ML-Agents (b) crear un entorno de aprendizaje
I. Introducción
En la que estamos hablando acerca de cómo configurar el entorno ML-Agents, esta sección creamos una muestra, el uso principal de aprendizaje por refuerzo (aprendizaje por refuerzo).
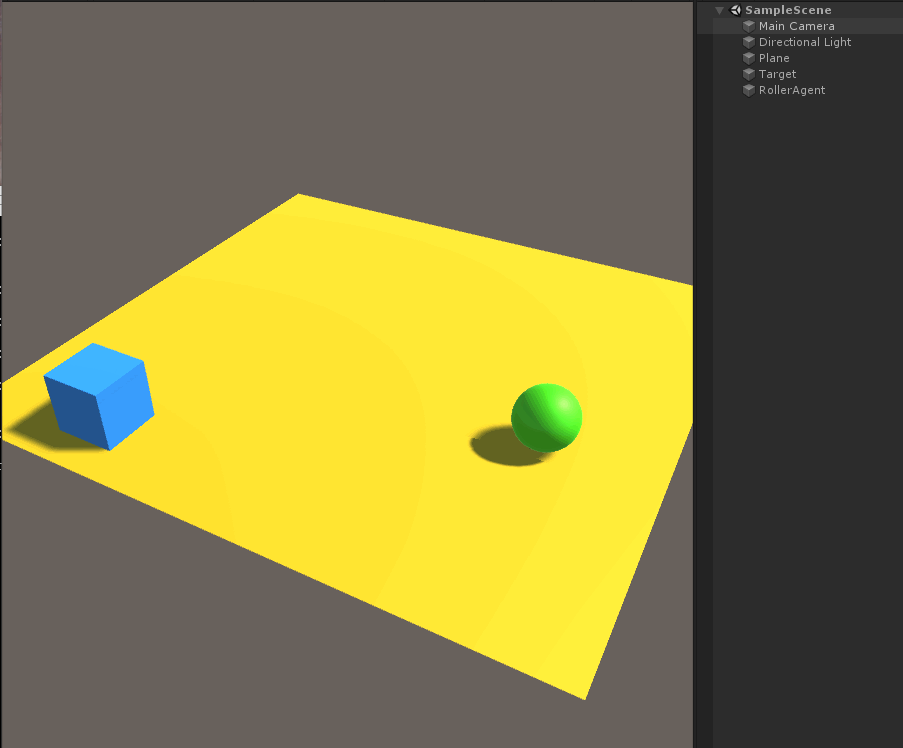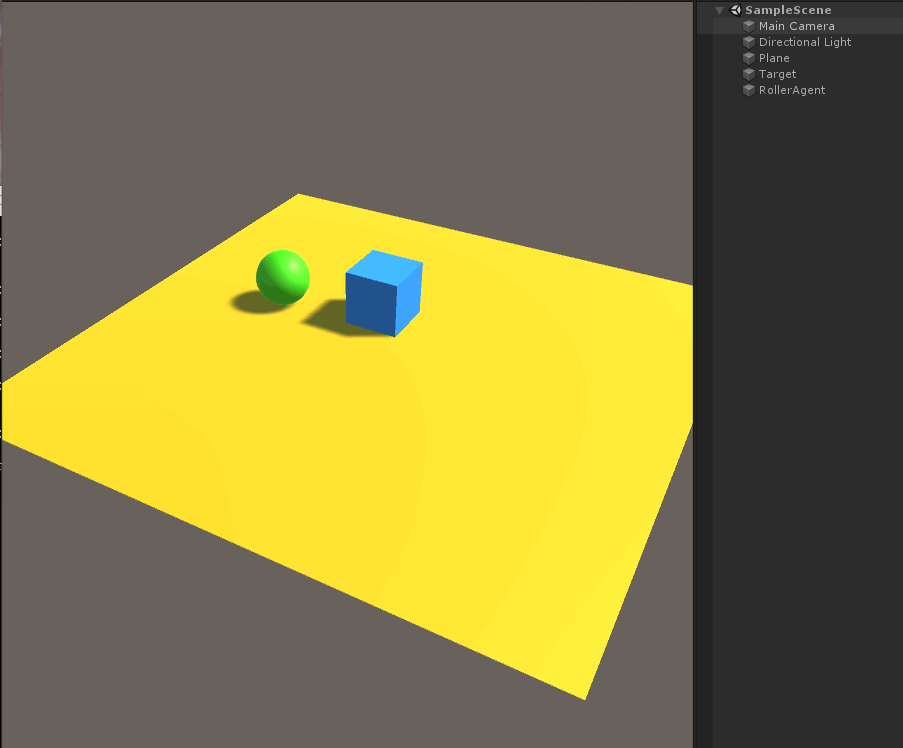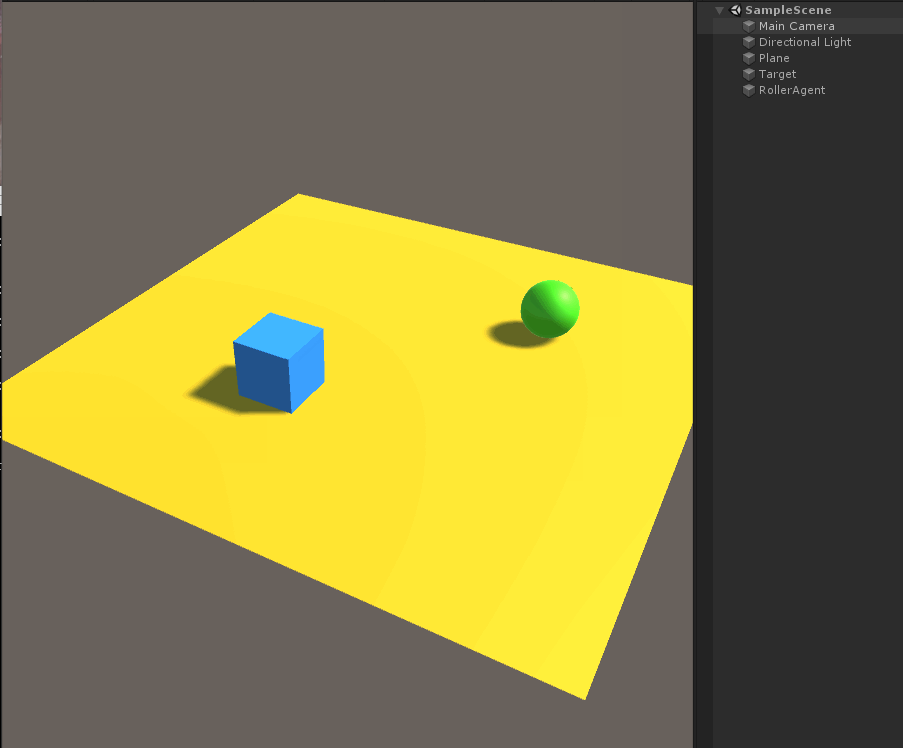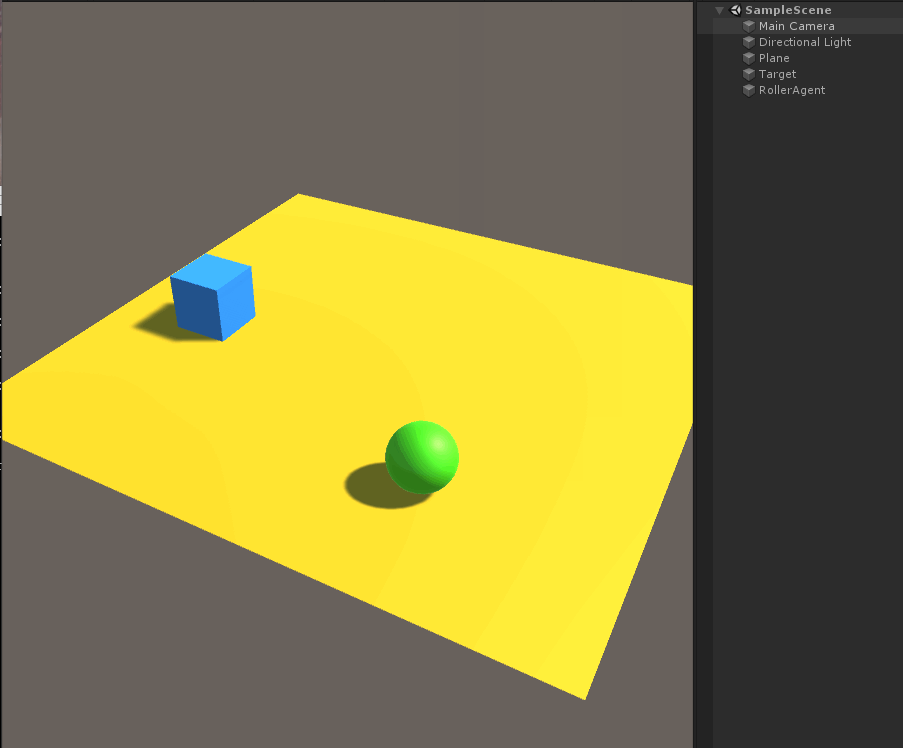
Por encima, el presente ejemplo será entrenado para encontrar una pelota que rueda cubos colocados al azar, sino también para evitar la caída de la Internet.
Este ejemplo se basa en el funcionario ML-Agentes de ejemplo, la versión oficial china y la versión en Inglés de los dos documentos, la versión en Inglés es la última, la mayor parte de la misma versión china y la versión Inglés, pero también son diferentes, este artículo se basa en la última versión hecho (v0.15.0, rama principal), es necesario hacer referencia a la documentación oficial también se pueden comer con referencia a las siguientes direcciones.
