
mysqld: Hermano, no puedo levantarme...
Autor: Ben Shaohua, ingeniero del Centro de I+D de ACOSEN, responsable de los requisitos y el mantenimiento del proyecto. Otras identidades: paleador Corgi.
Producido por la comunidad de código abierto de Aikeson. El contenido original no se puede utilizar sin autorización. Comuníquese con el editor e indique la fuente para la reimpresión.
Este artículo tiene aproximadamente 2100 palabras y se espera que demore 7 minutos en leerlo.
introducción
Como indica el título, en escenarios de pruebas automatizadas, MySQL no se puede iniciar a través de systemd .
Finalice continuamente kill -9el proceso de instancia y verifique si mysqld se abrirá correctamente después de salir.
La información específica es la siguiente:
- Información del host: CentOS 8 (contenedor Docker)
- Utilice systemd para gestionar el proceso mysqld
- El modo de funcionamiento del servicio systemd es: bifurcación
- El comando de inicio es el siguiente:
# systemd 启动命令
sudo -S systemctl start mysqld_11690.service
# systemd service 内的 ExecStart 启动命令
/opt/mysql/base/8.0.34/bin/mysqld --defaults-file=/opt/mysql/etc/11690/my.cnf --daemonize --pid-file=/opt/mysql/data/11690/mysqld.pid --user=actiontech-mysql --socket=/opt/mysql/data/11690/mysqld.sock --port=11690
Síntoma
El comando de inicio continúa bloqueándose, sin éxito ni retorno. Después de varios intentos, el escenario no se puede reproducir manualmente.
La siguiente figura muestra un escenario de reproducción. Si los números de puerto de servicio no son consistentes, ignórelos.

El registro de errores de MySQL no contiene información. Verifique el estado del servicio systemd y descubra que el script de inicio MAIN PIDno se pudo ejecutar debido a la falta de parámetros.
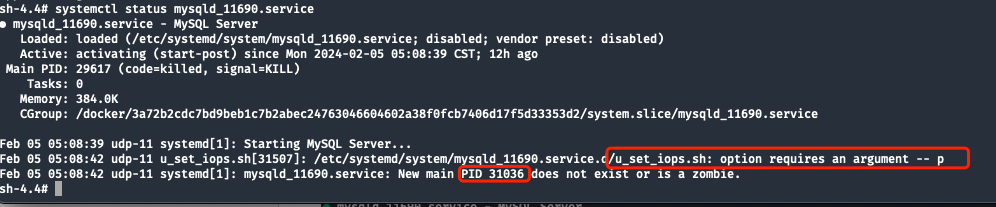
La información final generada por systemd es:New main PID 31036 does not exist or is a zombie
Resumen de razones
Cuando systemd inicia mysqld , primero se ejecutará de acuerdo con la configuración en la plantilla de servicio :
- ExecStart (iniciar mysqld )
- mysqld comienza a crear
pidarchivos - ExecStartPost (algunos post-scripts personalizados: ajustar permisos, escribir
piden cgroup , etc.)
En el estado intermedio del paso 2-3 , es decir, pidcuando se acaba de crear el archivo, el host recibe el comando emitido por la prueba automatizada sudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid):.
Dado que este pidarchivo y pidproceso existen (si killel comando o comando no existe, catse informará un error), CASE automatizado considera que killla operación ha finalizado con éxito. Sin embargo, dado que mysqld.pidMySQL mantiene este archivo, desde la perspectiva de systemd , aún debe esperar a que se complete el paso 3 antes de que el inicio se considere exitoso.
Cuando systemd usa el modo bifurcación , determinará PIDsi el servicio se inició exitosamente en función del valor del proceso hijo.
Si el proceso hijo se inicia correctamente y no se produce ninguna salida inesperada, systemd considera que el servicio se ha iniciado y establece el PIDvalor del proceso hijo como MAIN PID.
Si el proceso hijo no se inicia o se cierra inesperadamente, systemd considerará que el servicio no se inició correctamente.
en conclusión
Al ejecutar ExecStartPost, debido a que se eliminó el ID del proceso secundario 31036 ,kill el posprocesamiento shellcarece de parámetros de inicio, pero el paso ExecStart se completó, lo que provocó que MAIN PID 31036 se convirtiera en un proceso zombie que solo existe en systemd .
