Écrit en face: Les questions d'entretien avancées du back-end Java nécessaires pour les entretiens en 2020. Un guide de révision est résumé sur Github. Le contenu est détaillé, avec des images et des textes. Les amis qui ont besoin d'apprendre peuvent jouer!
Adresse GitHub: https://github.com/abel-max/Java-Study-Note/tree/master
La fonction principale du journal Binlog est la récupération des données et la réplication maître-esclave. Il s'agit d'un fichier journal au format binaire et la transmission réseau ne nécessite pas de conversion de protocole. La haute disponibilité du cluster MySQL, l'équilibrage de charge, la séparation lecture-écriture et d'autres fonctions sont tous basés sur Binlog.
Modèle d'architecture grand public de réplication maître-esclave MySQL
Sur la base de Binlog, nous pouvons répliquer un ou plusieurs serveurs MySQL, en fonction des fonctions que nous voulons implémenter. L'architecture du système grand public utilise les méthodes suivantes:
1. Un maître, un esclave / un maître, plusieurs esclaves
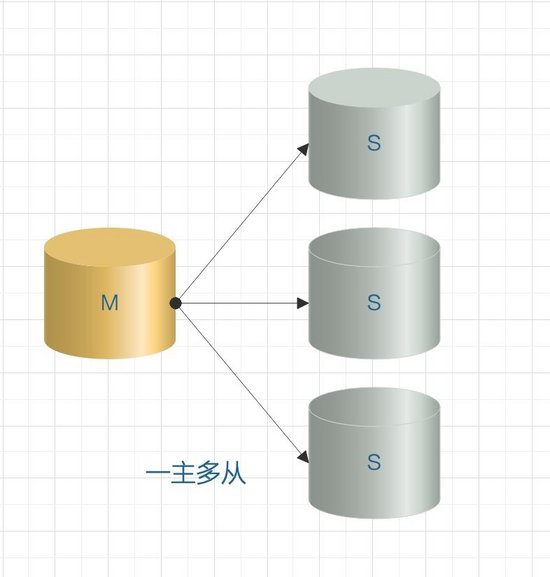
Les architectures maître-esclave les plus courantes sont les architectures maître-esclave les plus courantes.En règle générale, cette architecture peut être utilisée pour obtenir une configuration maître-esclave ou une séparation lecture-écriture.
S'il s'agit d'un mode mono-maître-multi-esclave, lorsque le nombre d'esclaves augmente jusqu'à un certain nombre, la charge de l'esclave sur le maître et la bande passante du réseau deviendront un problème sérieux.
2. Plusieurs maîtres et un esclave

MySQL 5.7 a commencé à prendre en charge un mode multi-maître-un-esclave, en sauvegardant les données de plusieurs bases de données vers une base de données pour le stockage.
3. Réplication à double maître
Théoriquement, c'est le même que le maître-esclave, mais les deux serveurs MySQL agissent comme des esclaves l'un de l'autre, et tout changement de chaque côté copiera les données de l'autre dans sa propre base de données. Le double maître convient aux scénarios d'entreprise où la pression d'écriture est relativement élevée ou lorsque le DBA doit basculer entre le maître et l'esclave pour la maintenance. (Le processus de la connexion d'autorisation mutuelle maître-esclave, la lecture du journal binlog de l'autre partie et la mise à jour vers la base de données locale; tant que les données de l'autre partie changent, vous changerez en conséquence)
4. Réplication en cascade
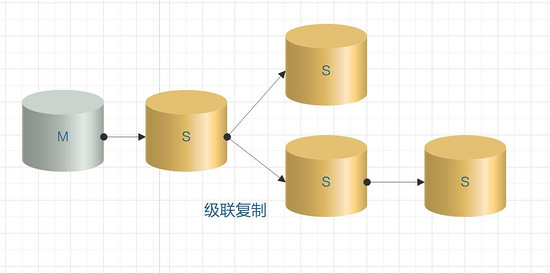
En mode cascade, comme de nombreux nœuds esclaves sont impliqués, s'ils sont tous connectés au maître, la pression sur le serveur maître n'est certainement pas faible. Par conséquent, certains nœuds esclaves sont connectés aux nœuds esclaves du niveau supérieur. Cela soulage la pression sur le serveur principal.
