Répertoire d'articles
Principe de Fork-Join
Type de tâche
Lié au processeur
Le processeur intensif est également appelé calcul intensif. Cela fait référence aux performances du disque dur du système et la mémoire est bien meilleure que celle du processeur. À l'heure actuelle, la plupart des opérations du système consistent en une charge du processeur à 100% et le processeur doit lire / écrire des E / S (disque dur / mémoire ), Les E / S peuvent être terminées en peu de temps et la CPU a encore de nombreuses opérations à traiter, et la charge CPU est très élevée. Dans un système multi-programme, le programme qui passe le plus clair de son temps à faire des calculs, des jugements logiques et d'autres actions CPU est appelé CPUbound. Par exemple, un programme qui calcule pi à mille chiffres sous la virgule décimale est utilisé pour le calcul des fonctions trigonométriques et des racines carrées la plupart du temps dans le processus d'exécution, et c'est un programme qui appartient à la CPU liée. Les programmes liés au processeur ont généralement un taux d'utilisation élevé du processeur. Cela peut être dû au fait que la tâche elle-même n'a pas besoin d'accéder au périphérique d'E / S ou au fait que le programme est implémenté dans plusieurs threads et protège ainsi le temps d'attente des E / S.
Le nombre de threads est généralement défini comme suit:
nombre de threads = nombre de cœurs CPU + 1
IO intensive (I / O lié)
Les E / S intensives font référence au fait que les performances du processeur du système sont bien meilleures que celles du disque dur et de la mémoire. À ce stade, le système fonctionne. La plupart des conditions sont que le processeur attend des opérations de lecture / écriture d'E / S (disque dur / mémoire). À ce stade, le chargement du processeur ne fonctionne pas pas grand. En règle générale, lorsque le programme lié aux E / S atteint la limite de performances, l'utilisation du processeur est encore faible. Cela peut être dû au fait que la tâche elle-même nécessite de nombreuses opérations d'E / S, que le pipeline ne fonctionne pas correctement et que la puissance du processeur n'est pas pleinement utilisée.
Le nombre de threads est généralement défini comme suit:
nombre de threads = ((temps d'attente du thread + temps d'exécution du processeur du thread) / temps d'exécution du processeur du thread) * numéro de cœur du processeur
Processeur intensif vs IO
Nous pouvons diviser les tâches en tâches intensives en calcul et en E / S.
La caractéristique des tâches intensives en calcul est d'effectuer un grand nombre de calculs et de consommer des ressources CPU, telles que le calcul du ratio pi, et le décodage haute définition de vidéos, etc., le tout en s'appuyant sur la puissance de calcul du CPU. Bien que ce type de tâche gourmande en calculs puisse également être effectué en multitâches, plus il y a de tâches, plus le temps passé à la commutation de tâches est important et plus l'efficacité du processeur pour effectuer des tâches est faible. Par conséquent, l'utilisation la plus efficace du processeur, le calcul intensif Le nombre de tâches simultanées doit être égal au nombre de cœurs de processeur. Les tâches intensives en calcul consomment principalement des ressources CPU, de sorte que l'efficacité de l'opération de code est très importante. Les langages de script tels que Python ont une efficacité de fonctionnement très faible et sont totalement inadaptés aux tâches intensives en calcul. Pour les tâches intensives en calcul, il est préférable d'écrire en langage C.
Le deuxième type de tâche est gourmand en E / S. Les tâches impliquant des E / S réseau et disque sont toutes des tâches gourmandes en E / S. Ce type de tâche se caractérise par une faible consommation CPU et la plupart de la tâche attend la fin de l'opération d'E / S (car La vitesse d'E / S est bien inférieure à la vitesse du processeur et de la mémoire). Pour les tâches gourmandes en E / S, plus il y a de tâches, plus l'efficacité du processeur est élevée, mais il y a une limite. La plupart des tâches courantes sont des tâches gourmandes en E / S, telles que les applications Web. Lors de l'exécution de tâches gourmandes en E / S, 99% du temps est consacré aux E / S, et très peu de temps est consacré au processeur. Par conséquent, il est totalement impossible de remplacer un langage de script tel que Python par un langage C très rapide. Améliorez l'efficacité opérationnelle. Pour les tâches à forte intensité d'E / S, le langage le plus approprié est le langage avec la plus grande efficacité de développement (moins de code), le langage de script est le premier choix et le langage C le pire.