Inglés: Https://Github.Com/Unity-Technologies/ml-agents/tree/master/docs
En segundo lugar, una visión general
proyecto en la unidad de LD-Agentes implica los siguientes pasos básicos:
- Crear un entorno para acomodar agente. El medio ambiente puede contener cantidades menores desde el objeto físico es un juego simple o entorno simulado a todo el ecosistema, patrón de entorno se puede variar;
- La realización de las subclases de agentes. define agente subclase el código necesario para el agente utilizado para observar su entorno, ejecutar las acciones especificadas y recompensas de cálculo para el entrenamiento intensivo. También puede aplicar un método alternativo para completar la tarea o tareas para restablecer el agente falla agente;
- subclase agente logrará se añade un script adecuado a la GameObject, cuando el objeto de la escena, significa que el agente correspondiente en el entorno simulado.
( PD. En el documento oficial china, pasos 2 y 3 subclases que poner en práctica la Academia y el cerebro, pero en la nueva versión, estas dos cosas no tienen necesidad de definir en la escena, así que esto es más importante subclase de Agente, aprender lógica básica aquí)
establecer el tercer proyecto, la Unidad
El primer paso, vamos a crear un nuevo proyecto de la Unidad, y el paquete de ML-Agents en él:
Abrir la unidad, crear un nuevo proyecto llamado nombres al azar, tales como "Rollerball";
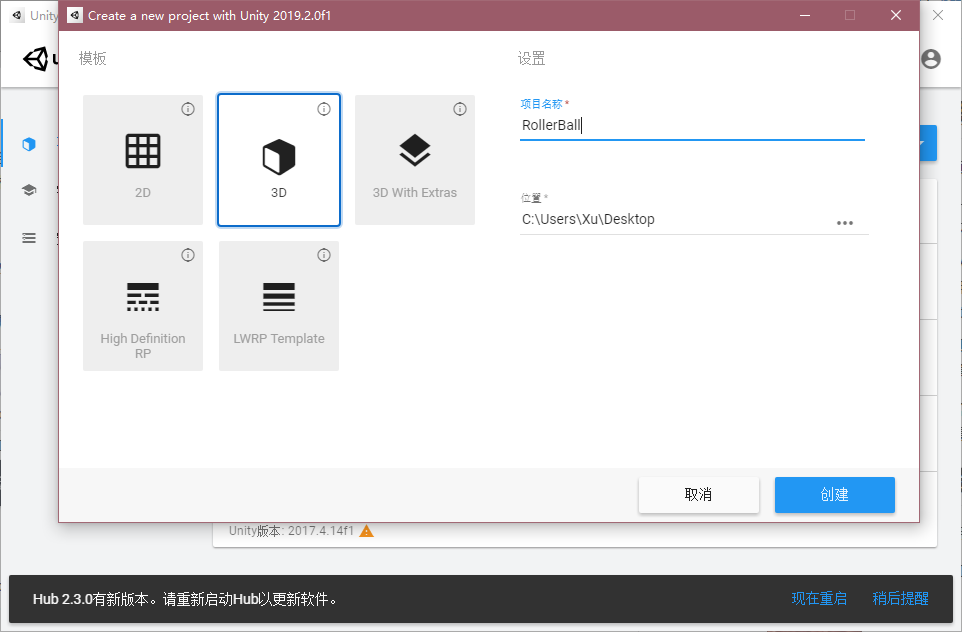
La unidad en el menú "Editar" -> "Configuración del proyecto", en la ventana emergente, encontrar el "Jugador", el "Api Compathbility Nivel" fue cambiado a "NET 4.x", tal como se muestra a continuación;
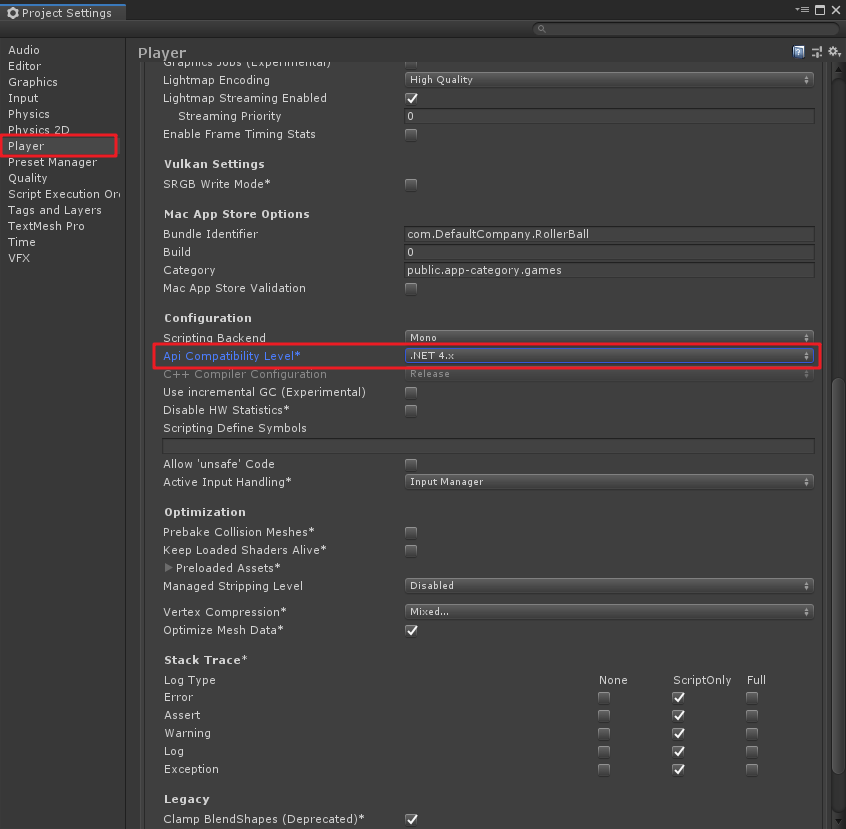
En la sección anterior, tenemos los clones de la biblioteca de código ml-agentes a un local, si no hay un clon, consulte en un "v0.15.0 la unidad de LD-Agents (a) el entorno de despliegue y prueba de funcionamiento" en el cinco por 1 , aquí, se supone que todos estamos ya clonado biblioteca, en la unidad de LD-Agentes necesidad de importar la Unidad enchufable. Aquí está mi versión de Unity2019.2, de la siguiente manera:
- Paquetes carpeta encuentran en el directorio raíz del proyecto;
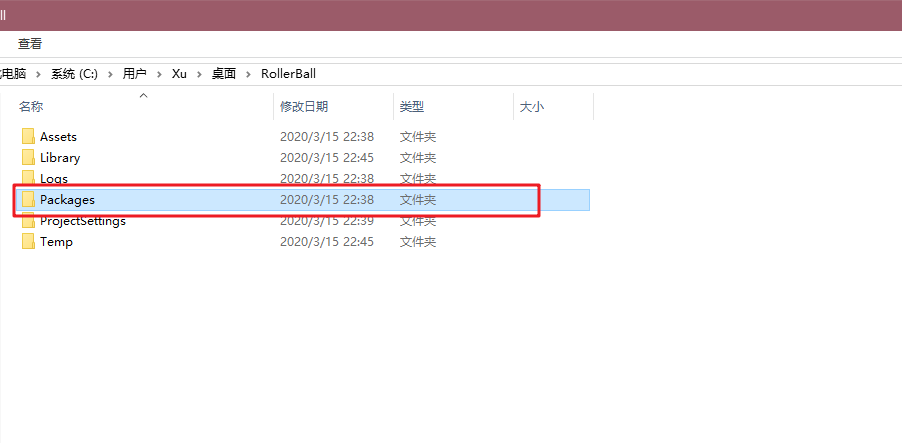
Carpeta tiene un archivo "manifest.json", edición, esta es la colección paquete Los paquetes de ingeniería, añadido al final "com.unity.ml-Agents": " Archivo: D: / de la unidad de los Proyectos / ml-Agentes /com.unity.ml-agents", aquí presentar: después de su propio camino clon ml-agentes de código, oh yo no copio, a menos que este camino - -, como se muestra a continuación;
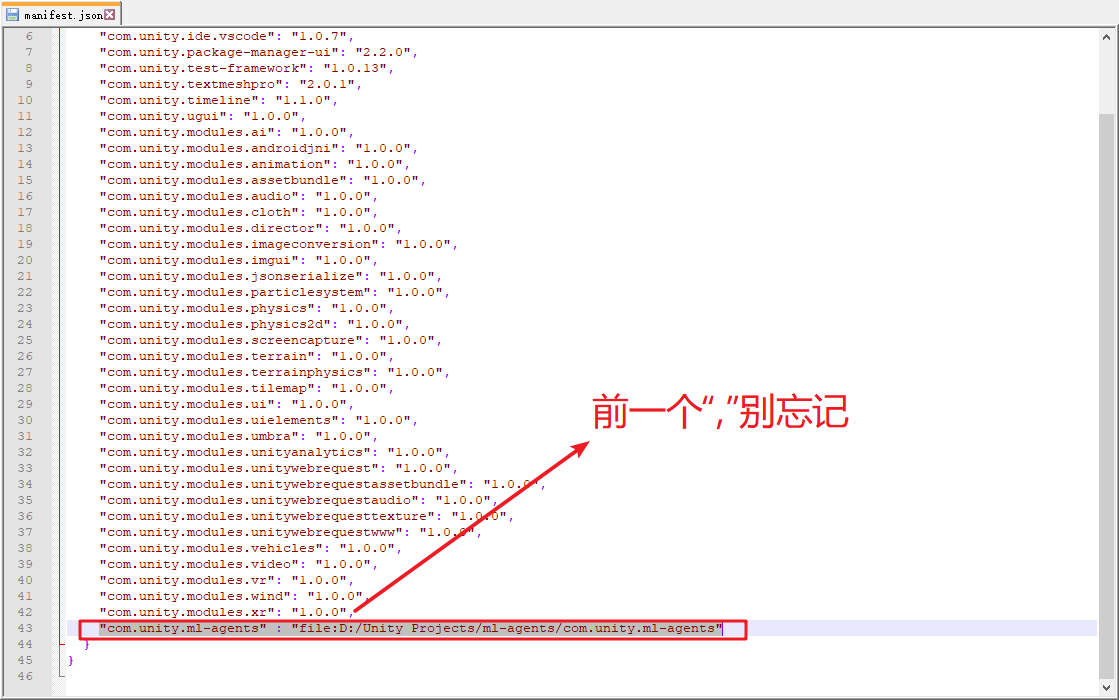
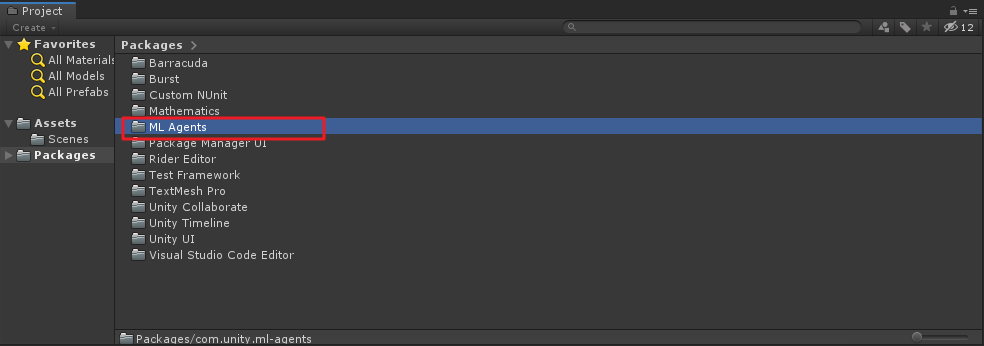
Después de modificar guardado en la unidad de corte, si la ruta es correcta, la pantalla aparecerá paquete de paquete de importación será emergen con éxito "ML Agentes" carpeta en el archivo de paquetes carpeta del proyecto, como se muestra a continuación:
Entorno de creación
A continuación, vamos a crear un entorno sencillo ML-Agent. componentes "física" del entorno incluyen un plano (que actúa como agente de suelo en movimiento), un cubo (que actúa como agente para encontrar la diana) y una esfera (agente representado en sí).
