Flink propose deux formes: la forme de table et DataStream. Vous pouvez choisir la manière d'implémenter en fonction de la situation réelle. Cependant, il peut être nécessaire de convertir les deux formulaires dans le processus de développement réel. Voici la méthode de fonctionnement
Les tables peuvent être converties en DataStream ou DataSet, de sorte que le traitement de flux personnalisé ou le programme par lots puisse continuer à s'exécuter sur les résultats de l'API Table ou de la requête SQL.
Lorsque la table est convertie en DataStream ou DataSet, vous devez spécifier le type de données généré, c'est-à-dire pour La
table des types de données convertie en chaque ligne de la table est le résultat de la requête en continu. La
conversion est mise à jour de manière dynamique. Il existe deux modes de conversion: le mode Ajouter (Appende) et le mode Retirer (Retract)
Afficher le plan d'exécution
Table API fournit un mécanisme pour expliquer la logique de la table de calcul et optimiser le plan de requête
Affichez le plan d'exécution, vous pouvez utiliser la méthode TableEnvironment.explain (table) ou la méthode TableEnvironment.explain () pour terminer, renvoyer une chaîne, décrivant trois plans
Plan de requête logique optimisé Plan de requête logique
optimisé Plan d'
exécution réel
explication val: String = tableEnv.explain (resultTable)
println (explication)
La différence entre le traitement de flux et l'algèbre relationnelle
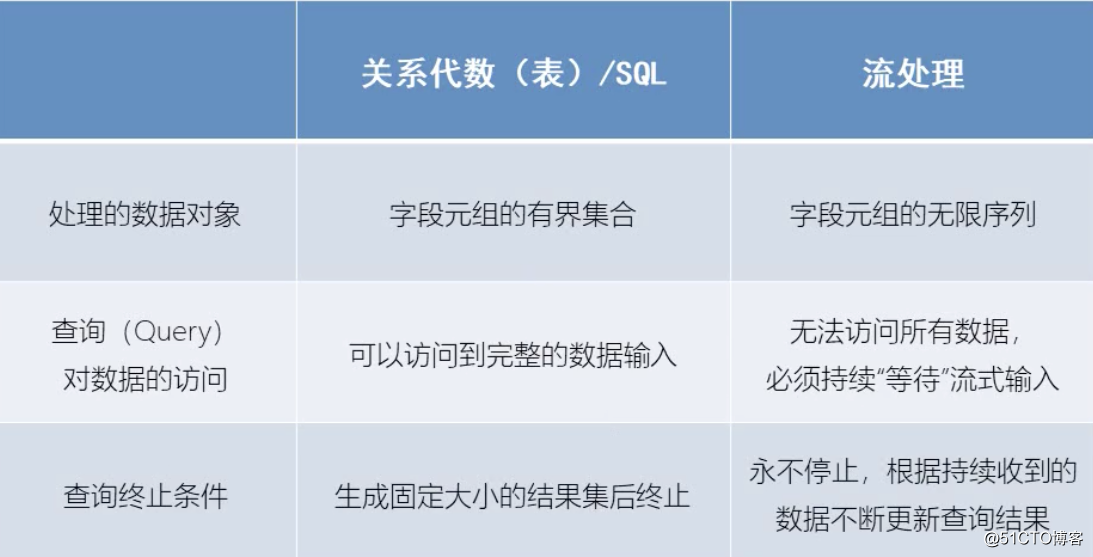
Les tables dynamiques (Dynamic Tables)
sont le concept de base de l'API Flink's Table et de la prise en charge de SQL pour la
diffusion de données.