Cadre Fork-Join
Définition et caractéristiques
Le framework Fork-Join est un framework pour l'exécution parallèle de tâches fourni par Java 7. C'est un framework qui divise une grande tâche
en plusieurs petites tâches, et enfin résume les résultats de chaque petite tâche pour obtenir le résultat de la grande tâche.
Fork consiste à diviser une grande tâche en plusieurs sous-tâches pour une exécution parallèle, et Join consiste à fusionner les résultats d'exécution de ces sous-tâches, et enfin obtenir le résultat de cette grande tâche. Par exemple, calculer 1 + 2 + ... + 10000 peut être divisé en 10 sous-tâches, et chaque sous-tâche additionne 1000 nombres, et résume enfin les résultats de ces 10 sous-tâches. Comme indiqué ci-dessous:
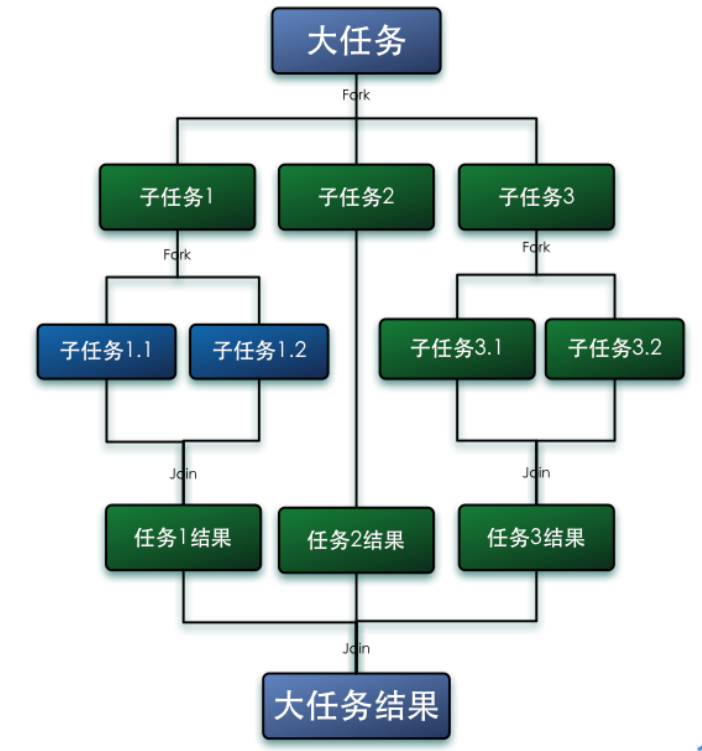
Caractéristiques de Fork-Jion:
- ForkJoinPool n'est pas pour remplacer ExecutorService, mais pour le compléter. Dans certains scénarios d'application, ses performances sont meilleures que ExecutorService.
- ForkJoinPool est principalement utilisé pour implémenter des algorithmes de division et de conquête , en particulier des fonctions appelées récursivement après la division et la conquête, telles que le tri rapide.
- ForkJoinPool est le plus approprié pour les tâches intensives en calcul. S'il y a des E / S, une synchronisation entre les threads, sleep (), etc., qui provoquent le blocage des threads pendant une longue période, il est préférable d'utiliser ManagedBlocker.
Algorithme de vol de travail
Le framework de base ForkJoin est un mécanisme de planification léger, utilisant la stratégie de planification de base de vol de travail (Work-Stealing) adoptée.