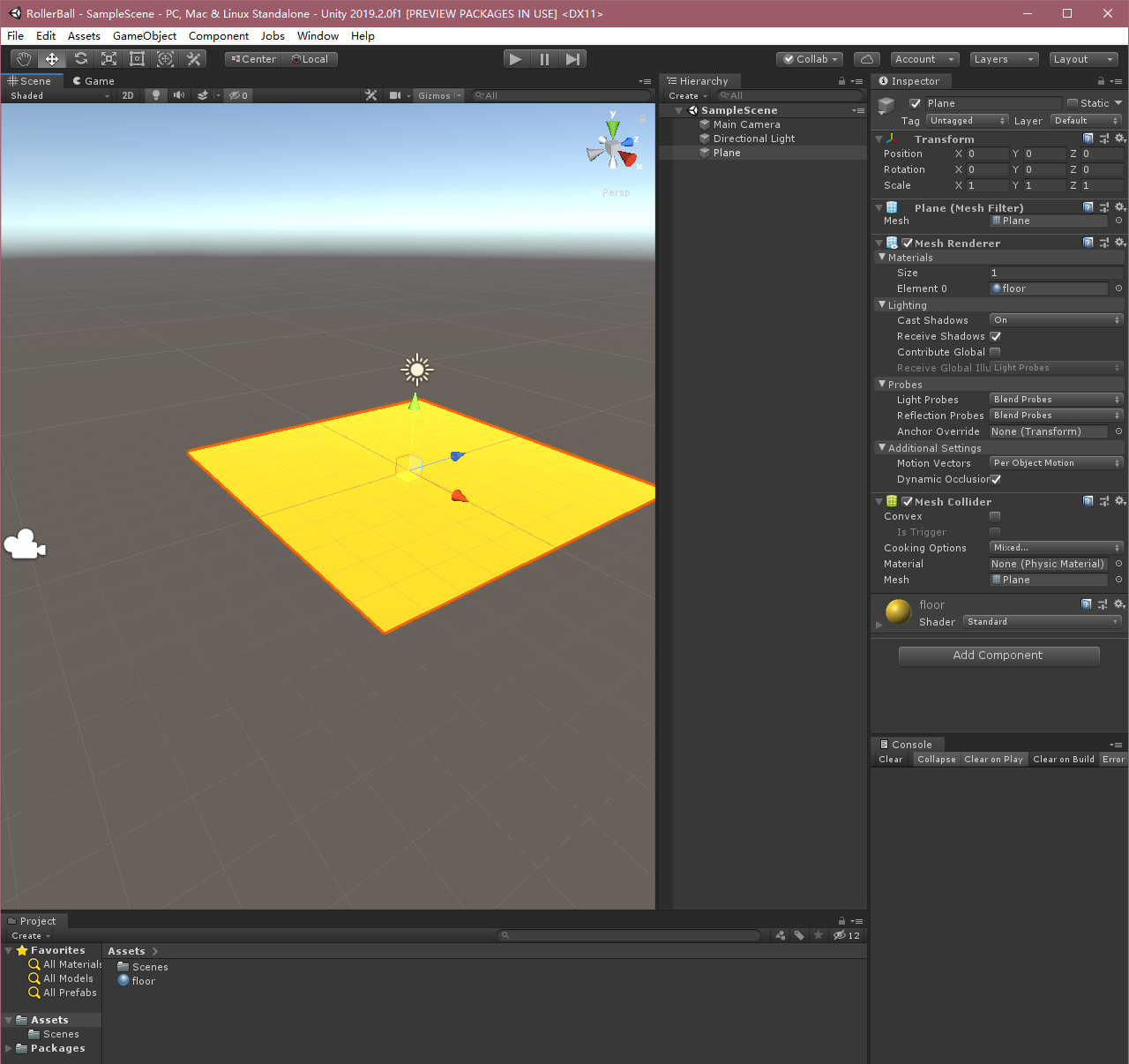
Crear un piso
Haga clic derecho en la ventana de jerarquía, seleccione Objeto 3D> Plane.
El objeto del juego llamado "piso".
Seleccione Plano para ver sus propiedades en la ventana de inspección.
La transformada de la Posición = (0,0,0), Rotación = (0,0,0), Escala = (1,1,1).
Plane modificaciones materiales, variaciones agradable punto.
Copié el proceso anterior son, de hecho, crear un avión, y luego otro buen material en la línea, tienen libertad para definir un OK.
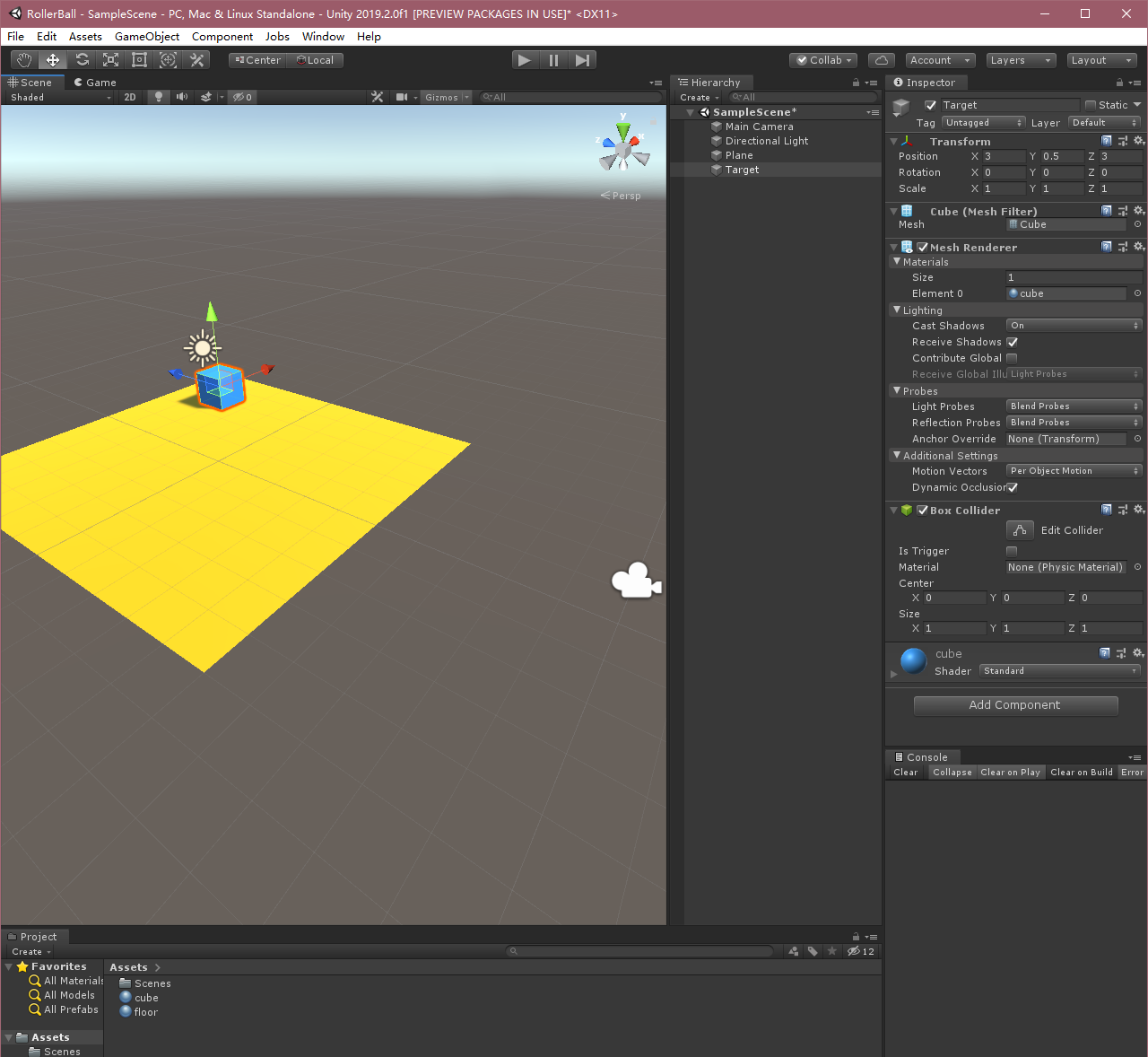
Crear un cubo de destino
En la ventana de jerarquía, haga clic derecho y seleccionar objetos 3D> Cubo.
