Las grandes preguntas del plano de datos +
una cara HDFS: preguntas
1. proceso de escritura HDFS
1) el módulo cliente solicitudes de los archivos de carga FileSystem distribuido a NameNode, cheque NameNode si el archivo de destino ya existe, existe el directorio padre.
2) la devolución NameNode si se puede cargar.
3) Las primeras solicitudes de los clientes de bloque en varias DataNode a cargar en el servidor.
4) NameNode devuelve tres nodos DataNode, respectivamente, DN1, DN2, DN3.
5) El cliente solicita DN1 carga de datos a través del módulo FSDataOutputStream, la recepción de la solicitud dn1 continuarán llamar dn2, entonces dn2 DN3 llamada, establecerá la tubería de comunicación se ha completado.
6) DN1, DN2, paso a paso DN3 por los clientes de respuesta.
7) el cliente comienza a subir dn1 primer bloque (a partir de las lecturas del disco de datos en una memoria caché local) a las unidades de paquetes, paquetes dn1 recibirán un pase dn2, dn2 DN3 pasado; dn1 cada pasar un paquete lugares una cola de respuestas en espera de una respuesta.
8) Después de una transferencia en bloque se ha completado, el cliente solicita una vez más subidos NameNode Bloque segundo servidor. (Repita los pasos 3-7).
2.HDFS leer flujo de datos
1) el cliente a través de la petición de sistema de archivos distribuido NameNode para descargar un archivo, NameNode mediante la consulta de metadatos, para encontrar el bloque de direcciones DataNode archivo se encuentra.
2) selección de un DataNodes (principio de proximidad, a continuación, el servidor al azar), una petición de lectura de datos.
3) DataNode comienza a transmitir datos al cliente (leer datos de un disco en el interior del flujo de entrada, hacer unidades de calibración de paquetes).
4) a clientes de recepción de paquetes de unidades, la primera en la memoria caché local, y luego escribe en el archivo de destino.
¿En qué circunstancias no 3.datenode copia de seguridad de
la configuración de copia de seguridad es el número 1, no será respaldado.
Establecer el número de copias de seguridad en el uso de la extensión -Hadoop dónde, en qué campo?
Dfs.replication variables de hdfs-site.xml en.
problemas causados por un gran número de pequeñas 4.HDFS archivos, así como soluciones al
problema:
directorio de Hadoop, el archivo se guardará en forma de bloques y objetos en la memoria de NameNode acerca de cada objeto ocupará más de 150bytes número de archivos pequeños va a ser mucho. NameNode ocupado memoria; metadatos lectura NameNode tan lento, puesta en marcha prolongada; memoria para más, porque es demasiado grande, lo que resulta en un tiempo de subida de GC.
La solución:
dos ángulos, uno de abordar las causas profundas producen archivos pequeños, y en segundo lugar, no se puede resolver en la elección de la fusión.
A partir de la fuente de datos, tales como la extracción en lugar de una vez por hora métodos de extracción como una vez al día para acumular la cantidad de datos.
Si un pequeño archivo inevitable, por lo general sobre una base consolidada para resolver. MR puede escribir una tarea de leer un catálogo de todos archivos pequeños, y volver a escribir como un archivo grande.
¿Qué, qué papel son los tres componentes básicos cuando 5.HDFS
1 NameNode. el nodo de gestión de cluster central es el sistema de archivos. mantiene
a) sistema de archivo de estructura de directorio de archivos y la información de metadatos
lista de archivos b) relación de correspondencia del bloque de datos
2 DataNode. bloque de datos específico de nodo se almacena, es responsable de la lectura y la escritura de datos, para enviar periódicamente una NameNode latido del corazón
. 3 SecondaryNameNode. nodo secundario, información de metadatos en NameNode sincronización, NameNode para ayudar fsimage y editsLog fusión.