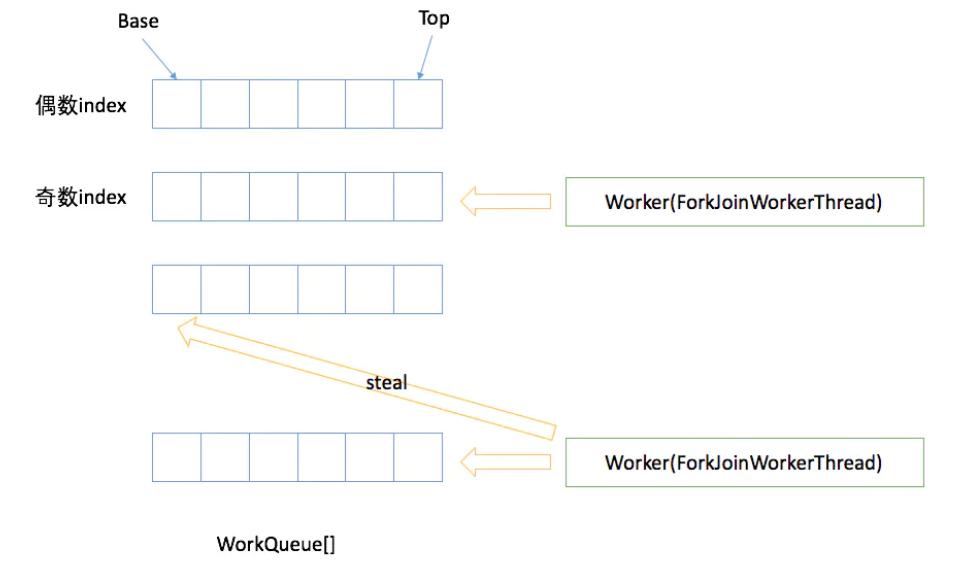
L'algorithme de vol de travail fait référence à un thread volant des tâches à partir d'autres files d'attente pour exécution. Nous devons faire une tâche relativement importante. Nous pouvons diviser cette tâche en plusieurs sous-tâches indépendantes. Afin de réduire la concurrence entre les threads, nous mettons ces sous-tâches dans différentes files d'attente, et créons pour chaque file d'attente. Un thread distinct exécute les tâches de la file d'attente et le thread correspond à la file d'attente un à un. Par exemple, le thread A est responsable du traitement des tâches de la file d'attente A. Cependant, certains threads termineront les tâches dans leurs propres files d'attente en premier, alors que des tâches attendent encore d'être traitées dans les files d'attente correspondant aux autres threads. Au lieu d'attendre, le thread qui a terminé son travail pourrait aussi bien aider d'autres threads à fonctionner, il est donc allé dans la file d'attente d'autres threads pour voler une tâche à exécuter. À ce stade, ils accèderont à la même file d'attente, donc afin de réduire la concurrence entre le thread de tâche volé et le thread de tâche volé, une file d'attente à deux extrémités est généralement utilisée. Le thread de tâche volé exécute toujours la tâche à partir du haut de la file d'attente à deux extrémités. Le thread qui vole la tâche exécute toujours la tâche à partir de la base du deque.
Le processus en cours de vol de travail est illustré dans la figure ci-dessous:
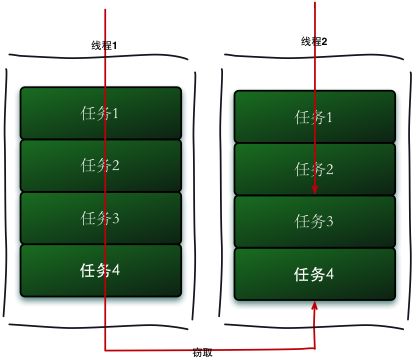
-
L'avantage de l'algorithme de vol de travail est de tirer pleinement parti des threads pour le calcul parallèle et de réduire la concurrence entre les threads.