La
table dynamique de requête continue (requête continue) peut être interrogée comme une table de lot statique, l'interrogation d'une table dynamique produira une requête continue (requête continue)
la requête continue ne se terminera jamais et générera une autre
requête de table dynamique continuera à la mettre à jour Tableau de résultats dynamique pour refléter les changements sur sa table d'entrée dynamique
Table dynamique et processus de conversion de requête continue
1) Le premier flux d'entrée sera converti en table dynamique, cette table dynamique ne sera ajoutée qu'en
continu 2) La requête continue est calculée sur la table dynamique, une nouvelle table dynamique est générée
et un état est ajouté au résultat de la requête précédente, de sorte qu'il n'est pas nécessaire de tout recommencer Lancer la requête, améliorer l'efficacité
3) La nouvelle table dynamique générée est convertie en flux puis sortie
Convertir le flux en table dynamique
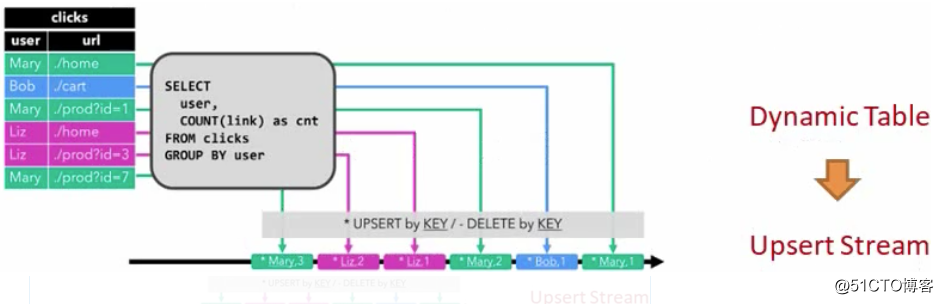
Pour traiter un flux avec une requête relationnelle, il doit d'abord être converti en table.
Conceptuellement, chaque enregistrement de données du flux est interprété comme une opération d'insertion et de modification sur la table de résultats
La première étape consiste à lire le journal d'accès et à l'insérer à chaque fois qu'une donnée arrive
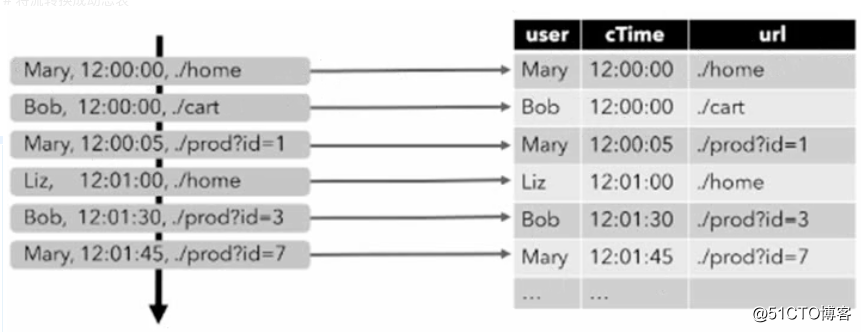
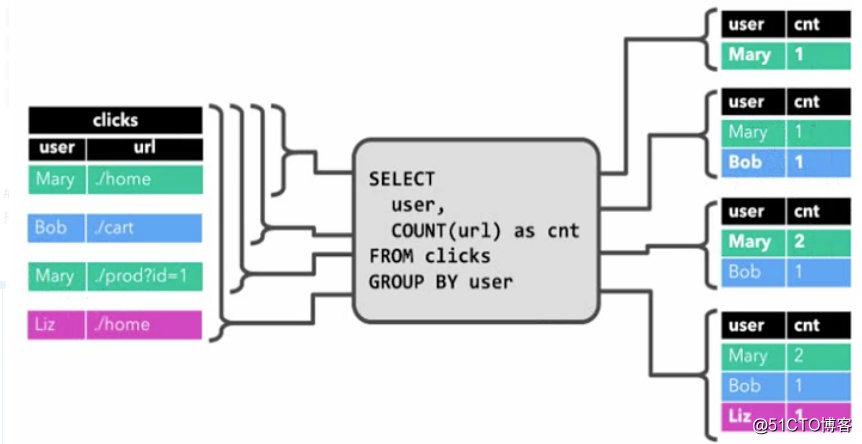
Continuez à interroger les châtaignes et comptez le nombre de clics de chaque utilisateur
La requête continue effectuera un traitement de calcul sur la table dynamique et générera une nouvelle table dynamique en conséquence
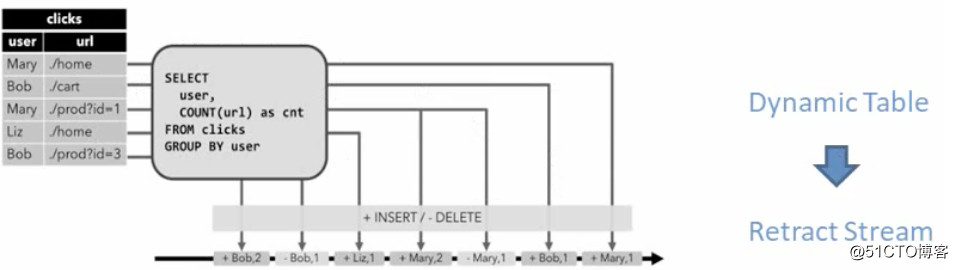
La dernière étape consiste à convertir la table dynamique en DataStream
À l'instar des tables de base de données normales, les tables dynamiques peuvent être modifiées par insertion, mise à jour et suppression.