6. fsimage y editlogs está haciendo qué?
archivo fsimage se almacena en el archivo de metadatos Hadoop, si el fallo NameNode, archivo fsimage reciente se carga en la memoria de reconstrucción de reciente metadatos estado, y luego comienzan cada transacción editar registros de los archivos grabados desde el punto en adelante relevante.
Cuando el sistema de archivos de cliente realiza una operación de escritura, estas transacciones se registran por primera vez en el archivo de registro.
Durante el funcionamiento NameNode, escritura a las hdfs cliente se guardan para editar el archivo, el paso del tiempo hará que editar archivos son muy grandes, esto no tiene ningún efecto sobre la NameNode operación, pero si reinicio NameNode, transfiere el contenido de fsimage mapeado en memoria, y luego uno por uno para llevar a cabo las operaciones de edición de archivos, por lo que los archivos de registro demasiado grande para reiniciar plomo muy lento. por lo que debemos ser los registros de editar periódicos y fsimage en tiempo de ejecución NameNode.
7. el tamaño de bloque en Linux 4 KB, ¿por HDFS tamaño del bloque es de 64 MB o 128 MB?
bloque es la unidad más pequeña de datos almacenados en el sistema de archivos. Si el tamaño de bloque de 4 kb almacenada en los datos almacenados en Hadoop, se necesita una gran cantidad de bloques, aumenta considerablemente la buscan bloque de tiempo, la eficiencia de escritura se reduce.
Además, un mapa o en una reducen se procesa en unidades de un bloque, si el bloque es pequeño, el número de tareas será mucho MapReduce, la sobrecarga de cambiar entre tareas se hace grande, la eficiencia reduciendo
8. escribe HDFS concurrentes archivo factible?
No, porque el cliente recibe la licencia por escrito en los bloques de datos por NameNode posteriores, el bloque se bloqueará recta La operación de escritura se completa, que no está escrito en el mismo bloque.
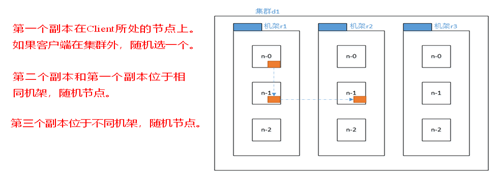
9.HDFS colocación de las copias de políticas
10. diferencias y relaciones NameNode y SecondaryNameNode?
Diferencias:
(. 1) es responsable de gestionar la totalidad NameNode metadatos del sistema de archivos y la información de ruta de datos para cada bloque (archivo) que corresponde a.
(2) SecondaryNameNode combinado se utiliza principalmente para la edición de la imagen de espacio de nombres espacio de nombres y espejo periódica de registro.
Contacto:
(1) SecondaryNameNode guarda en un archivo de imagen consistente y NameNode (fsimage) y el registro de ediciones
(Ediciones).
(2) el fracaso en el NameNode principal (suponiendo que los datos no oportuna de copia de seguridad), los datos se puede recuperar de SecondaryNameNode.
mecanismo de trabajo 11.namenode
- La primera etapa: NameNode se inicia
después de (1) la primera vez que se inicia formato NameNode, crear archivos Fsimage y ediciones. Si esta no es la primera vez que se inicia, registrar y editar la imagen cargar directamente los archivos en la memoria.
(2) el cliente solicita los metadatos de adiciones y supresiones.
(3) NameNode registros operativos de registro, actualización de registro de rodadura.
(4) adiciones NameNode y supresiones a los metadatos en la memoria. - La segunda etapa: el trabajo NameNode Secundaria
(1) Secundario NameNode preguntó si NameNode necesidad puesto de control. NameNode ya sea directamente de nuevo para comprobar los resultados.
(2) secundaria solicitud NameNode ejecución puesto de control.
(3) de desplazamiento NameNode siendo escrito registro de ediciones.
(4) Archivo de espejo y el registro de edición antes de desplazarse copiado en el NameNode secundaria.
(5) secundaria de carga NameNode y editar el archivo de registro a la memoria de imagen, y se agruparon.
(6) la generación de un nuevo fsimage.chkpoint archivo de imagen.
