
La magia del código eBPF, que propaga direcciones de pares directamente en el flujo TCP para reconstruir la topología de comunicación
" Construir una topología de red de una aplicación Kubernetes de forma no intrusiva" , según Ilya Shakhat.
introducir
Una aplicación de Kubernetes se divide lógicamente en dos partes: una parte son los recursos informáticos (representados por pods) y la otra parte proporciona acceso a la aplicación (representados por servicios). Los clientes de la aplicación pueden acceder a ella utilizando el nombre abstracto sin importar qué pod maneja realmente la solicitud. Y, dado que un único servicio puede tener varios pods como backends, también actúa como equilibrador de carga. En una implementación predeterminada de Kubernetes, esta función de equilibrio de carga se implementa utilizando iptables o IPVS de Linux muy simples: ambos funcionan en la capa L4 (como TCP) e implementan un ingenuo mecanismo de operación por turnos basado en aleatorio. Por supuesto, los proveedores de la nube también pueden ofrecer soluciones de equilibrio de carga más tradicionales para exponer aplicaciones, pero comencemos de manera simple.
Cuando pensamos en los diversos problemas que pueden ocurrir en las aplicaciones implementadas en Kubernetes, existe una clase de problemas que requieren comprender la instancia específica de manejo de solicitudes de clientes. Por ejemplo: (1) un Pod de aplicación se implementa en un host con una conexión de red deficiente y tarda más en establecer una nueva conexión que otros Pods, o (2) el rendimiento de un Pod se degrada con el tiempo, mientras que el rendimiento de otros Pods permanece estable , o (3) la solicitud de un cliente específico afecta el rendimiento de la aplicación. El rastreo distribuido es a menudo una de las formas de obtener información sobre problemas como este y, obviamente, se utiliza para rastrear la ruta de una solicitud de cliente a la aplicación backend. Tradicionalmente, el seguimiento distribuido requiere algún tipo de instrumentación, que puede pasar de agregar código manualmente a una inyección totalmente automatizada en el tiempo de ejecución. Pero, ¿se puede lograr el mismo efecto sin modificar en absoluto el código del cliente?
Para depurar el problema anterior, básicamente necesitamos dos características del seguimiento distribuido: (1) recopilar métricas relacionadas con la latencia de las solicitudes y (2) saber exactamente hacia dónde se dirige cada solicitud. La primera característica se puede implementar fácilmente de forma no intrusiva utilizando una de las numerosas herramientas admitidas por eBPF (una tecnología que permite conectar dinámicamente sondas a las funciones del kernel), por ejemplo, registrar qué proceso estableció una nueva conexión, obtener métricas relacionadas con el socket/la conexión. e incluso comprobar si hay retransmisiones o restablecimientos de conexión maliciosos. En el ecosistema openEuler, una herramienta de este tipo es gala-gopher, que proporciona una gran cantidad de sondas diferentes, incluidas sondas de socket, TCP y L7/HTTP(s). Sin embargo, la segunda característica (saber hacia dónde va una solicitud individual) es mucho más difícil de lograr. En un marco de seguimiento distribuido, esto se logra inyectando un ID de tramo/rastreo en la carga útil de la aplicación y luego correlacionando las observaciones tanto del cliente como del backend utilizando el mismo ID de tramo. Ser no intrusivo para el código de la aplicación significa que la misma información debe inyectarse de forma genérica, pero hacer esto en el protocolo de la aplicación simplemente no es factible ya que requeriría interceptar el tráfico saliente, analizarlo, inyectar el ID y su serializado y reenviado. ¡Parece que acabamos de reinventar una red de servicios!
Antes de continuar, echemos un vistazo a los datos disponibles en el monitoreo de red. Aquí suponemos que el monitor obtendrá información de todos los nodos que alojan la aplicación Pod y luego estos datos serán procesados, por ejemplo, por Prometheus. Colecciónalos. Para lograr esto, necesitamos algún entorno experimental.
entorno de prueba
Primero, necesitamos un clúster de Kubernetes de múltiples nodos implementado. En Huawei Cloud, el servicio correspondiente se llama Cloud Container Engine (CCE).
Luego necesitamos una aplicación de prueba, y para ello usaremos un programa Python muy simple que acepta una solicitud HTTP y es capaz de realizar solicitudes HTTP salientes a la dirección especificada en la solicitud original. De esta forma podremos vincular aplicaciones fácilmente.
Estas aplicaciones se denominarán con las letras latinas A, B, etc. La Aplicación A se implementa como Implementación A y Servicio A, y así sucesivamente. La primera aplicación también estará expuesta al mundo exterior para que pueda ser llamada desde el exterior.
