Dans la section précédente, j'ai examiné de plus près le "gestionnaire de contexte" de Python avec vous. Aujourd'hui, c'est toujours un sujet lié au contexte. C'est juste que le contexte ici est un peu différent du contenu de la section précédente. Le gestionnaire de contexte est de gérer le contexte du niveau de bloc de code, et le contexte dont je vais parler aujourd'hui est le contexte dans le projet d'ingénierie.
Peut-être que vous n'êtes toujours pas clair sur le concept de contexte . Voici une brève explication
Le fonctionnement d'un programme ou d'une fonction, dans de nombreux cas, doit s'appuyer sur des variables extérieures au programme pour s'exécuter. Une fois ces variables séparées, le programme ne fonctionnera pas correctement. Ces variables externes, conformément à la pratique conventionnelle, doivent passer ces variables en tant que paramètres de fonction un par un. C'est une approche, et il n'y a aucun problème avec de simples petits programmes. Une fois qu'une telle approche est utilisée dans un projet plus vaste, elle est trop lourde et rigide.
Une meilleure approche consiste à intégrer les valeurs de variables fréquemment utilisées dans le global de ces projets, et la collecte de ces valeurs est le contexte. Tirez-le simplement de ce contexte lorsque cela est nécessaire.
Dans Flask, il existe deux contextes
- contexte d'application
- contexte de la demande
application contextStockera des variables dans une application pouvant être partagée globalement. Et request contextstocke toutes les informations d'une demande initiée de l'extérieur.
Il peut y avoir plusieurs applications dans un projet Flask, mais il y aura plusieurs demandes dans une application. C'est la correspondance entre eux.
Comme mentionné ci-dessus, le contexte peut être atteint 信息共享, mais en même temps, une chose est très importante, c'est 信息隔离. Lorsque plusieurs applications s'exécutent en même temps, il est nécessaire de s'assurer qu'une application ne peut pas accéder et modifier les variables d'une autre application. C'est très important.
Alors exactement comment faire 信息隔离?
Ensuite, nous mentionnerons trois objets très courants dans Flask, vous ne devriez pas vous sentir étranger.
- Local
- LocalProxy
- LocalStack
Ces trois objets sont werkzeugdans l'offre, la définition de l' local.pyintérieur, donc ils ne sont pas uniques à Flask, ce qui signifie que nous pouvons les utiliser directement dans leurs propres projets, plutôt que de nous fier à l'environnement Flask.
1. Local
Tout d'abord Local, rappelez-vous que "cinquième chapitre de threads de la série de programmation simultanée dans le 信息隔离temps précédent , le mentionné threading.local, il est conçu pour stocker le thread variable actuel, l'isolation des threads afin d'atteindre l'objet.
Et le Local in Flask a la même fonction que celui-ci.
Afin de comprendre le rôle de ce Local, le meilleur moyen est de comparer directement deux morceaux de code.
Tout d'abord, sans utiliser Local, nous créons une nouvelle classe avec un attribut de nom, qui est wangbm par défaut, puis nous démarrons un thread. Ce que nous faisons est de changer l'attribut de nom en wuyanzu.
import time
import threading
class People:
name = 'wangbm'
my_obj = People()
def worker():
my_obj.name = 'wuyanzu'
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print(my_obj.name)Le résultat de l'exécution peut être imaginé, c'est wuyanzu. Les modifications apportées par le thread enfant à l'objet peuvent affecter directement le thread principal.
Ensuite, nous utilisons Local pour réaliser
import time
import threading
from werkzeug.local import Local
class People:
name = 'wangbm'
my_obj = Local()
my_obj.name = 'wangbm'
def worker():
my_obj.name = 'wuyanzu'
print('in subprocess, my_obj.name: '+str(my_obj.name))
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print('in mainprocess, my_obj.name: '+str(my_obj.name))Le résultat de l'impression est le suivant, on voit que la modification du sous-thread n'affectera pas le thread principal
in subprocess, my_obj.name: wuyanzu
in mainprocess, my_obj.name: wangbmAlors, comment fait Local? En fait, le principe est très simple: il utilise une structure de données de base: un dictionnaire.