(7) para copiar NameNode fsimage.chkpoint.
(8) NameNode se fsimage.chkpoint pasaría a denominarse fsimage.
mecanismo de trabajo 12.datenode
1) un bloque de datos en la DataNode almacenados como archivos en el disco, incluyendo dos archivos, uno para los propios datos, una longitud de bloque de metadatos comprende datos y bloque de datos de suma de control, y un sello de tiempo.
2) DataNode la NameNode Después de iniciar el registro, por el periódico (1 hora) para informar a todos los bloques de información NameNode.
3) los latidos del corazón cada 3 segundos, con un latido del corazón resultados de retorno a la DataNode NameNode comandos tales como bloque de datos de copia a otra máquina, o eliminación de un bloque de datos. Si hay más de 10 minutos no recibieron un DataNode latido del corazón, el nodo se considera disponible.
4) el funcionamiento del clúster puede unirse de forma segura y dejar algunas máquinas.
13. ¿Qué opinas hadoop diseñar razonable
- No es compatible con archivos al azar de escritura concurrente y modificar el contenido del documento.
- No es compatible con baja latencia, rendimiento alto de acceso a datos.
- El acceso a un gran número de archivos pequeños, NameNode ocupará mucha memoria, dirigiéndose a tiempo a leer los archivos pequeños con el tiempo.
- hadoop entorno para construir más complejo.
- Los datos no pueden ser procesados en tiempo real.
14. ¿Qué perfiles Hadoop en necesidad, cuál es su papel?
. 1, la site.xml Core-
fs.defaultFS: HDFS: cluster1 // (nombre de dominio), donde el valor predeterminado se refiere a la ruta de HDFS.
hadoop.tmp.dir: / export / datos / hadoop_tmp , donde la ruta por defecto es el almacenamiento de un directorio público NameNode, DataNode, secondaryNamenode de datos y similares. El usuario también puede especificar un directorio de estos tres solos nodos.
ha.zookeeper.quorum: hadoop101: 2181, hadoop102: 2181, hadoop103: 2181, aquí está la dirección del clúster ZooKeeper y el puerto. Tenga en cuenta que el número debe ser un número impar, y no menos de tres nodos.
2, hadoop-env.sh
ruta de instalación JDK simplemente conjunto, tales como: export JAVA_HOME = / usr / local / jdk.
. 3, el site.xml HDFS-
dfs.replication: Se determina el número de bloques de datos del sistema de archivos de copia de seguridad, que por defecto es 3.
dfs.data.dir: directorio de nodos DataNode almacenada en el sistema de archivos.
dfs.name.dir: almacenamiento de nodo de información del sistema de archivos hadoop ruta del sistema local del NameNode.
4, mapred-la site.xml
mapreduce.framework.name: el hilo especificado mr se ejecutan en hilo.
5, hilado-site.xml
configuración yarn.nodemanager.aux-servicios y funciones tales como la agregación de registro
6, esclavos, maestro
de configuración de una lista de nodos, el nodo maestro
15.Hadoop ventajas características
(1) de expansión de capacidad
(2) bajo coste
(3) de alta eficiencia
(4) la fiabilidad de
los principales carácter 16. sistemas de programación de recursos del hilado de la agrupación que es?
ResourceManager, NodeManager
vías 17. los despliegues de Hadoop hay?
1 modo autónomo
2 modo pseudo-distribuido
3 el modo de clúster
18. por favor lista de los trabajos de clúster Hadoop Hadoop en la que todos necesitamos para iniciar el proceso, cuáles son sus roles ?
-Namenode => HDFS demonio es responsable del mantenimiento de todo el sistema almacena el archivo de información de metadatos de todo el sistema de archivos, no habrá imagen + editar NameNode registro de almacenamiento persistente de estos datos, pero los datos reconstruidos en el arranque.