La réplication en cascade résout la pression de la réplication de plusieurs bibliothèques esclaves sur la bibliothèque maître dans le scénario multi-esclave à un maître. L'inconvénient est que le délai de synchronisation des données est relativement important.
Principe de réplication maître-esclave MySQL
La réplication maître-esclave MySQL implique trois threads:
Un thread sur le nœud maître: log dump thread
Deux threads seront générés à partir de la bibliothèque: un thread d'E / S et un thread SQL
Comme indiqué ci-dessous:
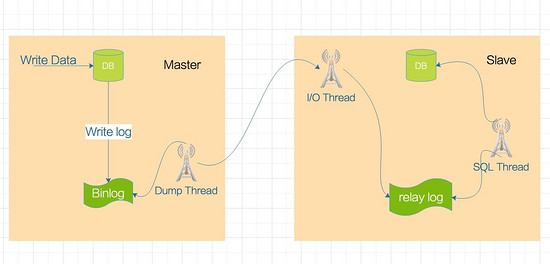
La bibliothèque principale générera un thread de vidage du journal pour transférer les données Binlog vers le thread d'E / S de la bibliothèque esclave.
Le thread d'E / S de la bibliothèque esclave demandera le Binlog de la bibliothèque principale et écrira le Binlog obtenu dans le fichier journal de relais local (journal de relais).
Le thread SQL lira le journal dans le fichier journal de relais et l'analysera en instructions SQL pour l'exécuter une par une.
Thread de vidage du journal du nœud principal
Lorsque le nœud esclave se connecte au nœud maître, le nœud maître créera un thread de vidage du journal pour qu'il envoie et lise le contenu de Binlog. Lors de la lecture de l'opération dans le Binlog, le thread de vidage du journal verrouille le Binlog sur le nœud maître; le verrou sera libéré avant que la lecture ne soit terminée et envoyé au nœud esclave. Le nœud maître créera un thread de vidage du journal pour chacun de ses nœuds esclaves .
Fil d'E / S du nœud esclave
Lorsqu'il est exécuté à partir du nœud start slaveaprès la commande, le nœud crée un thread d'E / S est utilisé pour connecter le nœud maître, la demande Binlog mise à jour du référentiel maître. Une fois que le thread d'E / S reçoit la mise à jour envoyée par le processus de vidage du journal du nœud maître, il l'enregistre dans le journal de relais local (journal de relais).
journal de relais
Voici un nouveau concept de bûche. Lorsque MySQL effectue une réplication maître-maître ou maître-esclave, un journal de relais correspondant sera généré sous le serveur pour être répliqué.
Comment le journal de relais est-il généré?
Le thread d'E / S du serveur esclave lit le journal Binlog du serveur maître, analyse divers événements et les enregistre dans le fichier local du serveur esclave. Ce fichier est appelé journal de relais. Ensuite, le thread SQL lira le contenu du journal de relais et l'appliquera au serveur esclave, afin que les données du serveur esclave et du serveur maître soient cohérentes. Le journal de relais agit comme un tampon afin que le maître n'ait pas à attendre la fin de l'exécution de l'esclave avant d'envoyer l'événement suivant.
Requête de paramètre relative au journal de relais:
mysql> show variables like '%relay%';
+---------------------------+------------------------------------------------------------+
| Variable_name | Value |
+---------------------------+------------------------------------------------------------+
| max_relay_log_size | 0 |
| relay_log | yangyuedeMacBook-Pro-relay-bin |
| relay_log_basename | /usr/local/mysql/data/yangyuedeMacBook-Pro-relay-bin |
| relay_log_index | /usr/local/mysql/data/yangyuedeMacBook-Pro-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | ON |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+---------------------------+------------------------------------------------------------+
11 rows in set (0.03 sec)</pre>
max_relay_log_size
Marquez le journal de relais maximum autorisé. Si la valeur est 0, la valeur par défaut est max_binlog_size (1G); si ce n'est pas 0, alors max_relay_log_size est la taille maximale du fichier relay_log.
relay_log_purge
Indique s'il faut effacer automatiquement le journal du relais lorsqu'il n'est plus nécessaire. La valeur par défaut est 1 (activé).