Lorsque le thread modifie les variables de l'objet Local (y compris le nom de la variable k1 et la valeur de la variable v1), il peut être vu à partir du code source qu'il obtient d'abord l'id du thread actuel comme __storage__clé (ce stockage est un dictionnaire imbriqué), et la valeur, Est un dictionnaire,{k1: v1}
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}Les exemples sont les suivants
# 0 和 1 是线程 id
self.__storage__['0'][k1] = v1
self.__storage__['1'][k2] = v2En raison de l'utilisation de l'ID de thread comme couche d'encapsulation, une isolation de thread peut être réalisée.
Si vous souhaitez utiliser un graphique pour représenter, le premier objet Local est une boîte vide

Lorsque différents threads écrivent des données, l'objet Local alloue une micro-boîte pour chaque thread.
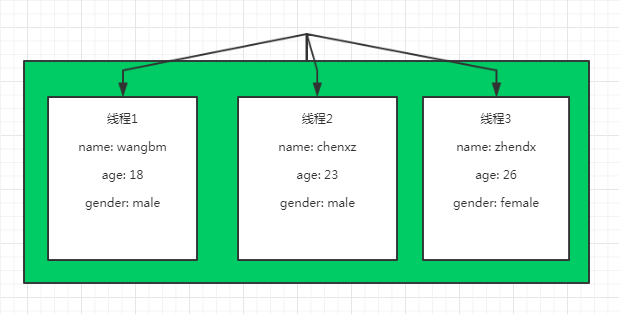
local qui doivent être localmanagergérés, après la demande, appelle la localmanager.cleanup()fonction, en fait, appelle local.__release_local__pour le nettoyage des données. Comment faire, regardez le code suivant.
from werkzeug.local import Local, LocalManager
local = Local()
local_manager = LocalManager([local])
def application(environ, start_response):
local.request = request = Request(environ)
...
# make_middleware会确保当request结束时,所有存储于local中的对象的reference被清除
application = local_manager.make_middleware(application)Ce qui suit est le Localcode, il y a un besoin peut être vu ici directement.
class Local(object):
__slots__ = ('__storage__', '__ident_func__')
def __init__(self):
object.__setattr__(self, '__storage__', {})
object.__setattr__(self, '__ident_func__', get_ident)
def __iter__(self):
return iter(self.__storage__.items())
def __call__(self, proxy):
"""Create a proxy for a name."""
return LocalProxy(self, proxy)
def __release_local__(self):
self.__storage__.pop(self.__ident_func__(), None)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
def __delattr__(self, name):
try:
del self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)2. LocalStack
Grâce à l'introduction de Local, nous pouvons savoir que Local encapsule en fait un dictionnaire pour réaliser l'isolation des threads.
Et la prochaine chose que je vais présenter LocalStackest la même idée, qui LocalStackest encapsulée Local, donc elle a à la fois les caractéristiques d'isolation des threads locaux et les caractéristiques de la structure de la pile. Vous pouvez accéder aux objets via pop, push et top.
Utilisez également une image pour représenter
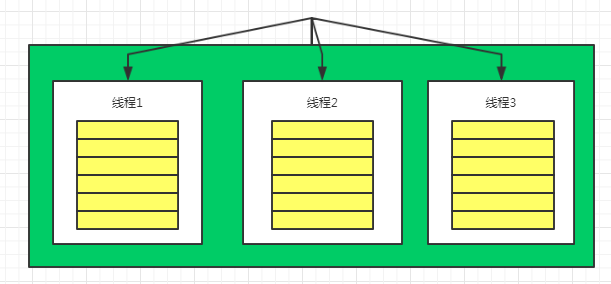
La caractéristique de la structure de la pile n'est rien de plus que le dernier entré, premier sorti. Sans oublier ici, l'accent est mis ici sur la manière de refléter les caractéristiques de l'isolation des threads, ou d'utiliser l'exemple ci-dessus avec une légère modification.