-
L'inconvénient de l'algorithme de vol de travail est qu'il y a encore de la concurrence dans certains cas, comme lorsqu'il n'y a qu'une seule tâche dans la deque. Et il consomme plus de ressources système, comme la création de plusieurs threads et plusieurs deques.
principe de fonctionnement
- Chaque thread de travail de ForkJoinPool gère une file d'attente de travail (WorkQueue), qui est un deque, et l'objet qui y est stocké est une tâche (ForkJoinTask).
- Lorsque chaque thread de travail génère une nouvelle tâche pendant l'opération (généralement parce que fork () est appelé), il est placé en haut de la file d'attente de travail et le thread de travail utilise la méthode LIFO lors du traitement de sa propre file d'attente de travail, c'est-à-dire Dites chaque fois qu'une tâche est retirée du haut pour être exécutée.
- Lors du traitement de sa propre file d'attente de travail, chaque thread de travail essaiera de voler une tâche (soit de la tâche qui vient d'être soumise au pool, soit de la file d'attente de travail d'autres threads de travail), et la tâche volée se trouve dans la file d'attente de travail des autres threads Le chef de l'équipe, ce qui signifie que le thread de travail utilise la méthode FIFO pour voler les tâches d'autres threads de travail.
- Lorsque vous rencontrez join (), si la tâche à rejoindre n'est pas terminée, les autres tâches seront traitées en premier et attendront qu'elle se termine.
- Lorsqu'il n'y a ni sa propre tâche ni une tâche à voler, il s'endort.
ForkJoinPool
ForkJoinPool est un pool d'exécution utilisé pour exécuter des tâches ForkJoinTask. Il ne s'agit plus d'une combinaison du pool d'exécution traditionnel Worker + Queue, mais maintient un tableau de files d'attente WorkQueue (WorkQueue []), ce qui réduit considérablement le temps de soumission des tâches et des tâches de thread. collision.
WorkQueue
- WorkQueue est une liste bidirectionnelle, utilisée pour l'exécution ordonnée des tâches. Si WorkQueue est utilisé pour son propre thread d'exécution Thread, le thread sélectionnera les tâches de la fin pour exécuter LIFO par défaut.
- Chaque ForkJoinWorkThread a sa propre WorkQueue, mais pas chaque WorkQueue a un ForkJoinWorkThread correspondant.
- ForkJoinWorkThread WorkQueue aucune préservation n'est la soumission, la soumission de l'extérieur, l'indice WorkQueue [] est un nombre pair de bits.
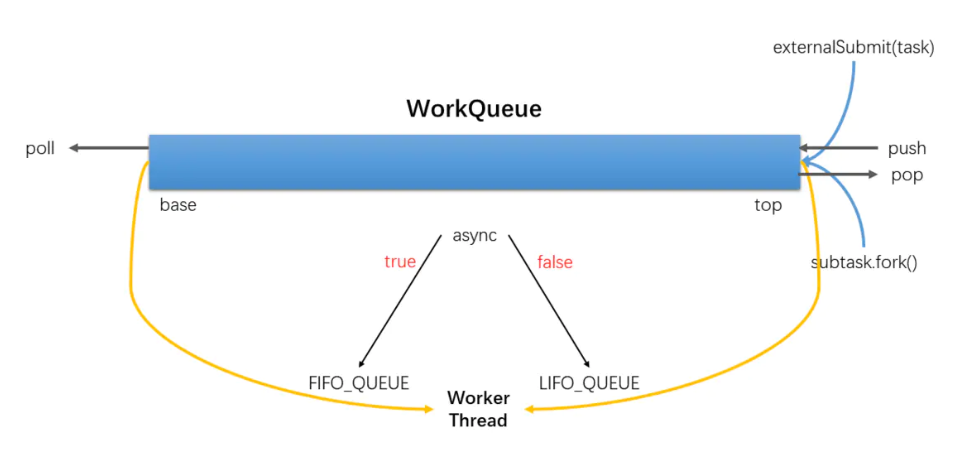
FourchetteJointTravail
ForkJoinWorkThread est un thread utilisé pour exécuter des tâches. Il est utilisé pour distinguer l'utilisation de threads non ForkJoinWorkThread pour soumettre des tâches. Le démarrage d'un thread, est automatiquement enregistré dans un pool WorkQueue, fait apparaître Thread of WorkQueue uniquement dans WorkQueue [] de bits impairs .
ForkJoinTask
ForkJoinTask est une tâche. Il est plus léger que les tâches traditionnelles et n'est plus une sous-classe de Runnable. Il fournit des méthodes Fork / Join pour diviser les tâches et agréger les résultats.
méthode de la fourche
fork()Le seul travail effectué est de pousser la tâche dans la file d'attente de travail du thread de travail actuel.
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
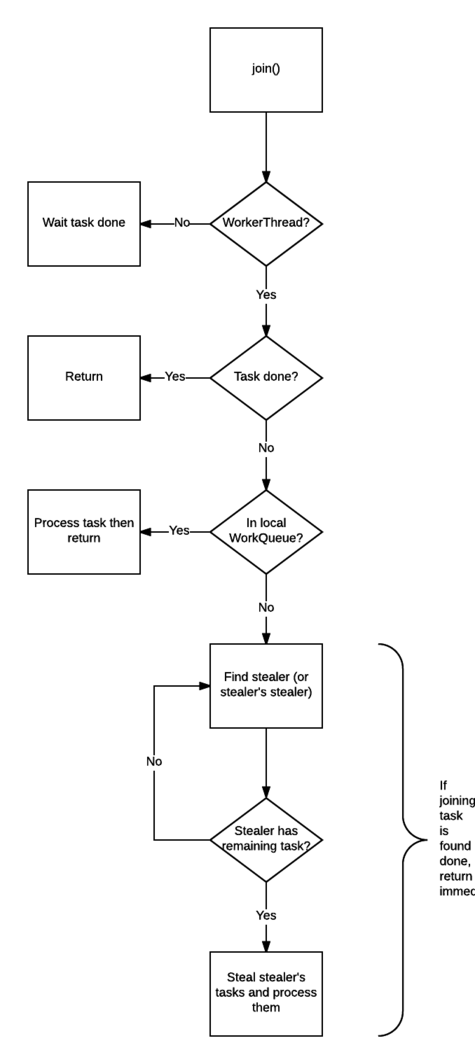
méthode de jointure
join() Le travail de est beaucoup plus compliqué, c'est pourquoi il peut empêcher le blocage des threads.
Vérifiez l'appel join()si le thread est un thread ForkJoinThread. Si ce n'est pas le cas (comme le thread principal), bloquez le thread en cours et attendez que la tâche se termine. Si c'est le cas, cela ne bloque pas.
Vérifiez l'état d'achèvement de la tâche, si elle est terminée, renvoyez directement le résultat.
Si la tâche n'est pas terminée mais se trouve dans sa propre file d'attente de travail, terminez-la.
Si la tâche a été volée par d'autres threads de travail, volez la tâche dans la file d'attente de travail du voleur (en mode FIFO) et exécutez-la afin de l'aider à terminer la tâche de pré-jointure dès que possible.
Si le voleur qui a volé la tâche a terminé toutes ses tâches et attend la tâche qui nécessite Rejoindre, trouvez le voleur du voleur et aidez-le à accomplir sa tâche.
Exécutez l'étape 5 de manière récursive.
Outre les files d'attente de travail appartenant à chaque thread de travail, ForkJoinPool possède également des files d'attente de travail. La fonction de ces files d'attente de travail est de recevoir des tâches soumises par des threads externes (et non des threads ForkJoinThread). Ces files d'attente de travail sont appelées Pour soumettre la file d'attente.
submit()Et fork()en fait, il n'y a pas de différence essentielle, mais la validation est devenue une file d'attente de soumission uniquement (et une opération de synchronisation est lancée). La file d'attente de soumission, comme les autres files d'attente de travail, est l'objet "volé" par le thread de travail. Par conséquent, lorsqu'une tâche qu'elle contient est volée avec succès par un thread de travail, cela signifie que la tâche soumise commence réellement à entrer en phase d'exécution.
