En C ++, les variables de pointeur sont utilisées pour stocker les adresses mémoire. C ++ nécessite l'utilisation de types spécifiques pour définir des pointeurs. Ce type est utilisé pour indiquer comment interpréter les données dans l'adresse mémoire. Nous savons déjà qu'à l'intérieur de l'ordinateur, la mémoire stocke 1 et 0, et le type de variable C ++ indiquera au compilateur comment interpréter ces bits de données dans le code qu'il génère. Dans le même temps, étant donné que les variables de pointeur sont utilisées pour stocker les adresses mémoire, toutes les variables de pointeur nécessitent le même espace mémoire (4 octets sur un système 32 bits). C'est un peu comme une citation en Python. Le pointeur C ++ est un concept similaire à la référence de Python. La différence entre eux est la suivante: en utilisant des pointeurs C ++, vous pouvez accéder à l'adresse pointée par le pointeur et les données (c'est-à-dire les données à cette adresse mémoire); tandis que les références Python ne peuvent vous permettre d'accéder qu'aux données pointées par la référence.
Les pointeurs C ++ sont déclarés en utilisant un astérisque (*) comme préfixe du nom de variable. L'ajout d'un astérisque signifie que cette variable contiendra l'adresse mémoire où le type de valeur de données spécifié sera stocké. Lorsque vous souhaitez déclarer plusieurs pointeurs dans une instruction de définition, une erreur courante consiste à oublier d'ajouter un astérisque avant chaque nom de variable. Dans l'exemple suivant, b et c seront déclarés en tant que pointeurs vers le type int, et d sera déclaré comme type int. La deuxième ligne de cet extrait de code est également légale, mais nous ne vous recommandons pas d'utiliser ce style. Mettre un astérisque après le mot int donnera l'impression que toutes les variables qu'elle contient sont des pointeurs vers le type int, mais en fait, seul e est un pointeur et f est un type int. Étant donné que le type int et le type pointeur nécessitent 4 octets, un total de 20 octets sera alloué dans cet exemple.
int *b, *c, d; // b and c are pointers to an int, d is an int
int* e, f; // only e is a pointer to an int, f is an intLa question suivante à laquelle vous devriez réfléchir est de savoir comment stocker les adresses dans des variables de pointeur. Nous ne savons pas quelles adresses mémoire notre programme est autorisé à utiliser, nous devons donc demander une adresse valide. Une façon consiste à utiliser l'adresse d'une variable existante. L'exemple suivant montre cette méthode, et cet exemple nous montre également comment accéder aux données pointées par la variable pointeur:
// p1.cpp
#include <iostream>using namespace std;int main(){ int *b, *c, x, y; x = 3;
y = 5;
b = &x; c = &y; *b = 4;
*c = *b + *c; cout << x << " " << y << " " << *b << " " << *c << " ";
c = b; *c = 2;
cout << x << " " << y << " " << *b << " " << *c << endl;
return 0;
}Le symbole & opérateur unaire calculera l'adresse de son opérande correspondant. Par conséquent, l'instruction b = & x amènera le programme à stocker l'adresse mémoire de x dans la mémoire de la variable b. Le tableau 10.7 montre que l'ordinateur utilise des adresses mémoire de 1 000 à 1 015 pour stocker nos variables et montre également la valeur de chaque variable après l'exécution de l'instruction c = & y. Comme auparavant, l'ordinateur n'utilise pas nécessairement des adresses à partir de 1 000, mais dans les exemples de ce livre, nous utiliserons cette adresse.
Tableau 10.7 Situation de la mémoire C ++ après l'exécution de l'instruction c = & y

Un symbole d'opérateur yuan *, il est utilisé comme un déréférencement de pointeur (déréférencement). Déréférencer un pointeur fait référence à l'accès aux données à l'adresse mémoire stockée par le pointeur. L'instruction * b = 4 amènera le programme à stocker la valeur de données 4 dans l'adresse mémoire 1 008 (car la valeur actuelle de b est 1 008). Avant de lire le paragraphe suivant, voyez si vous pouvez déterminer la sortie de cet exemple de programme sur la base de ces connaissances.