import time
import threading
from werkzeug.local import LocalStack
my_stack = LocalStack()
my_stack.push('wangbm')
def worker():
print('in subthread, my_stack.top is : '+str(my_stack.top) + ' before push')
my_stack.push('wuyanzu')
print('in subthread, my_stack.top is : ' + str(my_stack.top) + ' after push')
new_task = threading.Thread(target=worker)
new_task.start()
# 休眠1s,保证子线程先执行
time.sleep(1)
print('in main thread, my_stack.top is : '+str(my_stack.top))Les résultats de sortie sont les suivants: On peut voir que my_stack dans le sous-thread et my_stack dans le thread principal ne peuvent pas être partagés, et l'isolement est effectivement réalisé.
in subthread, my_stack.top is : None before push
in subthread, my_stack.top is : wuyanzu after push
in main thread, my_stack.top is : wangbmDans Flask, il existe deux contextes principaux, AppContextet RequestContext.
Lorsqu'une requête est initiée, le Flask va d'abord ouvrir un thread, puis la requête contient les informations de contexte RequestContextdans l'un des LocalStackobjets ( _request_ctx_stack), et avant de pousser, il va en fait détecter qu'un autre LocalStackobjet ( _app_ctx_stack) est vide (mais généralement _app_ctx_stackNe sera pas vide), s'il est vide, transmettez d'abord les informations de contexte de l'application _app_ctx_stack, puis transmettez les informations de contexte de la demande _request_ctx_stack.
Il y a trois objets couramment utilisés dans flask
- current_app
- demande
- session
Ces trois objets pointent toujours vers LocalStackl'application, la requête ou la session correspondante dans le contexte en haut de la pile. Le code source correspondant est le suivant:
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, 'request'))
session = LocalProxy(partial(_lookup_req_object, 'session'))3. LocalProxy
Grâce au code ci-dessus, vous pouvez constater que lorsque nous accédons aux éléments de LocalStack, nous passons tous par LocalProxyY a-t-il?
C'est très étrange, pourquoi ne pas visiter Localet LocalStackfaire?
Cela devrait être un point difficile, laissez-moi vous donner un exemple, peut-être comprendrez-vous.
Le premier est le cas de ne pas utiliser LocalProxy
# use Local object directly
from werkzeug.local import LocalStack
user_stack = LocalStack()
user_stack.push({'name': 'Bob'})
user_stack.push({'name': 'John'})
def get_user():
# do something to get User object and return it
return user_stack.pop()
# 直接调用函数获取user对象
user = get_user()
print user['name']
print user['name']Le résultat de sortie est
John
JohnAprès avoir utilisé LocalProxy
# use LocalProxy
from werkzeug.local import LocalStack, LocalProxy
user_stack = LocalStack()
user_stack.push({'name': 'Bob'})
user_stack.push({'name': 'John'})
def get_user():
# do something to get User object and return it
return user_stack.pop()
# 通过LocalProxy使用user对象
user = LocalProxy(get_user)
print user['name']
print user['name']Résultat de sortie
John
BobComment, voyez la différence, utiliser directement l'objet LocalStack, une fois l'utilisateur assigné, il ne peut plus être mis à jour dynamiquement, en utilisant Proxy, chaque fois que l'opérateur est appelé (ici []操作符utilisé pour obtenir l'attribut), l'utilisateur sera réacquis, réalisant ainsi dynamique Mettez à jour l'effet de l'utilisateur .
À chaque user['name']fois, la LocalProxyclasse déclenchera l' __getitem__appel de la classe _get_current_object. Et chacun _get_current_objectsera retourné get_user()(la fonction correspondante est dans le flacon _lookup_req_object) les résultats d'exécution, c'est-à-direuser_stack.pop()
def __init__(self, local, name=None):
# 【重要】将local对象(也就是一个get_user函数对象)赋值给self.__local
object.__setattr__(self, '_LocalProxy__local', local)
object.__setattr__(self, '__name__', name)
if callable(local) and not hasattr(local, '__release_local__'):
# "local" is a callable that is not an instance of Local or
# LocalManager: mark it as a wrapped function.
object.__setattr__(self, '__wrapped__', local)
def _get_current_object(self):
"""Return the current object. This is useful if you want the real
object behind the proxy at a time for performance reasons or because
you want to pass the object into a different context.