Proceso de solución de problemas
Cuando encontré este problema, estaba un poco confundido. Simplemente verifiqué la información básica de la memoria y el disco. Cumplió con las expectativas y no faltaron recursos.
Primero veamos el registro de errores de MySQL para ver qué encontramos. Vea los resultados de la siguiente manera:
...无关内容省略...
2024-02-05T05:08:42.538326+08:00 0 [Warning] [MY-010539] [Repl] Recovery from source pos 3943309 and file mysql-bin.000001 for channel ''. Previous relay log pos and relay log file had been set to 4, /opt/mysql/log/relaylog/11690/mysql-relay.000004 respectively.
2024-02-05T05:08:42.548513+08:00 0 [System] [MY-010931] [Server] /opt/mysql/base/8.0.34/bin/mysqld: ready for connections. Version: '8.0.34' socket: '/opt/mysql/data/11690/mysqld.sock' port: 11690 MySQL Community Server - GPL.
2024-02-05T05:08:42.548633+08:00 0 [System] [MY-013292] [Server] Admin interface ready for connections, address: '127.0.0.1' port: 6114
2024-02-05T05:08:42.548620+08:00 5 [Note] [MY-010051] [Server] Event Scheduler: scheduler thread started with id 5
Al observar el registro de errores, encontramos que no hay información útil porque no se genera información de registro después del tiempo de inicio.
Verifique el estado de systemctl para confirmar el estado actual del servicio:
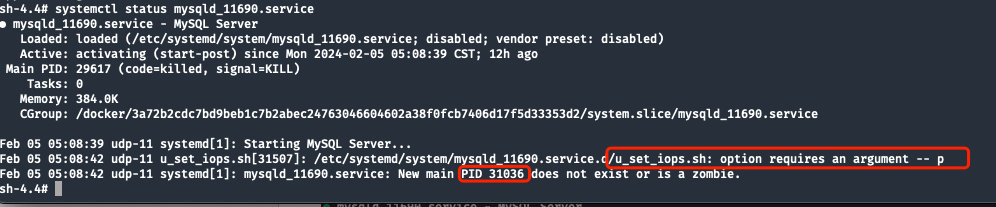
La siguiente imagen muestra la información de estado en circunstancias normales :

Después de la comparación, se recopilaron dos datos útiles:
- La ejecución posterior falló
shelldebido a la falta de-pparámetros (-plos parámetros sonMAIN PID, es decir, después de que se inicia el proceso hijo de la bifurcaciónPID). - systemd no se puede obtener
PID 31036, no existe o es un proceso zombie.
Primero revisemos el proceso IDy mysqld.pidveamos:
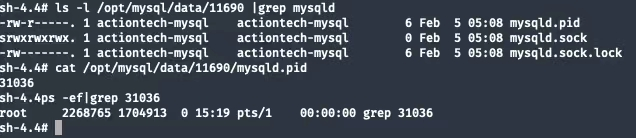
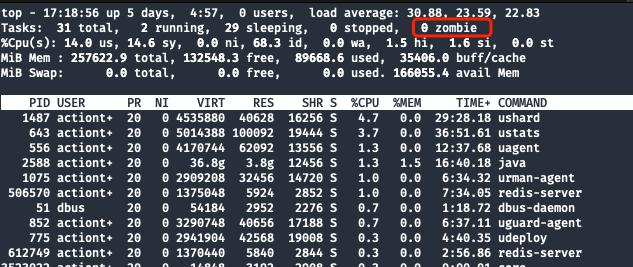
Pistas de confirmación:
PID 31036no existemysqld.pidEl archivo existe y el contenido del archivo es 31036.topComando para comprobar si no hay ningún proceso zombie
Aún necesito obtener más pistas para confirmar la causa, consulte journalctl -uel contenido para ver si ayuda:
sh-4.4# journalctl -u mysqld_11690.service
-- Logs begin at Mon 2024-02-05 04:00:35 CST, end at Mon 2024-02-05 17:08:01 CST. --
Feb 05 05:07:54 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:07:56 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:32 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:36 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:39 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:42 udp-11 u_set_iops.sh[31507]: /etc/systemd/system/mysqld_11690.service.d/u_set_iops.sh: option requires an argument -- p
Feb 05 05:08:42 udp-11 systemd[1]: mysqld_11690.service: New main PID 31036 does not exist or is a zombie.