L'instruction * c = * b + * c obtiendra la valeur entière de l'adresse mémoire 1 008 (l'adresse pointée par b) et l'adresse mémoire 1 012 (l'adresse pointée par c), et additionnera 4 et 5 ensemble. Après cela, le résultat 9 sera stocké à l'adresse mémoire 1 012 (l'adresse pointée par c). L'instruction c = b copiera la valeur de données de b (adresse 1 008) dans la mémoire de c (c'est-à-dire que 1 008 sera stocké dans l'adresse mémoire 1 004). Ce que vous devez noter, c'est que l'attribution d'une variable de pointeur est fondamentalement la même chose que l'attribution de deux noms en Python; b et c pointent maintenant tous les deux vers les mêmes données. Grâce aux connaissances de cette partie du paragraphe, vous devriez être en mesure de savoir que le résultat de ce programme sera 4 9 4 9 2 9 2 2. Après avoir exécuté l'instruction * c = 2, les changements de mémoire sont indiqués dans le tableau 10.8.
Tableau 10.8 Situation de la mémoire C ++ après l'exécution de l'instruction * c = 2

Un autre concept important que vous avez peut-être découvert que vous devez comprendre est qu'un pointeur vers un type int et un type int ne sont pas du même type. Si vous continuez à utiliser la déclaration de variable de l'exemple précédent, les instructions b = x et x = b sont toutes deux illégales. Étant donné que la variable b est un pointeur, la valeur de l'adresse doit lui être affectée et x est un type int, de sorte qu'il ne peut être attribué qu'une valeur entière. Si nous utilisons un autre type (tel que double) pour déclarer des variables de pointeur, ce phénomène sera plus évident, car dans les systèmes 32 bits, ils utilisent différentes quantités de mémoire. Quel que soit le type, le pointeur vers ce type et le type réel ne sont pas des types de données compatibles.
Nous allons maintenant écrire un exemple plus pratique pour montrer l'opérateur d'adressage et l'opérateur de déréférencement. Le langage C ne prend pas en charge le passage par référence comme le langage C ++, donc lorsque vous utilisez le langage C, le seul moyen de modifier les paramètres réels est d'utiliser des pointeurs. La méthode technique correspondante consiste à transmettre l'adresse du paramètre réel, puis à laisser la fonction ou la méthode déréférencer ce pointeur, de sorte que la valeur à l'adresse mémoire correspondant au paramètre formel puisse être modifiée. Vous pouvez également effectuer cette opération en C ++, mais les programmeurs utilisent généralement le passage par référence pour ce faire. L'exemple suivant montre la fonction swap pour permuter deux variables entières:
// swap.cpp
#include <iostream>
using namespace std;void swap(int *b, int *c)
{ int temp = *b;
*b = *c;
*c = temp;
}int main(){ int x = 3, y = 5; swap(&x, &y); cout << x << " " << y << endl;
return 0;
}Les paramètres formels b et c transmettent respectivement les adresses mémoire des variables x et y. Par conséquent, l'instruction d'affectation * b = * c équivaut à écrire x = y directement dans la fonction principale. Vous pouvez voir les similitudes entre les deux et le passage par référence. Que se passe-t-il si nous ajoutons la ligne b = & temp à la fin de la fonction d'échange? Cela changera-t-il x? En fait, cette instruction n'aura aucun effet sur x. La variable b sera modifiée pour enregistrer l'adresse de la variable temp, mais cela ne modifiera pas la variable x ou la valeur de l'adresse mémoire correspondant à la variable x.
Dans nos exemples, nous utilisons le symbole unaire & opérateur pour attribuer une adresse valide à la variable pointeur. Une autre façon de définir le pointeur pour qu'il pointe vers une adresse valide est la nouvelle instruction. La nouvelle instruction C ++ est utilisée pour allouer un morceau de mémoire dynamique à partir du tas et renvoyer l'adresse de départ de la mémoire allouée. Lorsque vous utilisez la nouvelle instruction, vous devez spécifier le type de données de l'objet que vous souhaitez allouer. Cela est dû au fait que le type de données spécifié sera utilisé pour déterminer la quantité de mémoire à allouer. Une fois que la mémoire est explicitement allouée en C ++, elle doit être libérée lorsque la mémoire n'est plus nécessaire. L'instruction delete sera utilisée pour libérer cette mémoire allouée dynamiquement. L'exemple suivant montre la version dynamique du tas explicite des programmes Python et C ++ écrits dans la section 10.1:
// p2.cpp
#include <iostream>using namespace std;int main(){ int *x, *y, *z; x = new int; *x = 3;
y = new int; *y = 4;
z = x; x = y; cout << *x << " " << *y << " " << *z << endl;
delete z; delete y; return 0;
}Les variables de pointeur x, y et z sont toutes des variables dynamiques de pile. Les 12 octets dont elles ont besoin sont automatiquement allouées au début de la fonction, puis libérées à la fin de la fonction. Nous avons utilisé des adresses mémoire de 1 000 à 1 011 pour représenter ces 12 octets, comme indiqué dans le tableau 10.9. Lorsque la nouvelle instruction est exécutée, de la mémoire est allouée dans le tas de mémoire dynamique dont l'adresse mémoire commence à 2 000. Il est à noter que dans ce code, il y a deux nouvelles instructions, nous devons donc avoir deux instructions delete correspondant à cela. Bien que nous n'ayons pas utilisé le même nom de variable lors de l'utilisation des instructions new et delete, la mémoire allouée par l'instruction x = new int sera libérée par l'instruction delete z, car z enregistre la nouvelle instruction allouée Adresse mémoire. De même, l'instruction delete y libère la mémoire allouée par l'instruction y = new int. À ce stade, nous pouvons en fait utiliser l'instruction delete x au lieu de l'instruction delete y pour libérer la mémoire, car l'instruction x = y oblige x et y à stocker la même adresse mémoire. Le point clé à retenir ici est que chaque nouvelle instruction exécutée doit avoir une instruction de suppression qui lui correspond. Cette instruction sera utilisée pour libérer la mémoire allouée par la nouvelle instruction. Si vous oubliez l'instruction de suppression, le programme aura une fuite de mémoire (fuite de mémoire). Bien qu'un programme avec une fuite de mémoire puisse ne pas se bloquer, un tel code n'est généralement pas considéré comme correct.
