La industria generalmente reconoce la coubicación como una solución para mejorar la utilización de recursos y reducir costos. En el proceso de nativaización de la nube y reducción de costos y mejora de la eficiencia, iQiyi ha combinado con éxito la computación fuera de línea de big data, el procesamiento de contenido de audio y video y otras cargas de trabajo con negocios en línea, y ha logrado ganancias graduales. Este artículo se centra en big data como ejemplo para presentar el proceso práctico de implementar un sistema de implementación mixta de 0 a 1.
fondo
Los big data de iQIYI respaldan escenarios importantes como la toma de decisiones operativas, el crecimiento de usuarios, la distribución de publicidad, las recomendaciones de videos, la búsqueda y la membresía dentro de la empresa, proporcionando un motor basado en datos para el negocio. A medida que crecen las demandas empresariales, la cantidad de recursos informáticos necesarios aumenta día a día y el control de costes y el suministro de recursos se enfrentan a una mayor presión.
La informática de big data de iQIYI se divide en dos enlaces de procesamiento de datos: informática fuera de línea y informática en tiempo real, entre los cuales:
-
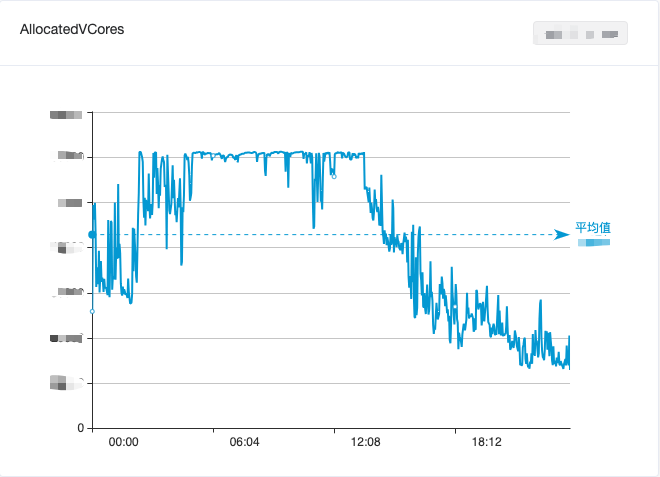
La computación fuera de línea incluye el procesamiento de datos basado en Spark, la construcción de un almacén de datos por hora o incluso por día basado en Hive y la consulta y análisis de informes correspondientes. Este tipo de cálculo generalmente comienza temprano en la mañana de cada día para calcular los datos del día anterior y termina en. la mañana. . De 0 a 8 en punto todos los días es el período pico de demanda de recursos informáticos. Los recursos totales del clúster a menudo son insuficientes y las tareas a menudo están en cola y atrasadas durante el día, lo que resulta en una gran cantidad de tiempo de inactividad. un desperdicio de recursos.
-
La computación en tiempo real incluye el procesamiento de flujo de datos en tiempo real representado por Kafka + Flink, que tiene requisitos de recursos relativamente estables.
Para equilibrar la utilización de los recursos de big data, combinamos la computación fuera de línea y la computación en tiempo real, lo que alivió en cierta medida el desperdicio de recursos inactivos durante el día. Sin embargo, aún no fue posible reducir los picos y llenar los valles de manera efectiva. y la utilización general de los recursos informáticos de big data aún se muestra "El fenómeno de marea de "valle diurna y pico temprano en la mañana" se muestra en la Figura 1.
Figura 1. Cambios en el uso de CPU del clúster de computación de big data en un día
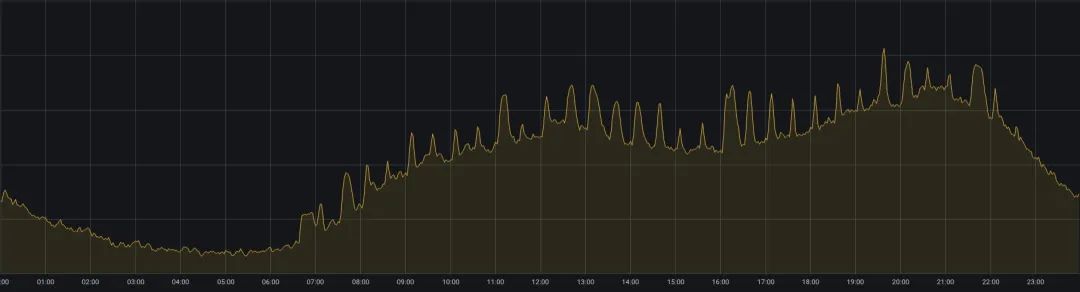
El negocio online de iQiyi enfrenta otro problema: el equilibrio entre la calidad del servicio y la utilización de recursos. El negocio en línea atiende principalmente escenarios como la reproducción de videos de iQiyi. Hay más usuarios viendo videos al mediodía y por la noche, y el uso de recursos tiene un fenómeno de marea de "picos durante el día y mínimos temprano en la mañana" (como se muestra en la Figura 2). . Para garantizar la calidad del servicio durante los períodos pico, las empresas en línea suelen reservar más recursos, lo que hace que la utilización de los recursos sea muy insatisfactoria.
Figura 2. Cambios en el uso de CPU del clúster empresarial en línea en un día
Para mejorar la utilización, la plataforma de contenedores de generación anterior desarrollada por iQiyi adoptó una estrategia de sobreventa estática de CPU. Aunque este método tiene un efecto significativo en la mejora de la utilización, está limitado por factores como las capacidades centrales y no puede evitar interrupciones entre servicios en un solo servicio. Los problemas ocasionales de competencia de recursos también han provocado una calidad inestable del servicio comercial en línea, y este problema nunca se ha resuelto adecuadamente.
Con el avance de la nativación de la nube, la plataforma de contenedores iQiyi se ha transformado gradualmente en la pila de tecnología Kubernetes (en lo sucesivo, "K8"). En los últimos años, han aparecido muchos proyectos de código abierto relacionados con la implementación conjunta en la comunidad K8, y también existen algunas prácticas de implementación conjunta en la industria [1] . En este contexto, el equipo de la plataforma informática ajustó su dirección de trabajo de "overbooking estático" a "overbooking dinámico + implementación mixta".
Como el negocio fuera de línea más típico, big data es pionero en intentar implementar la coubicación. Por un lado, los grandes volúmenes de datos tienen requisitos de recursos informáticos relativamente estables y, por otro lado, los negocios de grandes datos y los negocios en línea pueden lograr efectos complementarios en muchas dimensiones y la utilización de los recursos se puede mejorar por completo mediante la ubicación conjunta.
Con base en el análisis anterior, el equipo de la plataforma informática iQiyi y el equipo de big data comenzaron a explorar la ubicación conjunta.
Diseño de plano de ubicación mixta.
El sistema de big data de iQiyi se basa en el ecosistema Apache Hadoop de código abierto y utiliza YARN como sistema de programación de recursos informáticos. El negocio en línea se basa en K8. Lo primero que debe resolverse es cómo conectar dos sistemas de programación de recursos diferentes. la solución de coubicación.
Generalmente existen dos soluciones coubicadas en la industria:
-
Opción 1: ejecutar directamente trabajos de big data (Spark, Flink, etc., MapReduce no es compatible) en K8 y usar su programador nativo
-
Opción 2: Ejecute NodeManager de YARN (en lo sucesivo, "NM") en K8 y los trabajos de big data aún se programarán a través de YARN.
Después de una cuidadosa consideración, elegimos la opción dos por las dos razones principales siguientes:
-
En la actualidad, la gran mayoría de los trabajos de informática de big data en la empresa se programan en función de YARN. Tiene potentes funciones de programación (multi-inquilino, múltiples colas, reconocimiento de rack), excelente rendimiento de programación (más de 5.000 contenedores/s) y mecanismos de seguridad completos. (Kerberos, Delegation Tokens) y es compatible con casi todos los marcos informáticos de big data, como MapReduce, Spark y Flink. Desde la introducción de YARN en 2014, el equipo de big data de iQiyi ha creado una serie de plataformas a su alrededor para desarrollo, operación y mantenimiento, gobernanza informática, etc., proporcionando a los usuarios internos un proceso conveniente de desarrollo de big data. Por lo tanto, la compatibilidad con YARN API es una de las consideraciones importantes al seleccionar una solución híbrida.
-
Aunque K8s tiene un programador por lotes, no es lo suficientemente maduro y existe un cuello de botella en el rendimiento de la programación (<1k contenedores/s), que no es suficiente para satisfacer las necesidades de los escenarios de big data.
A nivel de K8, ambas partes necesitan un conjunto de interfaces estándar para gestionar y utilizar los recursos de coubicación. Hay muchos proyectos excelentes en la comunidad, como el Koordinator de código abierto de Alibaba [2], el proyecto FinOps de código abierto de Tencent Crane [3], el proyecto de código abierto Katalyst de ByteDance [4], etc. Entre ellos, Koordinator tiene adaptabilidad "natural" con el sistema operativo Dragon Lizard (una de las alternativas de CentOS que iQiyi está probando) y puede colaborar para lograr monitoreo de carga comercial en línea, compromiso excesivo de recursos inactivos, programación jerárquica de tareas y garantía de QoS de carga de trabajo fuera de línea. , etc., satisfacen las necesidades de iQiyi.
Con base en la selección de tecnología anterior, a través de una transformación profunda, colocamos YARN NM en contenedores y lo ejecutamos en K8s Pod, y podemos detectar los recursos informáticos de hiperresolución que cambian dinámicamente en tiempo real de Koordinator, logrando así expansión y contracción automática horizontal y vertical, y Maximizar la utilización de recursos mixtos.
Evolución de la estrategia de programación co-ubicada
La coubicación de big data y negocios en línea ha pasado por múltiples etapas de evolución tecnológica, que presentaremos en detalle a continuación.
Etapa 1: multiplexación de tiempo compartido por la noche
Para verificar rápidamente la solución, primero completamos la transformación de contenedorización de NM en K8s Pod (Koordinator no se usó en esta etapa) y lo expandimos al clúster Hadoop existente como un nodo elástico. A nivel de big data, YARN programa uniformemente estos NM de K8 junto con los NM de otras máquinas físicas. Estos nodos elásticos comienzan y se detienen regularmente todos los días y solo funcionan entre las 0 y las 9 en punto.
En esta etapa, hemos completado más de 20 renovaciones. Estos son los 5 puntos principales de renovación:
Punto de mejora 1: grupo de IP fija
El NM tradicional se implementa en una máquina física y la IP y el nombre de dominio de la máquina son fijos. La lista blanca de nodos (archivo esclavo) se configura en YARN ResourceManager (en lo sucesivo, "RM") para permitir que el nodo se una. grupo. Al mismo tiempo, el clúster YARN utiliza Kerberos para implementar la autenticación de seguridad. Antes de la implementación, el archivo keytab debe generarse en Kerberos KDC y distribuirse al nodo NM.
Para adaptarnos a la lista blanca y al mecanismo de autenticación de seguridad de YARN, utilizamos la función de IP estática de desarrollo propio para clústeres construidos por nosotros mismos. Cada IP estática tendrá un recurso K8s StaticIP correspondiente para registrar la relación correspondiente entre Pod e IP. Al mismo tiempo, se basa en la nube pública. También implementaremos el CRD StaticIP de desarrollo propio en el clúster y crearemos recursos StaticIP para cada IP estática, proporcionando así a YARN un grupo de IP fijas que tiene el mismo uso que el clúster de construcción propia. . Cree registros DNS y archivos de tabla de claves con anticipación según la IP en el grupo de IP fijo, de modo que la configuración requerida se pueda obtener rápidamente cuando se inicie NM.
Punto de transformación 2: operador de hilo elástico
Para que los usuarios no se den cuenta de la introducción de nodos elásticos, agregamos NM elástico al clúster Hadoop YARN existente. Teniendo en cuenta la complejidad de los recursos dinámicamente conscientes en implementaciones mixtas posteriores, elegimos el operador Elastic YARN de desarrollo propio para gestionar mejor el ciclo de vida de Elastic NM.
En esta etapa, las estrategias soportadas por el Operador Elastic YARN son:
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
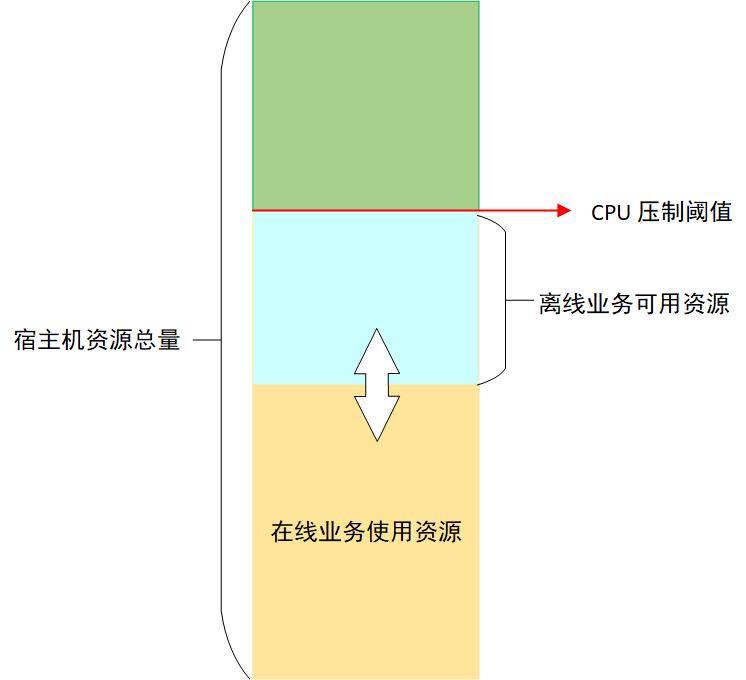
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
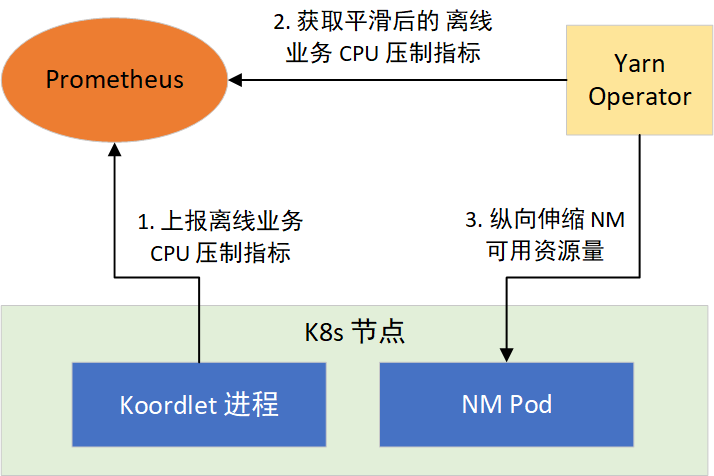
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
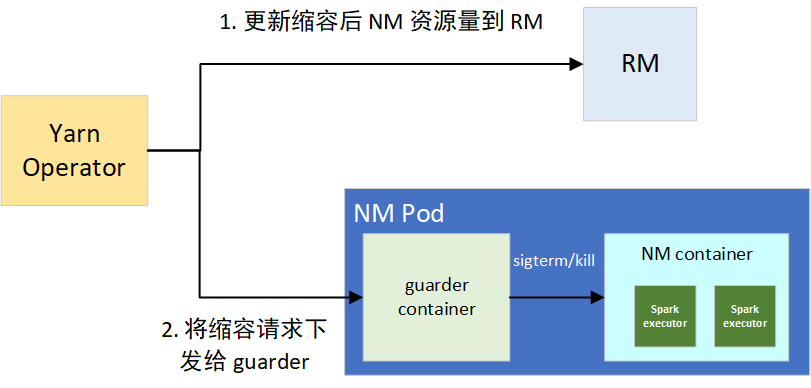
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
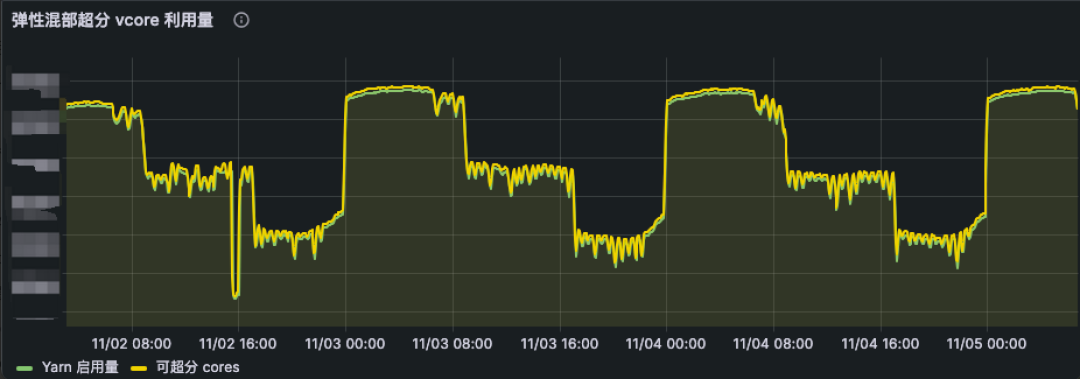
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
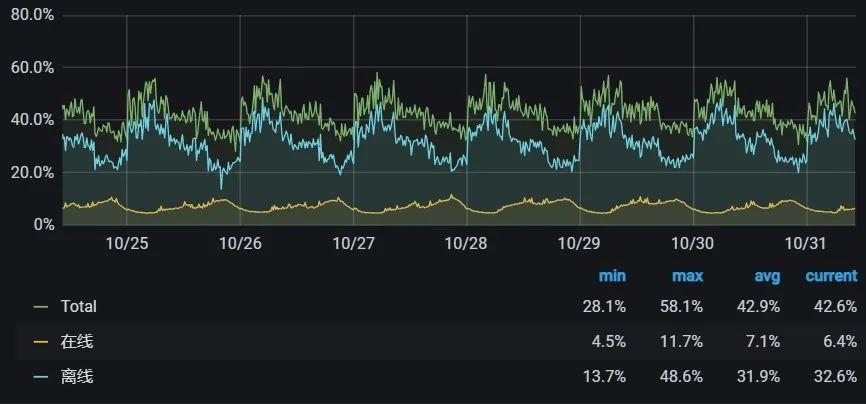
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。