El contenido aquí journalctl -usolo describe el fenómeno y no puede analizar las razones específicas. Es similar al contenido de systemctl status y no es muy útil.
Ver /var/log/messagesel contenido del registro del sistema:

Se descubrió que el bucle informaba información de error de memoria. Después de la búsqueda, se descubrió que el error puede ser un problema de hardware. Después de preguntar a mis colegas en pruebas automatizadas, llegué a la conclusión:
- El escenario es un problema ocasional. El caso de uso se ejecuta 4 veces, 2 veces con éxito y 2 veces con error.
- Cada ejecución se realiza en el mismo host y en la misma imagen de contenedor.
- Cuando falla, el contenedor donde vive el hang es el mismo.
Dado que hay resultados de ejecución exitosos, aquí ignoraremos los problemas de hardware.
Ahora que se mencionan los contenedores, surge un problema cuando pienso si los cgroups se asignarán al host. En el estado systemctl verificado arriba , se puede ver que el directorio de host asignado por cgroup es:CGroup: /docker/3a72b2cdc7bd9beb1c7b2abec24763046604602a38f0fcb7406d17f5d33353d2/system.slice/mysqld_11690.service
Verifique los permisos de lectura y escritura de la carpeta principal system.slicey no hay ninguna anomalía. Primero, elimine temporalmente el problema de mapeo de cgroup (porque hay otros servicios asumidos por systemd en el host que también usan el mismo cgroup ).
Planeo probar si pstack puede ver dónde se cuelga systemd específicamente, 3048143para systemctl start pid:
sh-4.4# pstack 3048143
#0 0x00007fdfaef33ade in ppoll () from /lib64/libc.so.6
#1 0x00007fdfaf7768ee in bus_poll () from /usr/lib/systemd/libsystemd-shared-239.so
#2 0x00007fdfaf6a8f3d in bus_wait_for_jobs () from /usr/lib/systemd/libsystemd-shared-239.so
#3 0x000055b4c2d59b2e in start_unit ()
#4 0x00007fdfaf7457e3 in dispatch_verb () from /usr/lib/systemd/libsystemd-shared-239.so
#5 0x000055b4c2d4c2b4 in main ()
La observación encontró que start_unit es sospechoso. start_unit()La función se encuentra en el archivo ejecutable y se utiliza para iniciar unidades systemd , lo cual no es útil.
Basándonos en las pistas existentes, podemos especular que:
mysqld.pidSi el archivo existe, significa que efectivamente hubo un proceso mysqld con el número de proceso31036que se inició antes.kill -9Una vez iniciado el proceso, el caso de uso automatizado lo finaliza .- systemd obtuvo un archivo ya terminado
MAIN PID, la ejecución posterior al shell falló y el proceso de bifurcación falló.
Al clasificar los pasos del proceso de inicio de systemd , podemos especular sobre las posibilidades. La instancia de MySQL solo generará archivos después de que mysqld se inicie correctamente, por lo que puede deberse a una finalización accidental mysqld.piden pasos posteriores .kill -9
Método de reproducción
Como no hay otras pistas o pistas, planeo intentar reproducirlo en base a la conclusión inferida.
4.1 Ajustar la plantilla de servicio systemd mysql
Edite el archivo de plantilla /etc/systemd/system/mysqld_11690.service, segundos después de que se inicie mysqld , sleep10para que pueda simular el escenario de finalizar el proceso de instancia dentro de esta ventana de tiempo.