Tableau 10.9 Situation de la mémoire après l'exécution de la nouvelle instruction
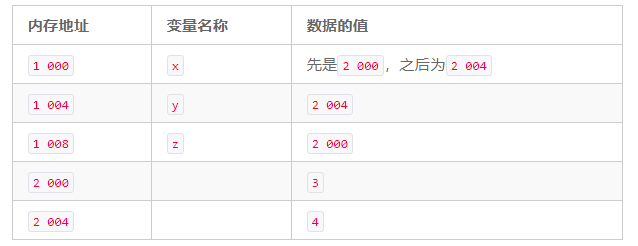
De manière générale, vous écrirez ce programme comme nous l'avons fait dans la section 10.1, car cela est plus efficace. De plus, cette version du code qui utilise des pointeurs nécessite plus de mémoire, et lors du déréférencement des pointeurs, l'ordinateur doit accéder à deux adresses mémoire (cout << * x doit d'abord accéder à l'adresse mémoire 1000, puis accéder à la mémoire Adresse 2 004). Cette version C ++ du code est similaire à la version Python dans l'allocation de mémoire. Par conséquent, vous pouvez comparer le tableau des indicateurs de mémoire de cette version du code avec le graphique de mémoire de la figure 10.1. Dans le même temps, cet exemple montre également que les références Python et les pointeurs C ++ sont essentiellement des syntaxes différentes du même concept.
Puisque Python n'utilise que des références, il n'a pas besoin d'avoir une syntaxe supplémentaire pour le déréférencement comme les pointeurs en C ++. Après avoir affecté une variable de pointeur à une autre variable de pointeur en C ++, ils pointeront tous vers la même valeur ou le même objet. En utilisant des pointeurs, nous pouvons utiliser la même façon d'allouer de la mémoire en C ++ qu'en Python pour implémenter l'exemple de classe Rational au début de ce chapitre.
Cependant, lors de l'utilisation de pointeurs, il y a un problème lors de l'accès aux membres d'instance de la classe: l'opérateur point (point) a une priorité plus élevée que l'opérateur astérisque (symbole unaire *) utilisé pour le déréférencement. Cela signifie que si nous avons une instance r de la classe Rational, nous ne pouvons pas écrire de code comme * r1.set (2,3) ;, nous devrions l'écrire comme (* r1) .set (2,3) Une telle forme. Heureusement, C ++ fournit également un opérateur supplémentaire qui nous permet d'utiliser des pointeurs sans ajouter de parenthèses pour accéder aux membres. Ce symbole est -> (un signe moins suivi d'un signe supérieur à), donc (* r1) .set (2,3) peut être écrit comme r1-> set (2,3). De manière générale, nous utiliserons le formulaire -> pour écrire du code au lieu de la version entre parenthèses.
Le code utilisant des pointeurs C ++ correspondant à la version Python de la classe Rational plus haut dans ce chapitre est le suivant:
Rational *r1, *r2; // constructors not called
r1 = new Rational; // constructor is called
r1->set(2, 3);
r2 = r1;r1->set(1, 3);
cout << *r1 << endl;cout << *r2 << endl;delete r1;Comme r1 et r2 sont des pointeurs vers la même adresse mémoire, le résultat de cet exemple de programme est de sortir à la fois r1 et r2 comme 1/3. L'état de la mémoire de ce fragment de code est indiqué dans le tableau 10.10.