relay_log_recovery
Lorsque l'esclave sort de la bibliothèque, si le journal de relais est endommagé, entraînant le non-traitement d'une partie du journal de relais, tous les journaux de relais non exécutés sont automatiquement supprimés et le journal est de nouveau obtenu auprès du maître, garantissant ainsi l'intégrité du journal de relais. Cette fonction est désactivée par défaut. Lorsque la valeur de relay_log_recovery est définie sur 1, la fonction peut être activée sur la bibliothèque esclave. Il est recommandé de l'activer.
relay_log_space_limit
Pour éviter que les journaux de relais ne remplissent le disque, définissez ici la limite maximale des journaux de relais. Cependant, ce paramètre a pour conséquence que la bibliothèque principale se bloque et que le journal de relais de la bibliothèque esclave est incomplet. Ce n'est pas un dernier recours et n'est pas recommandé.
sync_relay_log
Ce paramètre et Binlog ont le sync_binlogmême effet. Lorsqu'il est défini sur 1, chaque fois que le thread d'E / S de l'esclave reçoit le journal Binlog envoyé par le maître, il doit être écrit dans la mémoire tampon du système, puis vidé dans le journal de relais du journal de relais. C'est le moyen le plus sûr, car dans le crash À ce stade, vous perdrez au plus une transaction, mais cela entraînera beaucoup d'E / S disque.
Lorsqu'il est défini sur 0, il n'est pas immédiatement vidé dans le journal de relais, mais le système d'exploitation décide quand écrire. Bien que la sécurité soit réduite, de nombreuses opérations d'E / S de disque sont réduites. Cette valeur est 0 par défaut et peut être modifiée dynamiquement. Il est recommandé d'utiliser la valeur par défaut.
sync_relay_log_info
Lorsqu'il est défini sur 1, chaque fois que le thread d'E / S de l'esclave reçoit le journal Binlog envoyé par le maître, il doit être écrit dans la mémoire tampon système, puis vidé dans relay-log.info. C'est le moyen le plus sûr car il plante. À ce stade, vous perdrez au plus une transaction, mais cela entraînera beaucoup d'E / S disque. Lorsqu'il est défini sur 0, il n'est pas immédiatement flashé dans relay-log.info, mais le système d'exploitation décide quand écrire. Bien que la sécurité soit réduite, de nombreuses opérations d'E / S sur disque sont réduites. Cette valeur est 0 par défaut et peut être modifiée dynamiquement. Il est recommandé d'utiliser la valeur par défaut.
Thread SQL du nœud esclave
Le thread SQL est chargé de lire le contenu du journal de relais, de l'analyser en opérations spécifiques et de les exécuter, et finalement d'assurer la cohérence des données maître-esclave.
Pour chaque connexion maître-esclave, ces trois processus doivent être exécutés. Lorsque le nœud maître a plusieurs nœuds esclaves, le nœud maître crée un processus de vidage du journal pour chaque nœud esclave actuellement connecté, et chaque nœud esclave a son propre processus d'E / S, le processus SQL.
Le nœud esclave utilise deux threads pour extraire les mises à jour et les exécuter de la bibliothèque principale dans des tâches indépendantes, de sorte que les performances des opérations de lecture ne soient pas réduites lorsque la tâche de synchronisation des données est exécutée. Par exemple, si le nœud esclave n'est pas en cours d'exécution, le processus d'E / S peut obtenir rapidement des mises à jour du nœud maître, même si le processus SQL ne s'est pas encore exécuté. Si le service du nœud esclave est arrêté avant l'exécution du processus SQL, au moins le processus d'E / S a extrait les dernières modifications du nœud maître et les a enregistrées dans le journal de relais local. Lorsque le service est à nouveau en marche, la synchronisation des données peut être terminée.
Pour implémenter la réplication, vous devez d'abord activer la fonction Binlog côté maître, sinon cela ne sera pas possible.