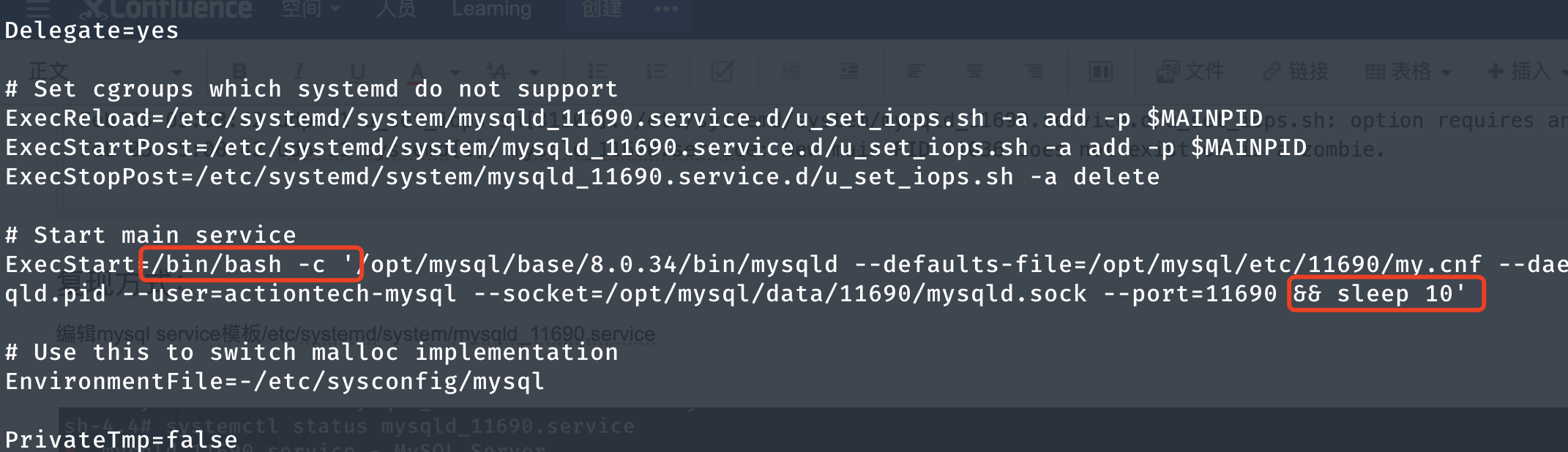
4.2 Recarga de configuración
Los cambios en las órdenes de ejecución systemctl daemon-reloadentrarán en vigor.
4.3 Reproducción de escenas
- [sesión ssh A] Primero prepare un nuevo contenedor, realice las configuraciones relevantes y ejecútelo para
sudo -S systemctl start mysqld_11690.serviceiniciar un proceso mysqld . En este momento,sleepla sesión se bloqueará por algún motivo. - [sesión ssh B] En otra ventana de sesión,
startmientras el comando hang está activo, verifiquemysqld.pidel archivo y ejecútelo inmediatamente una vez que se cree el archivosudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid). - En este momento, observe el estado de systemctl y el rendimiento es consistente con las expectativas.

Solución
Primero, elimine el comando systemctl startkill bloqueado y ejecútelo . Esto permite que systemd finalice activamente el proceso zombie. Aunque el comando puede informar un error, esto no lo afecta.systemctl stop mysqld_11690.servicestop
Espere a que stopse complete la ejecución y luego use startel comando para comenzar de nuevo y volver a la normalidad.
Para obtener más artículos técnicos, visite: https://opensource.actionsky.com/
Acerca de SQLE
SQLE es una plataforma integral de gestión de calidad de SQL que cubre la auditoría y gestión de SQL desde los entornos de desarrollo hasta los de producción. Admite bases de datos nacionales, comerciales y de código abierto convencionales, proporciona capacidades de automatización de procesos para el desarrollo, operación y mantenimiento, mejora la eficiencia en línea y mejora la calidad de los datos.
obtener SQLE
| tipo | DIRECCIÓN |
|---|---|
| Repositorio | https://github.com/actiontech/sqle |
| documento | https://actiontech.github.io/sqle-docs/ |
| noticias de lanzamiento | https://github.com/actiontech/sqle/releases |
| Documentación de desarrollo del complemento de auditoría de datos | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |