Méthode commune
df = pd.read_excel()
df = pd.read_csv()
df.to_csv()
df.to_excel()
entête
L'en-tête par défaut est 0, ce qui signifie que la première ligne est l'en-tête. Si l'en-tête est défini sur Aucun, cela signifie qu'il n'y a pas d'en-tête.
L'en-tête peut également être un autre entier n, ce qui signifie que la ligne n + 1 est l'en-tête et que les données des n premières lignes ne seront pas lues
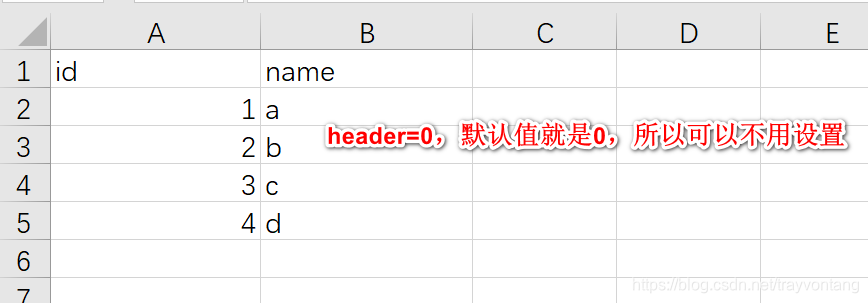
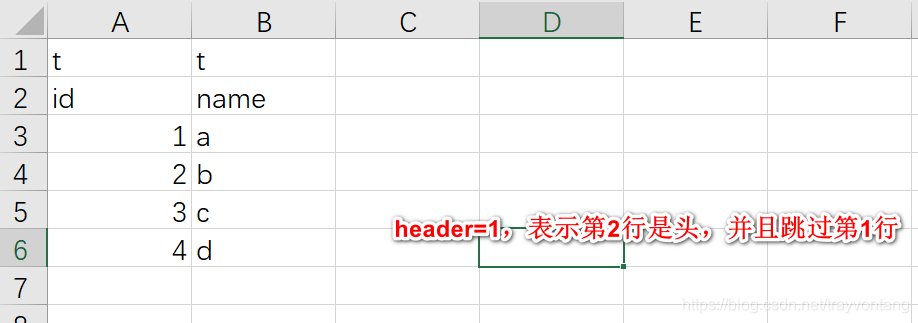

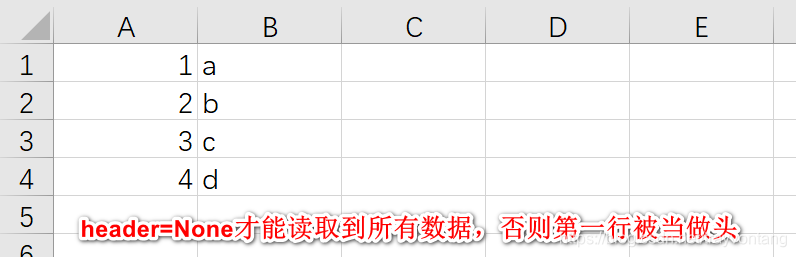
utiliser
Quelles colonnes doivent être sélectionnées, la valeur par défaut est Aucune
- Aucun, lire toutes les colonnes
- int, lisez les premières colonnes
- list, int list, signifie lire les colonnes de cette liste
- chaîne, lue par excel, par exemple: "A: F" signifie colonne A à F, "A, D, E: H" signifie colonne A et D et E à H
des noms
Renommer la colonne de lecture
Vous pouvez également renommer après avoir lu les données:
df = pd.read_csv('data.csv')
df.columns = ['A','B','C']
ou:
df = pd.read_csv('data.csv')
df.rename(columns = {
'A':'AN','B':'BN','C':'CN'})
Autres paramètres couramment utilisés pour la lecture de fichiers
sheet_name: lire la feuille avec le nom spécifié lors de la lecture d'Excel, ou index, par défaut 0
index_col: spécifier la colonne d'index, int type
nrows: lire quelles lignes
skiprows: ignorer quelles lignes
keep_default_na: s'il faut conserver la valeur vide, le True
dtype par défaut : Définissez le type de colonne, par exemple, {'a': np.float64, 'b': np.int32}
Paramètres communs pour l'écriture de fichiers
float_format: écrivez le format des nombres à virgule flottante,
colonnes '%. 0f' : nom de colonne en-
tête: s'il faut afficher l'en-tête, la valeur par défaut est True
index: s'il faut sortir l'index, la valeur par défaut est True
Pour les fichiers csv, vous pouvez également définir:
sep: set separator, default ","
mode: set write mode, default "w"
Pour Excel, vous pouvez également définir:
nom_feuille: nom de la feuille, par défaut "Sheet1"