.
Tout d'abord, le journal d'édition asynchrone doit garantir une grande prémisse de principe
Le résultat du traitement de la demande reçu par le Client doit être fiable.
Le vrai problème à résoudre ici est que nous ne voulons pas seulement que le journal d'édition soit écrit de manière asynchrone, d'autre part, le résultat du retour du thread appelant du client doit dépendre de l'achèvement de l'écriture du journal d'édition. Ce dernier dépend en fait du résultat de l'exécution précédente. L'écriture asynchrone de notre editlog n'est donc pas asynchrone au sens plein.
L'amélioration principale du journal d'édition asynchrone est qu'il supprime les opérations plus lourdes qui sont écrites de manière synchrone par le journal d'édition telles que logSync de la méthode de traitement des appels RPC, et un autre thread est utilisé pour écrire le journal d'édition. Au lieu de cela, logSync effectue une simple opération de file d'attente d'entrée de journal d'édition. Dans ce cas, le gestionnaire sur le serveur NameNode peut immédiatement prendre le relais pour gérer d'autres demandes. Après avoir attendu que le journal d'édition de consommation soit réellement écrit, le thread qui synchronise le journal d'édition déclenche l'opération de renvoi de la réponse du client. À ce stade, le client reçoit le résultat du traitement de la demande. Dans ce processus, nous nous assurons toujours qu'une si grande prémisse sera retournée tant que le journal d'édition est écrit avec succès.
En termes simples, pour le côté serveur, son écriture du journal d'édition est exécutée de manière asynchrone, mais pour le côté client, ses résultats doivent encore attendre la fin du journal d'édition.
Un schéma simple de ce processus est le suivant: La
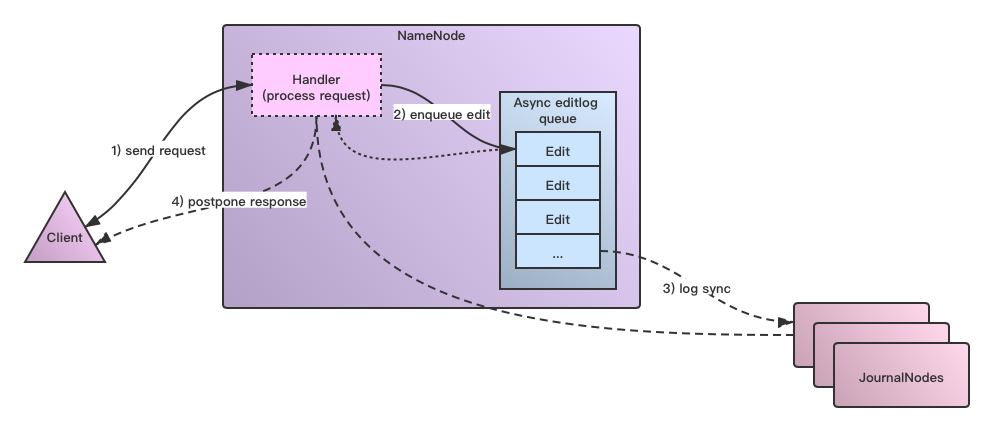
figure ci-dessus montre 2 lignes en pointillés, la première petite ligne en pointillés fait référence au thread du gestionnaire après l'exécution de la méthode logSync et le journal d'édition à écrire est ajouté à la file d'attente d'édition du journal en attente, et le gestionnaire est traité La demande est terminée, puis il peut continuer à traiter d'autres demandes. La grande ligne en pointillé dans le deuxième paragraphe signifie que le retour de la réponse est déclenché après que le thread d'écriture editlog a effectivement exécuté logSync.
Par conséquent, nous pouvons voir d'ici que la stratégie de retour différé de RPC Call fonctionne principalement comme suit:
- Divisez les opérations potentiellement fixes et éventuellement plus lourdes de l'opération d'appel RPC d'origine vers un autre thread pour traitement, afin de garantir que le thread Handler puisse exécuter rapidement la méthode d'opération principale, augmentant ainsi le débit des requêtes du serveur.
- Pour que les threads asynchrones exécutent les opérations précédemment fractionnées, le client attend la fin de l'exécution de l'opération demandée en retardant le résultat du retour pour garantir l'exactitude du traitement des données.
Concernant le changement de retour retardé, les étudiants intéressés se réfèrent à la communauté JIRA: HADOOP-10300: Envoi différé autorisé des réponses aux appels . Bien sûr, le journal d'édition asynchrone décrit dans cet article n'est qu'un cas d'utilisation du mécanisme de réponse différée, et nous pouvons également avoir d'autres scénarios applicables similaires.
Liens connexes
[1] .https: //issues.apache.org/jira/browse/HADOOP-10300
[2] .https: //blog.csdn.net/Androidlushangderen/article/details/106316751