contenu
1. Qu'est-ce qu'un reptile?
2. Pourquoi robots d'exploration Web avec python
configuration de l'environnement 3.python
4. J'ai besoin de savoir ce que pré-connaissance du reptile python
5. Expressions régulières A propos de
6. contenu Web extrait et l'expression traitées avec n
7.xPath et BeautifulSoup intro
En termes simples, la sonde de reptiles est une machine, son fonctionnement de base est de simuler le comportement humain à différents sites flânent, petits boutons, rechercher des données, des informations ou pour voir le dos arrière. Comme un infatigable insectes rampants autour dans un bâtiment.
Vous pouvez facilement imaginer: tous les reptiles est votre « avatar ». Comme le roi singe tiré une poignée de cheveux, souffler un tas de singes.
Vous utilisez tous les Baidu jour, en fait, l'utilisation de ce reptile technologique: le jour de la sortie d' innombrables reptiles à chaque site, leurs informations revenez à nouveau, puis la ligne de bonne équipe de maquillage vous attend de récupérer.
Logiciel à voix d'appui, ce qui équivaut à étaler de nombreux engagements, chaque avatar vous aidera à former constamment rafraîchi plus de 12306 billets site. Une fois un billet, immédiatement tiré vers le bas, puis vous criez: paiement Tyran Venez.- de l'utilisateur de connaître l'histoire de presque
<- ... ->: Définit le commentaire
<! DOCTYPE>: Définit le type de document
<html>: Document total html tag
<head>: Définir le chef
<body>: définir le contenu web
<script>: scripts personnalisés
<div>: Division, définir des partitions, des étiquettes de conteneurs
<p>: le paragraphe, le paragraphe défini
<a>: définir des liens hypertexte
<span>: définir le conteneur de texte
<br>: wrap
<form>: forme personnalisée
<table>: table de définition
<th>: tête défini
<tr>: table rangée
<td>: colonne du tableau
<b>: définir gras
<img>: l' image personnalisée
Importation Re importation urllib.request importation de la chardet la réponse = le urllib.request.urlopen ( « http://news.hit.edu.cn/ » ) des paramètres d'entrée # pour la page que vous souhaitez analyser l'URL de HTML = response.read () # html lire la variable chardet1 = chardet.detect (html) acquiert # codage html = html.decode (chardet1 [ ' codant ' ]) # traité selon le codage acquis
Ici, nous avons le site officiel de nouvelles d'une université à titre d'exemple pour démontrer le reptile python de fonctionnement, à seulement quelques lignes de code ci-dessus seront atteints analyse de contenu Web pour les opérations locales.
Suivant est le contenu de rampé au traitement d'expression régulière, obtenir ce que nous voulons observer le code source de la page:

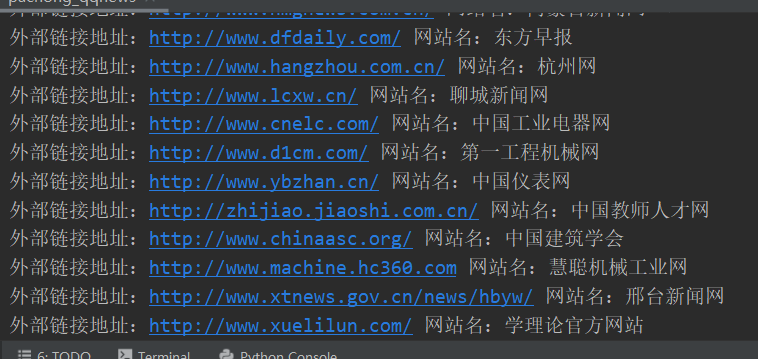
Nous espérons que des liens externes qui sont abondés par l'expression régulière avant que les connaissances acquises à atteindre les objectifs suivants:
mypatten = " <li class = \" link-item \ "> <a href=\"(.*)\"> <span> (. *) </ span> </a> </ li> " mylist = re.findall (mypatten, html) pour i dans mylist: print ( " 外部链接地址:% s网站名:% de " l'% (i [0], I [1]))
L'effet qui en résulte est:
7.xPath et BeautifulSoup intro
En plus des documents Web de traitement régulier d'expression obtenus par, on peut aussi considérer leur propre architecture web.
