Big Data: Hbase

- Qu'est-ce que Hbase
Hbase est une base de données NoSQL distribuée et extensible qui prend en charge le stockage massif de données, la structure de stockage de structure physique (KV).
- S'il n'y a pas d'Hbase
Comment renvoyer des centaines de millions de données en quelques secondes dans un scénario de Big Data. (Conditionnel: données uniques, données de plage)
1 Structure et type de données Hbase
- Structure logique
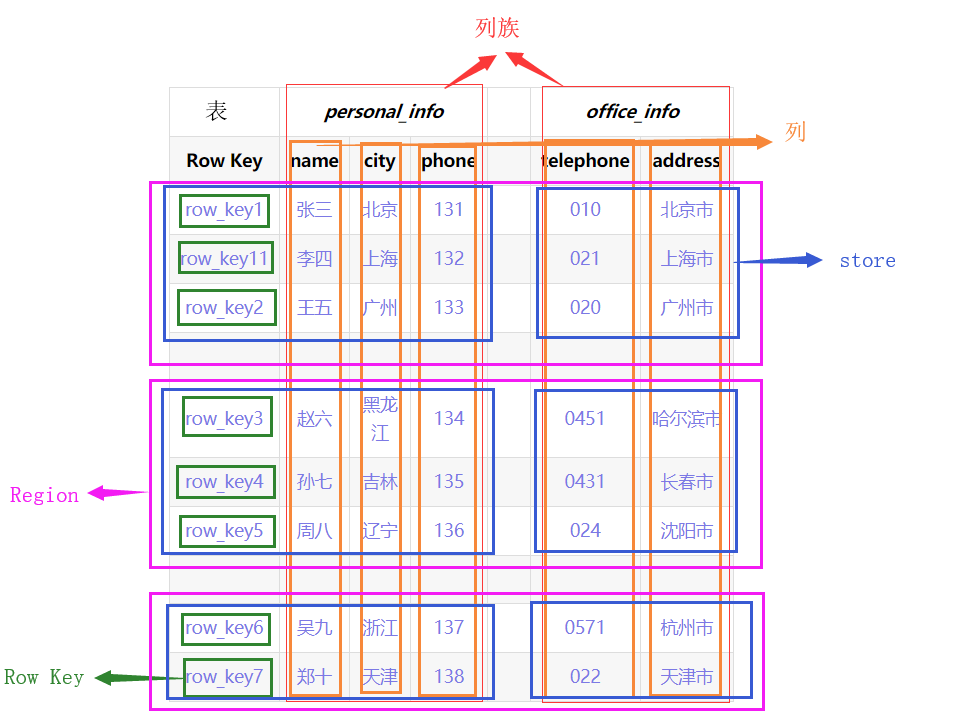
- Structure physique
La montre entière sera coupée selon la touche de ligne (région) dans le sens horizontal. Appuyez ensuite sur ColumnFamily pour couper (Store) dans le sens vertical,
-
Espace de nom: Espace de nom
- Semblable au concept de base de données dans une base de données relationnelle, plusieurs tables peuvent être placées sous chaque espace de noms, et il y a deux espaces de noms par défaut: hbase et par défaut. Hbase stocke les tables intégrées de Hbase. La table par défaut est l'espace de noms par défaut utilisé par les utilisateurs. (Par exemple, le test de l'espace de noms est affecté à la table de commande, qui peut être écrite comme test: commande)
-
Ligne: Ligne
- Chaque ligne de données dans Hbase se compose d'une RowKey et de plusieurs colonnes.
-
Colonne: Colonne
- Chaque colonne dans Hbase est qualifiée par ColumnFamily (famille de colonnes) et ColumnQualifier (qualificatif de colonne) (par exemple: personal_info: nom, personal_info: city)
-
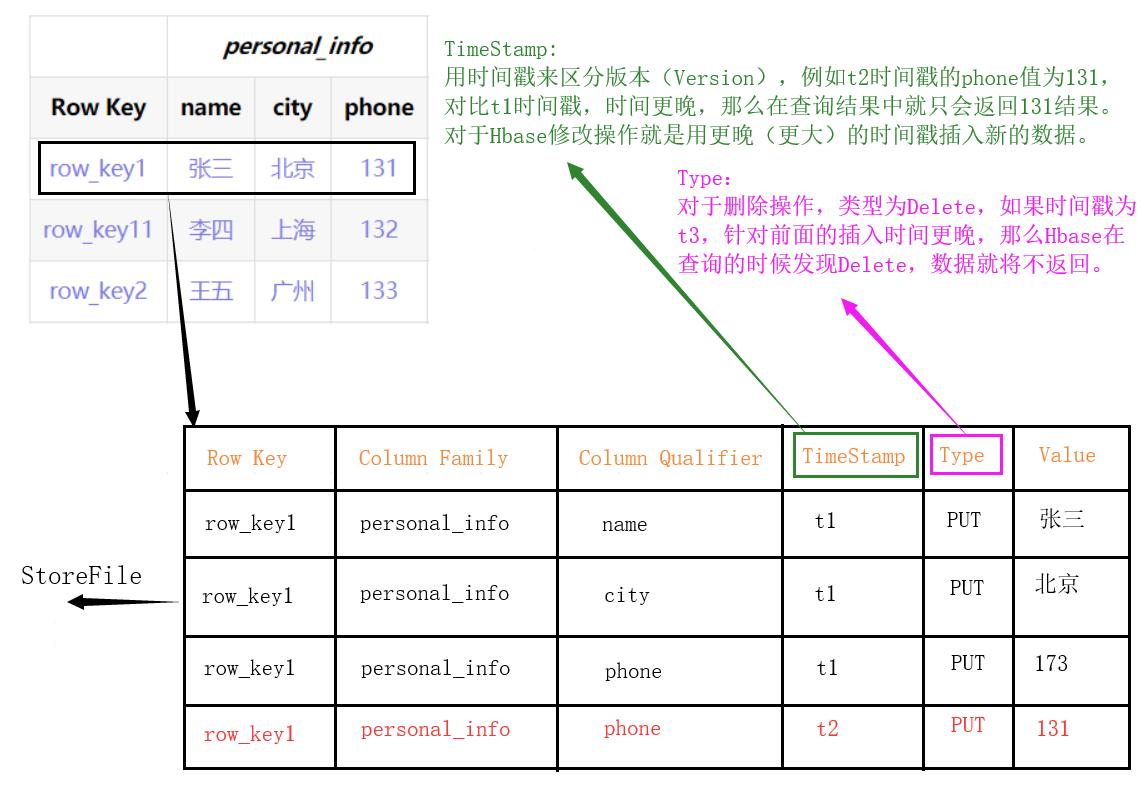
Cellule: cellule
- L'unité uniquement déterminée par {RowKey, ColumnFamily, ColumnQualifier, TimeStamp}, les données de la cellule ne sont pas typées et toutes sont stockées en code octet.
-
Touche de ligne: Touche de ligne
- La clé de ligne doit être unique dans la table et doit exister.
- Les clés de ligne sont organisées dans l'ordre selon l'ordre lexicographique (une valeur est supérieure à aucune valeur). Par exemple, row_key11 est organisé entre row_key1 et row_ley2.
- Tous les accès à la table doivent passer par la clé de ligne. (Accès simple RowKey, ou accès à la plage RowKey, ou analyse complète de la table)
-
ColumnFamily: famille de colonnes
- Lors de la création d'une table Hbase, il vous suffit de spécifier le CF. Lors de l'insertion de données, les colonnes (champs) peuvent être dynamiquement augmentées selon les besoins.
- Chaque CF peut avoir un ou plusieurs membres de colonne (ColumnQualifier).
- Différentes familles de colonnes sont stockées dans différents dossiers dans hdfs.
-
TimeStamp: horodatage