Tableau 10.10 Situation de la mémoire après l'exécution de code C ++ à l'aide de pointeurs C ++
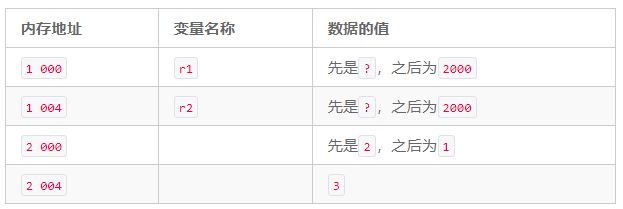
Lors de la déclaration de r1 et r2, 4 octets sont alloués pour chaque variable, car le pointeur nécessite 4 octets. De plus, lors de la déclaration d'un pointeur, le constructeur de la classe Rational ne sera pas appelé, car nous créons uniquement un pointeur et non un objet Rational. Par conséquent, l'instruction r1 = new Rational entraînera l'allocation de 8 octets, car cette instance a deux variables d'instance entières num_ et den_, et elles nécessitent 8 octets au total. L'instruction r1 = new Rational stockera également la variable r1 dans l'adresse mémoire 2000. Alors que l'instruction r1 = new Rational est exécutée, car elle crée un objet Rational, le constructeur est également appelé. Ensuite, l'instruction r1-> set (2,3) stockera 2 à l'adresse mémoire 2000, et en conséquence 3 seront stockées à l'adresse mémoire 2004.
L'instruction suivante de r2 = r1, puisque la valeur de r1 est 2000, stockera 2000 à l'adresse mémoire 1004. Par conséquent, il a maintenant la même structure de mémoire que l'exemple Python, c'est-à-dire que r1 et r2 pointent tous les deux vers le même objet Rational. Ensuite, lorsque nous exécutons l'instruction r1-> set (1,2), nous ne changerons pas la valeur de r1, mais modifierons l'objet stocké dans l'adresse mémoire pointée par r1. Puisque r2 pointe vers le même objet que r1, nous pouvons obtenir le même résultat que Python. Lorsque l'exécution de la fonction contenant un tel extrait de code C ++ se termine, l'adresse mémoire de la variable déclarée (1000-1007) sera automatiquement libérée comme mentionné précédemment, mais nous avons également besoin de l'instruction delete r1 pour publier la nouvelle instruction Rational Adresse mémoire allouée explicitement (2000 ~ 2007). Parce que les deux pointeurs r1 et r2 pointent tous deux vers la même adresse, nous pouvons également utiliser delete r2 pour libérer la mémoire, mais nous ne pouvons pas écrire delete r1; supprimer r2 comme ceci, car pour chaque nouvelle instruction, il doit y avoir et Il n'y a qu'une seule instruction de suppression correspondante. Essayer de libérer à nouveau la mémoire à la même adresse mémoire peut détruire le tas de mémoire dynamique et provoquer le blocage du programme.
En C ++, l'utilisation de pointeurs avec mémoire dynamique peut vous offrir la même flexibilité que les références Python, mais comme vous devez être responsable de la gestion explicite de l'allocation et de la libération de la mémoire, c'est mieux que la version Python qui exécute la même fonction Le code est plus difficile. Si vous êtes imprudent lors de l'utilisation de la mémoire dynamique, chaque exécution du programme produira des résultats différents, et peut même planter l'ensemble. Nous aborderons ces problèmes de mémoire dynamique de tas explicite dans ce chapitre.
Cet article est extrait de: "Structure des données et algorithme (description du langage Python et C ++)"

Ce livre utilise deux langages de programmation, Python et C ++, pour introduire les structures de données. Le livre contient 15 chapitres. Le livre présente d'abord les principes de base et la connaissance des structures de données telles que l'abstraction et l'analyse, l'abstraction de données, puis combine les caractéristiques de Python pour introduire des classes de conteneurs, des structures de chaîne et des itérateurs, des piles et des files d'attente, la récursivité et les arbres; puis, une brève introduction J'ai appris la connaissance du langage C ++ et expliqué plus en détail les classes C ++, la mémoire dynamique C ++, la structure de la chaîne C ++, le modèle C ++, le tas, l'arbre équilibré et la table de hachage, les graphiques, etc. Enfin, la technologie de l'algorithme a été résumée. À la fin de chaque chapitre, des exercices et des exercices de programmation sont donnés pour aider les lecteurs à revoir et à consolider ce qu'ils ont appris.
Ce livre convient comme manuel et ouvrage de référence pour les cours de structure de données professionnels liés à l'informatique dans les collèges et les universités, et convient également aux lecteurs intéressés par la structure de données.