Ces modifications doivent être apportées lorsque la table dynamique est convertie en flux ou écrite sur un système externe. Code
1, ajouter uniquement
- Une table dynamique qui est modifiée uniquement par des modifications d'insertion peut être directement convertie pour ajouter uniquement le flux
2, retirer le flux (Retract) - Le flux de retrait est un flux qui contient deux types de messages: ajouter (ajouter) un message et retirer (retirer) le message
3, mettre à jour le flux d'insertion (Upsert) - Le flux Upsert contient également deux types de messages: les messages Upsert et les messages supprimés (Supprimer).
Convertir une table dynamique en DataStream
Opération de retrait, chaque nouvelle opération est insertion + opération, et celle de retrait est opération de suppression.
Lorsque Mary vient pour la première fois, il y aura une insertion. Lorsque Mary vient pour la deuxième fois, cela déclenchera deux opérations, insérer et supprimer , Ajouter un mary2, supprimer mary1
Attributs de
temps Pour les opérations basées sur le temps (telles que l'API de table et les opérations de fenêtre dans SQL), vous devez définir la sémantique de temps et les informations de source de données d'événement pertinentes. La
table peut fournir un champ de temps logique pour le traitement des programmes dans la table. Dans, l'indication de l'heure et l'accès à l'
attribut d' horodatage correspondant peuvent faire partie de chaque schéma. Une fois l'attribut time défini, il peut être référencé en tant que champ et l'attribut time peut être utilisé dans des opérations basées sur le temps.
Le comportement est similaire à un horodatage normal, il est accessible et calculé.
Définir le temps de traitement (temps de traitement)
Avec la sémantique du temps de traitement, le programme de traitement de table est autorisé à générer des résultats basés sur l'heure locale de la machine. C'est le concept de temps le plus simple, pas besoin d'extraire l'horodatage ni de générer un filigrane
Plusieurs méthodes de définition:
1. Spécifiez lors de la conversion de DataStream en une table (la plus simple)
Lors de la définition du schéma, vous pouvez utiliser .proctime pour spécifier le nom du champ afin de définir le champ de temps de traitement.
