GroupingComparator
En mapreduce hadoop modelo de programación, el final de la hoja cuando el procesado de salida se completa pares de valores clave, la misma clave será sólo para reducir el fin de reducir la misma función a ejecutar. Sin embargo, cuando se utiliza el objeto Java es una clave, la forma de determinar el objeto Java es una llave con ella, esta vez necesita GroupingComparator, comparar el uso del método en esta clase, de acuerdo con sus necesidades, establecer las mismas condiciones clave para poner la misma reducir un método de procesamiento.
paquete GroupingComparator (tipo secundario)
Reducir los datos de fase se agrupan de acuerdo a uno o varios campos.
pasos de secuenciación de paquetes:
(1) clase personalizada que hereda WritableComparator
(2) se puede reescribir comparar método (), de acuerdo con sus necesidades, siempre que las operaciones de comparación, devuelve 0, entonces los dos objetos se establecen en la misma clave
ublic class GroupComparator extends WritableComparator{
WritableComparator:
public GroupComparator() {
//以使用hadoop中的GroupingComparator对其进行分组,先要定义一个类继承
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//根据自己的需求,设置比较业务,返回0,则表示两个对象是设置为相同的key
TextPair t1 = (TextPair) a;
TextPair t2 = (TextPair) b;
return t1.getFirst().compareTo(t2.getFirst());
}
}
Caso secuenciación de paquetes
datos
order001, U001, mijo 6,1999.9,2
order001, U001, Nescafé, 99.0,2
order001, U001, un Muxi, 250.0,2
order001, U001, la felicidad del doble clásico, 200.0,4
order001, U001, bolsa de ordenador portátil a prueba de agua, 400,0 , 2
order002, U002, pulsera mijo, 199.0,3
order002, U002, durian, 15.0,10
order002, U002, manzanas, 4.5,20
order002, U002, jabón, 10.0,40
requisitos:
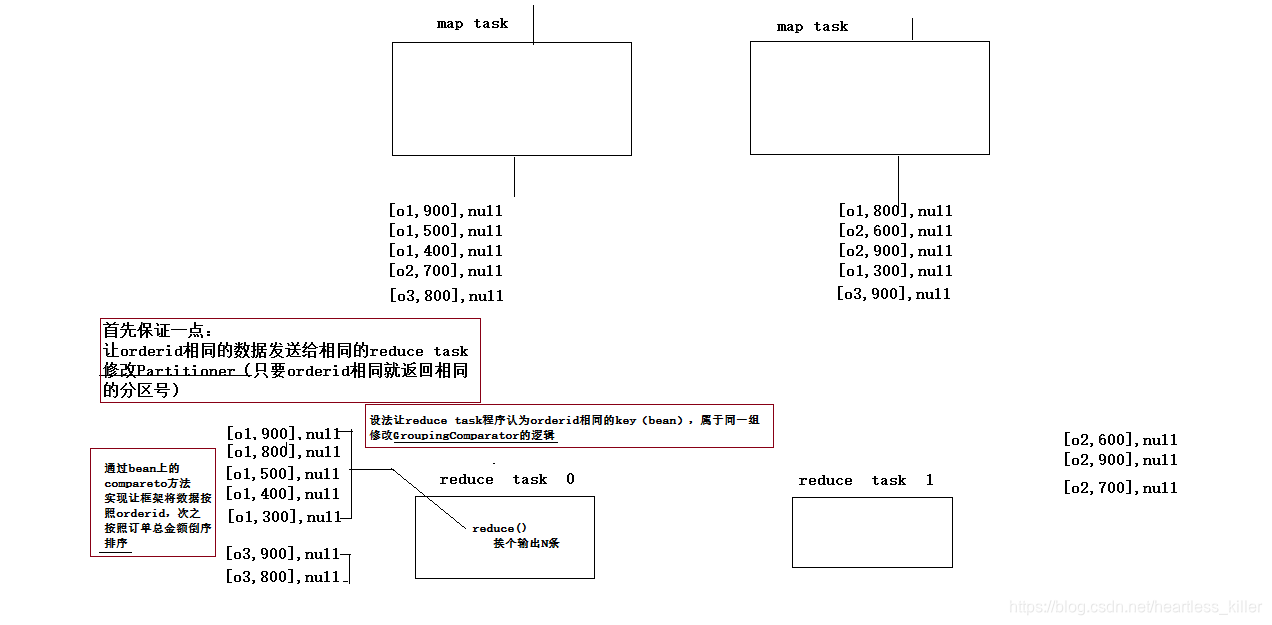
Cada orden es necesario para obtener la cantidad más grande de la facturación son tres elementos de
la naturaleza: TopN paquete de solicitud
Realización de las ideas:
1. Set un java datos de objeto almacenado orden, a la OrderBean y sus interfaces para lograr interfaz serializable y el comparador, se consigue WritableComparable <> a continuación, se compara los datos de regla de interfaz: la cantidad total de la primera relación de si mismo, otro nombre que el producto.
gobierna 2 de distribución de datos de reescritura Partitioner, distribuido bajo OrderId.
