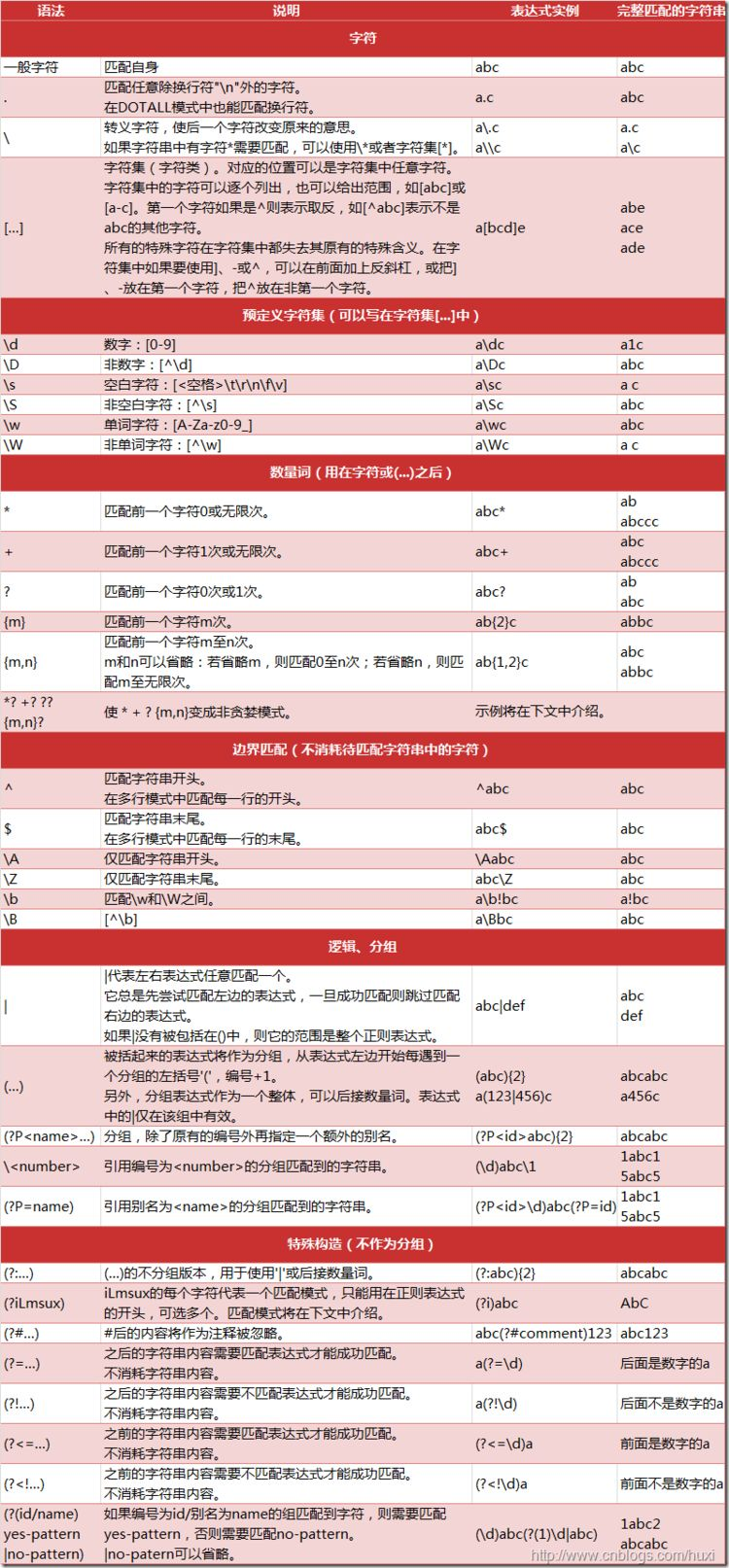
caracteres especiales de expresiones regulares de Python
| carácter | descripción |
| \ | El siguiente carácter está marcado como un carácter especial o un carácter literal, o una referencia hacia atrás, o un escape octal. Por ejemplo, 'n' coincide con el carácter "n". '\ N' coincide con una nueva línea. Secuencia '\\' partidos "\" y \ "(" Partido "(". |
| ^ | Coincide con el comienzo de la cadena. Si el objeto se establece la propiedad Multiline RegExp, también partidos 'n \' ^ posición después o '\ r'. |
| PS | Coincide con el extremo de entrada de la cadena. Si el objeto se establece la propiedad Multiline RegExp, $ también coincide con la posición antes de la '\ n' o '\ r'. |
| * | Coincide con el cero subexpresión precedente o más veces. Por ejemplo, una zo partidos * "z" y "zoo". * Es equivalente a {0}. |
| + | Coincide con la subexpresión precedente o más veces. Por ejemplo, 'zo +' coincidirá con "zo" y "zoo", pero no puede coincidir con la "z". + Es equivalente a {1}. |
| ? | Coincide con la subexpresión precedente cero o uno. Por ejemplo, "hacer (es)?" Coincide con "hacer" o "sí" en el "hacer". ? Es equivalente a {0,1}. |
| {norte} | n es un entero no negativo. Coincidencia de los tiempos n determinados. Por ejemplo, 'o {2}' no coincide con el "Bob" en la 'o', pero puede coincidir con el "alimento" de las dos juntas. |
| {norte,} | n es un entero no negativo. Coincidencia de al menos n veces. Por ejemplo, 'o {2,}' no coincide con el "Bob" en la 'o', pero puede coincidir con todos o "cooooomida" en. 'O {1,}' es equivalente a 'o +'. 'O {0,}' es equivalente a 'O *'. |
| {Nuevo Méjico} | m y n son números enteros no negativos, en los que n <= m. Al menos n veces y la altura de m veces. Por ejemplo, "o {1,3}" encuentra "cooooomida" en los tres o anterior. 'O {0,1}' es equivalente a 'o?'. Tenga en cuenta que no hay espacios entre la coma y los dos números. |
| ? | Cuando el carácter inmediatamente a cualquier otro calificador (*, +,?, {N}, {n,}, {n, m}) cuando el patrón de coincidencia trasera, no expansivo. partidos no codiciosos patrón lo menos posible la cadena de búsqueda, y las coincidencias de patrones codiciosos por defecto como gran parte de la cadena de búsqueda. Por ejemplo, la cadena "oooo", 'O +?' Coincide con una sola "o", y 'O +' coincidirá con todo 'o'. |
| . | Coincide con cualquier carácter excepto "\ n" es. Para que coincida incluyen '\ n', incluyendo cualquier carácter, como el uso de '[. \ N]' modo. |
| (modelo) | Coincida con el patrón y obtener la tonalidad. El juego se puede obtener de los Partidos se han utilizado en subcoincidencias recogida de VBScript, JScript se utiliza en los $ 0 ... $ 9 propiedades. Para que coincida con los caracteres de paréntesis, usa '\ (' o '\)'. |
| (?:modelo) | Pero no a los resultados de adquirir la coincidencia de patrones coincidentes, que este es un partido de no acceso, no se almacena para su uso posterior. Este uso de "o" carácter (|) para combinar las diversas partes de un modelo es útil. Por ejemplo, 'industr (?: Y | s) es una relación de' la industria | expresiones más breves industrias. |
| (? = Patrón) | Positivo-investigación previa, coincidente con la cadena de búsqueda en el comienzo de cualquier cadena perfil de compatibilidad. Este es un partido de no acceso, es decir, el partido no necesita obtener para su uso posterior. Por ejemplo, 'de Windows (= 95 |? 98 | NT | 2000)' puede coincidir con el "Windows 2000" en el "Windows", pero no puede coincidir con el "Windows 3.1" "Windows". Pre-registro no consume caracteres, que es, después se produce una coincidencia, el último partido después de que el siguiente partido para iniciar la búsqueda de inmediato, en lugar de a partir de los caracteres que contiene previa a la investigación. |
| (?!modelo) | Negativa previa a la investigación, al comienzo de cualquier cadena de búsqueda cadena coincidente perfil de compatibilidad. Este es un partido de no acceso, es decir, el partido no necesita obtener para su uso posterior. Por ejemplo 'de Windows (95 | ?! 98 | NT | 2000)' puede coincidir con el "Windows 3.1" "Windows", pero no puede coincidir con el "Windows 2000" en el "Windows". Pre-registro no consume caracteres, es decir, después de que ocurra un partido, después del último partido comenzó de inmediato búsqueda siguiente partido, en lugar de a partir de los caracteres que contiene previa a la investigación |
| x|y | Partido x o y. Por ejemplo, 'z | alimentos' puede coincidir con la "z" o "comida". '(Z | f) ood' el partido "Zood" o "comida". |
| [Xyz] | Conjunto de caracteres. Coincide con cualquier carácter incluido. Por ejemplo, '[abc]' coincide con "simple" en el 'a'. |
| [^ Xyz] | juegos de caracteres negativos. Coincide con cualquier carácter no incluido. Por ejemplo, '[^ abc]' coincide con "simple" la 'p'. |
| [Arizona] | Rango de caracteres. Coincide con cualquier carácter dentro del rango especificado. Por ejemplo, '[az]' partido 'a' 'z' a cualquier minúsculas caracteres alfabéticos dentro del alcance. |
| [^ Az] | gama carácter negativo. Coincide con cualquier carácter no en cualquier rango especificado. Por ejemplo, '[^ az]' no puede coincidir con cualquier 'a' a un carácter arbitrario 'z' dentro del alcance. |
| \si | Coincide con un límite de palabra, es decir, se refiere a la ubicación y los espacios entre las palabras. Por ejemplo, 'er \ b' partidos "nunca" en el 'ER', pero no coincide con el "verbo" en el 'er'. |
| \SI | Coincidencia de límite de palabra. 'Er \ B' partidos "verbales" en el 'ER', pero no coincide con el "no" en el 'er'. |
| \ cx | Coincidir con los caracteres de control especificados por el x. Por ejemplo, \ cm coincide con un Control-M o retorno de carro. El valor de x debe ser AZ o az. De lo contrario, c como un carácter literal 'c'. |
| \re | Coincide con un carácter dígitos. Equivalente a [0-9]. |
| \RE | Que coinciden con un carácter no numérico. Es equivalente a [^ 0-9]. |
| \F | Coincidir con un carácter de avance. Equivalente a \ x0c y \ cl. |
| \norte | Coincide con un carácter de nueva línea. Equivalente a \ x0a y \ cJ. |
| \ r | Coincidencia de un retorno de carro. Equivalente a \ x0d y \ cm. |
| \ s | Coincide con cualquier espacio en blanco, incluidos los espacios, tabulaciones, saltos de página, y así sucesivamente. Es equivalente a [\ f \ n \ r \ t \ v]. |
| \ S | Coincide con cualquier carácter no está en blanco. Es equivalente a [^ \ f \ n \ r \ t \ v]. |
| \ t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
举例:
字符串: s="adsfasdf1230adsf+123adsf123.33adsf-123.66asdg+344.66"
匹配数字、小数点数字、包含正负号数字;
a=re.findall('-?\d+\.*\d+|\+?\d+\.*\d+',s)
a=['1230', '+123', '123.33', '-123.66', '+344.66']
匹配数字、小数点数字、包含正号;
a=re.findall('\+?\d+\.*\d+',s)
a=['1230', '+123', '123.33', '123.66', '+344.66']
匹配数字、小数点数字、包含负号;
a=re.findall('-?\d+\.*\d+',s)
a=['1230', '123', '123.33', '-123.66', '344.66']