-Datanode sistema => archivo específico nodo está trabajando cuando necesitamos ciertos datos, NameNode nos dice dónde encontrarlo y el fondo procesa DataNode correspondiente servidor se comunican directamente, para recuperar datos de DataNode, a continuación, específica las operaciones de lectura / escritura
-secondarynamenode => un demonio redundante, un mecanismo de copia de seguridad de los metadatos NameNode equivalente, actualizaciones periódicas, y NameNode comunicación, que se edita la imagen, y la fusión de la NameNode, como NameNode copia de seguridad mediante
-resourcemanager => es la plataforma demonio de hilo, responsable de la asignación y programación de todos los recursos, solicitando con ello cliente encargado de vigilar NodeManager
-Nodemanager => Gestión de Recursos es un solo nodo, realice las tareas y comandos específicos de ResourceManager de
19. Por favor lista de lo que sabe planificador hadoop, y una descripción breve de sus métodos de trabajo
Fifo cedular: Por defecto, el principio FIFO
cedular Capacidad : computación programador de energía, seleccione el tamaño más pequeño, de alta prioridad se ejecuta en primer lugar, y así sucesivamente.
cedular justo: planificación equitativa, todo el trabajo tienen los mismos recursos.
20. Por favor describa la forma de lograr los dos hadoop clasificación (clasificación es la clave y el valor doble)
Un primer método es que todos los valores clave se dan Reductor en caché, y luego hacer una especie dentro del reductor. Sin embargo, debido a la necesidad de ahorrar Reductor para todos los valores de una clave determinada, puede causar errores que se quede sin memoria.
El segundo método es una parte o la totalidad del valor añadido de la llave original, para generar una clave de combinación. Ambos métodos tienen sus ventajas, bajo el primer método de escritura sencilla, pero un pequeño grado de concurrencia, situación volumen de datos de baja velocidad (en peligro de quedarse sin memoria),
El segundo método chupado tipo de tarea de MapReduce marco shuffle, más en línea con las ideas de diseño Hadoop / Reducir es. Este artículo es la segunda opción. Vamos a escribir un particionador, garantizar que todos los datos tiene la misma llave (la llave original, adiciones no están incluidos) se envía a la misma Reductor, también preparará un Comparador, por lo que tan pronto como lleguen los datos Reductor agrupa por la llave original.
21. Por favor describa partición mapreduce y combinar el papel de
combinador se produce en la última etapa de un mapa, el principio es también una pequeña reductor, el papel principal es reducir la cantidad de salida de datos para reducir y aliviar el cuello de botella de la red de transmisión, aumento del reductor eficiencia.
El principal efecto de todo mapa de particiones kv generado para diferentes etapas reductor tarea asignada al tratamiento, reducir la carga de procesamiento se puede distribuir etapa
modo de planificación 22. mapreduce (problemas de ambigüedad, hilado pueden entenderse como el modo de programación, puede ser entendida como la mr flujo de trabajo interno)
appmaster como director de programación, gestión y maptask reducetask
Appmaster responsable de iniciar, el seguimiento y maptask reducetask
Después de que el proceso se completa Maptask, appmaster será objeto de seguimiento, y su salida se notifica a ReduceTask, y luego tirar el archivo del mapa final ReduceTask, y después del tratamiento;
Cuando la fase de reducir completado, appmaster sino también a la cancelación de la propia ResourceManager
flujo de trabajo 23.MapReduce
El proceso anterior es el proceso más amplia MapReduce todo el flujo de trabajo, pero sólo el principio aleatoria de la etapa 7 al paso 16 extremos, particularmente aleatoria proceso detallada, como sigue:
. 1) MapTask recogió nuestro método kv mapa () de salida, en memoria intermedia
2) de forma continua desde la memoria buffer overflow archivo de disco local, varios archivos pueden desbordarse
3) varios archivos de derrames se fusionarán en un gran archivo de vertido
4) en el proceso de consolidación del proceso de desbordamiento y, deben llamar partición Partitioner y para clasificar Key
. 5) de acuerdo con su número de partición ReduceTask, obtiene los datos correspondientes a la partición resultados respectivos máquina MapTask
6) ReduceTask será llevado a la misma partición de los archivos de resultados de diferentes MapTask, estos archivos ReduceTask a continuación, la fusión (merge especie)
después de 7) mayor que el archivo combinado, proceso aleatoria es más, de nuevo en la operación lógica proceso ReduceTask (clave elimina uno por uno para reducir Group, llamadas desde el archivo definido por el usuario ( ) método)
3. Tenga en cuenta que
el tamaño del búfer de reproducción aleatoria afectará a la eficacia de la aplicación de los programas de MapReduce, en principio, cuanto mayor sea el buffer, menor será el número de io disco, lleve a cabo con mayor rapidez.