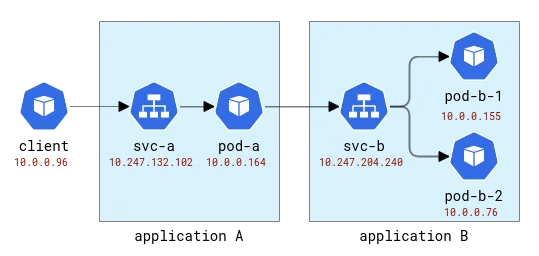
Topología de aplicaciones A y B
En Kubernetes, Gala-gopher se implementa como un conjunto de demonios y se ejecuta en todos los nodos de Kubernetes. Proporciona métricas que Prometheus consume y, en última instancia, visualizan Grafana. La topología del servicio se crea en función de métricas y se visualiza mediante el complemento NodeGraph.
Observabilidad
Enviemos algunas solicitudes a la Aplicación A y reenviémoslas a la Aplicación B de esta manera:
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
En el resultado, vemos que una de las solicitudes para la Aplicación B se envió a un pod y la otra solicitud se envió a otro pod. Así aparece la topología en Grafana:
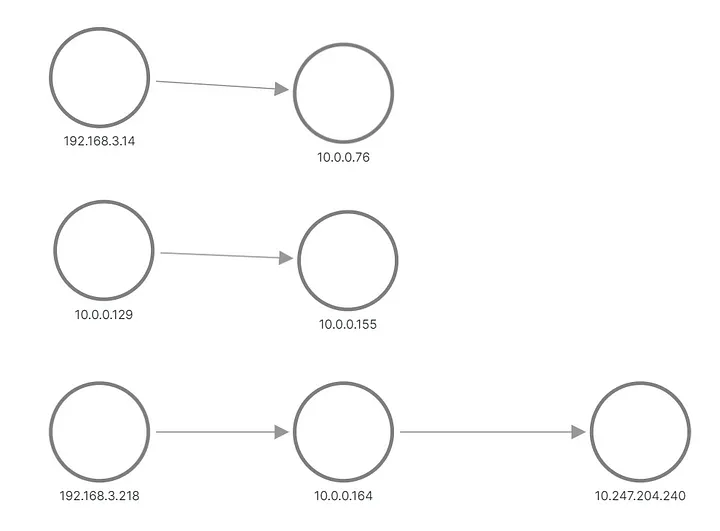
A y B aplican topología, reconstruida a partir de métricas
Las filas superior e intermedia muestran algo que envía una solicitud al pod de la Aplicación B, mientras que la parte inferior muestra uno de los pods de A que envía una solicitud a la IP virtual del Servicio B. Pero esto no se parece en nada a lo que esperábamos, ¿verdad? Sólo vemos tres conjuntos de nodos sin vínculos entre ellos. Las direcciones IP de la subred 192.168.3.0/24 son las direcciones de nodo de la red privada del clúster (VPC) y 10.0.0.1/24 es la dirección del pod, excepto 10.0.0.129, que es la dirección de nodo utilizada para intra-red. comunicación de nodo.
Ahora, estas métricas se recopilan a nivel de socket, lo que significa que son exactamente lo que el proceso de solicitud puede ver. La recopilación se realiza mediante sondas eBPF, por lo que la primera idea es comprobar si el kernel del sistema operativo sabe más sobre la conexión de la aplicación que la información disponible en el socket. El clúster está configurado con un CNI predeterminado y el servicio Kubernetes se implementa como una regla de iptables. La salida de iptables-save muestra la configuración. Las más interesantes son estas reglas que realmente configuran el equilibrio de carga:
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
El equilibrio de carga se realiza en el mismo nodo que el cliente. Entonces, si asignamos pods a nodos, se verá así:
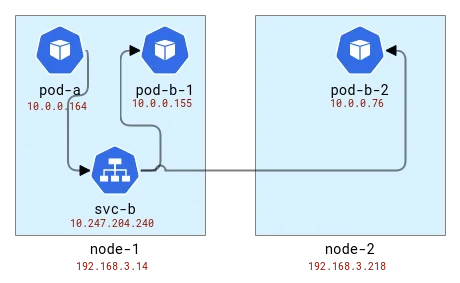
Asigne la topología de las aplicaciones A y B a los nodos de Kubernetes
Internamente, iptables (en realidad nftables ) usa el módulo conntrack para comprender que los paquetes pertenecen a la misma conexión y deben manejarse de manera similar. Conntrack también es responsable de la traducción de direcciones, por lo que los nodos con aplicaciones cliente deben saber dónde enviar los paquetes. Comprobémoslo usando la herramienta CLI conntrack.