XPath, le nom complet de la langue XML Path, à savoir XML Path Language, est une information de conclusion dans un langage de document XML. XPath a été conçu à l'origine pour rechercher des documents XML, mais cela vaut aussi pour rechercher des documents HTML.
nodename sélectionner tous les nœuds enfants de ce noeud
/ nœuds à partir du courant sélectionné nœud enfant direct
// Sélection noeud descendant à partir du nœud actuel
. Sélectionnez le noeud courant
.. sélectionnez le nœud parent du nœud actuel
@ attribut de sélection
Voici une liste des règles de correspondance couramment XPath, par exemple / représentants choisis noeud enfant direct représentant sélectionné // tous les descendants nœuds représentatifs de sélectionner le noeud courant, le noeud courant .. représentant nœud parent sélectionné @ attribut est ajouté la définition, la sélection d'un des attributs correspondants de noeud spécifique.
de lxml import eTree import urllib.request import chardet réponse = urllib.request.urlopen ( " https://www.dahe.cn " ) html = response.read () chardet1 = chardet.detect (html) html = html.decode (chardet1 [ ' codant ' ]) etreehtml = etree.HTML (html) mylist = etreehtml.xpath ( " / html / corps / div / div / div / div / div / ul / div / li " )
reptile BeautifulSoup4 apprendra les compétences. BeautifulSoup principale fonction est de récupérer les données à partir de la bande, Belle soupe automatiquement converti en Unicode codant pour le document d'entrée, le document est converti en un signal de sortie utf-8 codé. BeautifulSoup prend en charge la bibliothèque standard Python d'analyseur HTML prend également en charge l'analyseur tiers, si nous n'installons pas, la valeur par défaut Python Python utilise l'analyseur, l'analyseur lxml plus puissant, plus rapide, résolution recommandée lxml appareil.
de BS4 Importer le BeautifulSoup fichier = Ouvrir ( ' ./aa.html ' , ' RB ' ) HTML = File.read () BS = le BeautifulSoup (HTML, " html.parser " ) # indentation Imprimer (bs.prettify () ) # Format structure HTML Imprimer (bs.title) # obtenir le nom de la balise title Print (bs.title.name) # obtenir la balise de titre du texte Imprimer (bs.title.string) # toute la tête acquisition ontenu Imprimer ( bs.head) #Obtenez tout le contenu de la première balise div impression (bs.div) # obtenir une première valeur de la balise div id print (bs.div [ « id » ]) # Obtenez tout le contenu d'une étiquette à une impression (bs.a) # obtenir tout le contenu de toutes les balises dans une impression (bs.find_all ( " un " )) # Get = ID "U1" Imprimer (bs.find (ID = " U1 " )) # extraient tous une étiquette et une valeur traversée de href d'impression d'étiquettes pour objet en bs.find_all ( « un » ): Imprimer (item.get ( « href »)) # Obtenir tous une étiquette et d' imprimer traverse une valeur de texte de l' étiquette pour l' article dans bs.find_all ( « un » ): Print (item.get_text ())
<- ... ->: Définit le commentaire
<! DOCTYPE>: Définit le type de document
<html>: Document total html tag
<head>: Définir le chef
<body>: définir le contenu web
<script>: scripts personnalisés
<div>: Division, définir des partitions, des étiquettes de conteneurs
<p>: le paragraphe, le paragraphe défini
<a>: définir des liens hypertexte
<span>: définir le conteneur de texte
<br>: wrap
<form>: forme personnalisée
<table>: table de définition
<th>: tête défini
<tr>: table rangée
<td>: colonne du tableau
<b>: définir gras
<img>: l' image personnalisée