El objeto del juego llamado "destino"
Seleccionar destino para ver sus propiedades en la ventana de inspección.
La transformada de la Posición = (3,0.5,3), Rotación = (0,0,0), Escala = (1,1,1).
Cubo modificar el material.
Agregar Agente esfera
- Haga clic derecho en la ventana de jerarquía, seleccione Objeto 3D> Esfera.
- El objeto del juego llamado "RollerAgent"
- Seleccionar destino para ver sus propiedades en la ventana de inspección.
- La transformada de la Posición = (0,0.5,0), Rotación = (0,0,0), Escala = (1,1,1).
- Esfera en la malla Renderizador, expanda Propiedades Materiales y cambiar el material por defecto para el Comprobador 1 .
- Haga clic en la opción Agregar el componente .
- Añadir componentes Física / cuerpo rígido a la Esfera. (Añadir cuerpo rígido)
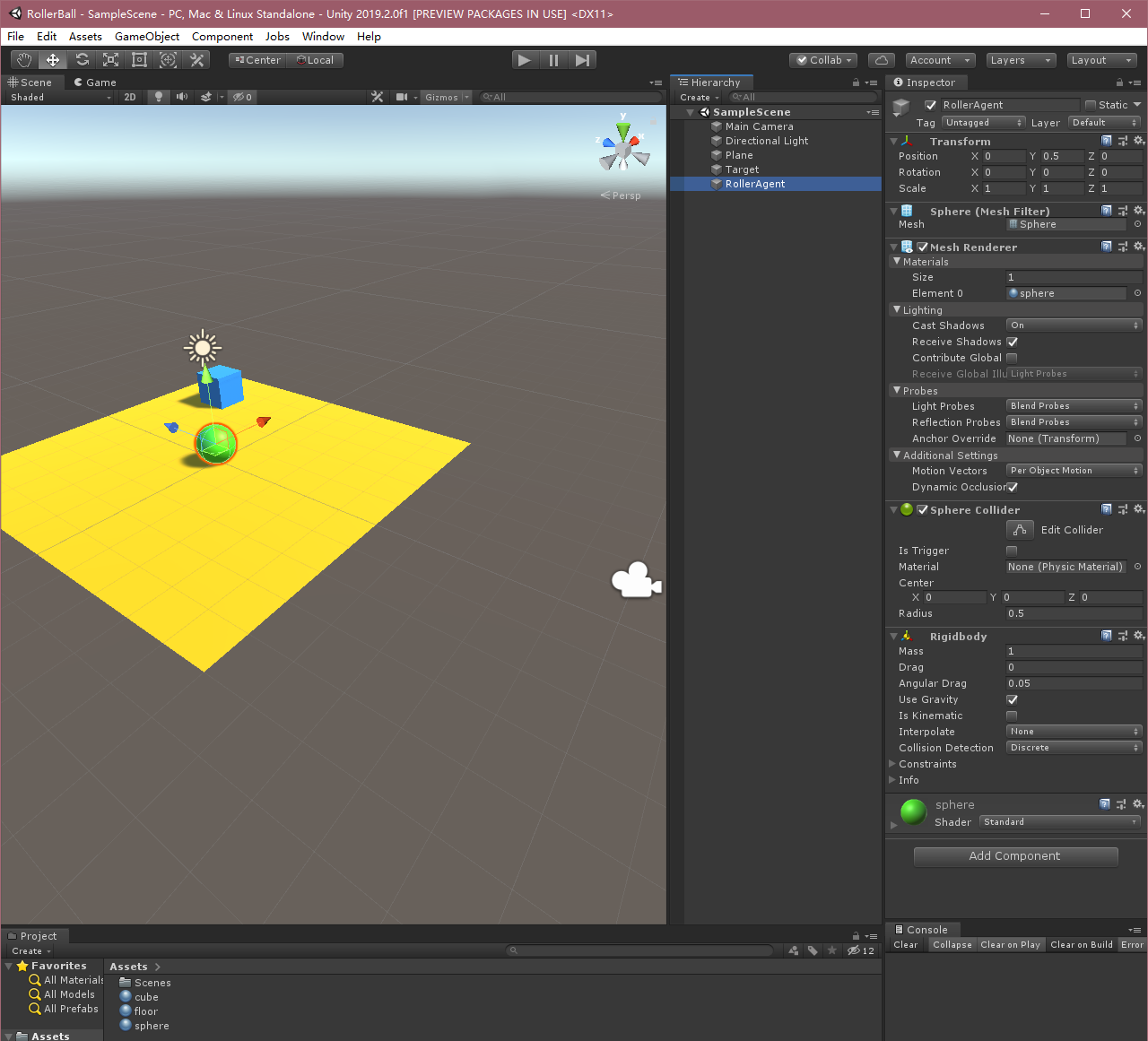
OK, el proceso anterior será en el entorno Unity 3D creado, aquí nos damos cuenta de Agente.
En cuarto lugar, implementar Agente
Y "da cuenta de la Academia" y "añadir cerebro" en los documentos oficiales de China, la última edición ya no es necesario! El agente directamente en la línea.
Para crear un Agente:
- Seleccione RollerAgent juego de objetos con el fin de ver el objeto en la ventana de inspección.
- Haga clic en la opción Agregar el componente .
- En la lista Componentes, haga clic en Nuevo guión (en el fondo).
- El script llamado "RollerAgent".
- Haga clic en la opción Crear y la opción Agregar .
A continuación, editar el nuevo RollerAgentguión:
- Abra la
RollerAgentsecuencia de comandos; - Así
RollerAgentheredadaAgentde clase, mientras que las referenciasusing MLAgentsyusing MLAgents.Sensorsespacio de nombres; - Eliminar
Update()método, para retener elStart()uso después del método.
Hasta el momento, los pasos anteriores son los pasos básicos para añadir ML-Agentes de cualquier proyecto de la Unidad y la necesidad. A continuación, vamos a añadir lógica, nuestro agente puede utilizar el aprendizaje por refuerzo (aprendizaje por refuerzo) el aprendizaje de técnicas para encontrar el cubo.
inicialización agente y reinicio
Cuando el agente (esfera) alcanza la posición de destino (bloque), será propio estado marcado como completa, y la función de restablecimiento agente (Reset) de nuevo se moverá a una nueva ubicación de bloque. Además, si el agente se caiga de la plataforma, se activará la función de reposición, de modo que el agente se inicializa, la posición de destino se actualizará al azar.
Con el fin de restablecer la velocidad del agente (y, posteriormente, aplicar una fuerza para moverlo), necesitamos para referirse a la esfera Rigidbodyde montaje. Este componente puede ser una referencia a escritos Start()método, la lógica anterior, nuestra RollerAgentsecuencia de comandos es la siguiente:
using MLAgents;
using MLAgents.Sensors;
using UnityEngine;
public class RollerAgent : Agent
{
public Transform Target;//方块
public float speed = 10;//小球移动速度
private Rigidbody rBody;//球刚体
private void Start()
{
rBody = GetComponent<Rigidbody>();
}
/// <summary>
/// Agent重置
/// </summary>
public override void AgentReset()
{
if (this.transform.position.y < 0)
{//如果小球掉落,小球初始化
rBody.velocity = Vector3.zero;
rBody.angularVelocity = Vector3.zero;
transform.position = new Vector3(0, 0.5f, 0);
}
//方块位置随机
Target.position = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4);
}
}A continuación, poner en práctica Agent.CollectObservations(VectorSensor sensor)métodos.
Tenga en cuenta que aquí la versión antigua y diferentes métodos, y no antes de la función VectorSensor sensorparámetros, pero el uso de la misma.
Observando el medio ambiente (Observando el Medio Ambiente)
Agente enviará la información que recogemos para Cerebro, utilizar esta información para tomar decisiones por el cerebro. Cuando se entrena - Agente (o modelo ha sido entrenado), los datos como un vector de características de entrada a la red neuronal. Para tener éxito Agente de aprender una tarea, tenemos que proporcionar la información correcta. Una regla empírica buena es considerar lo que hay que utilizar en el análisis de soluciones a los problemas de cálculo.
