Avant-propos:
Peut - être qu'avant de lire cet article, votre concept de Git et GitHub est encore très vague, peut-être que vous pensiez qu'ils sont la même chose, mais en fait ils ne le sont pas, en fait, les deux sont des choses complètement différentes , Si nous voulons entrer dans la porte de GitHub, nous devons d'abord traverser la montagne de Git. L'auteur fait ici hardiment une métaphore pour les deux d'entre eux. Git est comme un camion, et GitHub est un entrepôt, et l'identité de Git est d'agir comme un lien entre chaque entrepôt. Transport. Bien sûr, cette analogie n'est pas très appropriée, et le talent littéraire de l'auteur est également très limité. Mais je pense que vous devriez rapidement comprendre ce que sont Git et GitHub après avoir lu les explications et les applications ci-dessous. Je ne le vendrai pas ici. Entrons dans le sujet d'aujourd'hui;
1. Le contexte de Git
-
Git a été écrit par Linus Torvalds, le fondateur du système Linux, en 2005. À cette époque, ce n'était qu'un rudiment et ne pouvait pas être appelé Git dans le vrai sens du terme, en raison de la licence de développeur du système de gestion de version existant utilisé dans le développement du noyau Linux. Afin de remplacer le nouveau système de gestion des versions, Linus a développé plus tard Git sur la base du précédent. Comme nous le savons tous, la vitesse de mise à jour du noyau Linux est incomparable dans le monde.Par conséquent, un système de gestion de version puissant et performant est appelé à augmenter la vitesse de développement. Dans l'environnement open source à cette époque, bien que plusieurs logiciels de gestion de versions aient été développés, les fonctions et les performances ne sont pas satisfaisantes. De plus, Git a été personnellement développé par Linus Torvalds, on peut donc dire qu'il est impeccable en termes de fonctionnalités et de performances. La volonté des programmeurs d'accepter Git dépend dans une large mesure de ce contexte pour bénéficier du développement.
-
En fait, il existe de nombreux outils de contrôle de version sur le marché, tels que CSV (Concurrent Version System), SVN (Subversion), etc.
-
Alors, pourquoi Git apparaît-il, et en quoi est-il différent des autres outils de contrôle de version. Voici un par un
(1) Tout d'abord, la plus grande différence entre Git et SVN, CSV est: Git est distribué , et les deux derniers L'un n'est pas, c'est la différence la plus essentielle
(2) L'intégrité du contenu de Git est meilleure que celle de SVN: le stockage de contenu de Git utilise l'algorithme de hachage SHA-1. Cela peut garantir l'intégrité du contenu du code et réduire les dommages au référentiel en cas de panne de disque et de problèmes de réseau.
(3) La branche Git est différente de la branche SVN: la branche n'est pas spéciale dans SVN, en fait c'est le référentiel Dans un autre annuaire de Git, la branche ignore quasiment l'utilisateur quand elle vient. Vous avez complètement l'impression qu'il n'y a pas de connexion entre les deux branches. Cela semble être deux environnements différents, ce qui est un peu similaire à celui du téléphone mobile actuel. L'effet d'un clone de téléphone mobileRemarque: en fait, il existe de nombreuses différences, toutes ne sont pas répertoriées ici
-
Plus tôt, lorsque nous avons parlé de la différence entre Git et les autres outils de contrôle de version, nous avons mentionné un mot-clé ( distribué ). Avec le développement du big data maintenant, il peut être vu partout. Puis des outils de contrôle de version distribués et centralisés ordinaires Quelle est la différence entre un outil de contrôle de version et qui est meilleur?
-
En fait, cet auteur peut affirmer avec certitude qu'il n'y a pas de différence entre les deux architectures différentes des outils de contrôle de version, celle que vous utilisez dépend entièrement de vos besoins de travail.
-
Jetons un coup d'œil au modèle d'architecture de l'outil de contrôle de version centralisé :
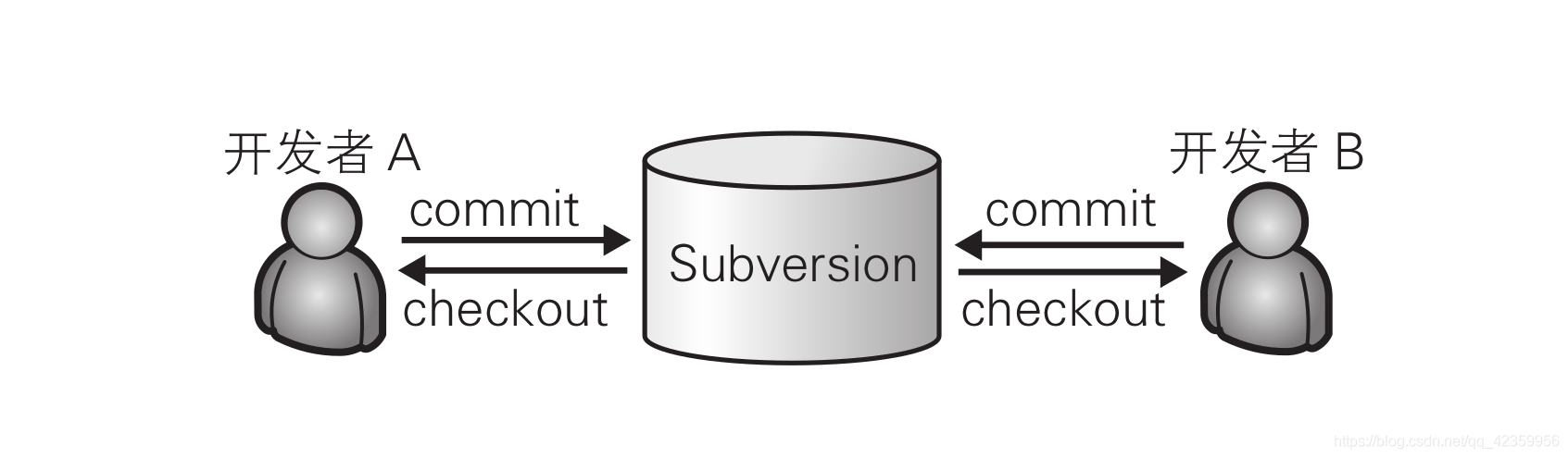 D'après la figure ci-dessus, nous pouvons voir que l'entrepôt est stocké dans le serveur, il n'y a donc qu'un seul entrepôt. C'est pourquoi ce système de gestion de version est appelé centralisé. Le type centralisé stocke toutes les données sur le serveur, ce qui présente l'avantage d'une gestion facile. L'inconvénient est qu'une fois que l'environnement du développeur ne peut pas se connecter au serveur, le dernier code source ne peut pas être obtenu et le développement est presque impossible. La même chose est vraie lorsque le serveur est en panne, et si le serveur échoue et que les données disparaissent, j'ai peur que le développeur ne reverra jamais le dernier code source.
D'après la figure ci-dessus, nous pouvons voir que l'entrepôt est stocké dans le serveur, il n'y a donc qu'un seul entrepôt. C'est pourquoi ce système de gestion de version est appelé centralisé. Le type centralisé stocke toutes les données sur le serveur, ce qui présente l'avantage d'une gestion facile. L'inconvénient est qu'une fois que l'environnement du développeur ne peut pas se connecter au serveur, le dernier code source ne peut pas être obtenu et le développement est presque impossible. La même chose est vraie lorsque le serveur est en panne, et si le serveur échoue et que les données disparaissent, j'ai peur que le développeur ne reverra jamais le dernier code source.
- Parlons du modèle d'architecture de l'outil de contrôle de version distribué.
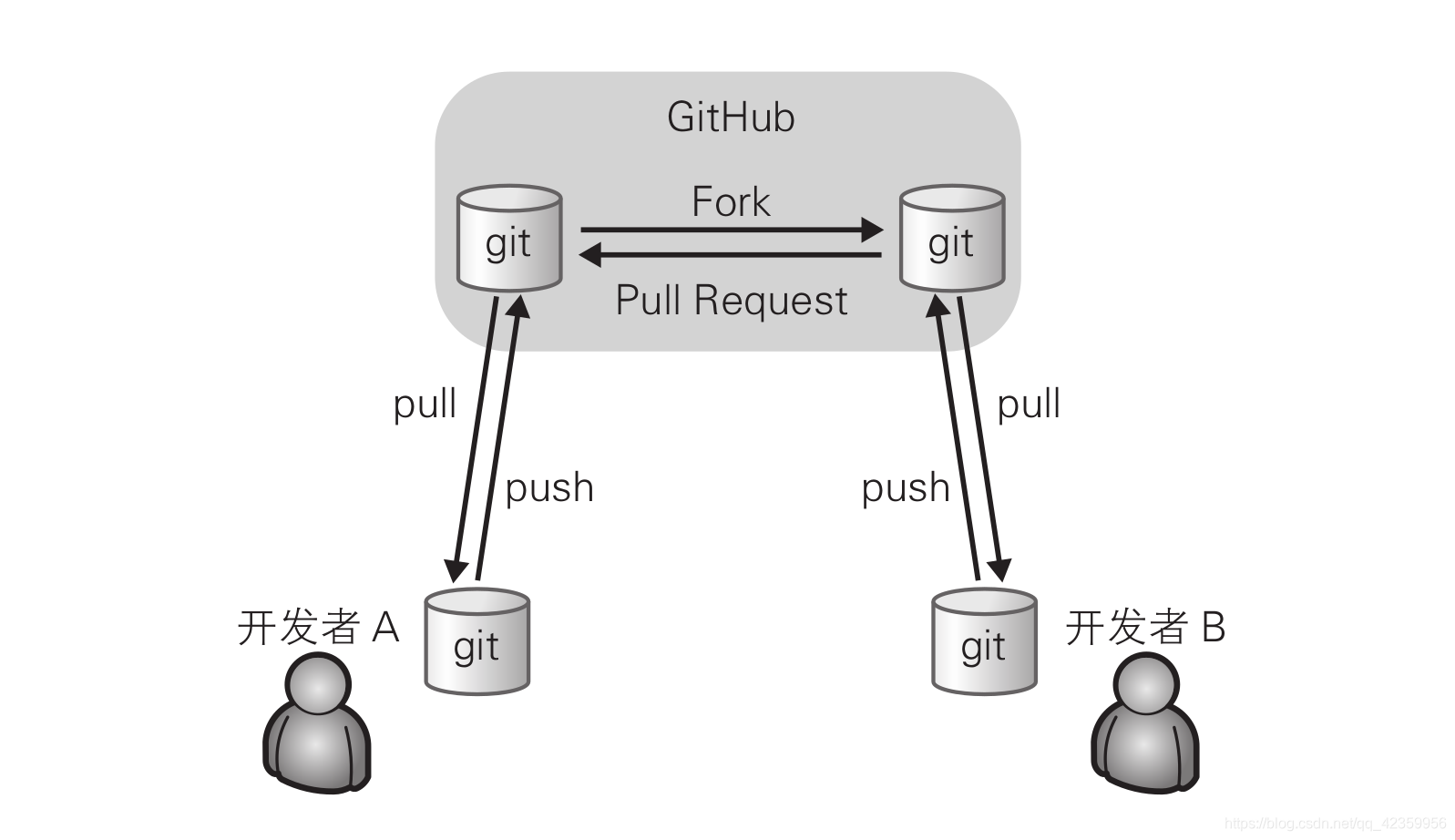
Vous pouvez voir sur la figure que GitHub équivaut à un pont public. Grâce à ce pont et à l'outil Git, nous pouvons communiquer avec d'autres développeurs à tout moment et n'importe où. GitHub Fournissez aux utilisateurs des entrepôts de stockage dans le cloud et pouvez donner des fourchettes d'entrepôt à chaque utilisateur (notez qu'il est ouvert ou autorisé). Fork consiste à copier un référentiel spécifique sur GitHub dans votre compte. L'entrepôt de Fork et l'entrepôt d'origine sont deux entrepôts différents. Les développeurs peuvent éditer sur leurs propres entrepôts (les entrepôts mentionnés ci-dessus sont toujours stockés côté serveur). Dans le développement actuel, nous Je vais cloner mon propre entrepôt sur GitHub vers le local, puis définir le distant (en amont) de l'entrepôt Git local du côté GitHub. L'outil de contrôle de version de l'architecture distribuée dispose de plusieurs entrepôts, ce qui est relativement compliqué. Cependant, comme il existe un entrepôt dans l'environnement de développement local, les développeurs peuvent développer sans se connecter à un entrepôt distant. Voici quelques exemples simples dans la figure. En fait, sous les relations complexes sur Internet, le modèle Git actuel est beaucoup plus compliqué que celui montré dans la figure.
Remarque: dans l'explication précédente, de nombreux concepts de modèle Git ont été mentionnés. Peut-être que vous n'avez toujours rien entendu, alors vous pouvez aussi bien jeter un œil aux applications suivantes pour approfondir votre compréhension.
2. Paramètres d'initialisation
-
L'installation sur un système
Linux est très simple, une seule commande:# Debian 发行版(Ubuntu,Kali ..): sudo apt install -y git # Red Hat 发行版(CentOS): sudo yum install -y gitSous Windows , comme la ligne de commande utilise la commande Dos pour interagir, vous devez vous rendre sur le site officiel pour télécharger la version Windows
Git pour Windows
. Je ne le mentionnerai pas ici pour des raisons d'espace, car ce n'est pas l'objet de cet article. Les lecteurs peuvent se référer à Google ou à Baidu. Tutoriels d'installation connexes.
Si vous êtes débutant, vous pouvez également essayer d'utiliser l'interface graphique Git pour faire fonctionnerLes utilisateurs de MacOs peuvent utiliser homebrew pour installer
brew install git -
Configuration Une fois l'
installation terminée, nous devons encore configurer Git. Après tout, voici comment nous pouvons l'utiliser.
(1) Définissez votre nom. En tant qu'excellent développeur, d'autres seront plus intéressés par vous après avoir vu votre code. , Vous devez laisser les autres se souvenir de vous, il est donc très important de vous donner un nom, et c'est aussi de distinguer la fiche d'identité lors de la soumission du code.git config --global user.name "firstname lastname"(2) Il ne suffit pas d'avoir un nom. Sur Internet illimité, personne ne peut garantir que personne ne porte le même nom que vous, nous avons donc besoin d'une identification unique qui puisse vous représenter. Il vous suffit donc de configurer une adresse e-mail. Il est pratique pour les autres de vous contacter.
git config --global user.email "[email protected]"(3) Le livre de codes est ennuyeux. Pourquoi ne pas décorer ce monde gris avec quelques couleurs. C'est un bon choix pour mettre en évidence.
git config --global color.ui auto(4) Que font ces quelques lignes de code, autant retourner dans votre répertoire HOME et y jeter un œil.
cat .gitconfig ============================= .giticonfig ========================== [user] name = firstname lastname email = [email protected] [color] ui = auto ================================= END ===============================Dans votre répertoire HOME, il y aura un nom supplémentaire appelé gitconfig, le contenu à l'intérieur est ce que nous venons d'utiliser pour configurer, vous pouvez également modifier directement les informations de configuration dans ce fichier pour qu'elles soient les mêmes.
Remarque: Bien sûr, les paramètres sont bien plus que ceux-ci, et il y a beaucoup plus de paramètres qui peuvent être configurés.Les lecteurs peuvent se référer à la documentation officielle pour la configuration.
-
Initialiser le répertoire de travail de git Une
fois l'installation et la configuration terminées, nous devons exécuter un répertoire comme répertoire de travail. Créons un nouveau répertoire pour les tests de Git dans le répertoire HOME, et utilisons la commande Git pour entrer dans ce répertoire. Ce répertoire est initialisé;mkdir GitTest cd GitTest git initC'est la première commande git que vous avez apprise. Est-ce simple? Voyons ce que fait cette commande.
ls -aNous pouvons voir qu'il existe un répertoire caché supplémentaire nommé .git dans le répertoire GitTest. En fait, il enregistre l'ensemble de l'arborescence de travail de Git. Il enregistre les informations de métadonnées du fichier, la version historique, le journal des opérations, etc. Attendre.
3. Pratique du commandement
-
git status
prompt après que vous devriez être en mesure d'effectuer le ménage dans la figure ci-dessous la
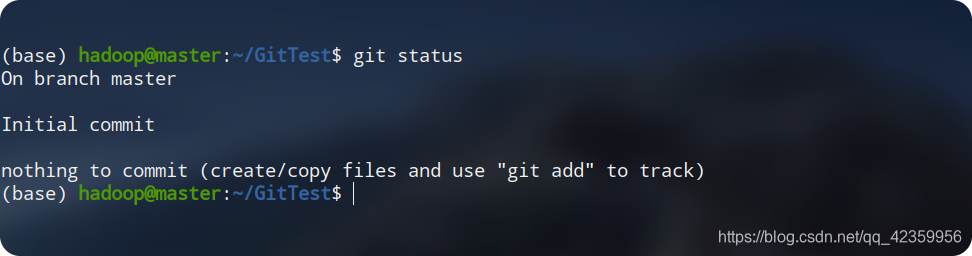
première ligne indique que nous sommes dans la branche master (après qu'init git crée automatiquement une branche master qui est notre branche principale, la branche développera le concept derrière)
second La ligne indique notre état ou l'état de la soumission initiale. La
troisième ligne indique que nous n'avons actuellement aucun fichier à soumettre.Jetons un coup d'œil à un nouveau fichier:
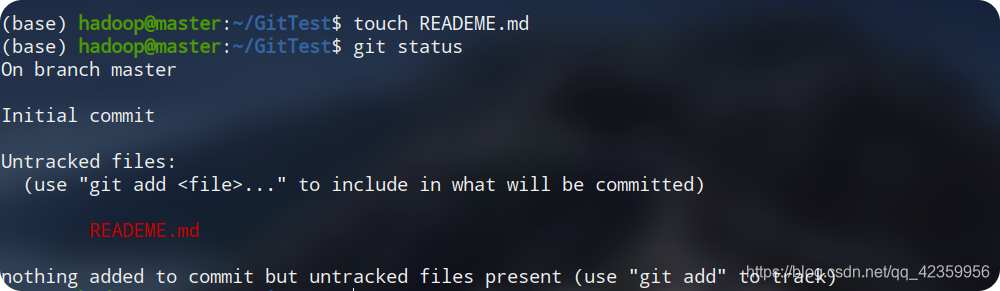
Le fichier que nous avons créé est le fichier REDEME.md. Ce fichier utilise la syntaxe MarkDown. Il est utilisé pour présenter le but de votre code aux personnes qui voient votre code. Vous pouvez également apprendre la syntaxe de MarkDown. Cela reste très utile. Il est également souvent utilisé dans le travail. À partir de l'image ci-dessus, vous pouvez voir que nous avons une ligne d'invite supplémentaire lorsque nous exécutons la commande "git status", et elle est toujours rouge (voir la comparaison Important), son invite est que ce fichier n'a pas encore été soumis, vous pouvez essayer la commande donnée pour le soumettre -
git add
Ici, nous exécutons la commande selon l'invite donnée ci-dessus, et ajoutons le fichier nouvellement créé à la zone de stockage temporaire du fichier.
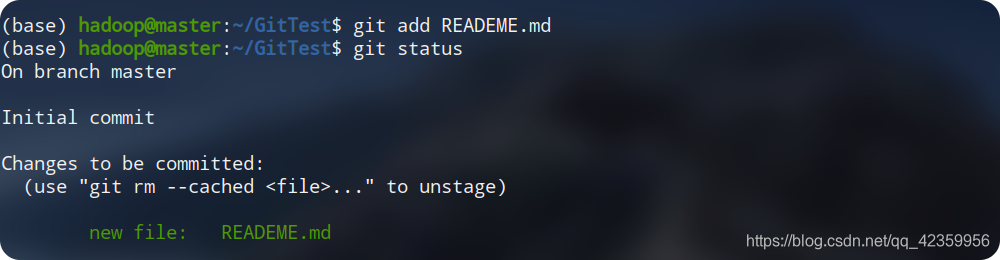
À partir du processus d'exécution de la figure, nous pouvons voir que nous avons déjà ajouté le fichier nouvellement créé à la zone de stockage temporaire du fichier. , Mais notez qu'il n'a pas encore été soumis. -
git commit,
nous devons donc soumettre à nouveau les fichiers stockés dans la zone de stockage temporaire.