"""
if not hasattr(self.__local, '__release_local__'):
# 【重要】执行传递进行的 get_user 对象。
return self.__local()
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError('no object bound to %s' % self.__name__)De cette manière, chaque opération sur l'élément supérieur de l'empilement est effectuée face au dernier élément.
4. Erreurs classiques
Une erreur souvent rencontrée dans Flask est:
Travailler en dehors du contexte d'application.
Cette erreur est difficile à comprendre si vous ne comprenez pas le mécanisme de contexte de flask. Sur la base des connaissances ci-dessus, nous pouvons essayer de comprendre pourquoi cela se produit.
Tout d'abord, simulons l'occurrence de cette erreur. Supposons qu'il existe maintenant un fichier séparé avec le contenu suivant
from flask import current_app
app = Flask(__name__)
app = current_app
print(app.config['DEBUG'])Exécutez-le, il signalera l'erreur suivante.
Traceback (most recent call last):
File "/Users/MING/PycharmProjects/fisher/app/mytest/mytest.py", line 19, in <module>
print(app.config['DEBUG'])
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/werkzeug/local.py", line 306, in _get_current_object
return self.__local()
File "/Users/MING/.virtualenvs/fisher-gSdA58aK/lib/python3.6/site-packages/flask/globals.py", line 51, in _find_app
raise RuntimeError(_app_ctx_err_msg)
RuntimeError: Working outside of application context.Vous devez être surpris. J'ai évidemment également instancié un objet d'application, mais pourquoi aurais-je une erreur en prenant current_app? Et si current_app n'est pas utilisé, aucune erreur ne sera signalée.
Si vous étudiez attentivement le contenu ci-dessus, ce n'est pas difficile à comprendre ici.
D'après des recherches précédentes current_app, il a été constaté que lorsqu'il est utilisé , il prend l' LocalStackélément supérieur de la pile (informations de contexte d'application). En fait, lorsque nous app = Flask(__name__)instancions un objet d'application, ces informations de contexte n'ont pas été écrites pour le moment LocalStack. Naturellement Ce sera une erreur de récupérer l'élément supérieur de la pile.
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.appComme nous l'avons dit plus haut, quand ce contexte sera-t-il mis en place? Une fois qu'une demande est lancée en externe, il vérifie d'abord si les informations de contexte de l'application ont été transférées, et sinon, elles le seront la moitié du temps.
Ce qui précède est la façon dont nous exécutons un seul fichier, et aucune demande n'est réellement générée une demande, naturellement LocalStackil n'y a pas d'informations de contexte dans l'application. Il est normal de signaler des erreurs.
Après avoir connu la source de l'erreur, comment résoudre ce problème?
Dans Flask, qui fournit une méthode, ctx=app.app_context()vous pouvez obtenir un objet de contexte, tant que nous allons cet objet de contexte à pousser manuellement LocalStack, current_appil peut être normal de prendre notre application des objets.
from flask import Flask, current_app
app = Flask(__name__)
ctx = app.app_context()
ctx.push()
app = current_app
print(app.config['DEBUG'])
ctx.pop()Parce que la classe AppContext implémente le protocole de contexte
class AppContext(object):
def __enter__(self):
self.push()
return self
def __exit__(self, exc_type, exc_value, tb):
self.pop(exc_value)
if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)Donc tu peux aussi écrire comme ça
from flask import Flask, current_app
app = Flask(__name__)
with app.app_context():
app = current_app
print(app.config['DEBUG'])Ci-dessus, j'apprends jusqu'en juillet Flask高级编程avec leur propre simple à comprendre, vous voulez comprendre le contexte dans le mécanisme de base de Flask serait utile.