Cet article explique l'opération à l'aide de l'outil kibana:
Arrangement kibana
Téléchargez et décompressez kibana, recherchez kibana.yml dans le dossier config du répertoire racine, modifiez la configuration comme suit

- ** Jusqu'à présent (la dernière version officielle actuelle est la 6.4), la fonction officielle signifie: temporairement ne prend pas en charge la connexion de plusieurs nœuds es, c'est-à-dire qu'une seule adresse peut être renseignée dans le fichier de configuration ci-dessus. ** Une autre solution fournie par le site officiel: https://www.elastic.co/guide/en/kibana/6.4/production.html#load-balancing
signifie grosso modo:
Construisez un nœud es qui est uniquement utilisé pour la "coordination", laissez ce nœud rejoindre le cluster es, puis kibana se connecte à ce nœud "coordination". Ce nœud "coordination" ne participe pas à l'élection du nœud maître et ne stocke pas de données. Il est uniquement utilisé pour le traitement Requête HTTP entrante, et rediriger l'opération vers d'autres nœuds es du cluster, puis collecter et renvoyer le résultat. Ce nœud de "coordination" joue également essentiellement un rôle d'équilibrage de charge.
Après avoir installé le plugin xpack, vous pouvez activer la vérification de la connexion. Si le mot de passe est configuré comme suit:
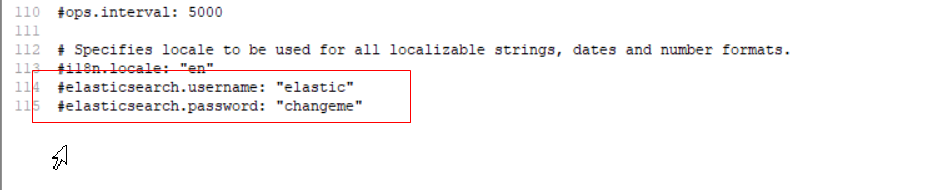
vous pouvez le démarrer une fois la configuration terminée, visitez: http: // localhost: 5601
Concepts de base
_index 文档在哪存放
_type 文档表示的对象类别
_id 文档唯一标识
API d'indexation
# 创建索引(插入数据,没有索引会创建)
PUT twitter/_doc/1
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}

total-Indique que l'opération d'indexation doit être effectuée sur plusieurs copies de partition (partition principale et partition de réplique).
succès-Indique le nombre de copies de partition exécutées avec succès par l'opération d'indexation.
a échoué - Si l'opération d'indexation échoue sur le fragment de réplique, le tableau contenant les erreurs liées à la réplication
# 允许创建 叫twitter,index10 没有其他的折射率匹配index1*,以及任何其他折射率匹配ind*。模式按照给定的顺序进行匹配
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "twitter,index10,-index1*,+ind*"
}
}
# 不允许 自动创建索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "false"
}
}
# 允许创建所有类型索引
PUT _cluster/settings
{
"persistent": {
"action.auto_create_index": "true"
}
}
Obtenez l'API
# 根据id查询
GET twitter/_doc/1

Supprimer l'API
# 根据id删除
DELETE /twitter/_doc/1
# 根据查询条件删除
POST twitter/_delete_by_query
{
"query": {
"match": {
"user": "kimchy"
}
}
}

API en vrac
#多条命令一起执行
POST _bulk
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
Mise à jour de l'API
POST twitter/_doc/3/_update
{
"doc" : {
"user" : "liuli-new"
}
}

API de réindexation
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
Cet article est tout simplement quelques exemples, de nombreux es documentation api, reportez - vous à la documentation officielle d'apprendre en fonction de leurs besoins de

documentation de référence:
https://www.elastic.co/guide/en/elasticsearch/reference/6.5/docs.html