Parce que l'ensemble du processus de réplication est en fait que l'esclave obtient le journal du maître et exécute ensuite les différentes opérations enregistrées dans le journal dans un ordre complet sur lui-même. Comme indiqué ci-dessous:

Le processus de base de la copie
sart slave
master-info
relay log.info
MySQL est basé sur l'introduction du mode de réplication maître-esclave Binlog
La réplication maître-esclave MySQL est le mode asynchrone par défaut . Les opérations d'ajout, de suppression et de modification de MySQL seront toutes enregistrées dans Binlog. Lorsque le nœud esclave se connectera au maître, il obtiendra activement le dernier fichier Binlog du maître. Et stockez le Binlog dans le journal de relais local, puis exécutez le contenu mis à jour du journal de relais.
Mode asynchrone (mode asynchrone)
Le mode asynchrone est illustré ci-dessous:
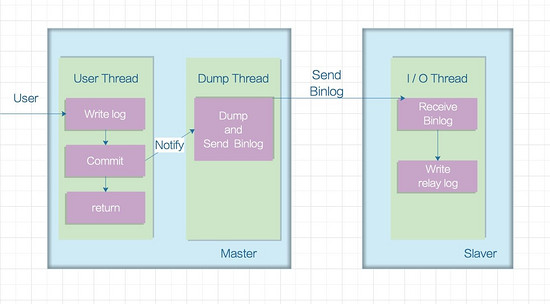
Dans ce mode, le nœud maître ne transmettra pas activement les données aux nœuds esclaves. La bibliothèque maître renverra immédiatement les résultats au client après avoir exécuté la transaction soumise par le client, et il ne se soucie pas de savoir si la bibliothèque esclave l'a reçue et traitée. Il y aura un problème. Si le nœud maître tombe en panne, les transactions qui ont été validées sur le nœud maître risquent de ne pas être transmises au nœud esclave. Si, à ce stade, la mise à niveau forcée sera le maître, ce qui peut entraîner la perte des données sur le nouveau nœud maître. Achevée.
Mode semi-synchro (semi-sync)
Entre la réplication asynchrone et la réplication entièrement synchrone, la bibliothèque principale ne revient pas au client immédiatement après l'exécution de la transaction soumise par le client, mais attend au moins une bibliothèque esclave pour recevoir et écrire dans le journal de relais avant de renvoyer un message de réussite au client (Il ne peut garantir que le Binlog de la bibliothèque principale est transmis à au moins un nœud esclave), sinon vous devez attendre le délai d'expiration, puis passer en mode asynchrone avant de soumettre.
[Échec de l'importation de l'image ... (image-d63820-1603346152190)]
Par rapport à la réplication asynchrone, la réplication semi-synchrone améliore la sécurité des données et garantit que les données peuvent être sauvegardées avec succès dans la base de données esclave dans une certaine mesure. En même temps, elle entraîne également un certain retard, mais il est inférieur au mode synchrone complet et présente le moins de retard. Est un temps d'aller-retour TCP / IP. Par conséquent, la réplication semi-synchrone est mieux utilisée dans les réseaux à faible latence.
Le mode semi-synchrone n'est pas intégré à MySQL. À partir de MySQL 5.5, le maître et l'esclave doivent installer des plug-ins pour activer le mode semi-synchrone.
Mode de synchronisation complet
Désigne le moment où la bibliothèque principale a terminé une transaction, puis toutes les bibliothèques esclaves ont copié la transaction et l'ont exécutée avec succès avant de renvoyer un message de réussite au client. Étant donné que vous devez attendre que tous les esclaves aient terminé la transaction avant de renvoyer un message de réussite, les performances de la réplication synchrone complète seront inévitablement affectées gravement.
Combat de réplication Binlog
Configurer my.cnf
[mysqld]
log-bin
server-id
gtid_mode=off #禁掉 gtid
Ajouter des utilisateurs de réplication maître-esclave:
grant replication slave on *.* to 'repl'@'%' identified by 'gtidUser';
flush privileges;
Ensuite, nous ajoutons une bibliothèque esclave.
