- 1. Les concepts de base et la classification du tri
- Stabilité de tri:
- Tri interne et externe
- Trois facteurs qui affectent les performances de l'algorithme de tri interne:
- Selon les principales opérations utilisées dans le processus de tri, le tri interne peut être divisé en:
- Selon la complexité de l'algorithme, il peut être divisé en deux catégories:
- 2. Tri des bulles BubbleSort
- 3. Tri de la sélection SelectionSort
- 4. Insérer le tri InsertionSort
- 5. Hill Sort ShellSort
- 6. Tri par fusion MergeSort
- 7. Tri rapide
- 8. HeapSort
- Comparaison des performances de sept algorithmes de tri
1. Les concepts de base et la classification du tri
Le tri dit consiste à faire une série d'enregistrements, selon la taille d'un ou de certains mots-clés, l'opération d'augmentation ou de diminution. L'algorithme de tri consiste à organiser les enregistrements conformément aux exigences.
Stabilité de tri:
Après un certain tri, si les deux enregistrements ont le même numéro de série et que l'ordre des deux enregistrements dans les enregistrements non ordonnés d'origine reste inchangé, la méthode de tri utilisée est dite stable, sinon elle est instable.
Tri interne et externe
Tri interne: lors du tri, tous les enregistrements à trier sont placés en mémoire
Tri externe: lors du tri, un stockage externe est utilisé.
Habituellement, la discussion est en cours de tri.
Trois facteurs qui affectent les performances de l'algorithme de tri interne:
- Complexité temporelle: c'est-à-dire performances temporelles, l'algorithme de tri efficace doit avoir le moins de comparaisons de mots clés et de mouvements enregistrés possible
- Complexité de l'espace: principalement l'espace auxiliaire requis pour exécuter l'algorithme, moins il est meilleur.
- Complexité de l'algorithme. Se réfère principalement à la complexité du code.
Selon les principales opérations utilisées dans le processus de tri, le tri interne peut être divisé en:
- Insérer un tri
- Ordre d'échange
- Sélectionnez le tri
- Tri par fusion
Selon la complexité de l'algorithme, il peut être divisé en deux catégories:
- Algorithme simple: tri des bulles, tri par sélection simple et tri par insertion directe
- Algorithme amélioré: y compris le tri Hill, le tri en tas, le tri par fusion et le tri rapide
Les sept algorithmes de tri suivants ne sont que les plus classiques parmi tous les algorithmes de tri, mais pas tous.
2. Tri des bulles BubbleSort
Présentation:
Le principe du tri à bulles est très simple: il visite à plusieurs reprises la séquence à trier, compare deux éléments à la fois et les échange si leur ordre est erroné.
Étapes:
- Comparez les éléments adjacents. Si le premier est plus grand que le second, échangez-les tous les deux.
- Faites de même pour les données 0 à n-1. À ce moment, le plus grand nombre "flotte" à la dernière position du tableau.
- Répétez les étapes ci-dessus pour tous les éléments sauf le dernier.
- Continuez à répéter les étapes ci-dessus pour de moins en moins d'éléments à chaque fois jusqu'à ce qu'il n'y ait plus de paires de nombres à comparer.
Implémentation de Python
def bubble_sort(arr): n = len(arr) # 遍历所有数组元素 for i in range(n): for j in range(0, n - i - 1): if arr[j] > arr[j + 1]: #如果前者比后者大 arr[j], arr[j + 1] = arr[j + 1], arr[j] #则交换两者 return print(arr)arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
3. Tri de la sélection SelectionSort
Présentation:
Le tri par sélection est sans aucun doute le tri le plus simple et le plus intuitif. Cela fonctionne comme suit.
Étapes:
- Recherchez le plus petit (grand) élément dans la séquence non triée et stockez-le au début de la séquence triée.
- Continuez ensuite à rechercher le plus petit (grand) élément parmi les éléments non triés restants, puis placez-le à la fin de la séquence triée.
- Et ainsi de suite, jusqu'à ce que tous les éléments soient triés.
Implémentation de Python
def select_sort(arr): n = len(arr) for i in range(n): min = i # 最小元素下标标记 for j in range(i + 1, n): if arr[j] < arr[min]: min = j # 找到最小值的下标 arr[min], arr[i] = arr[i], arr[min] # 交换两者 return print(arr)
arr = [64, 34, 25, 12, 22, 11, 90]
select_sort(arr)
4. Insérer le tri InsertionSort
Présentation:
Le principe de fonctionnement du tri par insertion est que pour chaque donnée non triée, elle balaye de l'arrière vers l'avant dans la séquence triée, trouve la position correspondante et insère.