- Utilisé pour identifier différentes versions de données. Si vous ne spécifiez pas d'horodatage, Hbase ajoutera automatiquement l'horodatage actuel du système à cette valeur de champ lors de l'écriture des données.
2 Architecture Hbase
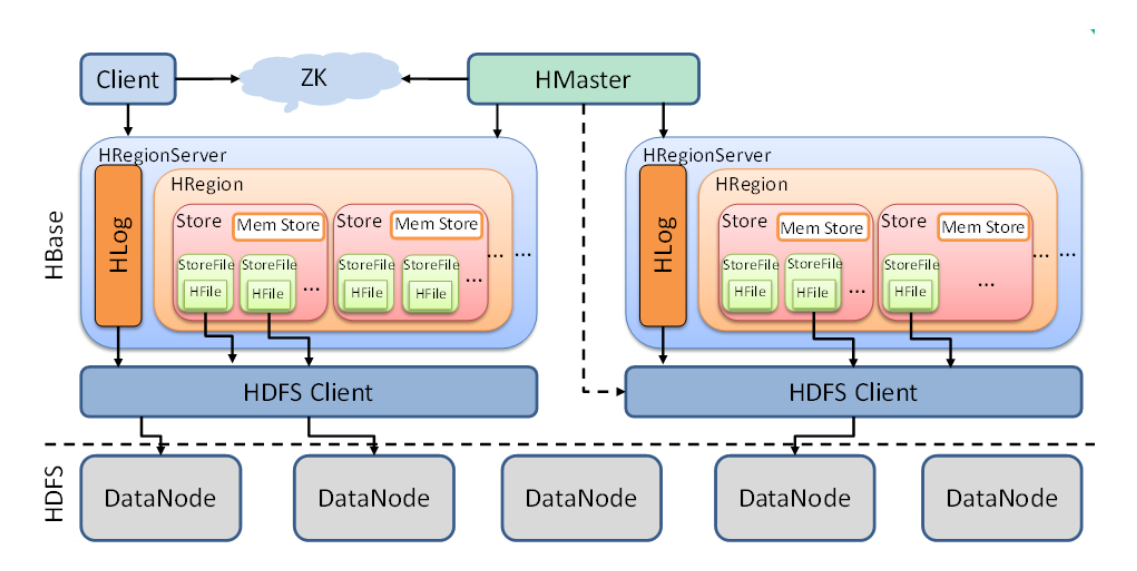
Ce qui suit explique les fonctions des composants dans le diagramme ci-dessus de petit à grand.
-
StoreFile
- StoreFile est le fichier que HBase stocke vraiment, et finalement stocké dans le DataNode via le client HDFS. (Autrement dit, sur le disque Linux)
-
Boutique
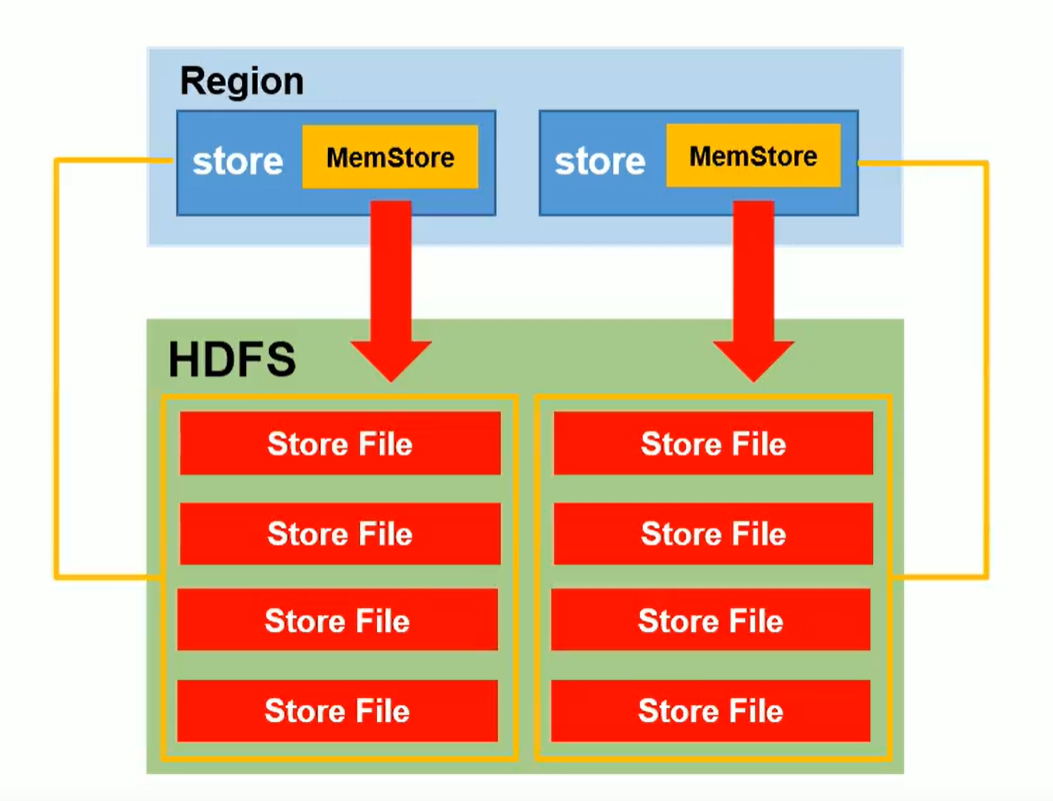
- Il peut être compris comme un ensemble de familles de colonnes dans une région découpée. (Comme indiqué ci-dessus, il y a plusieurs magasins dans une région)
- Store contient Mem Store (stockage en mémoire), StoreFile (les données flashées de la mémoire, plus seront fusionnées et les données plus grandes seront divisées)
-
Région
- La région peut être considérée comme une tranche d'un tableau. La région est divisée en fonction du seuil de taille des données et de la clé de ligne.
- HBase divise automatiquement la table horizontalement (par ligne) en plusieurs régions (régions), et chaque région stockera une donnée continue dans une table.
- Au début de chaque tableau, il n'y a qu'une seule région. Avec l'insertion continue de données, la région continue d'augmenter. Lorsqu'elle atteint un seuil, la région sera divisée en deux nouvelles régions selon la touche Ligne, etc.
- À mesure que le nombre de lignes de la table augmente, il y aura de plus en plus de régions et les données d'une table seront enregistrées dans plusieurs régions.
-
L'amour
- Le journal de pré-écriture de Hbase empêche la perte de données dans des circonstances particulières.
-
RegionServer
- Opérations de données (DML): obtenir, mettre, supprimer
- Région de gestion: SplitRegion (split), CompactRegion (fusionné)
-
Maître
- Opérations au niveau de la table (DDL): créer, supprimer, modifier
- Gérer RegionServer: surveiller l'état de RegionServer et affecter des régions à RegionServer (s'il y a des machines rs1, rs2, rs3, les données sont écrites dans Region sur rs1, rs2, r3 est inactif ---> alors rs1 est écrit beaucoup de données pour atteindre la limite supérieure de Region Après que rs1 ait divisé la région également, il avisera le maître d'en envoyer un à rs3 pour la gestion.)
3 Fonctionnement en ligne de commande
3.1 Lien hbase
- Lien hbase
hbase shell
- Afficher les commandes d'aide ou utiliser les commandes en détail
help
help '命令'
3.2 Fonctionnement de l'espace de noms
3.2.1 Interroger l'espace de noms
list_namespace

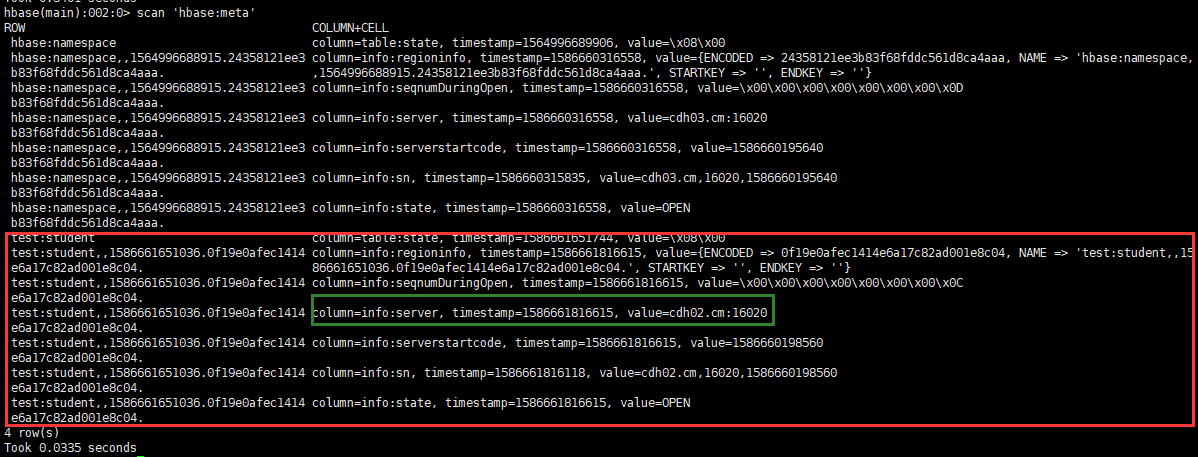
3.2.2 Interroger la table sous l'espace de noms
list_namespace_tables '命名空间名'

3.2.3 Créer un espace de noms
create_namespace '命名空间名'

3.2.4 Supprimer l'espace de noms (nécessite que l'espace de noms soit vide)
drop_namespace '命名空间名'
3.3 Fonctionnement DDL
3.3.1 Interroger toutes les tables d'utilisateurs
list
3.3.2 Créer une table
create '命名空间:表', '列族1', '列族2', '列族3','列族4'... 
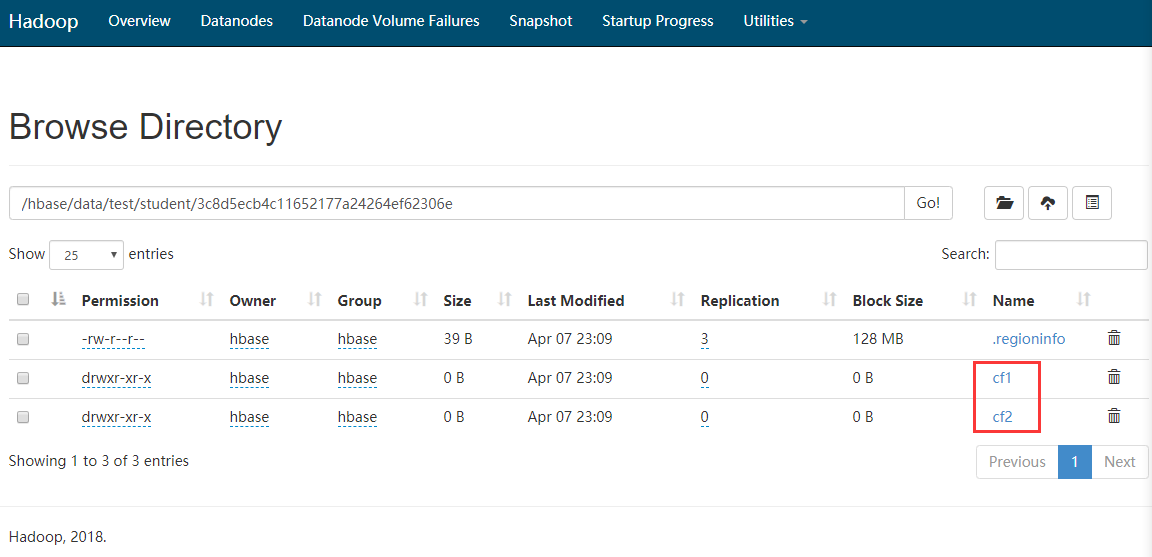
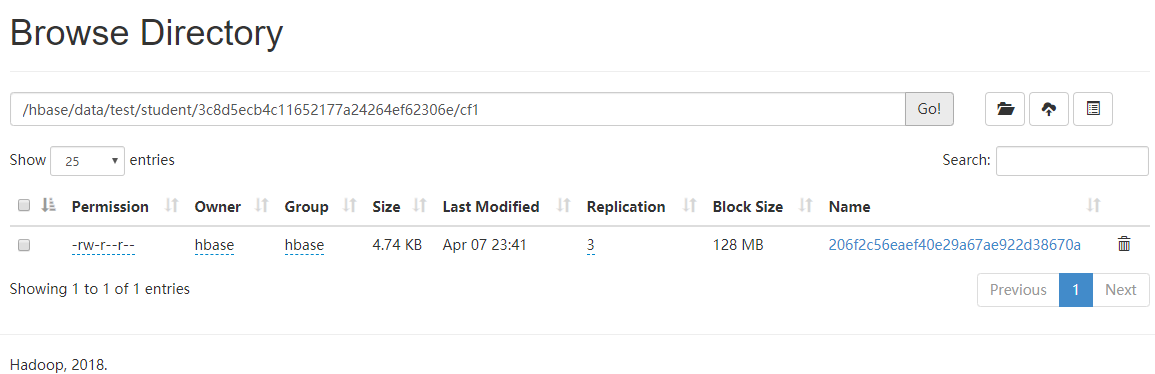
Comme le montre la figure, il existe une série de dossiers en panne. Cette série de dossiers en panne représente le numéro de région

3.3.3 Afficher les détails du tableau
describe '命名空间:表'

On peut voir que VERSIONS est 1, ce qui signifie que cette table ne peut stocker qu'une seule version des données.
3.3.4 Modifier les informations de la table
Il est principalement utilisé pour modifier les informations de sauvegarde de version de la table et peut également être spécifié lors de la création de la table, mais la commande shell est compliquée, de sorte que la commande change est généralement utilisée.
alter '命名空间:表',{NAME=>'列族名',VERSIONS=>3}
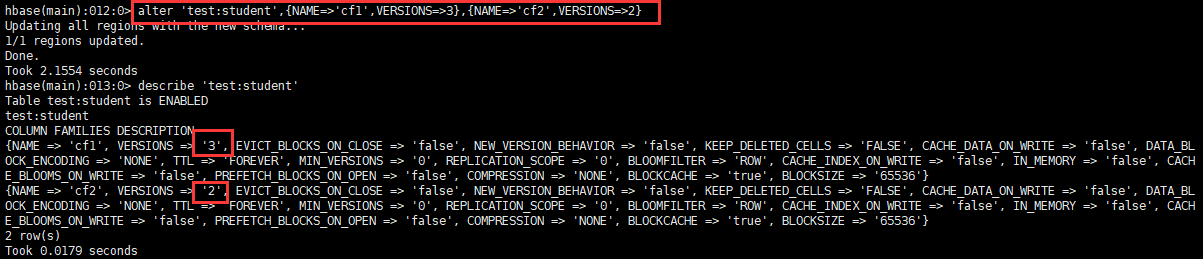

3.3.5 Modifier l'état de la table (la table doit être invalide avant la suppression)
- Table d'échec
disable '表'
- Activer la table
enable '表'
3.3.6 Supprimer le tableau
delete '表'
3.4 Fonctionnement DML
3.4.1 Insertion de données
put '命名空间:表','RowKey','列族:列','值'
put '命名空间:表','RowKey','列族:列','值',时间戳(版本控制) 

Comme le montre la figure, aucun fichier de données n'est généré, car les données sont en mémoire, vous devez vider la «table», puis vous pouvez voir l'atterrissage des données. (Flush consiste à générer un StoreFile une fois)
3.4.2 Table de numérisation
#全表扫描
scan '命名空间:表'
#范围扫描(左闭右开)
scan '命名空间:表',{STARTROW => 'RowKey',STOPROW=>'RowKey'} #扫描N个版本的数据 scan '命名空间:表',{RAW=>true,VERSIONS=>10} 3.4.3 Rinçage
flush '命名空间:表'
- Mécanisme de conservation des versions de données
D'après ce qui précède, il est connu que le vidage doit générer une fois un StoreFile, puis les données stockeront les données les plus récentes en fonction du nombre de versions de la réservation de table.
Par exemple: si le nombre de versions réservées est de 2, alors si vous insérez trois données v1, v2, v3, après vidage, il ne reste que deux données v2, v3, puis insérez trois données v4, v5, v6, après vidage, restant Les données suivantes sont quatre versions de v2, v3, v5 et v6 (dans ce cas, deux fichiers StoreFile). Si une fusion ou une division de région se produit, le fichier StoreFile sera fusionné et placé dans la région correspondante. À ce stade, les données Il sera supprimé en fonction du nombre de versions réservées, et v2, v3, v5, v6 deviendront v5, v6. (S'il n'y a pas de vidage manuel ou le temps de vidage automatique défini, les données ne seront pas supprimées en fonction du nombre de versions) (Par défaut, plus de 3 fichiers StoreFile seront fusionnés)
- Une famille de colonnes correspond à un MemStore
- Chaque MemStore génère un StoreFile indépendant lors du flashage sur HDFS
- Heure d'actualisation globale de MemStore par RegionServer: hbase.regionserver.global.memstore.size
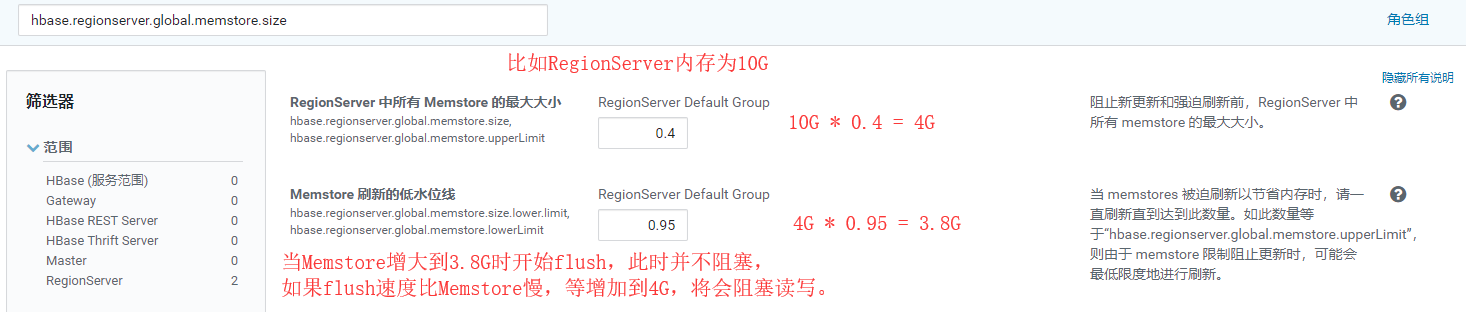
- Temps d'actualisation de Memstore unique: hbase.hregion.memstore.flush.size

3.4.3 Interroger les données
get '命名空间:表','RowKey'
get '命名空间:表','RowKey','列族' get '命名空间:表','RowKey','列族:列' #获取N个版本的数据 get '命名空间:表','RowKey',{COLUMN=>'列族:列',VERSIONS=>10} 
3.4.4 Vider la table
truncate '命名空间:表'
3.4.5 Supprimer des données
#delete '命名空间:表','RowKey','列族'(此命令行删除有问题,但是API可以)
delete '命名空间:表','RowKey','列族:列'
deleteall '命名空间:表','RowKey' 4 Processus de lecture et d'écriture
4.1 Processus d'écriture
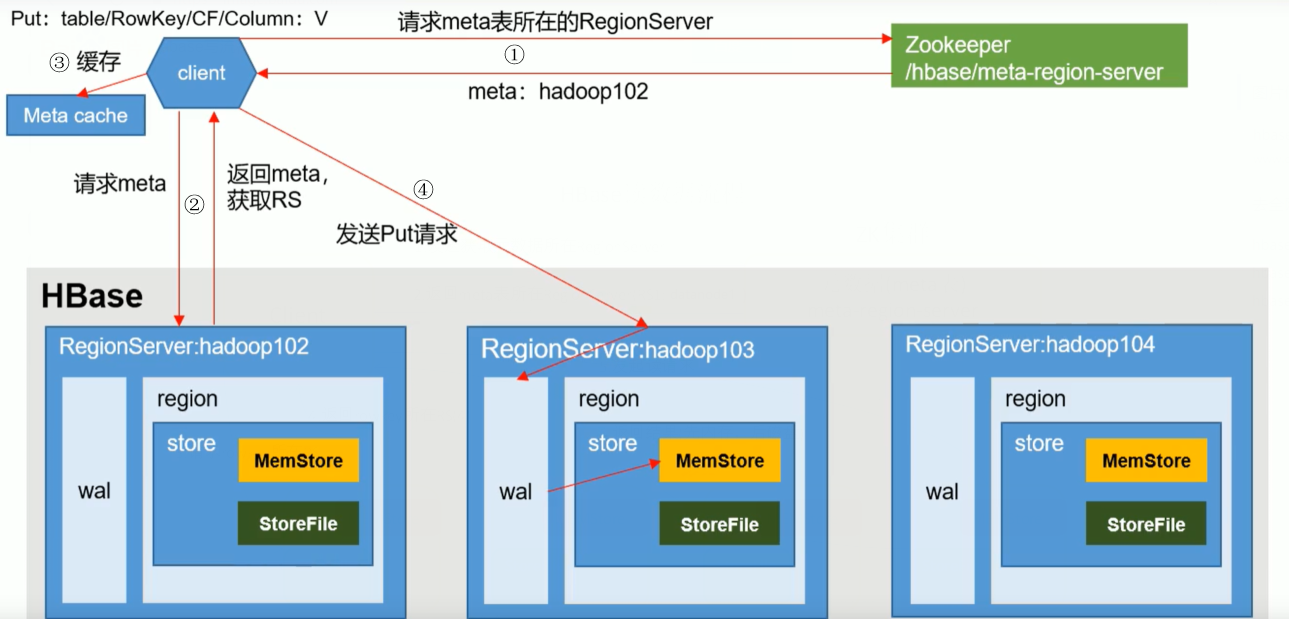
- Le client interroge l'emplacement du RegionServer où se trouve la table de stockage des métadonnées via ZK et renvoie


- Interrogez les métadonnées et renvoyez le RegionServer qui a besoin de la table

-
Le client met en cache les informations pour une utilisation facile la prochaine fois
-
Envoyez une demande PUT au RegionServer, écrivez le journal des opérations (WAL), puis écrivez dans la mémoire, puis synchronisez wal vers HDFS, puis c'est terminé. (Dans cette étape, la transaction est annulée pour garantir que les journaux et la mémoire sont correctement écrits)
4.2 Processus de lecture

Lors de la lecture des données, MemStore et StoreFile lisent ensemble, placez les données dans StoreFile dans BlockCache, puis fusionnez les données de la mémoire et l'horodatage BlockCache, et récupérez les dernières données et retournez.
5 Fusion et fractionnement
- Compactage
Parce que Memstore va générer un nouveau HFile à chaque fois qu'il est flashé, et différentes versions et différents types du même champ peuvent être distribués dans différents HFiles, il est donc nécessaire de parcourir tous les HFiles lors de la requête. Afin de réduire le nombre de HFiles et de nettoyer les données expirées et supprimées, la fusion de StoreFile sera effectuée.
Le compactage est divisé en compactage mineur et compactage majeur.
Le compactage mineur fusionnera plusieurs HFiles adjacents plus petits en un seul HFile plus grand, mais ne nettoiera pas les données expirées et supprimées.
Le compactage majeur fusionnera tous les fichiers HF d'un magasin en un seul fichier H et supprimera les données expirées et supprimées.
Réglage des paramètres:
hbase.hregion.majorcompaction = 0
hbase.hregion.majorcompaction.jitter = 0
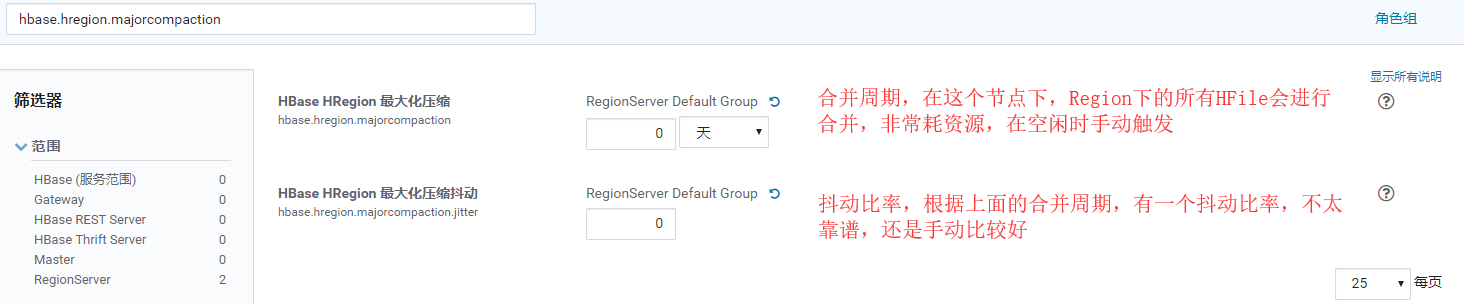
hbase.hstore.compactionThreshold = 3

- Split
Par défaut, il n'y a qu'une seule région au début de chaque table. Au fur et à mesure que les données continuent d'être écrites, la région sera automatiquement divisée. Lorsqu'elle est fractionnée, les deux sous-régions se trouvent dans le serveur de région actuel, mais pour des considérations d'équilibrage de charge, HMaster a Une région peut être transférée vers un autre serveur de région.
Réglage des paramètres:
hbase.hregion.max.filesize = 5G (Max1 dans la formule suivante) (cette valeur peut être réduite pour augmenter la simultanéité)
hbase.hregion.memstore.flush.size = 258M (Max2 dans la formule suivante)
Chaque division comparera la valeur de Max1 et Max2, la valeur la plus petite étant retenue. [min (Max1, Max2 * Nombre de régions * 2)], où le nombre de régions est le nombre de régions de la table dans le serveur de région actuel.
Étant donné que la segmentation automatique ne peut pas éviter les points chauds, nous utilisons souvent la pré-partitionnement et la conception de RowKey pour éviter les points chauds en production.


6 Optimisation
6.1 Essayez de ne pas utiliser plusieurs familles de colonnes
Afin d'éviter de générer plusieurs petits fichiers lors du vidage.
6.2 Optimisation de la mémoire

La fonction principale est de mettre en cache les données de la table, mais GC sera utilisé lors du rinçage, pas trop grand, selon les ressources du cluster, alloue généralement 70% de la mémoire du cluster Hbase, 16-> 48G est suffisant
6.3 Autoriser du contenu supplémentaire dans HDFS
dfs.support.append = true (hdfs-site.xml 、 hbase-site.xml)
6.4 Optimiser DataNode permet le nombre maximum de fichiers ouverts
dfs.datanode.max.transfer.threads = 4096 (HDFS 配置)
Dans une opération de fusion au niveau de Region Server, Region Server n'est pas disponible. Vous pouvez ajuster cette valeur en fonction des ressources du cluster pour augmenter la simultanéité.
6.5 Augmenter le nombre de moniteurs RPC
hbase.regionserver.handler.count = 30
Selon la situation du cluster, cette valeur peut être augmentée de manière appropriée, la décision principale est le nombre de demandes des clients.
6.6 Optimiser le cache client
hbase.client.write.buffer = 100M (tampon d'écriture)
L'augmentation de cette valeur peut réduire le nombre d'appels RPC, le singulier consommera plus de mémoire, défini en fonction de la situation des ressources du cluster.
6.7 Optimisation de la fusion et de la segmentation
Fusion et division de la référence 5
6.8 Pré-partition
- Ajouter le paramètre SPLITS lors de la création de la table
create '命名空间:表', '列族1', '列族2', '列族3','列族4'...,SPLITS=>['分区号','分区号','分区号','分区号'] 
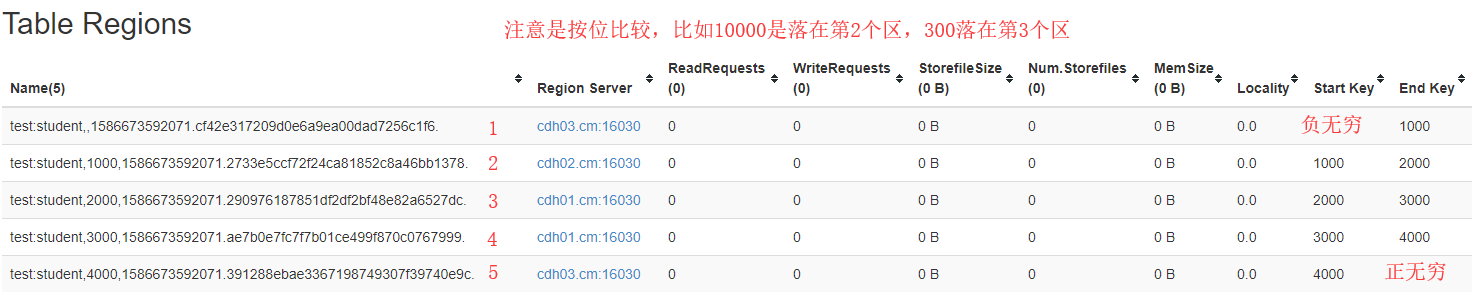
Le nombre de pré-partitions est sélectionné en fonction de la quantité de données estimée de six mois à un an et de la valeur maximale de Région.
6.9 RowKey
- Hashabilité: uniformément divisé en différentes régions
- Unicité: ne se répétera pas
- Longueur: 70-100
Option 1: nombres aléatoires, valeurs de hachage, mais cela ne peut pas être interrogé par plage, et il n'y a pas de concentration de données.
Option 2: inversion de chaîne, par exemple, la possibilité de hachage est obtenue après que l'horodatage est inversé, mais la concentration n'est meilleure que la première lors de la visualisation.
- Plan de production recommandé:
#设计预分区键(如比如200个区) | ASCLL码为124只有 } 和 ~ 比它大,那么不管以后的RowKey使用什么字符,都是小于这个字符的,所以可以有效的得到RowKey规律
000|
001|
......
199|
# 1 设计RowKey键_ASCLL码为95
000_
001_
......
199_
# 2 根据业务唯一标识(如用户ID,手机号,身份证)和时间维度(比如按月:202004)计算后根据分区数取余(13408657784^202004)%199=分区号
# 想以什么时间进行查询就把什么往前提,如下数据需要查1月数据范围就是 000_13408657784_2020-04 -> 000_13408657784_2020-04|
000_13408657784_2020-04-01 12:12:12
......
199_13408657784_2020-04-01 24:12:12