Ensuite, nous utilisons la ligne de commande pour charger le Binlog de la bibliothèque principale dans la bibliothèque esclave, où vous pouvez définir le fichier binlog spécifié et la valeur de déplacement. Exécutez les commandes suivantes dans la bibliothèque esclave:
mysql>change master to
master_host='192.168.199.117',
master_user='slave',
master_port=7000,
master_password='slavepass',
master_log_file='mysql-bin.000008',
master_log_pos=0;
mysql>start slave;
mysql>show slave status\G;
Si une erreur de code se produit pendant le processus de copie, l'individu détermine s'il doit ignorer l'erreur et poursuivre l'exécution en fonction du journal des erreurs:
mysql>stop slave;
mysql>set global sql_slave_skip_counter=1;
Problèmes pouvant survenir lors de la réplication maître-esclave
Délai de synchronisation esclave
Parce que le côté esclave implémente l'analyse et le stockage des données via un seul thread d'E / S; et le Binlog du côté maître écrit dans l'ordre car il est très efficace. Lorsque le TPS de la bibliothèque principale est très élevé, l'efficacité d'écriture du côté maître doit être supérieure à celle du côté esclave. Efficacité de lecture, à ce moment il y a un problème de retard de synchronisation.
La synchronisation d'E / S Thread est basée sur une bibliothèque, c'est-à-dire que la synchronisation de plusieurs bibliothèques ouvrira plusieurs Threads d'E / S.
Par show slave statuscommande pour voir Seconds_Behind_Masters'il y a du point de vue valeur de retard de synchronisation, cette valeur représente la synchronisation maître-esclave de la temporisation, plus la valeur est élevée, plus les retards sont importants. Une valeur normale est égale à 0. Une valeur positive indique qu'un délai s'est produit. Plus le nombre est élevé, plus la bibliothèque esclave est en retard sur la bibliothèque maître.
La méthode de réplication basée sur Binlog doit avoir ce problème. Les responsables de MySQL se rendent également compte que le fil unique n'est pas aussi fort que le multi-thread, donc dans MySQL version 5.7, la réplication parallèle basée sur la soumission de groupe (officiellement appelée Enhanced Multi-threaded Slaves, ou MTS) a été introduite. , Paramètres de réglage:
slave_parallel_workers>0Oui, et global.slave_parallel_type=‘LOGICAL_CLOCK’,
Il peut prendre en charge un schéma (bibliothèque), slave_parallel_workersun thread de travail exécute simultanément la transaction soumise par la bibliothèque principale dans le journal de relais.
Son idée principale:
Toutes les transactions soumises par un groupe peuvent être lues en parallèle (avec validation de groupe de journaux binaires);
La même transaction last_committed (numéro de séquence différent) dans le journal de relais de la machine esclave peut être exécutée simultanément. Où la variable slave-parallel-typepeut avoir deux valeurs:
- DATABASE valeur par défaut, copie parallèle basée sur la bibliothèque
- LOGICAL_CLOCK, réplication parallèle basée sur la soumission de groupe
Il est très simple d'activer MTS dans MySQL 5.7. Il vous suffit de configurer les éléments suivants dans le fichier my.cnf de la base de données Slave:
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=8 #一般建议设置4-8,太多的线程会增加线程之间的同步开销
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
Bien entendu, la solution de réplication parallèle apportée par le multithreading présente également de nombreuses difficultés d'implémentation.Par exemple, les transactions sont exécutées de manière ordonnée.Si une lecture parallèle est effectuée, il y aura des problèmes de désordre des données d'exécution. Ces questions ne sont pas expliquées dans cette section et toutes les personnes intéressées peuvent continuer à les étudier.
Une nouvelle génération de mode de réplication maître-esclave-mode de réplication GTID
Dans la copie conventionnelle qui, en cas de panne, doit basculer sur le principal , et la nécessité de trouver des informations sur le site Binlog, après l'achèvement des données de récupération vers le nouveau site principal. Dans MySQL 5.6, une nouvelle idée de récupération de données est fournie. Il vous suffit de connaître l'adresse IP, le port et le mot de passe du compte du nœud maître. La réplication étant automatique, MySQL trouvera automatiquement un point de synchronisation via le mécanisme interne GTID .
La réplication basée sur GTID est une nouvelle méthode de réplication ajoutée après MySQL 5.6.5.
GTID (global transaction identifier) est l'ID de transaction global. Une transaction correspond à un GTID, qui garantit que chaque transaction soumise sur la bibliothèque principale a un ID unique dans le cluster.