Aquí es más importante, que está en formación, es necesario tener en cuenta la variable es lo que vamos a ver en la información contenida en este caso tenemos que recoger el agente que:
Posición del objetivo
sensor.AddObservation(Target.position);ubicación agente
sensor.AddObservation(transform.position);la velocidad del agente, lo que ayuda a agente de control de aprender a su propio ritmo, sin hacer más allá del objetivo y rodar de la plataforma
sensor.AddObservation(rBody.velocity.x);sensor.AddObservation(rBody.velocity.z);
Aquí un total de ocho observaciones (una posición de recuento de x, y, z tres valores), entonces necesitará Behavior Parametersser proporcionado en las propiedades del componente, como se muestra a continuación:
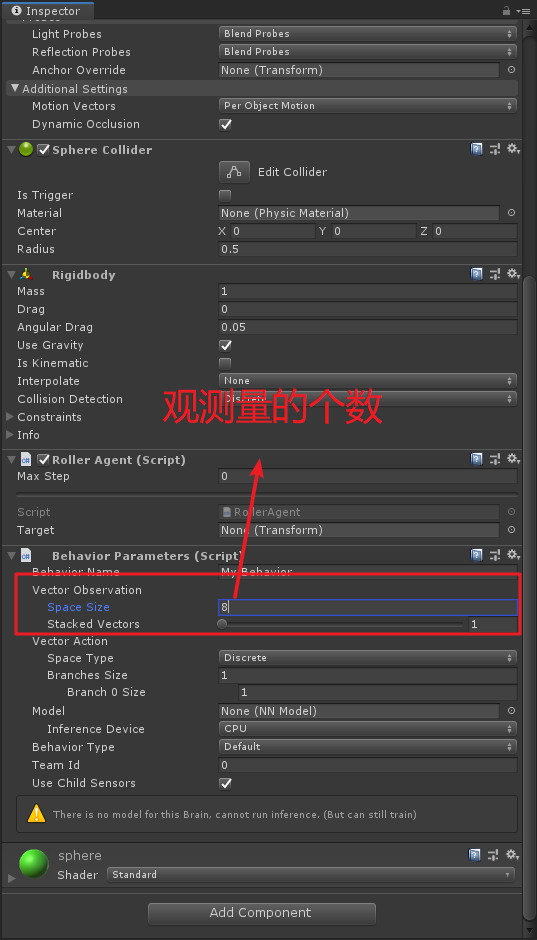
En el documento chino, estos valores se normalizaron, el último documento Inglés y no ser normalizados, acoplado directamente en la línea. Aquí entonces sobrecargado funciones de la siguiente manera:
/// <summary>
/// Agent收集的观察值
/// </summary>
/// <param name="sensor"></param>
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(Target.position);//目标的位置
sensor.AddObservation(transform.position);//小球的位置
sensor.AddObservation(rBody.velocity.x);//小球x方向的速度
sensor.AddObservation(rBody.velocity.z);//小球z方向的速度
}Agente parte final de la Aegnt.AgentAction()función, este método se utiliza principalmente para recibir una decisión de mando y al cerebro Recompensa (recompensa) dependiendo de las circunstancias.
Acción (acciones)
decisiones operación de cerebro en la forma de una matriz de transferencia a la función AgentAction (). Este elemento de la matriz se compone principalmente del agente de cerebro Vector Action, Space Typey Space Sizepara decidir. Aquí representa el espacio vectorial , vector tipo de espacio de movimiento y movimiento espacial vector , ML-Agents Los dos tipos de acciones: Continusous espacio vectorial es un número vector continuamente cambiante puede ser, por ejemplo, un elemento puede ser aplicado a la agente indica una uno Rigidbodyen el interior o el par; Discrete espacio vectorial se define como una mesa de operaciones, el agente proporcionado a la operación específica es el índice de la tabla.
Aquí se utiliza un Continusousmovimiento de espacio vectorial, a punto de Space Typeconjunto continuo, y Space Sizese establece en 2. Esta decisión representa el primer elemento generó usando cerebro action[0]determina la fuerza se aplica a lo largo del eje x, por action[1]la determinación de una fuerza aplicada a lo largo del eje z (si el agente es un movimiento en tres dimensiones, a continuación, Space Sizea conjunto 3). Tenga en cuenta que , en este cerebro no sabe action[]el significado específico de cada valor de la matriz, sólo para ajustar la acción basada en las observaciones introducidas en el proceso de entrenamiento, y luego ver qué tipo de recompensas será. Detallada proporcionada a continuación, también en Behavior Parametersla fijación del precio del grupo:
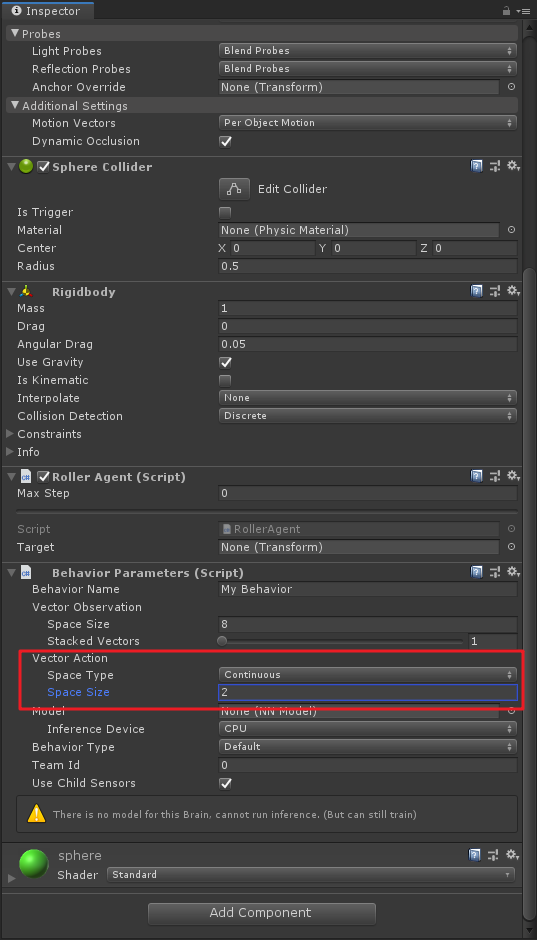
mirada extendida, donde también se puede utilizar el tipo discreto de entrenamiento, pero el correspondiente Space Sizese convertirá en 4 porque hay cuatro direcciones tienen que controlar.
OK, el código de operación descrito anteriormente es como sigue:
//Space Type=Continuous Space Size=2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];//x轴方向力
controlSignal.z = vectorAction[1];//z轴方向力
//当然上面这两句可以互换,因为Brain并不知道action[]数组中数值具体含义
rBody.AddForce(controlSignal * speed);Recompensas (recompensas)
Refuerzo de aprendizaje (aprendizaje por refuerzo) incentivos necesidad. Del mismo modo recompensa (penalización) también AgentAction()funcionan para conseguir, junto con la operación de reescritura para lograr la función anterior. Algoritmo de aprendizaje utilizado en cada paso de la simulación del proceso de aprendizaje y se asigna a los incentivos del agente para determinar si se debe proporcionar la mejor acción para el agente. Cuando el agente para completar la tarea, se recompensa. En este ejemplo, si el agente (la bola) alcanzó la ubicación de destino (bloque), luego darle un bono de 1 punto.
RollerAgent calcula la distancia necesaria para alcanzar el objetivo cuando se alcanza el objetivo, podemos Agent.SetReward()agente marcado la finalización del método en términos de recompensa y darle 1 punto, mientras que utilizando Done()el método para restablecer el medio ambiente.
//计算自身与目标的距离
float distanceToTarget = Vector3.Distance(transform.position,Target.position);
//不同情况进行奖励
if (distanceToTarget < 1.42f)
{//到达目标附近
SetReward(1);
Done();
}Por último, si la plataforma caer la pelota, dejando reinicio agente. No hay un conjunto castigo, botas interesados niño puede tratar de establecer su propio castigo.
if (transform.position.y < 0)
{//小球掉落
//SetReward(-1); 惩罚先不设置
Done();
}AgentAction método ()
OK, por lo anterior acción y recompensa constituir AgentAction método (), que es principalmente de entender el significado de cada paso es por qué, último AgentAction()método es el siguiente:
public override void AgentAction(float[] vectorAction)
{
//Space Type=Continuous Space Size=2
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];//x轴方向力
controlSignal.z = vectorAction[1];//z轴方向力
//当然上面这两句可以互换,因为Brain并不知道action[]数组中数值具体含义
rBody.AddForce(controlSignal * speed);
//计算自身与目标的距离
float distanceToTarget = Vector3.Distance(transform.position, Target.position);
//不同情况进行奖励
if (distanceToTarget < 1.42f)
{//到达目标附近
SetReward(1);
Done();
}
if (transform.position.y < 0)
{//小球掉落
Done();
}
}El Editor de conjunto final
En este punto, todos los objetos del juego y componentes ML-Agent están listos, entonces tenemos que añadir un poco de secuencia de comandos en el escenario de la pelota, modificar algunas propiedades.