Cet attribut proctime ne peut étendre le schéma physique qu'en ajoutant des champs logiques. Il ne peut donc être défini qu'à la fin de la définition du schéma
val sensorTables = tableEnv.fromDataStream(dataStream, 'id,'temperature,'timestamp, 'pt.proctime)Augmenter pom.xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.10.1</version>
</dependency>
châtaigne:
package com.mafei.apitest.tabletest
import com.mafei.sinktest.SensorReadingTest5
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api._
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
object TimeAndWindowTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置1个并发
//设置处理时间为流处理的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
val inputStream = env.readTextFile("/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt")
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
})
//设置环境信息(可以不用)
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner() // Flink 10的时候默认是用的useOldPlanner 11就改为了BlinkPlanner
.inStreamingMode()
.build()
// 设置flink table运行环境
val tableEnv = StreamTableEnvironment.create(env, settings)
//流转换成表
val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp,'temperature,'pt.proctime)
sensorTables.printSchema()
sensorTables.toAppendStream[Row].print()
env.execute()
}
}
Structure du code et effet de l'opération: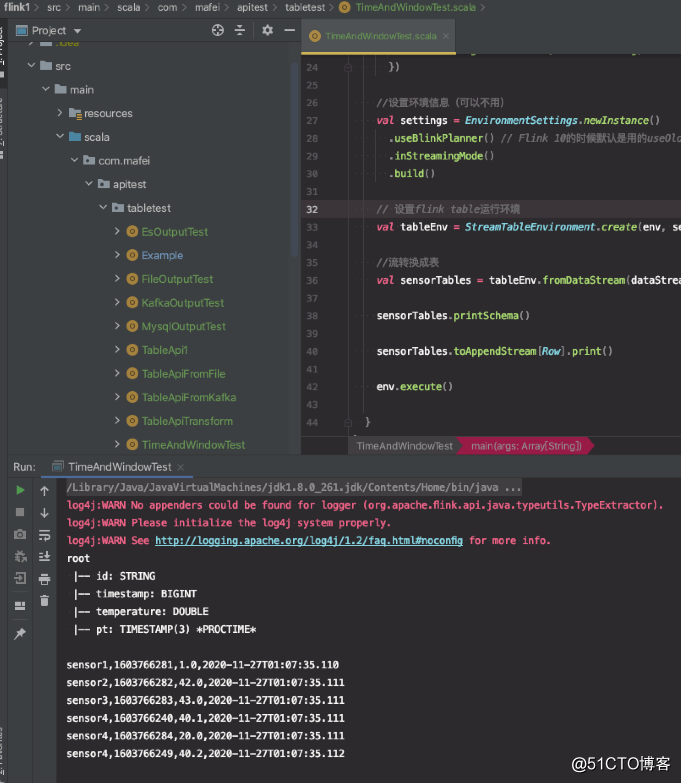
La seconde consiste à définir le temps de traitement (temps de traitement)
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("tem", DataTypes.DOUBLE())
.field("pt", DataTypes.TIMESTAMP(3))
.proctime() //需要注意,只有输出的sink目标里面实现了DefineRowTimeAttributes才能用,否则会报错,文件中不能,但kafka中是可以用的
).createTemporaryTable("inputTable")
La troisième consiste à définir une autre implémentation du temps de traitement, qui doit utiliser le moteur de clignotement
val sinkDDlL: String =
"""
|create table dataTable(
| id varchar(20) not null
| ts bigint,
| temperature double,
| pt AS PROCTIME()
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = '/sensor.txt',
| 'format.type' = 'csv'
|)
|""".stripMargin
tableEnv.sqlUpdate(sinkDDlL)
Définir l'heure de l'événement (heure de l'événement)
Ce n'est pas que flink prend le temps de traitement localement, mais prend le temps dans l'
événement de traiter la sémantique de l'heure de l' événement, permettant au gestionnaire de table de générer des résultats en fonction du temps contenu dans chaque enregistrement. De cette manière, même dans le cas d'événements hors séquence ou d'événements retardés, des résultats corrects peuvent être obtenus.
Pour gérer les événements dans le désordre et faire la distinction entre les événements ponctuels et tardifs dans le flux, Flink doit extraire l'horodatage des données d'événement et l'utiliser pour avancer la progression de l'
heure de l' événement. Il existe 3 façons de définir l'heure de l'événement. La
première consiste à convertir DataStream en table. Lorsque vous spécifiez que
le DataStream est converti en table, utilisez rowtime pour définir l'attribut de l'heure de l'événement
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReadingTest5](Time.seconds(1000L)) {
override def extractTimestamp(t: SensorReadingTest5): Long =t.timestamp * 1000L
}) //指定watermark
//流转换成表,指定处理时间-上面的实现方式
// val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp,'temperature,'pt.proctime)
//将DataStream转换为Table,并指定事件时间字段
val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp.proctime,'temperature)
//将DataStream转换为Table,并指定事件时间字段-直接追加字段
val sensorTables = tableEnv.fromDataStream(dataStream,"id","temperature","timestamp","rt".rowtime)
Le second est spécifié lors de la définition du schéma de table
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("tem", DataTypes.DOUBLE())
.rowtime(
new Rowtime()
.timestampsFromField("timestamp") //从数据字段中提取时间戳
.watermarksPeriodicBounded(2000) //watermark延迟2秒
)
).createTemporaryTable("inputTable")
Défini dans le DDL qui a créé la table
//在创建表的DDL中定义
val sinkDDlL: String =
"""
|create table dataTable(
| id varchar(20) not null
| ts bigint,
| temperature double,
| rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts)),
| watermark for rt as rt - interval '1' second //基于ts减去1秒生成watermark,也就是watermark的窗口时1秒
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = '/sensor.txt',
| 'format.type' = 'csv'
|)
|""".stripMargin
tableEnv.sqlUpdate(sinkDDlL)
Fenêtre Flink
La sémantique temporelle doit coopérer avec les opérations de fenêtre pour jouer un rôle réel.
Dans Table ApI et SQL, il existe deux principaux types de fenêtres
Fenêtres de groupe
Définissez d'abord à quoi ressemble le chef de groupe, effectuez groupby en fonction de la touche et exécutez la fonction d'agrégation à la dernière étape
En fonction du temps ou de l'intervalle de comptage de lignes, les lignes sont agrégées dans un groupe limité (Groupe), et une fonction d'agrégation est effectuée sur les données de chaque groupe
Le groupe Windows est défini à l'aide de la clause window (w: GroupWindow) et un alias doit être spécifié par la clause as.
Pour regrouper la table en fonction de la fenêtre, l'alias de la fenêtre doit être dans la clause group by, comme un champ de regroupement normal Reference
val table = input
.window ([w ;: GroupWindow] as'w) // Définir la fenêtre, l'alias est w
.groupBy ('w,' a) // Regrouper par champ a et fenêtre w.
Select ('a, 'b.sum) // opération d'agrégation
L'API Table fournit un ensemble de classes de fenêtre prédéfinies avec une sémantique spécifique, ces classes seront converties en l'opération de fenêtre DataStream ou DataSet sous-jacente
Fenêtres tumultueuses
La fenêtre déroulante doit être définie avec la classe Tumble
// Tumbling Event-time window
.window (Tumble over 10 minutes on'rowtime as'w)
// Définit la fenêtre
déroulante du temps de traitement (Fenêtre de temps de traitement de Tumbling) .window (Tumble over 10.minutes on'proctime as'w)
// Fenêtre de comptage de lignes qui définit la quantité de
data.window (Tumble over 10.rows on'proctime as'w)
Fenêtres coulissantes
Une fenêtre glissante pendant 10 minutes, glissant toutes les 5 minutes
// Fenêtre
glissante de l' heure de l'événement .window (Glissez plus de 10 minutes toutes les 5 minutes sur'rowtime as'w)
// Fenêtre de temps de traitement glissante
.window (Glissez plus de 10 minutes toutes les 5 minutes sur 'proctime as' w)
// Fenêtre de comptage de lignes coulissante
.window (Glisser plus de 10 minutes toutes les 5 lignes sur 'proctime as' w)
Fenêtres de session
La fenêtre de session doit être définie par la classe Session
// Sesion Evnet-time Window
.window (Session withGap 10.minutes on 'rowtime as' w)
// Fenêtre de temps de traitement de session
.window (Session withGap 10.minutes on 'procetime as' w)
Regrouper les fenêtres dans SQL
Group Windows est défini dans la clause Group By de la requête SQL
TUMBLE (time_attr, interval)
définit une fenêtre déroulante , le premier paramètre est le champ time et le second paramètre est la longueur de la fenêtre
Une fenêtre glissante définie par HOP (time_attr, interval, interval) , le premier paramètre est le champ time, le deuxième paramètre est la longueur du pas glissant de la fenêtre et le troisième est la longueur de la fenêtre
SESSION (time_attr, interval)
définit une fenêtre de session, le premier Un paramètre est le champ de temps, le deuxième paramètre est l'intervalle de fenêtre
Sur Windows
Pour chaque ligne d'entrée, calculez l'agrégation des lignes adjacentes