parámetros de tamaño de memoria intermedia pueden ser parámetros ajustados: io.sort.mb un 100M predeterminado.
mecanismo de trabajo 24.Yarn
2. mecanismo de trabajo detallado
programa de MR (1) presentada al nodo cliente se encuentra.
(2) YarnRunner para aplicar una Aplicación ResourceManager.
camino de recursos (3) RM vuelve a la YarnRunner aplicación.
(4) El programa se ejecutará en HDFS a presentar los recursos necesarios.
(5) los recursos del programa para presentar las solicitudes para ejecutar mrAppMaster completado.
(6) RM se iniciará a petición de un usuario de tareas.
(7) para recibir uno de tarea NodeManager de tareas.
(8) El contenedor crea NodeManager Container, y genera MRAppmaster.
(9) Recipiente copia en el local de los recursos de los HDFS.
(10) La aplicación se ejecuta MRAppmaster recursos MapTask a RM.
(11) RM se ejecutará tareas MapTask asignados a los otros dos NodeManager, los otros dos NodeManager recibir, respectivamente, la tarea y crear un contenedor.
(12) MR recibido el mandato de la secuencia de comandos de inicio de programa de transmisión de dos NodeManager, que se inician dos NodeManager MapTask, MapTask Ordenar la partición de datos.
(13) espera MrAppMaster para todos MapTask terminado de ejecutarse después de la aplicación de la RM contenedor, ejecutar ReduceTask.
(14) ReduceTask para obtener datos correspondientes partición MapTask.
Después de (15) que se ejecuta terminado, MR RM será la de solicitar la cancelación de su cuenta.
La razón 25.Mapreduce correr lento
rendimiento de una computadora: CPU, memoria, disco está sano, la red
2 I / O operaciones para optimizar
1) datos de oblicuidad
2) Mapa y Reducir número razonable
3) Mapa correr demasiado tiempo, lo que resulta en mucho tiempo esperando Reducir
4) muchos pequeños archivos
5) no puede bloquear una gran cantidad de archivos de gran tamaño
6) Spill demasiadas veces
7) Merge excesivo número de veces que los
26.MapReduce optimización de
métodos de optimización MapReduce principalmente desde el punto de vista de seis: una entrada de datos, la fase de Mapa, la etapa Reducir, la transmisión IO, y sesgo de los datos problemas comunes parámetros de ajuste
6.2.1 de datos de entrada
(1) con pequeño archivo: mr tarea antes de realizar archivos pequeños se fusionan, un gran número de archivos pequeños generará una gran cantidad de
Mapa de tareas, mapa de tareas para aumentar el número de cargas, durante la carga de la tarea requiere mucho tiempo, lo que resulta en una carrera más lenta mr.
(2) CombineTextInputFormat como una entrada a la dirección extremo de entrada del número de escena de archivos pequeños.
6.2.2Map Etapa
1) para reducir el desbordamiento de escritura (derrame) veces: ajustando io.sort.mb y valor de parámetro sort.spill.percent, aumentando el gatillo
derrame tapa memoria, reducir el número de derrame, reduciendo de este modo el disco IO.
2) para reducir) veces de combinación combinados (: io.sort.factor mediante el ajuste de los parámetros, el aumento del número del documento de combinación, reducir el número de combinación, acortando así el tiempo de procesamiento mr.