Principe de réplication GTID
Dans la réplication d'origine basée sur le journal, la base de données esclave doit indiquer à la base de données maître à partir de quel décalage effectuer la synchronisation incrémentielle. Si l'erreur spécifiée est spécifiée, les données seront manquées et les données seront incohérentes.
Dans la réplication basée sur GTID, la bibliothèque esclave informera la bibliothèque maître de la valeur GTID de la transaction qui a été exécutée, puis la bibliothèque maître renverra la liste des GTID de toutes les transactions non exécutées à la bibliothèque esclave, et elle peut garantir que la même transaction est uniquement spécifiée La bibliothèque esclave est exécutée une fois, et la méthode de détermination de la transaction à exécuter par la bibliothèque esclave via l'ID de transaction global remplace la méthode précédente d'utilisation de Binlog et de l'emplacement pour déterminer la transaction à exécuter à partir de la bibliothèque.
Le processus de réplication basé sur GTID est le suivant:
gitd_next变量
Composition GTID
GTID = source_id: transaction_id
source_idCela est normalement server_uuidgénéré (fonction lors du premier démarrage generate_server_uuid) et conservé dans le DATADIR/auto.cnffichier.
transaction_idOui 顺序化的序列号(numéro de séquence), qui est une séquence auto-croissante commençant à 1 sur chaque serveur MySQL, et est l'identifiant unique de la transaction.
Génération GTID
GTID généré par le gtid_nextcontrôle.
Sur le maître, c'est gtid_nextla valeur par défaut AUTOMATIC, c'est-à- dire que le GTID est automatiquement généré à chaque fois qu'une transaction est validée. Il trouve une valeur minimale inutilisée supérieure à 0 à partir de l'ensemble GTID actuellement exécuté (c'est-à-dire gtid_executed) comme prochaine transaction GTID. Écrivez le GTID dans Binlog avant l'enregistrement de transaction de mise à jour réel.
Sur Slave, le GTID de la bibliothèque principale est d'abord lu à partir de Binlog (c'est-à-dire définir l'enregistrement gtid_next), puis la transaction exécutée utilise ce GTID.
Avantages de GTID
master_auto_position=1
Limitations de la réplication en mode GTID
-
Utilisation mixte de moteurs dans une transaction, comme Innodb (transactions de support), MyISAM (pas de transactions de support), entraînant des erreurs associées à plusieurs GTID et à la même transaction.
-
CREATE TABLE…..SELECTNe peut pas être utilisé, les deux événements générés par cette instruction. Dans une certaine situation, le même GTID sera utilisé (le même GTID ne peut être utilisé qu'une seule fois dans l'esclave):- événement un: instruction create table create table
- événement deux: insérer une instruction de données insérer
-
CREATE TEMPORARY TABLE and DROP TEMPORARY TABLENe peut pas être utilisé dans une transaction (–enforce-gtid-consistencyparamètre activé ). -
Utiliser la copie GTID de la bibliothèque ignore l'erreur, ne prend pas en charge les
sql_slave_skip_counterparamètres de syntaxe.
Combat de réplication maître-esclave GTID
1. Opérations sur la base de données principale principale
Configurer la réplication maître-esclave GTID dans le fichier my.cnf
[root@mysql-master ~]# cp /etc/my.cnf /etc/my.cnf.bak
[root@mysql-master ~]# >/etc/my.cnf
[root@mysql-master ~]# cat /etc/my.cnf
[mysqld]
datadir = /var/lib/mysql
socket = /var/lib/mysql/mysql.sock
symbolic-links = 0
log-error = /var/log/mysqld.log
pid-file = /var/run/mysqld/mysqld.pid
#GTID:
server_id = 1
gtid_mode = on
enforce_gtid_consistency = on
#binlog
log_bin = mysql-bin
log-slave-updates = 1
binlog_format = row
sync-master-info = 1
sync_binlog = 1
#relay log
skip_slave_start = 1
Après la configuration, redémarrez le service MySQL:
[root@mysql-master ~]# systemctl restart mysqld
Connectez-vous à MySQL et vérifiez l'état du maître. Il y a encore un élément Executed_Gtid_Set:
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 154 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> show global variables like '%uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | 317e2aad-1565-11e9-9c2e-005056ac6820 |
+---------------+--------------------------------------+
1 row in set (0.00 sec)
Vérifiez que la fonction GTID est activée:
mysql> show global variables like '%gtid%';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| session_track_gtids | OFF |
+----------------------------------+-------+
8 rows in set (0.00 sec)
Vérifiez que la fonction de journalisation Binlog est activée:
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
Autorisez l'esclave à copier les utilisateurs et à actualiser les autorisations:
mysql> flush privileges;
Query OK, 0 rows affected (0.04 sec)
mysql> show grants for slave@'172.23.3.66';
+-------------------------------------------------------------------------------+
| Grants for [email protected] |
+-------------------------------------------------------------------------------+
| GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'172.23.3.66' |
+-------------------------------------------------------------------------------+
1 row in set (0.00 sec)
Vérifiez à nouveau l'état du maître:
mysql> show master status;
+-------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000001 | 622 | | | 317e2aad-1565-11e9-9c2e-005056ac6820:1-2 |
+-------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
Notez ici:
Avant de démarrer la configuration, le serveur esclave doit également être initialisé. La méthode d'initialisation du serveur esclave est fondamentalement la même que celle basée sur le point de journal, sauf qu'après le démarrage du mode GTID, ce qui est enregistré dans la sauvegarde n'est pas le nom et le décalage du fichier journal binaire pendant la sauvegarde, mais la sauvegarde. La dernière valeur GTID à l'époque.
Vous devez d'abord sauvegarder la base de données cible sur la machine de base de données principale, en supposant que la base de données cible est slave_test:
mysql> CREATE DATABASE slave_test CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.02 sec)
mysql> use slave_test;
Database changed
mysql> create table user (id int(10) PRIMARY KEY AUTO_INCREMENT,name varchar(50) NOT NULL);
Query OK, 0 rows affected (0.27 sec)
mysql> insert into slave_test.user values(1,"xiaoming"),(2,"xiaohong"),(3,"xiaolv");
Query OK, 3 rows affected (0.06 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from slave_test.user;
+----+----------+
| id | name |
+----+----------+
| 1 | xiaoming |
| 2 | xiaohong |
| 3 | xiaolv |
+----+----------+
3 rows in set (0.00 sec)
Sauvegardez la bibliothèque slave_test:
[root@mysql-master ~]# mysqldump --single-transaction --master-data=2 --triggers --routines --databases slave_test -uroot -p123456 > /root/user.sql
Voici un problème de version:
Utilisation de MySQL 5.6 mysqldumppendant la sauvegarde, la sauvegarde désignait des bibliothèques spécifiques à utiliser --database.
Utilisation de MySQL 5.7 mysqldumppendant la sauvegarde, la sauvegarde a désigné des bibliothèques spécifiques, utilisez--databases。
Ensuite, la /root/user.sqlcopie de sauvegarde du fichier sur le serveur esclave à partir de la base de données.
[root@mysql-master ~]# rsync -e "ssh -p20" -avpgolr /root/user.sql
À ce stade, le fonctionnement de la bibliothèque principale est terminé, les données de sauvegarde contenant GTID ont été copiées dans la bibliothèque esclave et le fonctionnement de la bibliothèque esclave est effectué ci-dessous.
2. Fonctionnement depuis la bibliothèque
Configurer la réplication maître-esclave GTID dans le fichier my.cnf
La configuration du serveur maître est à peu près la même. Outre l'incohérence de server_id, le serveur esclave peut également être ajouté dans le fichier de configuration read_only=on, afin que le serveur esclave ne puisse effectuer que des opérations de lecture. Ce paramètre n'est pas valide pour le super utilisateur et n'affectera pas la réplication du serveur esclave.
[root@mysql-slave1 ~]# >/etc/my.cnf
[root@mysql-slave1 ~]# vim /etc/my.cnf
[mysqld]
datadir = /var/lib/mysql
socket = /var/lib/mysql/mysql.sock
symbolic-links = 0
log-error = /var/log/mysqld.log
pid-file = /var/run/mysqld/mysqld.pid
#GTID:
server_id = 2
gtid_mode = on
enforce_gtid_consistency = on
#binlog
log_bin = mysql-bin
log-slave-updates = 1
binlog_format = row
sync-master-info = 1
sync_binlog = 1
#relay log
skip_slave_start = 1
read_only = on
Une fois la configuration terminée, redémarrez le service mysql.
[root@mysql-slave1 ~]# systemctl restart mysql
Ensuite, les données de sauvegarde de la base de données de la bibliothèque cible principale user.sqldans la base de données.
[root@mysql-slave1 ~]# ls /root/user.sql
/root/user.sql
[root@mysql-slave1 ~]# mysql -p123456
.........
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
mysql> source /root/user.sql;
mysql> select * from slave.test;
+----+----------+
| id | name |
+----+----------+
| 1 | xiaoming |
| 2 | xiaohong |
| 3 | xiaolv |
+----+----------+
3 rows in set (0.00 sec)
Dans la base de données, à change masterl' aide de la configuration de réplication principale:
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> change master to master_host='172.23.3.66',master_user='slave1',master_password='123456',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.26 sec)
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.23.3.66
Master_User: slave1
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 1357
Relay_Log_File: mysql-slave1-relay-bin.000002
Relay_Log_Pos: 417
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
................
................
Executed_Gtid_Set: 317e2aad-1565-11e9-9c2e-005056ac6820:1-5
Auto_Position: 1
Par conséquent, les nœuds maître et esclave ont été configurés avec une relation de synchronisation maître-esclave. Ensuite, vous pouvez insérer une donnée dans la bibliothèque maître pour voir si la bibliothèque esclave est synchronisée.
Il y a deux façons d'ajouter une bibliothèque esclave à l'aide de GTID
Synchronisez directement tous les GTID de la bibliothèque principale
Si GTID est activé dans la bibliothèque principale depuis le début, tous les GTID de la bibliothèque principale peuvent être directement obtenus pour se synchroniser avec la bibliothèque esclave. Mais s'il y a trop de journaux Binlog dans la bibliothèque principale, le temps de synchronisation correspondant sera également plus long. Cette méthode convient à la synchronisation de petits volumes de données.
Utilisez cette méthode pour synchroniser les commandes correspondantes:
mysql>change master to master_host='xxxxxxx',master_user='xxxxxx',master_password='xxxxx',MASTER_AUTO_POSITION=1;
mysql> start slave;
mysql> stop slave io_thread; #重启 io 线程,刷新状态
mysql> start slave io_thread;
Lorsque MASTER_AUTO_POSITIONles paramètres de temps MASTER_LOG_FILE, MASTER_LOG_POSles paramètres ne peuvent pas être utilisés.
Si vous souhaitez GTID 配置回 possuivre, exécutez à nouveau cette instruction, mais définissez MASTER_AUTO_POSITION sur 0.
Synchroniser par plage de réglage
GTID en spécifiant une plage, puis l'esclave est fourni @@GLOBAL.GTID_PURGEDafin de sauter la sauvegarde GTID incluse.
Cette solution convient aux données dont le volume de données est relativement important et une synchronisation prend un temps considérable. Mais en même temps, il y a aussi le problème des opérations compliquées, qui oblige à se souvenir de la portée de chaque synchronisation.
Les commandes correspondantes pour synchroniser de cette manière sont:
mysql>change master to master_host='xxxxxxx',master_user='xxxxxx',master_password='xxxxx',MASTER_LOG_POS='xxxx';
mysql> start slave;
mysql> stop slave io_thread; #重启 io 线程,刷新状态
mysql> start slave io_thread;
Notez ici que nos paramètres ont été modifiés:, MASTER_LOG_POSce paramètre représente la valeur de départ de la transaction GTID qui doit actuellement être synchronisée.
Pour résumer
Cet article présente deux formes de réplication maître-esclave: la méthode de réplication traditionnelle basée sur Binlog et les informations de site; et la nouvelle méthode de réplication basée sur Binlog et GTID. De nombreuses entreprises peuvent encore utiliser la version MySQL 5.6, de sorte que GTID peut ne pas être disponible.
Cet article est long, vous pouvez donc passer brièvement en revue le principe.