Concepts de base:
Index
index (index) est logique ElasticSearch stocker des données logiques, il peut être divisé en plus petites portions.
L'indice peut être considéré comme une table de base de données relationnelle, la structure d'index est préparé pour le rapide et efficace d' indexation en texte intégral, en particulier, il ne stocke pas la valeur d' origine.
ElasticSearch l'indice peut être stocké dans une seule machine ou répartie sur plusieurs serveurs, chacun avec un ou plusieurs fragments d'index (Shard), chaque tranche peut avoir une pluralité de copies (réplique).
Les documents
stockés dans l' entité principale ElasticSearch appelé le document (document). Avec une analogie de base de données relationnelle, un document équivalent à une ligne dans la table de base de données.
ElasticSearch et MongoDB est un document similaire, peut avoir des structures différentes, mais le document ElasticSearch, le même domaine doivent avoir le même type.
Documentation d'une pluralité de champs, chaque champ peut apparaître plus d'une fois dans un document, champ appelé un champ à valeurs multiples (multivalué).
Tapez pour chaque champ, il peut être du texte, numérique, date, etc.. Les types de champ peuvent également être de type complexe, un champ qui contient des documents ou d' autres sous-tableau.
La cartographie
tout d' abord être écrit dans le document avant l'analyse de l' index, la saisie de texte est divisé en entrées, les entrées sont filtrées, ce comportement est appelé cartographie (mapping). Règles générales définies par l'utilisateur.
Type de document
dans ElasticSearch, l'objet d'index peut stocker un grand nombre d'objets de différentes fins. Par exemple, une application de blog peut enregistrer des articles et des commentaires.
Chaque document peut avoir une structure différente.
Les différents types de documents ne peuvent pas définir les mêmes propriétés de différents types. Par exemple, tous les types de documents dans le même indice, celui qui est appelé le champ doit avoir le même type.
API RESTful:
Dans ElasticSearch fourni une API d'exploitation riche en fonctionnalités RESTful, y compris CRUD de base, créer un index, supprimer l'index et d'autres opérations.
Création d'index non structuré:
En Lucene, créer l'index est nécessaire de définir les noms de champs et les types de terrain, et fournit des index non structurées dans ElasticSearch, la structure est pas nécessaire de créer un index, vous pouvez écrire des données à l'index, en fait, le fond sera ElasticSearch opération de structuration, cette opération est transparente pour l'utilisateur.
Créer un index vide
PUT / Haoke
{ "Paramètres" : { "index" : { "number_of_shards": "2" , #分片数 "number_of_replicas": "0" #副本数 } } }
Index Supprimer
SUPPRIMER / Haoke
{ "Reconnu": true }
Insérer des données:
Le POST / dépôt index {} / {type d'index} / {id} passe id sinon, généré automatiquement
POST / Haoke / user / 1001
{ "Id": 1001 , "name": "张三" , "âge": 20 , "sexe": "男" }
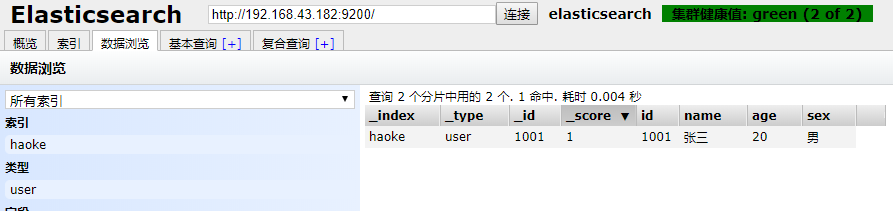
Description: index non structuré, n'a pas besoin d'être créé à l'avance, directement dans les données créées par index par défaut.
Id données insérées ne sont pas spécifiés:
POST / Haoke / utilisateur /
{ "Id": 1002 , "name": "张三" , "âge": 20 , "sexe": "男" }

Mettre à jour les données:
En ElasticSearch, n'est pas modifié les données du document, mais le couvercle peut être mis à jour par les étapes suivantes:
1. Récupérer le JSON de l'ancien document
2. Modifiez - le
supprimer les anciens documents
4. nouveaux documents d'indexation
PUT / Haoke / user / 1001
{ "Id": 1001 , "name": "李四" , "âge": 30 , "sexe": "女" }

Mise à jour locale: Note: Ceci est plus qu'un logo _update
POST / Haoke / user / 1001 / _update
{ "Doc" : { "age": 23 } }
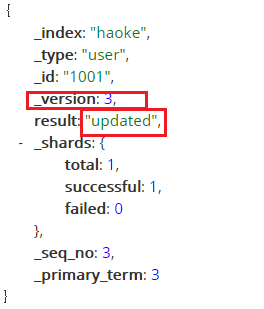
Supprimer les données:
Dans ElasticSearch, supprimez les données du document, il vous suffit de lancer une requête SUPPRIMER.
DELETE / Haoke / user / 1001
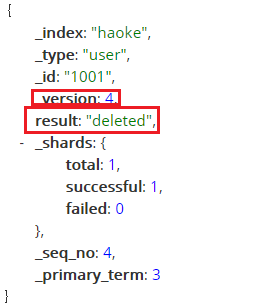
Il convient de noter, la représentation de résultat a été supprimé, la version ajoute également, si vous supprimez une donnée n'existe pas, répondra à 404.
Description:
Supprimer le fichier d'un ne sera pas retiré immédiatement du disque, mais il est marqué comme supprimé. ElasticSearch sera ajouté après l'index plus de temps sera nettoyé pour enlever le contenu en arrière - plan.
Rechercher des données:
Selon les données de recherche id
GET / Haoke / user / 6NAVEXEBVAiLr6jRjciF

Recherche Toutes les données (retour par défaut 10 données)
GET / Haoke / user / _search
Recherche par mot clé données éléments
20 ans est égale à la requête de l'utilisateur
? GET / Haoke / user / _search q = âge: 20
DSL Recherche:
ElasticSearch fournir un langage de requête riche et flexible appelé requête DSL (Requête DSL), ce qui vous permet de construire des requêtes plus complexes et puissants.
DSL (Domain Specific Language langue spécifique à domaine) sous la forme de corps demande JSON se produit.
POST / Haoke / utilisateur / _search
{ "Requête" : { "match" : {#match une seule requête "Age": 20 est } } }
Les hommes de plus de 18 ans requête de l'utilisateur est.
POST / Haoke / utilisateur / _search
{ "Requête" : { "bool" : { "filtre" : { "range" : { "age" : { "gt": 18 } } }, "must" : { "match" : { "sexe": "男» } } } } }
recherche plein texte
POST / Haoke / utilisateur / _search
{ "Requête" : { "match" : { "name": "张三李四" } } }
Mettez en surbrillance:
POST / Haoke / utilisateur / _search
{ "Requête" : { "match" : { "name": "张三李四" } }, "highlight" : { "champs" : { "name" : {} } } }

polymérisation:
Dans ElasticSearch, l'opération de polymérisation supporté, similaire au groupe d'opérations SQL.
POST / Haoke / utilisateur / _search
{ "Aggs" : { "all_interests" : { "termes" : { "champ": "age" } } } }