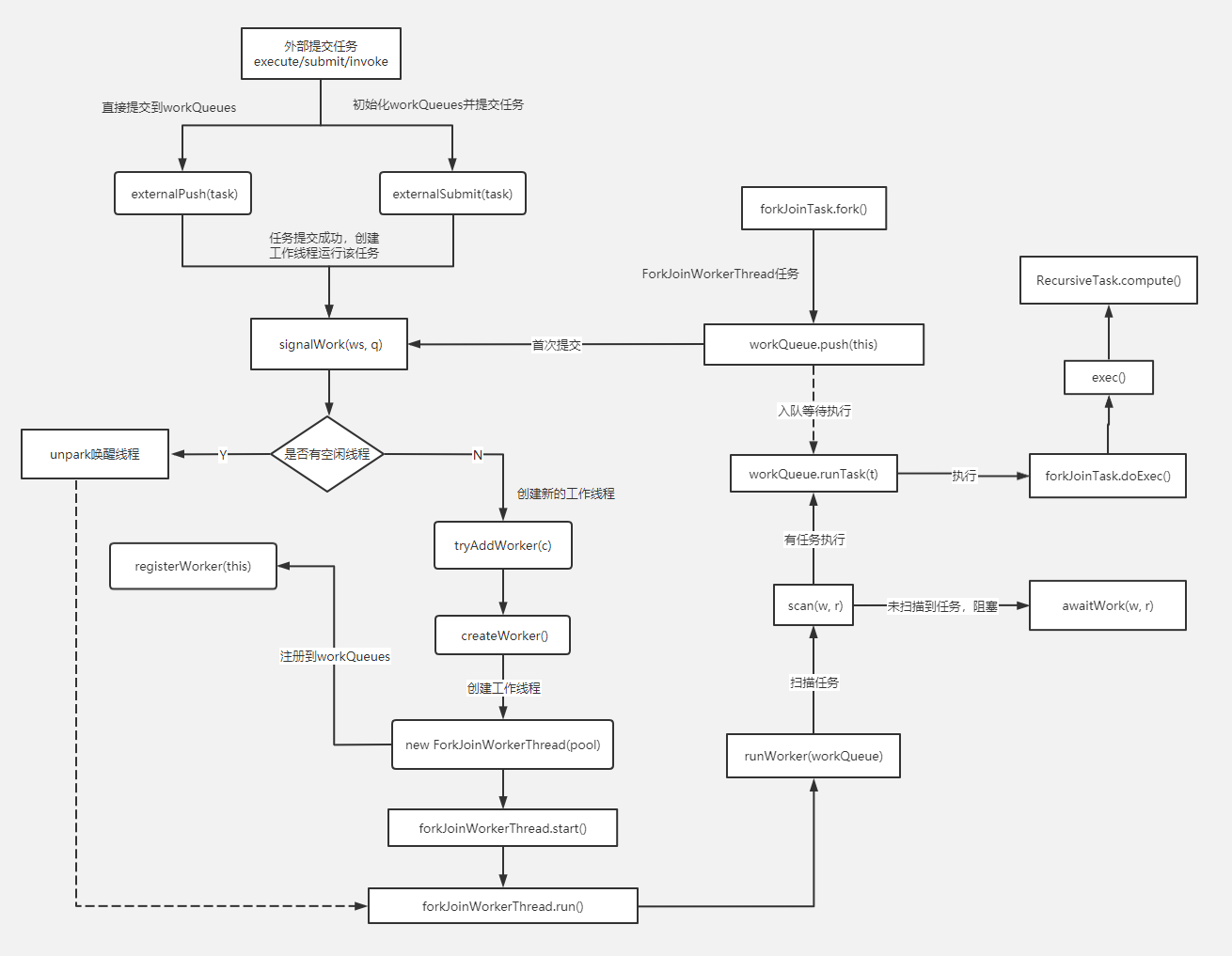
Schéma de ForkJoin