Seleccione la escena RollerAgent bola, primero añadir el
Behavior Parametersguión, y ponerlosSpace Sizea 8 ,Space Typecomo la continua ,Space Sizees 2 . Si este paso hasta hace pocos años ha sido la de levantarse, usted no tiene control. Pero no existeBehavior Name, esta propiedad debe ser el nombre distinguido del cerebro, la nueva versión tiene el mismo múltiplo Agente cerebro, se debe distinguir aquí, yo personalmente creo que sí, si no es incorrecto, por favor me corrija;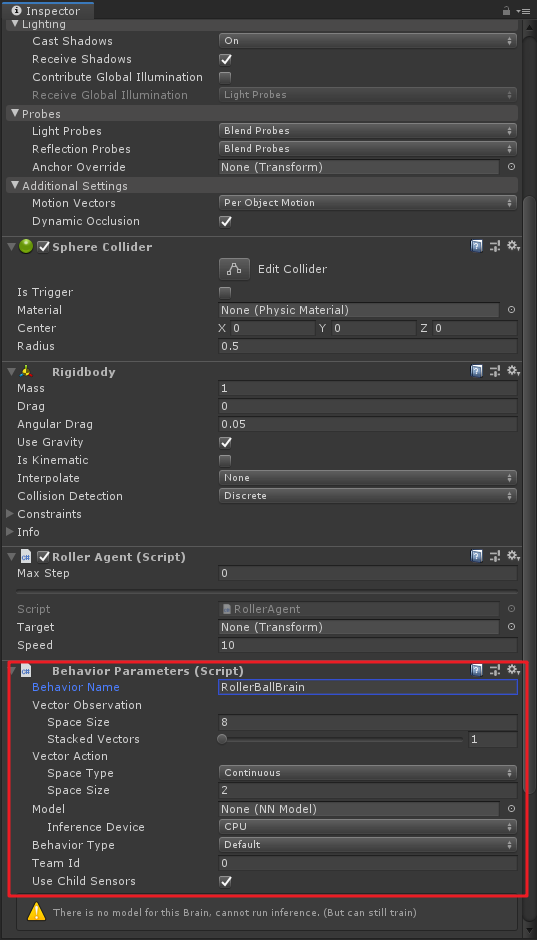
Este paso debe recordar que no hay versión antigua, es necesario agregar
Decision Requestercomponentes, yDecision Periodcambiaron a 10! documentación de Inglés está escrito aquí mucho, si no añadir este script, la bola no se mueve hacia arriba.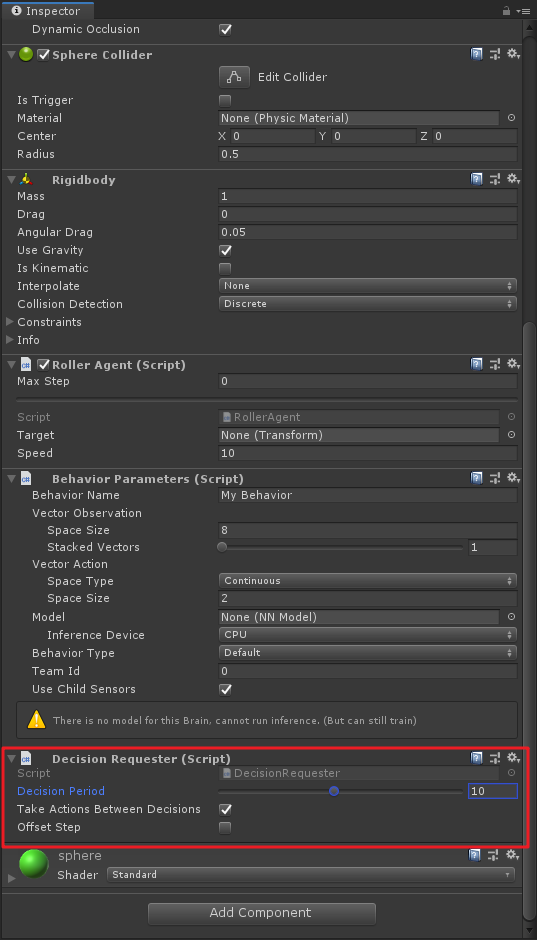
entorno de pruebas manuales
Antes de iniciar un manual de formación a lo largo probar el entorno de prueba es un enfoque sensato. Para las pruebas manuales, tenemos que Roller Agentañadir un guión Heuristic()método, con el fin de sustituir las decisiones del cerebro, de la siguiente manera:
/// <summary>
/// 手动测试
/// </summary>
/// <returns></returns>
public override float[] Heuristic()
{
var action = new float[2];
action[0] = Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}De hecho, esta es la acción [] matriz de modo que el agente asignado a la acción a través del espacio de acción del teclado.
Entonces también se necesita Behavior Parametersen la asamblea Behavior Typea Heuristic Only, lo siguiente:

Esta vez podemos ejecutarlo, (de repente se encontró Rollerel Targer olvídese se prolongaba, los objetivos cuadrados arrastran venir), entonces se puede utilizar WSAD o arriba y abajo para controlar el balón, y cerca de la caja, la caja será automáticamente re-set, si descenso de la bola, será re-establecido.
OK, hemos Behavior Typecambiado de nuevo Default, listo para comenzar el entrenamiento del ~
En quinto lugar, la formación
Abrir Anaconda3, encontramos construida antes de ambiente de entrenamiento, se inicia "Terminal".

ml-agente cd al directorio raíz, por ejemplo, mi camino:
cd /d D:\Unity Projects\ml-agents
Aquí para chip, modificamos archivo de configuración ml-agentes, localice ml-agentsla configcarpeta, y abra el trainer_config.yamlarchivo de configuración, añadimos la última frase
RollerBallBrain:
batch_size: 10
buffer_size: 100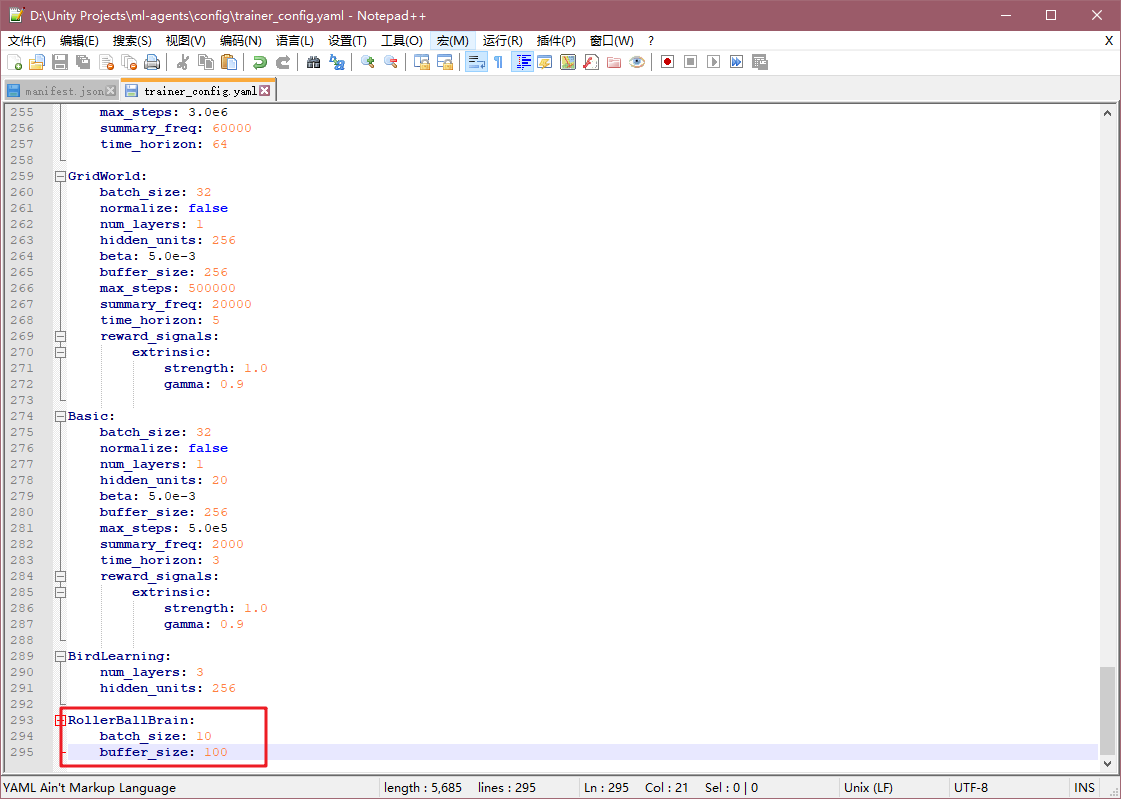
Aquí se puede ver RollerBallBrain hecho, sólo estaba Behavior Parametersfijando componentes Behavior Name. Aquí modificar estos dos parámetros anularán las entradas del archivo de configuración por defecto más importante default, estos dos valores de los parámetros de modificación ultra pequeños pueden facilitar una formación más rápida, si los parámetros originales (batch_size: 1024, BUFFER_SIZE: 10240 ), necesitan ser entrenados alrededor de 300.000 pasos , pero sólo menos de 20.000 pasos modificado. Se debe basarse en parámetros específicos del proyecto-específicas.