Étapes:
- A partir du premier élément, l'élément peut être considéré comme trié
- Prenez l'élément suivant et scannez d'arrière en avant dans la séquence d'éléments triés
- Si l'élément analysé (trié) est plus grand que le nouvel élément, reculez l'élément d'un bit
- Répétez l'étape 3 jusqu'à ce que vous trouviez la position de l'élément trié inférieure ou égale au nouvel élément
- Après avoir inséré le nouvel élément à cette position
- Répétez les étapes 2 à 5
Démo de tri:
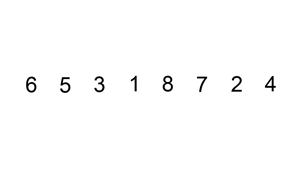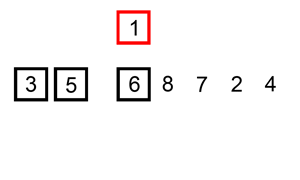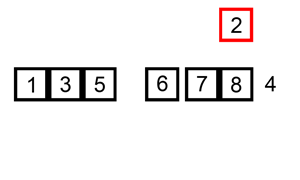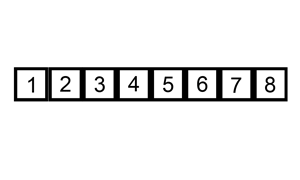
Implémentation de Python
def inset_sort(arr): n = len(arr) for i in range(1,n): if arr[i] < arr[i-1]: temp = arr[i] index = i # 待插入的下标 for j in range(i-1,-1,-1): # 从i-1 循环到 0 包括0 if arr[j] > temp: arr[j+1] = arr[j] index = j # 记录待插入的下标 else: break arr[index] = temp return print(arr)
arr = [64, 34, 25, 12, 22, 11, 90]
inset_sort(arr)
5. Hill Sort ShellSort
Présentation:
Le tri en côte, également appelé algorithme de tri incrémentiel décroissant , regroupe essentiellement le tri par insertion. Proposé par Donald Shell en 1959. Le tri en côte est un algorithme de tri instable.
L'idée de base du tri Hill est de répertorier le tableau dans un tableau et d'insérer et de trier les colonnes séparément. Répétez ce processus, mais à chaque fois avec une colonne plus longue (la longueur de l'étape est plus longue, le nombre de colonnes est moins) . Enfin, la table entière n'a qu'une seule colonne. La conversion du tableau en tableau vise à mieux comprendre l'algorithme, l'algorithme lui-même utilise toujours le tableau pour trier.
Par exemple, supposons qu'il existe un tel ensemble de nombres [ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ], si nous commençons à trier avec une taille de pas de 5, nous pouvons mieux décrire l'algorithme en plaçant cette liste dans un tableau à 5 colonnes, ils devraient donc ressembler à ceci:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
Ensuite, nous trions chaque colonne:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
Lorsque les quatre lignes de chiffres ci - dessus, on se rassemble dans l' ordre: [ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ]. À ce stade, 10 a été déplacé vers la position correcte, puis trié par étapes de 3:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
Après le tri, il devient:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
Enfin, triez par étape (il s'agit d'un simple tri par insertion).
Implémentation de Python
def shell_sort(ary): n = len(ary) gap = round(n/2) #初始步长 , 用round四舍五入取整 while gap > 0 : for i in range(gap,n): #每一列进行插入排序 , 从gap 到 n-1 temp = ary[i] j = i while ( j >= gap and ary[j-gap] > temp ): #插入排序 ary[j] = ary[j-gap] j = j - gap ary[j] = temp gap = round(gap/2) #重新设置步长 return print(ary) ary = [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10] shell_sort(ary)
6. Tri par fusion MergeSort
Présentation:
Le tri par fusion est une application très typique de la méthode diviser pour régner. 归并L'idée du tri consiste à 递归décomposer le tableau en premier , puis à 合fusionner le tableau.
Envisagez d'abord de fusionner deux tableaux ordonnés. L'idée de base est de comparer le premier nombre des deux tableaux. Celui qui est plus jeune prendra le premier, et après l'avoir pris, le pointeur correspondant reculera d'un bit. Comparez ensuite jusqu'à ce qu'un tableau soit vide, puis copiez le reste de l'autre tableau.
En considérant la décomposition récursive, l'idée de base est de décomposer le tableau en une leftsomme right. Si les données internes de ces deux tableaux sont ordonnées, alors les deux tableaux peuvent être combinés et triés en utilisant la méthode ci-dessus de fusion de tableaux. Comment rendre ces deux tableaux ordonnés en interne? Il peut être à nouveau divisé en deux jusqu'à ce que le groupe décomposé ne contienne qu'un seul élément. Pour l'instant, on considère qu'il y a de l'ordre au sein du groupe. Ensuite, vous pouvez fusionner et trier les deux groupes adjacents.
Démo de tri:
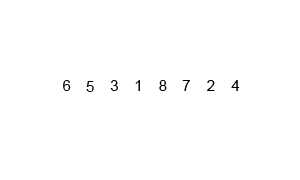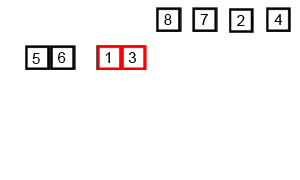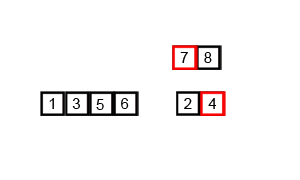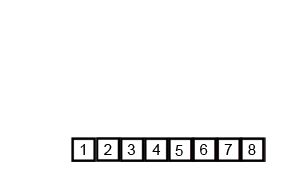
Implémentation de Python
def merge_sort(ary): if len(ary) <= 1: return ary num = int(len(ary) / 2) # 二分分解 left = merge_sort(ary[:num]) right = merge_sort(ary[num:]) return merge(left, right) # 合并数组def merge(left, right):
'''合并操作,
将两个有序数组left[]和right[]合并成一个大的有序数组
'''
l, r = 0, 0 # left与right数组的下标指针
result = []
while l < len(left) and r < len(right):
if left[l] < right[r]:
result.append(left[l])
l += 1
else:
result.append(right[r])
r += 1
result += left[l:]
result += right[r:]
return result
ary = [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10]
merge_sort(ary)
7. Tri rapide
Introduction:
Le tri rapide est généralement évidemment plus rapide que d' autres algorithmes avec le même Ο (n log n) , il est donc souvent utilisé, et le tri rapide adopte l' idée de méthode de division et de conquête , donc dans de nombreuses interviews écrites, vous pouvez souvent voir le tri rapide. Ombre. On peut voir l'importance de maîtriser un peloton rapide.
Étapes:
- Choisissez un élément de la série comme numéro de base.
- Dans le processus de partitionnement, ceux supérieurs au numéro de référence sont placés à droite et les nombres inférieurs ou égaux à celui-ci sont placés à gauche.
- Effectuez ensuite récursivement la deuxième étape sur les intervalles de gauche et de droite jusqu'à ce que chaque intervalle ait un seul numéro.
Démo de tri:
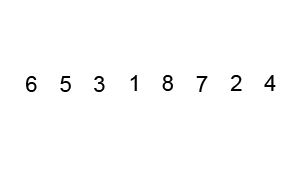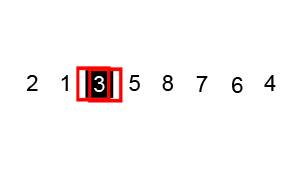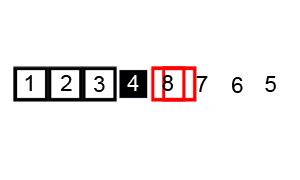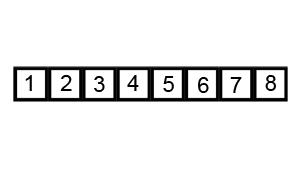
Implémentation de Python
def quick_sort(ary): return qsort(ary, 0, len(ary) - 1)def qsort(ary, left, right):
# 快排函数,ary为待排序数组,left为待排序的左边界,right为右边界
if left >= right:
return ary
key = ary[left] # 取最左边的为基准数
lp = left # 左指针
rp = right # 右指针
while lp < rp:
while ary[rp] >= key and lp < rp:
rp -= 1
while ary[lp] <= key and lp < rp:
lp += 1
ary[lp], ary[rp] = ary[rp], ary[lp]
ary[left], ary[lp] = ary[lp], ary[left]
qsort(ary, left, lp - 1)
qsort(ary, rp + 1, right)
return ary
ary = [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10]
quick_sort(ary)
def quick_sort(a, start, end):
if start < end:
i, j = start, end # 记录当前索引值
base = a[i] # 设置基准
while i < j:
while (i < j) and (a[j] >= base):
j -= 1
a[i] = a[j]
while (i < j) and (a[i] <= base):
i += 1
a[j] = a[i]
a[i] = base
quick_sort(a, start, i - 1)
quick_sort(a, j + 1, end)
return print(a)
a = [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10]
quick_sort(a, 0, len(a) - 1)
8. HeapSort
Présentation:
Le tri par segment de mémoire est fréquemment utilisé dans les principaux problèmes K. Le tri en tas est implémenté à l'aide d'une structure de données binaire fork, bien qu'il s'agisse essentiellement d'un tableau unidimensionnel. Le tas binaire est un arbre binaire approximativement complet.
Le tas binaire a les propriétés suivantes:
- La valeur de clé du nœud parent est toujours supérieure ou égale à (inférieure ou égale à) la valeur de clé de tout nœud enfant.
- Les sous-arborescences gauche et droite de chaque nœud sont un tas binaire (à la fois le plus grand tas ou le plus petit tas).
Étapes:
- Construire le segment de mémoire maximal (Build_Max_Heap): si la plage d'indices du tableau est comprise entre 0 et n, sachant qu'un seul élément est un segment de racine volumineux,
n/2les éléments à partir de l'indice sont tous de grands segments de racine. Par conséquent, tant que len/2-1gros segment racine est construit dans l'ordre depuis le début, cela peut garantir que lorsqu'un nœud est construit, ses sous-arbres gauche et droit sont déjà de grands segments racine. - Tri de tas (HeapSort): parce que le tas est simulé avec un tableau. Après avoir obtenu un grand segment racine, le tableau n'est pas ordonné. Par conséquent, la baie de disques doit être commandée. L'idée est de supprimer le nœud racine et d'effectuer l'opération récursive d'ajustement de segment de mémoire maximal. La première fois
heap[0]avec l'heap[n-1]échange, puis deheap[0...n-2]faire le réglage maximale du tas. Le second seraheap[0]l'heap[n-2]échange, puis deheap[0...n-3]faire le réglage maximale du tas. Répétez cette opération jusqu'àheap[0]etheap[1]échangez. Étant donné que le plus grand nombre est fusionné dans la plage ordonnée suivante à chaque fois, la matrice entière est ordonnée après l'opération. - Ajustement de tas max (Max_Heapify): Cette méthode est fournie pour les deux procédures ci-dessus. Le but est d'ajuster les nœuds enfants à la fin du tas afin que les nœuds enfants soient toujours plus petits que le nœud parent.
Démo de tri:

Implémentation de Python
def heap_sort(ary): n = len(ary) first = int(n / 2 - 1) # 最后一个非叶子节点 for start in range(first, -1, -1): # 构造大根堆 max_heapify(ary, start, n - 1) for end in range(n - 1, 0, -1): # 堆排,将大根堆转换成有序数组 ary[end], ary[0] = ary[0], ary[end] max_heapify(ary, 0, end - 1) return print(ary)最大堆调整:将堆的末端子节点作调整,使得子节点永远小于父节点
start为当前需要调整最大堆的位置,end为调整边界
def max_heapify(ary, start, end):
root = start
while True:
child = root * 2 + 1 # 调整节点的子节点
if child > end: break
if child + 1 <= end and ary[child] < ary[child + 1]:
child = child + 1 # 取较大的子节点
if ary[root] < ary[child]: # 较大的子节点成为父节点
ary[root], ary[child] = ary[child], ary[root] # 交换
root = child
else:
break
ary = [13, 14, 94, 33, 82, 25, 59, 94, 65, 23, 45, 27, 73, 25, 39, 10]
heap_sort(ary)
Comparaison des performances de sept algorithmes de tri
Voici une comparaison des indicateurs de sept algorithmes de tri classiques:

- Si la séquence à trier est ordonnée, utilisez directement un algorithme simple et n'utilisez pas un algorithme amélioré complexe.
- Bien que le tri par fusion et le tri rapide aient des performances élevées, ils nécessitent plus d'espace auxiliaire. En fait, c'est utiliser l'espace pour le temps.
- Moins il y a d'éléments dans la séquence à trier, plus la méthode de tri simple est appropriée; plus le nombre d'éléments est grand, plus l'algorithme de tri amélioré est approprié.
- Bien que le tri par sélection simple ne soit pas bon en termes de performances temporelles, il présente des performances élevées en termes d'utilisation de l'espace. Il est particulièrement adapté à ces types d'éléments avec une petite quantité de données et une grande quantité d'informations dans chaque élément de données.