3) Después de que el mapa, sin afectar a la premisa de lógica de servicio, se combinan para ser procesado, para reducir la I / O.
6.2.3Reduce Etapa
1) un conjunto razonable de mapa y reducir el número de: tanto no puede ser demasiado bajo, no puede ser demasiado. Demasiado poco conducirá
espera tarea causa, el tiempo de tratamiento; demasiado dará lugar a inter-mapa, reducir las tareas compiten por los recursos, lo que resulta en el procesamiento de error de tiempo de espera.
2) el establecimiento de un mapa, reducir coexisten: parámetros de ajuste slowstart.completedmaps para mapear hasta cierto punto correr
grados después, también se reducirá en funcionamiento, para reducir el reducir el tiempo de espera.
3) reducir evitar el uso de: porque una gran cantidad reducirá conjuntos de datos de conexión de red para el consumo de tiempo.
4) un conjunto razonable de tampón reducir lado: Por defecto, los datos llegan a un valor de umbral, los datos de la memoria intermedia se escriben en el disco, y luego reduce'll todos los datos del disco. Es decir, reducir buffer y
no está directamente relacionada con, entre una pluralidad de escritura en disco -> disco proceso de leer, ya que hay algunas desventajas para esto, entonces puede ser configurado por parámetros, de tal manera que una parte de la memoria intermedia de datos puede ser entregado directamente a reducir , reduciendo así la sobrecarga de IO: mapred.job.reduce.input.buffer.percent, el valor predeterminado es 0,0. Cuando el valor es mayor que 0, se conservan los datos mostró reducen directamente las proporciones especificadas de lectura de memoria tampón. Por lo tanto, la necesidad de fijar la memoria intermedia, las necesidades de lectura de datos
sea un recuerdo, sino también el reducir la memoria de cálculo, por lo que ser ajustado de acuerdo con el funcionamiento del trabajo.
Transmisión 6.2.4IO
1) utilizando el modo de compresión de datos, reduciendo el tiempo de la red IO. Instalación y Snappy lzo codificador de compresión.
2) Uso SequenceFile Binarios.
6.2.5 sesgo de los datos problema
1) fenómeno de sesgo de los datos
Inclinación frecuencia de datos - cantidad de datos de un área es mucho mayor que en otras regiones. Inclinación tamaño de los datos - mucho más grande que el tamaño de la porción de registro del valor medio.
2) ¿Cómo recopilar datos inclinadas
detalles añadidos del mapa de teclas de función de grabación en el proceso de salida de reducir.
3) un método para reducir la inclinación de un método para datos: el rango de la muestra y la partición
pueden ser ajustados por el resultado obtenido con el valor preestablecido límite de partición de datos muestreados originales.
Método 2: Custom partición
particiones personalizadas en base a la clave de fondo de salida. Por ejemplo, si las palabras clave de salida de mapa de un libro.
Y en donde un poco más especializada vocabulario. A continuación, puede personalizar la partición éstos vocabulario especializado para enviar la parte fija
reducir los casos. Mientras que los otros son enviados a la instancia reducir restante. Método 3: Combinar
el uso de una gran cantidad puede reducirse Combinar datos de oblicuidad. En lo posible, se combinan el objeto se agrega y
datos reduce.
Método 4: El Mapa de Ingreso, evite Reducir Ingreso.
27. Cuando mapa-a reducir los programas que se ejecutan cuáles son los problemas más comunes
, como la mayor parte del trabajo, pero siempre hay unos pocos reduce've estado funcionando
Esto es porque estos reducen procesamiento de datos es mucho más grande que en otros reducen, los datos pueden estar inclinadas debido a la irregularidad de las tareas clave de la división causadas por
La solución puede ser redefinido reglas de partición para muchos datos de valores clave se puede dividir uniformemente dispersos como el tiempo de proceso de partición, o datos de operación de preprocesamiento en el final de la hoja combinador