Después de terminar la configuración, de vuelta a la línea de comandos, escriba:
mlagents-learn config/trainer_config.yaml --run-id=RollerBall-1 --train
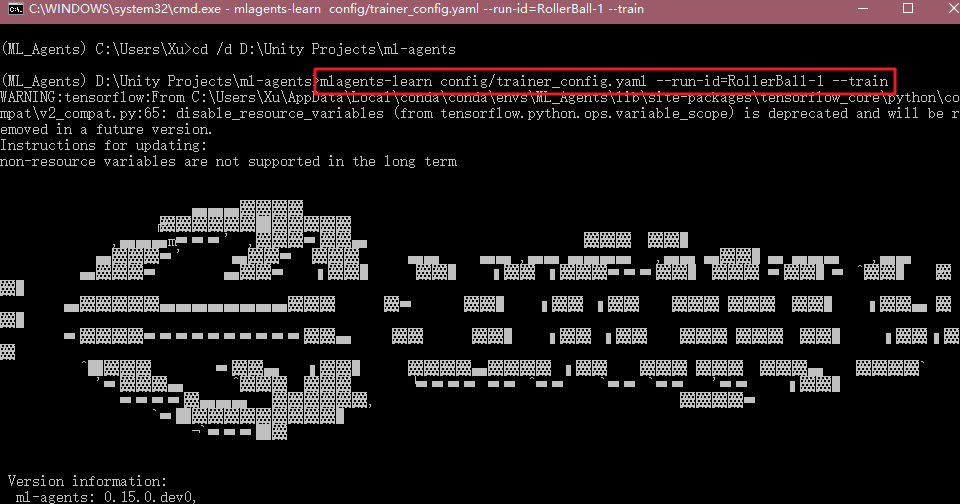
La unidad se está ejecutando el programa.
Si la Unidad de formación y de Anaconda comunicación exitosa, se encuentra la configuración de la línea de comandos de su formación:
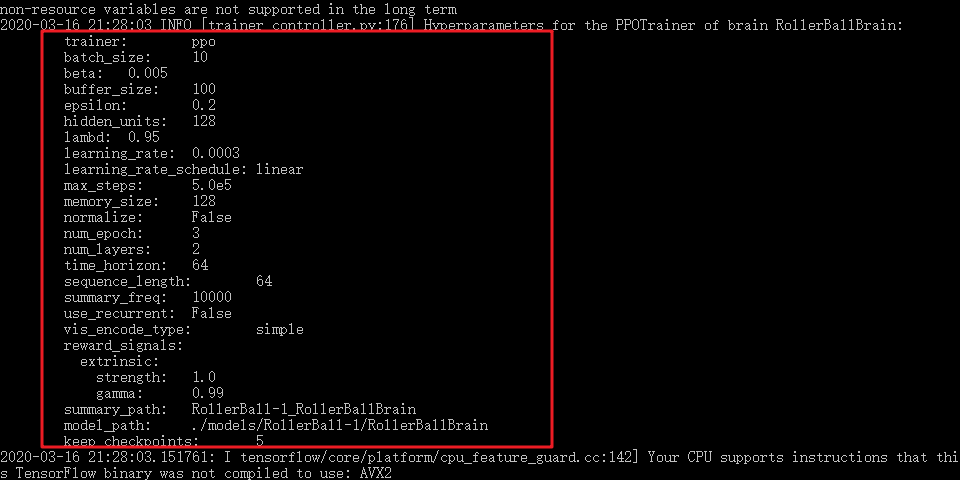
Al mismo tiempo, se puede ver la unidad para iniciar su propio movimiento de la bola rápida pequeña, la caja se generará aleatoriamente según los diferentes estados.
Con el tiempo, la línea de comando mostrará el número correspondiente paso de ejecución, el tiempo transcurrido, premios promedio y otra información.
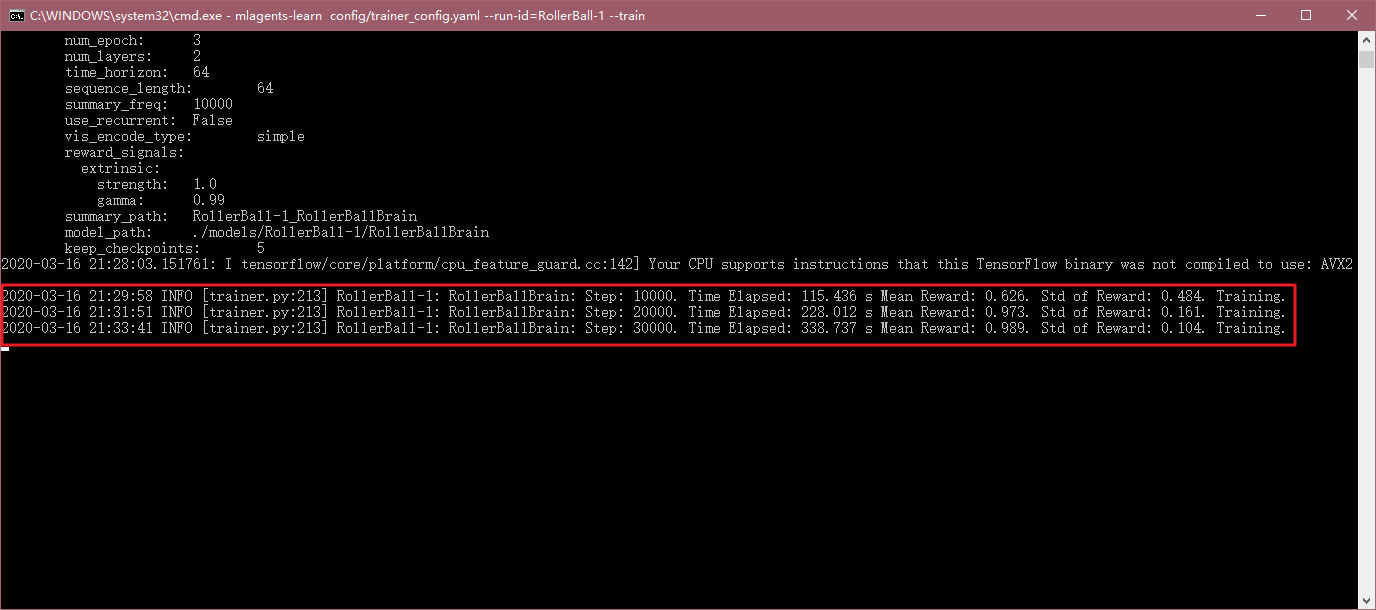
A medida que el entrenamiento progresa, se encuentra una pequeña bola difícil de caer de la plataforma, y ha seguido la posición de la caja:

Por último, la formación de tiempo es demasiado largo, puede configurar el archivo mediante max_stepsla modificación del entrenamiento paso más grande, por lo que estoy aquí directamente Ctrl + C, por lo que el modelo de formación sobrevivirá.
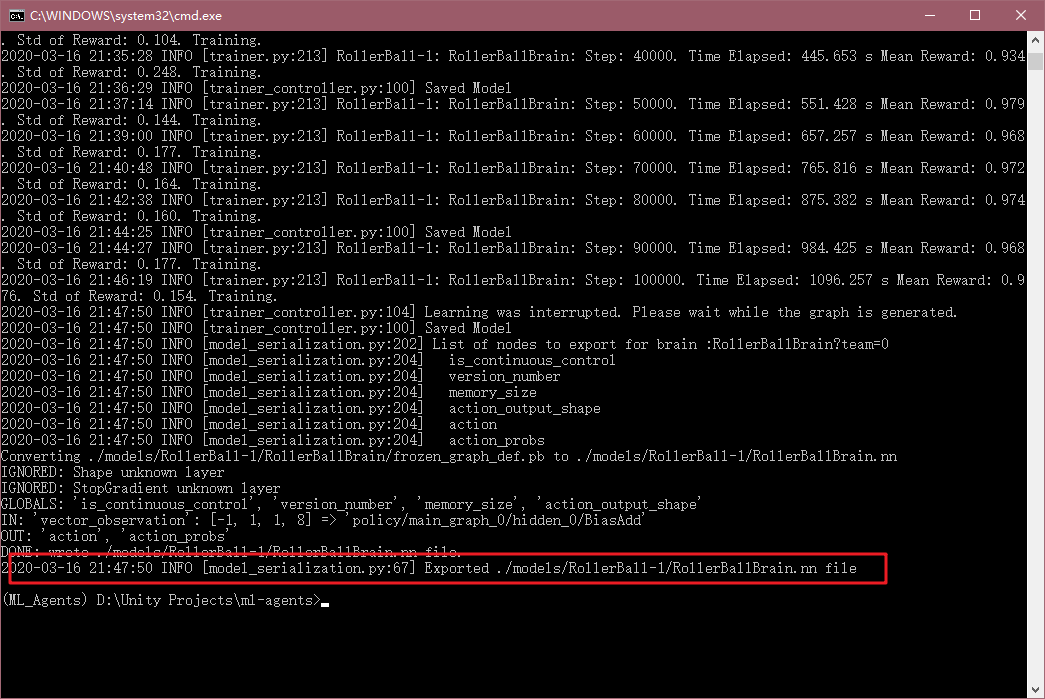
Encuentra este RolerBallBrain.nnarchivo, el ML-agente de la modelscarpeta, este documento admitido .nn Unidad de la siguiente manera:
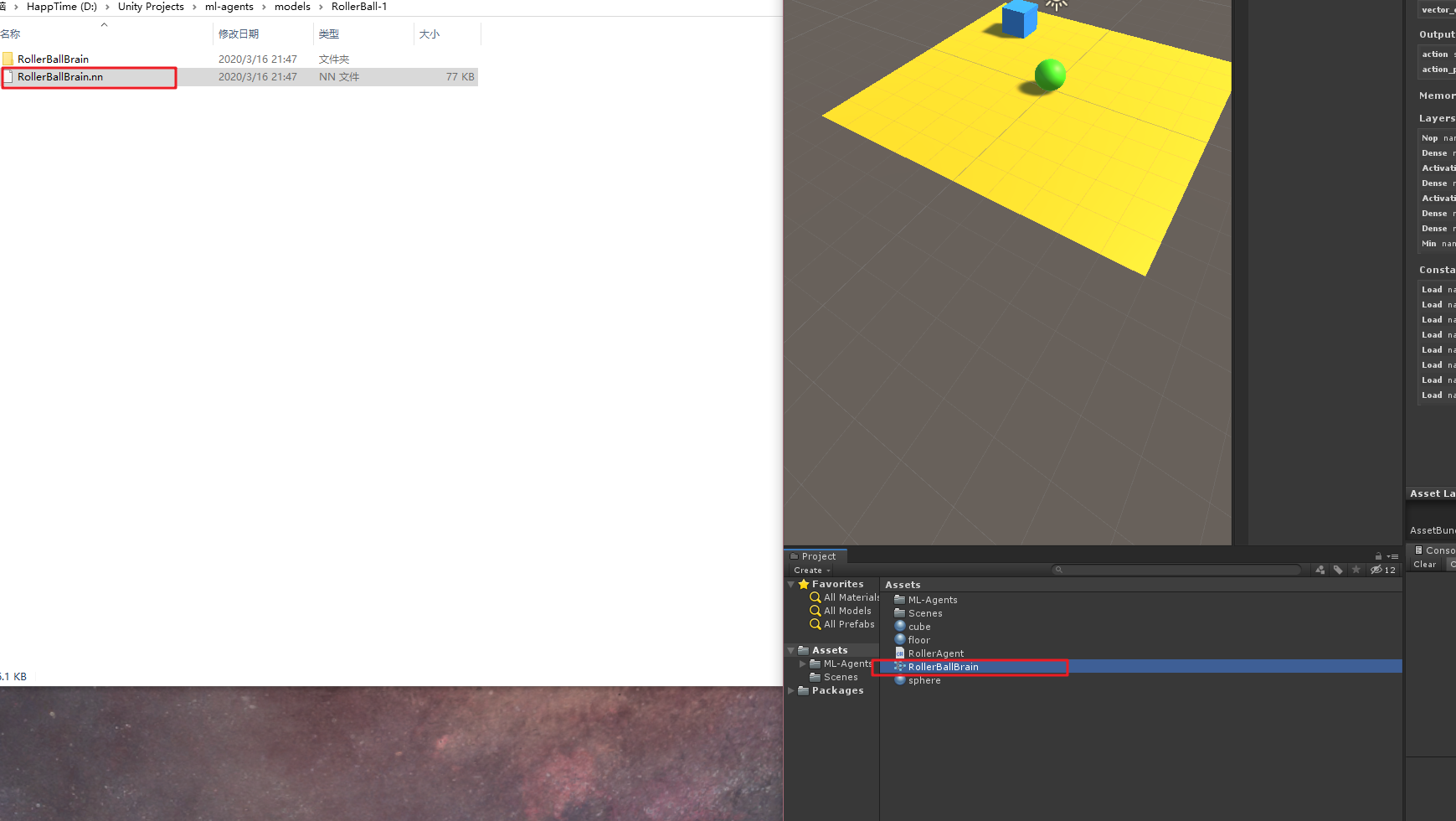
A continuación, seleccione la pelota escena, los Behavior Parameterscomponentes Modelde propiedades, seleccione sólo los modelos de formación, y Behavior Typeelegidos Inference Only, de la siguiente manera:
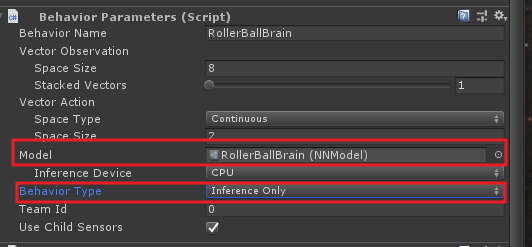
A continuación, haga clic en la carrera, se puede ver la pelota buen uso de nuestro modelo de formación comenzó a encontrar la caja.
estadísticas TensorBoard
Nosotros, en la línea de comandos, también se puede encontrar información de la carta sólo la formación, introduzca la línea de comandos:
tensorboard --logdir=summaries

A continuación, la dirección para abrir el navegador, por lo generalhttp://localhost:6006/
Como se puede ver el número de la formación de cada valor de cambio de paso de valor.
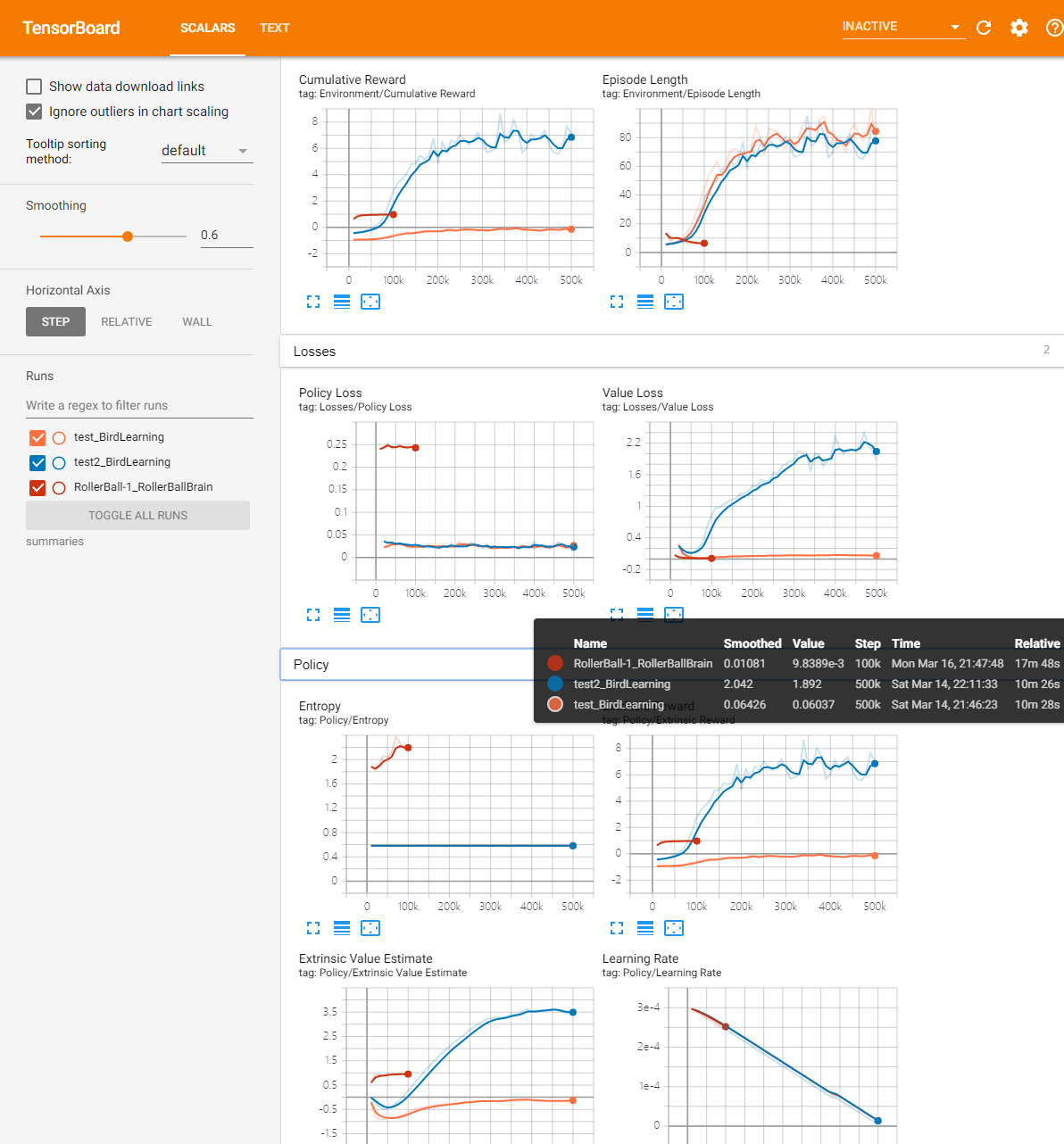
El significado de un valor, copiar algún documento oficial chino:
Lección - sólo durante el curso de formación] es significativa.
Recompensa acumulada - la recompensa media acumulada para todos agente de escenarios. Durante una capacitación exitosa debe ser aumentado.
Entropía - un grado aleatoria de modelo de toma de decisiones. proceso de formación exitosa debe disminuir lentamente. Si disminuye demasiado rápido, aumentar los
betaparámetros de super.Episodio Longitud - la duración media de la totalidad del agente en el entorno de cada escena.
El aprendizaje de la tarifa - requieren mucho algoritmos de entrenamiento en la búsqueda de las medidas de política óptima. Con el tiempo se debe reducir.
Pérdida Política - actualizaciones promedio característica de directiva de pérdida. El grado de la política (proceso de acción de decisión) y el cambio relacionado. El éxito de esta magnitud durante el entrenamiento debe ser reducida.
Valor estimado - el valor medio de todos los estados de la visita agente de estimaciones. Durante una capacitación exitosa debe ser aumentado.
La pérdida de valor - valor medio pérdida de actualizaciones de funciones. Asociado a la capacidad del modelo para predecir el valor de cada estado. Este éxito se debe reducir durante el entrenamiento.
Aceptar, por encima de ella es un pequeño ejemplo de todo el proceso de la formación oficial.
El registro también agotador, pero la bienvenida para discutir el mensaje, que se reproduce, por favor indique la dirección original problemas Oh, gracias ~
citar:
https://github.com/Unity-Technologies/ml-agents/tree/master/docs