3map: leer el campo de datos de segmentación, los datos se encapsula en un grano como una clave de transmisión, llave de acuerdo con el volumen de negocios que el tamaño
4reduce: primera salida N para reducir cada conjunto de datos en el proceso, pero si quiere cumplir con el requisito. OrderId requiere que sea el mismo que la clave, para reducir la misma función a ejecutar, si se quiere lograr este requisito, es necesario volver a escribir las mismas reglas de determinación de claves GroupingComparator.
5 GroupingComparator personalizado, identificación de la orden de la misma como una clave.
mapa
muestra en el código:
conjunto OrderBean
Java objeto a un conjunto de datos de pedido almacenados, a la OrderBean y sus interfaces para lograr interfaz serializable y el comparador, se compara entonces se consigue WritableComparable <> datos de la regla de interfaz: la cantidad total de la primera relación de si mismo, entonces la relación nombres comerciales.
package cn.edu360.mr.order.topn.grouping;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String userId;
private String pdtName;
private float price;
private int number;
private float amountFee;
public void set(String orderId, String userId, String pdtName, float price, int number) {
this.orderId = orderId;
this.userId = userId;
this.pdtName = pdtName;
this.price = price;
this.number = number;
this.amountFee = price * number;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getPdtName() {
return pdtName;
}
public void setPdtName(String pdtName) {
this.pdtName = pdtName;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public float getAmountFee() {
return amountFee;
}
public void setAmountFee(float amountFee) {
this.amountFee = amountFee;
}
@Override
public String toString() {
return this.orderId + "," + this.userId + "," + this.pdtName + "," + this.price + "," + this.number + ","
+ this.amountFee;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.orderId);
out.writeUTF(this.userId);
out.writeUTF(this.pdtName);
out.writeFloat(this.price);
out.writeInt(this.number);
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.userId = in.readUTF();
this.pdtName = in.readUTF();
this.price = in.readFloat();
this.number = in.readInt();
this.amountFee = this.price * this.number;
}
// 比较规则:先比总金额,如果相同,再比商品名称
@Override
public int compareTo(OrderBean o) {
return this.orderId.compareTo(o.getOrderId())==0?Float.compare(o.getAmountFee(), this.getAmountFee()):this.orderId.compareTo(o.getOrderId());
}
}
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderIdPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
// 按照订单中的orderid来分发数据
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
Partitioner personalizada
Reglas de distribución de datos de reescritura Partitioner, distribuido bajo OrderId.
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderIdPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
// 按照订单中的orderid来分发数据
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions; //numPartitions就是reduce的数量
}
}
programas MapReduce
Mapa: leer el campo de datos de segmentación, los datos se encapsula en un grano como una clave de transmisión, tamaño de la clave de acuerdo al volumen de negocio que
reducen: primera salida N para reducir cada conjunto de datos en el proceso, pero si quiere cumplir con el requisito. OrderId requiere que sea el mismo que la clave, para reducir la misma función a ejecutar, si se quiere lograr este requisito, es necesario volver a escribir las mismas reglas de determinación de claves GroupingComparator.
package cn.edu360.mr.order.topn.grouping;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderTopn {
public static class OrderTopnMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
OrderBean orderBean = new OrderBean();
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
orderBean.set(fields[0], fields[1], fields[2], Float.parseFloat(fields[3]), Integer.parseInt(fields[4]));
context.write(orderBean,v);
}
}
public static class OrderTopnReducer extends Reducer< OrderBean, NullWritable, OrderBean, NullWritable>{
/**
* 虽然reduce方法中的参数key只有一个,但是只要迭代器迭代一次,key中的值就会变
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
int i=0;
for (NullWritable v : values) {
context.write(key, v);
if(++i==3) return;
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 默认只加载core-default.xml core-site.xml
conf.setInt("order.top.n", 2);
Job job = Job.getInstance(conf);
job.setJarByClass(OrderTopn.class);
job.setMapperClass(OrderTopnMapper.class);
job.setReducerClass(OrderTopnReducer.class);
job.setPartitionerClass(OrderIdPartitioner.class);
job.setGroupingComparatorClass(OrderIdGroupingComparator.class);
job.setNumReduceTasks(2);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("F:\\mrdata\\order\\input"));
FileOutputFormat.setOutputPath(job, new Path("F:\\mrdata\\order\\out-3"));
job.waitForCompletion(true);
}
}
GroupingComparator personalizada
GroupingComparator, ID del objeto de la misma como una clave.
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderIdGroupingComparator extends WritableComparator{
public OrderIdGroupingComparator() { // 用于告知方法,需要对什么类进行操作。
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) { //相同的OrderId认为是一个key。
OrderBean o1 = (OrderBean) a;
OrderBean o2 = (OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}