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
Bien, vemos que en el primer nodo, la dirección se tradujo del pod de la Aplicación A y obtuvimos una dirección de nodo con algún puerto aleatorio. En el segundo nodo, la información de conexión se invierte ya que su propio paquete es en realidad una respuesta, pero con esto en mente vemos que la solicitud proviene del primer nodo y del mismo puerto aleatorio. Tenga en cuenta que hay dos solicitudes en el Nodo-1 porque enviamos 2 solicitudes y fueron manejadas por diferentes pods: pod-b-1 en el mismo nodo y pod-b-2 en otro nodo.
La buena noticia aquí es que es posible conocer el destinatario real de la solicitud en el nodo cliente, pero para el lado del servidor debe correlacionarse con la información recopilada en el nodo cliente . como esto:
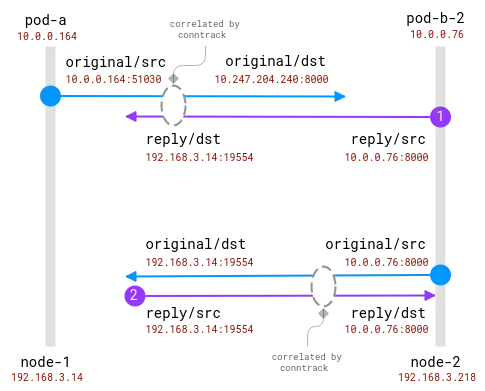
Las conexiones son rastreadas por el módulo conntrack. El círculo azul es la dirección local observada en el socket y el morado es la dirección remota. El desafío es relacionar el morado y el azul.
Cuando los pods de cliente y servidor están en el mismo nodo, la correlación se vuelve más simple, pero aún existen algunas suposiciones sobre qué direcciones son reales y cuáles deben ignorarse:
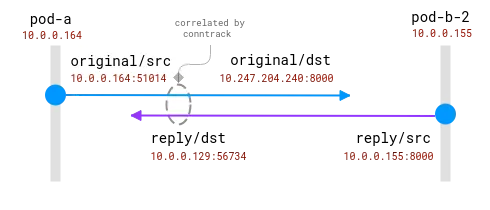
Una conexión entre dos Pods en el mismo nodo. La dirección de origen es real, pero es necesario asignar la dirección de destino.
Aquí, el sistema operativo tiene visibilidad total de la NAT y puede proporcionar un mapeo entre el origen real y el destino real. Es _posible_ reconstruir la secuencia completa de 10.0.0.164 a 10.0.0.155.
Para concluir esta sección, debería ser posible ampliar las sondas eBPF existentes para incluir información sobre la traducción de direcciones desde el módulo conntrack. El cliente puede saber hacia dónde va la solicitud. Pero el servidor no siempre puede saber quién es el cliente, no existe un algoritmo de correlación centralizado directamente. Por el contrario, los métodos de seguimiento distribuido proporcionan a los clientes y servidores información sobre sus pares, directa e inmediatamente a partir de los datos de comunicación. Entonces, ¡aquí viene FlowTracer!
rastreador de flujo
La idea es simple: transferir datos entre pares directamente dentro de la conexión. Esta no es la primera vez que se necesita una característica de este tipo; por ejemplo, el equilibrador de carga HTTP insertará el encabezado HTTP X-Forwarded-For para informar al servidor backend sobre el cliente. La limitación aquí es que queremos permanecer en L4, admitiendo así cualquier protocolo de nivel de aplicación. Esta funcionalidad también existe, y algunos balanceadores de carga L4 (como este ) pueden inyectar la dirección de origen como una opción de encabezado TCP y ponerla a disposición del servidor.
Resumen de requisitos:
- Dirección del par de transporte de capa L4.
- Capacidad para habilitar dinámicamente la inyección de direcciones (como implementar fácilmente aplicaciones en K8).
- No invasivo y rápido.
El enfoque más sencillo parece ser utilizar opciones de encabezado TCP (también conocidas como TOA). La carga útil es la dirección IP y el número de puerto (porque cambian durante la traducción de la dirección). Dado que la implementación de Huawei Kubernetes solo admite IPv4, podemos limitar la compatibilidad solo a IPv4. Las direcciones IPv4 son de 32 bits, mientras que los números de puerto requieren 16 bits, lo que requiere un total de 6 bytes, más 1 byte para el tipo de opción y 1 byte para la longitud de la opción. Así es como se ven las especificaciones del encabezado TCP:
El encabezado puede contener múltiples opciones de hasta 40 bytes. Cada opción puede tener una longitud y un tipo/clase variables.
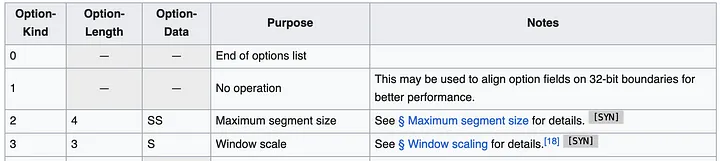
En general, los paquetes TCP de Linux ya tienen algunas opciones, como MSS o marca de tiempo. Pero todavía nos quedan unos 20 bytes de espacio disponibles.
Ahora que sabemos dónde colocar los datos, la siguiente pregunta es ¿dónde debemos agregar el código? Queremos que la solución sea lo más general posible y pueda usarse para todas las conexiones TCP. El lugar ideal es algún lugar del núcleo en la pila de la red, en lo que se llama un búfer de socket (una estructura que representa la información de conexión de la red), desde el nivel superior hasta los paquetes listos para ser transmitidos a través de la red. Desde una perspectiva de implementación, el código debe ser código eBPF (¡por supuesto!) y la funcionalidad de inyección de direcciones se puede habilitar dinámicamente.
El lugar más obvio para este tipo de código es TC, un módulo de control de flujo. En el TC, el programa eBPF tiene acceso al paquete creado y puede leer y escribir datos del paquete. Una desventaja es que el paquete debe analizarse desde el principio, es decir, aunque la función bpf_skb_load_bytes_relative proporciona un puntero al comienzo del encabezado L3, la posición L4 aún debe calcularse manualmente. La más problemática es la operación de inserción. Hay 2 funciones con nombres prometedores, bpf_skb_adjust_room y bpf_skb_change_tail , pero permiten cambiar el tamaño de paquetes hasta L3, no L4. Una solución alternativa es verificar si el encabezado TCP existente contiene ciertas opciones y anularlas, pero primero verifiquemos qué contiene un paquete típico.
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
Este es el paquete TCP SYN enviado cuando el cliente establece una conexión con la aplicación backend. El encabezado contiene varias opciones: MSS para especificar el tamaño máximo del segmento, luego un reconocimiento opcional, una marca de tiempo específica para garantizar el orden de los paquetes, un código de operación NOP posiblemente para la alineación de palabras y, finalmente, para la alineación. Escalado de ventana para el tamaño de la ventana. De esa lista, la opción de marca de tiempo es la mejor candidata para ser cubierta (según Wikipedia, la adopción todavía ronda el 40%), mientras que DeepFlow, uno de los líderes en seguimiento no intrusivo de eBPF, ha realizado esta operación en .
Si bien este enfoque parece factible, no es fácil de implementar. El programa TC tiene acceso a las direcciones traducidas, lo que significa que el mapa de traducción debe recuperarse de alguna manera del módulo conntrack y almacenarse. El programa TC se conecta a la tarjeta de red, por lo que si un nodo tiene varias tarjetas de red, la implementación debe identificar correctamente la ubicación del enlace. El módulo lector tiene que analizar todos los paquetes para encontrar el TCP y luego recorrer los encabezados para encontrar dónde está nuestro encabezado. ¿Hay alguna otra manera?
Al buscar esta pregunta a través de Google en agosto de 2023, es común ver No más resultados en la parte inferior de la página de resultados de búsqueda (¡esperamos que esta publicación de blog cambie eso!). La referencia más útil es un enlace a un parche del kernel de Linux producido por ingenieros de Facebook en 2020. Este parche muestra lo que estamos buscando:
Los primeros trabajos en BPF-TCP-CC permitieron escribir algoritmos de control de congestión de TCP en BPF. Brinda la oportunidad de mejorar el tiempo de respuesta en entornos de producción al probar/lanzar nuevas ideas de control de congestión. La misma flexibilidad se puede extender a la escritura de opciones de encabezado TCP.
No es inusual que la gente quiera probar nuevas opciones de encabezado TCP para mejorar el rendimiento de TCP. Otro caso de uso es para centros de datos que tienen un entorno más controlado y pueden incluir opciones de encabezado en el tráfico solo interno, lo que brinda más flexibilidad.
El santo grial son estas funciones: bpf_store_hdr_opt y bpf_load_hdr_opt . Ambos pertenecen a un tipo especial de programa sock ops , disponible desde el kernel 5.10, lo que significa que se pueden utilizar en casi cualquier versión después de 2022. El programa Sock ops es una función única adjunta a cgroup v2 que permite habilitarlo solo para ciertos sockets (por ejemplo, pertenecientes a un contenedor específico). El programa recibe una única operación que indica el estado actual del socket. Cuando queremos escribir una nueva opción de encabezado, primero debemos habilitar la escritura para una conexión activa o pasiva, y luego debemos indicar la longitud del nuevo encabezado antes de que se pueda escribir la carga útil del encabezado. La operación de lectura es más simple; sin embargo, también debemos habilitar la lectura primero antes de poder leer las opciones del encabezado. Cuando se crea un paquete TCP, se llama a la devolución de llamada del encabezado TCP. Esto sucede antes de la traducción de la dirección, por lo que podemos copiar la dirección de origen del socket en las opciones del encabezado. El lector puede extraer fácilmente el valor de la opción del encabezado y almacenarlo en un mapa BPF para que luego el consumidor pueda leer y mapear desde la dirección remota observada a la dirección real. La parte BPF del código de la primera ejecución tiene mucho menos de 100 líneas. ¡Bastante bien!
Preparar el código para producción
Sin embargo, el diablo está en los detalles. Primero, necesitamos una forma de eliminar registros antiguos del mapa BPF. El mejor momento para hacer esto es cuando el módulo conntrack elimina la conexión de su tabla. Este artículo de Arthur Chiao proporciona una buena descripción del módulo conntrack y la estructura interna del ciclo de vida de la conexión, por lo que es fácil encontrar la función correcta en las fuentes del kernel: nf_conntrack_destroy . Esta función recibe la entrada conntrack antes de eliminarla de la tabla interna. Dado que aquí es cuando finaliza oficialmente la conexión, también podemos agregar una sonda que también eliminará la conexión de nuestra tabla de mapeo.
En el programa sock ops, no especificamos en qué paquetes se inyecta la nueva opción de encabezado, asumiendo que se aplica a todos los paquetes. De hecho, esto es cierto, pero la lectura solo es efectiva cuando la conexión está en el estado establecido/reconocido, lo que significa que el lado del servidor no puede leer las opciones del encabezado del paquete SYN entrante. SYN-ACK también se procesa antes de la pila TCP normal y las opciones de encabezado no se pueden inyectar ni leer. De hecho, esta característica sólo funciona en ambos extremos si la conexión se ejecuta completamente con el primer PSH (paquete). Esto está perfectamente bien para una conexión que funcione, pero si el intento de conexión falla, el cliente no sabe a dónde estaba intentando conectarse. Este es un error crítico; esta información es útil para depurar problemas de red. Como sabemos, el equilibrio de carga de Kubernetes se implementa en el nodo cliente, por lo que podemos extraer la información de conntrack y almacenarla en el mismo formato que los datos recibidos a través del flujo. La función Conntrack ___nf_conntrack_confirm_ ayuda aquí: se llama cuando está a punto de confirmarse una nueva conexión, lo que para las conexiones TCP de cliente activo (salientes) ocurre cuando se envía el primer paquete SYN.
Con todas estas adiciones, el código se vuelve un poco inflado, pero aún tiene menos de 1000 líneas en total. El parche completo está disponible en este MR . ¡Es hora de habilitarlo en la configuración de nuestro experimento y verificar las métricas y la topología nuevamente!
Mirar:
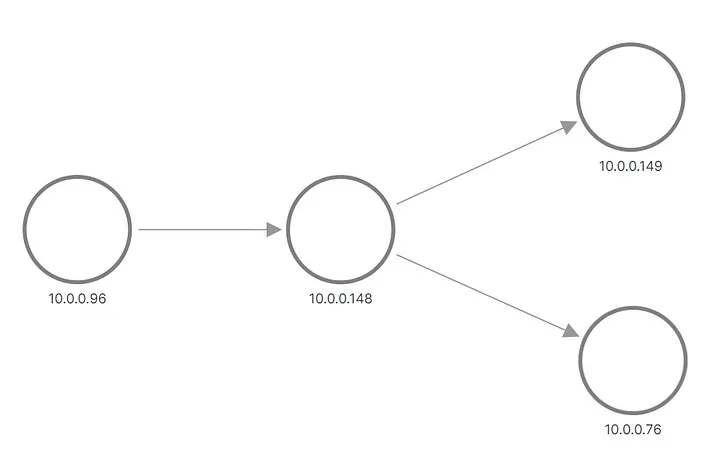
Topología correcta de la aplicación A/B
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuroEste artículo se publicó por primera vez en Yunyunzhongsheng ( https://yylives.cc/ ), todos son bienvenidos a visitarlo.