2-1 Description du modèle
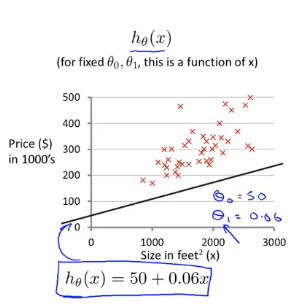
Nous voulons utiliser un ensemble de données qui contient les prix des logements à Portland, Oregon. Ici, je veux dessiner mon ensemble de données en fonction des prix vendus pour différentes tailles de maisons. Par exemple, si la maison de votre ami mesure 1 250 pieds carrés, vous devez lui dire combien la maison peut vendre.
Une chose que vous pouvez faire est de construire un modèle, peut-être une ligne droite. À partir de ce modèle de données, vous pouvez peut-être dire à votre ami qu'il peut vendre la maison pour environ 220 000 (USD). Ceci est un exemple d'algorithme d'apprentissage supervisé.

J'utiliserai des minuscules m pour le nombre d'échantillons d'entraînement tout au long du cours .
Prenons l'exemple du problème de transaction de logement précédent, si nous revenons à l'ensemble de formation (ensemble de formation) du problème, comme indiqué dans le tableau ci-dessous

Les étiquettes que nous utiliserons pour décrire ce problème de régression sont les suivantes:
m représente le nombre d'instances dans l'ensemble d'apprentissage
x signifie caractéristique / variable d'entrée
y représente la variable cible / variable de sortie
(x, y) représente une instance dans l'ensemble d'apprentissage
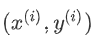 Représente la première instance d'observation
Représente la première instance d'observation
h représente la solution ou la fonction de l'algorithme d'apprentissage peut également être appelée hypothèse
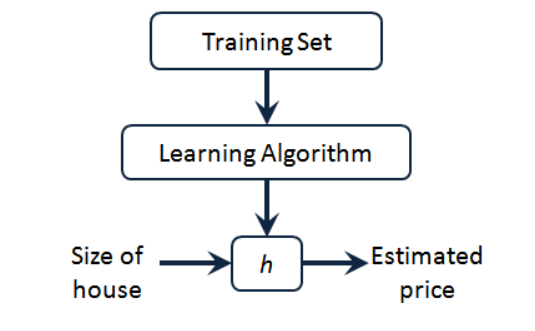
Nous pouvons voir qu'il y a des prix de l'immobilier dans notre ensemble de formation. Nous le donnons à notre algorithme d'apprentissage, apprenons le travail de l'algorithme, puis émettons une fonction, généralement exprimée en h minuscule
Représente une hypothèse (hypothèse), une fonction, l'entrée est la taille de la maison, tout comme la maison que votre ami veut vendre, donc h dérive la valeur y en fonction de la valeur x entrée , et la valeur y correspond au prix de la maison. Par conséquent, h est une fonction mappant de x à y .
Alors, comment pouvons-nous exprimer h pour notre problème de prédiction du prix des maisons ?
Un moyen d'expression possible est: 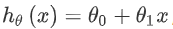 Puisqu'il ne contient qu'une seule caractéristique / variable d'entrée (la superficie de la maison), un tel problème est appelé un problème de régression linéaire univariée.
Puisqu'il ne contient qu'une seule caractéristique / variable d'entrée (la superficie de la maison), un tel problème est appelé un problème de régression linéaire univariée.
2-2 Fonction de coût
Nous définirons le concept de la fonction de coût, ce qui nous aidera à déterminer comment adapter la ligne droite la plus probable à nos données .

Dans la régression linéaire, nous avons un ensemble d'apprentissage comme celui-ci, m représente le nombre d'échantillons d'apprentissage, par exemple m = 47 . Et notre fonction hypothétique est la forme de la fonction utilisée pour faire des prédictions: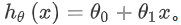
Nous allons introduire une terminologie. Ce que nous devons faire maintenant est de choisir les paramètres appropriés pour notre modèle  . Dans le cas du problème du prix du logement, c'est la pente de la droite et l'ordonnée à l'origine sur l' axe des y .
. Dans le cas du problème du prix du logement, c'est la pente de la droite et l'ordonnée à l'origine sur l' axe des y .
Erreur de modélisation Le paramètre que nous choisissons détermine la précision de la ligne droite que nous obtenons par rapport à notre ensemble d'entraînement, et l'écart entre la valeur prédite par le modèle et la valeur réelle dans l'ensemble d'entraînement (la ligne bleue dans la figure ci-dessous)

Notre objectif est de sélectionner les paramètres du modèle qui peuvent minimiser la somme des erreurs de modélisation au carré.
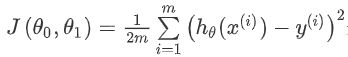
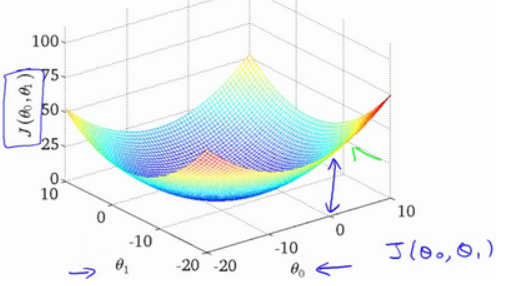
Nous dessinons une carte de contour, les trois coordonnées sont θ 0 et θ 1 et J (θ 0, θ1) :
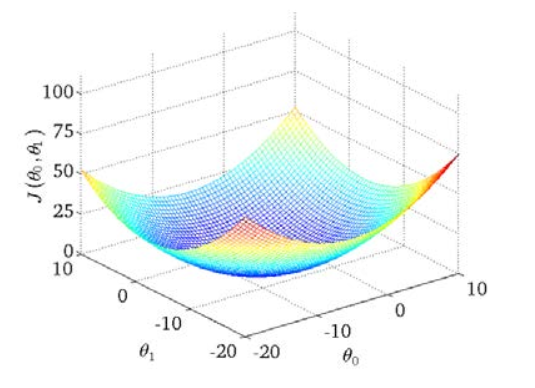
On peut voir qu'il y a un point minimum dans l'espace tridimensionnel .
La fonction de coût est également appelée fonction d'erreur quadratique, et parfois appelée fonction de coût d'erreur quadratique. La raison pour laquelle nous avons besoin de la somme des erreurs au carré est que la fonction de coût au carré des erreurs est un choix raisonnable pour la plupart des problèmes, en particulier les problèmes de régression.
2-3 Comprendre la fonction de coût (1)
Obtenons quelques sentiments intuitifs à travers quelques exemples et voyons ce que fait la fonction de coût.

Ensuite, notre exemple est l'analyse lorsque θ 0 est 0
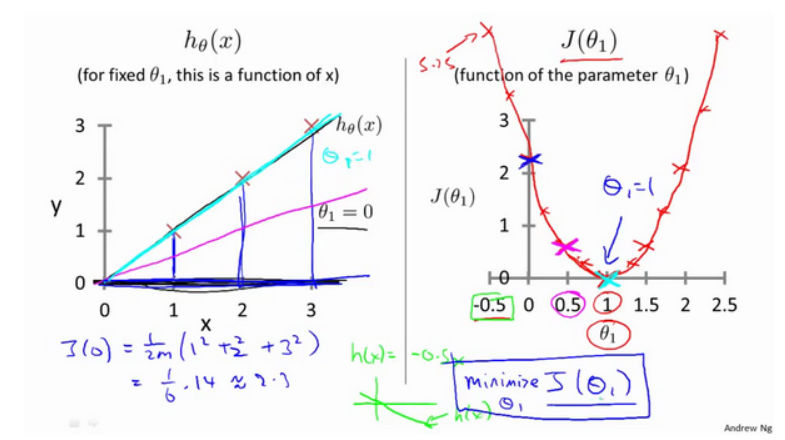
2-4 Comprendre la fonction de coût (2)
L'apparition de la fonction de coût, le tracé de contour, montre qu'il existe un point dans l'espace tridimensionnel qui minimise J (θ 0, θ1) .
Supposons que la droite que nous ajustons soit comme indiqué sur la figure, nous avons maintenant deux paramètres θ 0, θ1, et sa fonction de coût est la suivante
La figure ci-dessous montre une carte de contour. Chaque point de la carte de contour a une pente et une intersection correspondantes. Plus le centre est proche, meilleure est la ligne droite.
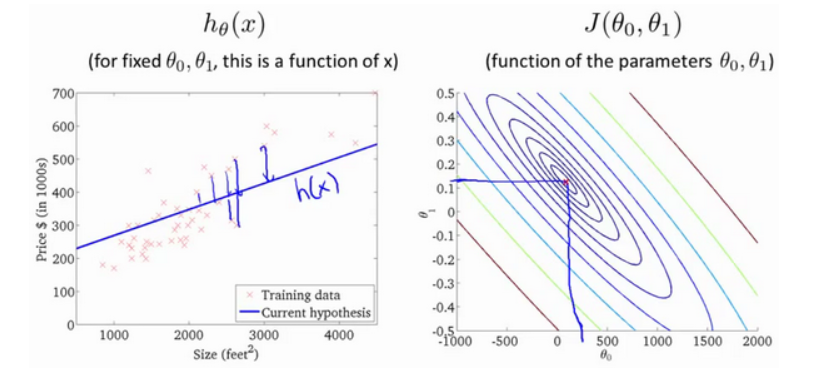
Grâce à ces graphiques, je l' espère , vous pouvez mieux comprendre la fonction de coût J valeurs exprimées ce qu'ils correspondent hypothèse est que, et quelles sont les hypothèses point correspondant, plus proche de la fonction de coût J de La valeur minimale.
2-5 descente en pente
La descente de gradient est un algorithme utilisé pour trouver la valeur minimale de la fonction. Nous utiliserons l'algorithme de descente de gradient pour trouver la valeur minimale de la fonction de coût J (θ 0, θ 1 ) .
L'idée derrière la descente du gradient est: au début, nous choisissons au hasard une combinaison de paramètres , calculons la fonction de coût, puis nous recherchons la prochaine combinaison de paramètres qui fera le plus chuter la valeur de la fonction de coût. Nous continuons à le faire jusqu'à ce que nous atteignions un minimum local, car nous n'avons pas essayé toutes les combinaisons de paramètres, donc nous ne sommes pas sûrs que le minimum local que nous obtenons soit le minimum global. Le choix de différentes combinaisons de paramètres initiaux peut trouver différent Minimum local de.
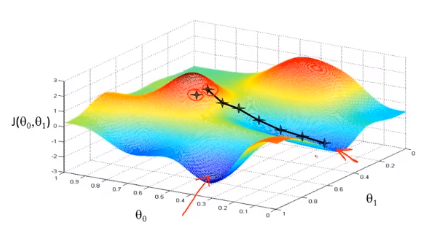
Imaginez que vous vous tenez sur ce point de la montagne, debout sur la montagne rouge dans le parc que vous imaginez. Dans l'algorithme de descente en gradient, tout ce que nous avons à faire est de tourner à 360 degrés, de regarder autour de nous et de nous demander d'être à un certain endroit. Dans ce sens, descendez la montagne à petits pas. Pensez à chaque pas que vous faites jusqu'à ce que vous soyez proche du point le plus bas local
La formule de l'algorithme de descente de gradient par lots est

Où α est le taux d'apprentissage, qui détermine le nombre de pas que nous prenons dans la direction qui peut faire diminuer le plus la fonction de coût. Dans la descente de gradient par lots, chaque fois que nous soustrayons tous les paramètres d' apprentissage en même temps par le taux d'apprentissage multiplié par la dérivée de la fonction de coût.

Dans l'algorithme de descente de gradient, c'est la bonne façon de réaliser des mises à jour simultanées.
2-6 Résumé des points de connaissance de la descente du gradient

L'affectation de θ fait avancer J (θ) dans la direction de descente de gradient la plus rapide, et itère complètement pour finalement obtenir le minimum local. Parmi eux, le taux d'apprentissage α ( taux d'apprentissage ), qui détermine le nombre de pas que nous faisons dans la direction qui peut faire diminuer le plus la fonction de coût.
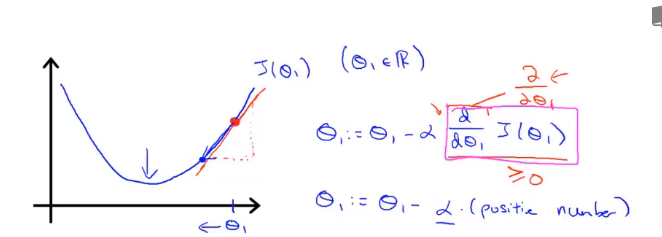
Maintenant, cette ligne a une pente positive, ce qui signifie qu'il a une dérivée positive, de sorte que j'obtenir le nouveau [theta] 1 , après la mise à jour est égale à moins d' un nombre positif multiplié par [theta] 1 .
Voyons ce qui se passe si α est trop petit ou trop grand:
Si α est trop petit, c'est-à-dire que mon taux d'apprentissage est trop petit, le résultat est que je ne peux que bouger un peu comme un bébé, en essayant de me rapprocher du point le plus bas, donc il faut de nombreuses étapes pour atteindre le point le plus bas.
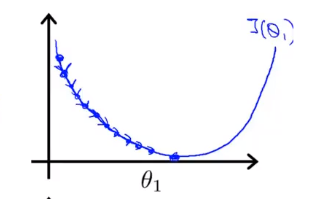
Si α est trop grand, alors la méthode de descente en gradient peut traverser le point le plus bas, et peut même ne pas converger. La prochaine itération a déplacé un grand pas, encore et encore, encore et encore, sur le point le plus bas, jusqu'à ce que vous constatiez qu'il est réellement éloigné Le point devient de plus en plus loin, donc s'il est trop grand, il guidera
En conséquence, il ne peut pas converger ni même diverger.

Si votre paramètre est déjà au point le plus bas local et que la pente est 0, alors la mise à jour de la méthode de descente en gradient ne fait rien, elle ne changera pas la valeur du paramètre. Cela explique également pourquoi la descente de gradient peut converger vers le point le plus bas local même lorsque le taux d'apprentissage α reste inchangé.
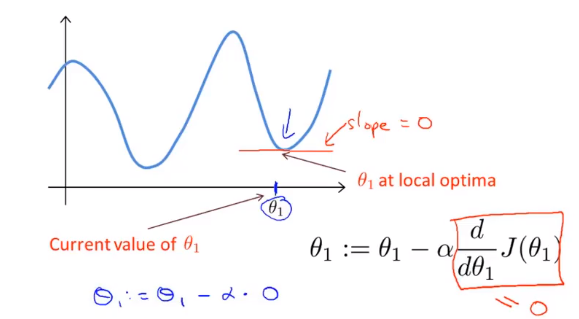
Dans la méthode de descente en gradient, lorsque nous sommes proches du minimum local, la méthode de descente en gradient prendra automatiquement une plus petite amplitude, car lorsque nous sommes proches du minimum local, il est clair que la dérivée est égale à zéro au minimum local, donc quand nous sommes proches du local Au point le plus bas, la valeur dérivée deviendra automatiquement de plus en plus petite, donc la descente de gradient prendra automatiquement une amplitude plus petite, c'est la méthode de descente de gradient.
2-7 Descente en gradient de régression linéaire
La comparaison entre l'algorithme de descente de gradient et l'algorithme de régression linéaire est la suivante:

La clé pour appliquer la méthode de descente de gradient à notre précédent problème de régression linéaire est de trouver la dérivée de la fonction de coût, à savoir:
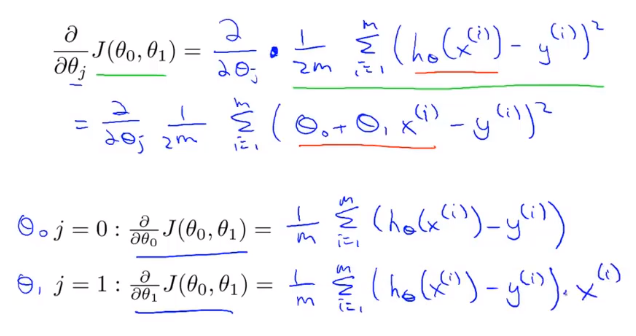
L'algorithme que nous venons d'utiliser est parfois appelé descente de gradient par lots. Cela signifie qu'à chaque étape de la descente de gradient, nous utilisons tous les échantillons d'apprentissage m. Dans la descente de gradient, lors du calcul du terme dérivé différentiel, nous devons effectuer une opération de sommation, donc, dans chaque descente de gradient individuelle En fin de compte, nous devons calculer une telle chose, cet élément doit additionner tous les m échantillons d'apprentissage.
Maintenant que nous avons maîtrisé la descente de gradient, nous pouvons utiliser la méthode de descente de gradient dans différents environnements, et nous l'utiliserons également largement dans différents problèmes d'apprentissage automatique.