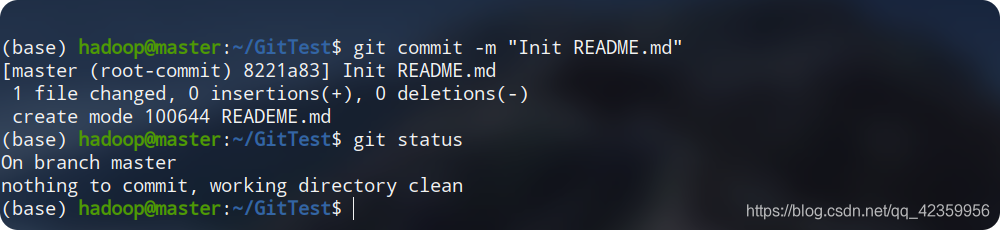
J'ai utilisé le paramètre '-m' ici, qui écrira directement la chaîne suivante (c'est-à-dire une description de notre soumission) Entrez ce journal de soumission, si vous n'ajoutez pas ce paramètre, vous entrerez dans une interface de ligne de commande interactive, puis remplirez les informations pertinentes. Une fois la soumission terminée, nous pouvons utiliser la commande d'état de vue précédente pour trouver que l'ensemble du projet L'état est restauré à son état d'origine. -
git log
Parfois, nous voulons afficher l'historique de soumission de l'ensemble du projet, nous pouvons utiliser cette commande pour l'afficher.

D'après la figure ci-dessus, nous pouvons voir que les informations du journal de l'esprit sont divisées en quatre lignes. La
première ligne représente le code de hachage de la soumission. Ce code se trouve dans ce L'élément est unique et sert à indiquer la seule opération. La
deuxième ligne contient les informations, le nom et l'adresse e-mail de l'expéditeur. La
troisième ligne indique la date et l'heure de soumission. La
quatrième ligne contient les informations de description renseignées lors de la soumission. -
git diff
Essayons maintenant d'ajouter une ligne de contenu au fichier. Essayez à
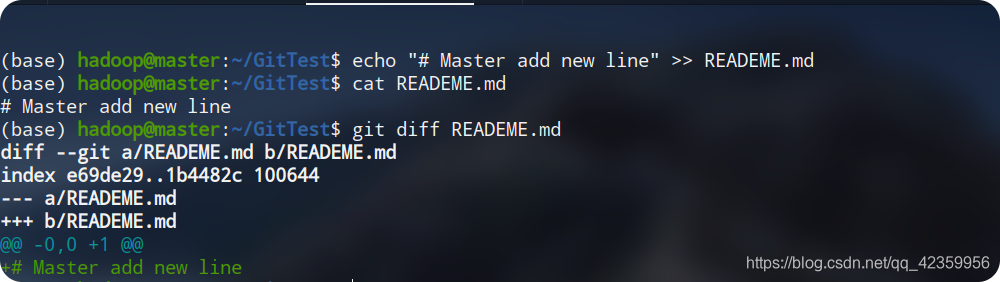
partir de la figure, vous pouvez voir que nous avons d'abord ajouté une ligne de contenu au fichier, puis nous utilisons la commande "git diff" pour voir la différence entre le fichier et l'état actuel Vous pouvez voir que les informations de sortie indiquent que le contenu de notre fichier et le fichier stocké dans la branche sont différents. Le fichier actuel a ajouté une ligne de contenu par rapport à l'original.
Ensuite, nous utilisons toujours la méthode précédente pour soumettre cette modification ensemble :

Vous pouvez voir que le fichier REDEME n'est actuellement pas différent de la dernière version
Eh bien, vous maîtrisez les commandes les plus élémentaires de Git. Bien sûr, des opérations plus avancées vous attendent, telles que le branchement, le retour en arrière, la modification des informations de soumission, le transfert des données de l'entrepôt local vers l'entrepôt distant et leur extraction depuis l'entrepôt distant. , Clonage de projet, etc., parce que vous ne vous souciez pas de l'apprentissage des connaissances, mais de la compréhension, trop de contacts à la fois ne peuvent pas être digérés immédiatement, le blogueur expliquera donc les opérations plus avancées en détail dans l'article plus loin dans cette rubrique. Après avoir vu cela, merci d'avoir pris un temps si précieux pour lire le blog du blogueur, et merci pour votre attitude de connaissance avide, merci pour la plateforme CSDN, merci!