
Ideas de ajuste de retardo maestro-esclavo
1. ¿Qué es el retraso maestro-esclavo?
La esencia es que la reproducción de la biblioteca esclava no puede seguir el ritmo de la biblioteca maestra y la etapa de reproducción se retrasa.
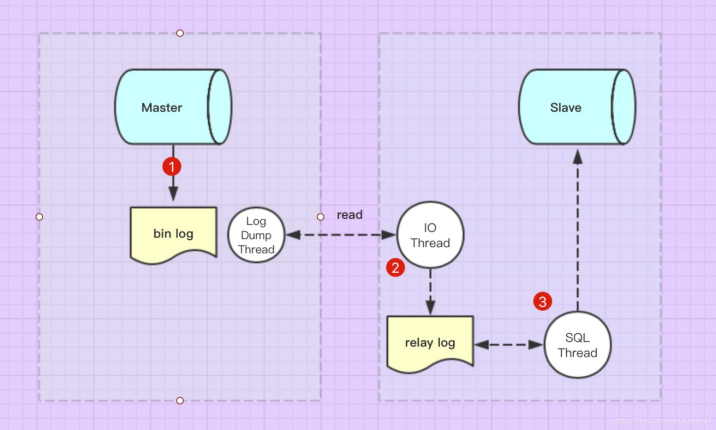
2. ¿Cuáles son las causas comunes del retraso entre maestro y esclavo?
1. Para transacciones grandes, el tiempo de reproducción de la biblioteca esclava es largo, lo que provoca un retraso maestro-esclavo.
2. La biblioteca principal escribe con demasiada frecuencia y la biblioteca esclava no puede seguir el ritmo de la reproducción.
3. Configuración de parámetros irrazonable
4. Diferencias en hardware maestro-esclavo
5. Retraso de la red
6. La tabla no tiene una clave principal o el índice se actualiza con frecuencia y frecuencia.
7. Algunas arquitecturas que separan la lectura y la escritura ejercen mayor presión sobre la biblioteca esclava.
3. ¿Cuáles son los métodos para solucionar el retraso maestro-esclavo?
1. Para transacciones grandes, divídalas en transacciones pequeñas.
2. Habilite la replicación paralela
3. Actualizar el hardware esclavo
4. Intenta tener claves primarias
4. ¿Qué es la replicación paralela y cuáles son sus parámetros?
Revise el viaje de la replicación paralela de MySQL
MySQL5.6 se basa en la replicación paralela a nivel de base de datos
esclavo-paralelo-tipo=BASE DE DATOS (transacciones en diferentes bibliotecas, sin conflictos de bloqueo)
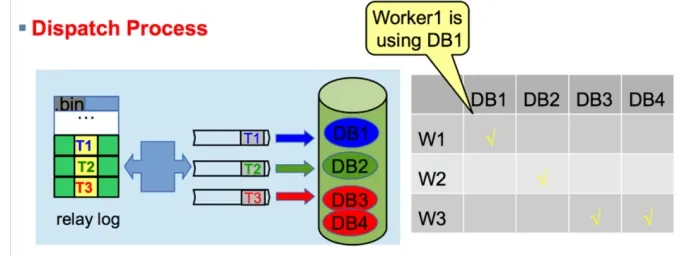
MySQL5.7 Replicación paralela basada en confirmación de grupo
slave-parallel-type=LOGICAL_CLOCK : Commit-Parent-Based模式(同一组的事务[last-commit相同]No hay conflicto de bloqueo. En el mismo grupo, no debe haber conflicto; de lo contrario, no hay forma de convertirse en el mismo grupo).
Lo anterior es la configuración de la biblioteca esclava. La replicación paralela depende del envío grupal de la biblioteca maestra (tenga en cuenta la distinción entre replicación grupal).
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
-
binlog_group_commit_sync_delay: Cuánto tiempo esperar antes de enviar el grupo -
binlog_group_commit_sync_no_delay_count: ¿Cuántas transacciones esperar antes de comprometer el grupo?
Todos los parámetros anteriores dependen de la situación de ocupación de la base de datos principal. Si el negocio no es frecuente, será muy vergonzoso.
binlog_group_commit_sync_no_delay_count: Este parámetro está establecido en 2
Por ejemplo, si solo un subproceso ejecuta una transacción y la segunda transacción se ejecuta 24 horas después, entonces esta transacción debe esperar 24 horas antes de enviarse, lo cual es muy frustrante.
binlog_group_commit_sync_delay
Si se establece en 200 ms y solo un subproceso ejecuta una transacción, se puede enviar en 10 ms, pero debe esperar 200 ms.
Generalmente, ambos se configuran en línea. Por ejemplo, es como un pequeño bote que transporta personas a través de un río.
Supongamos que nuestros parámetros están configurados así:
binlog_group_commit_sync_delay=200;
binlog_group_commit_sync_no_delay_count=2
Puede ir directamente si necesita 200 ms, o puede ir directamente si necesita 2 personas. Esto es mucho más fácil de usar, pero sigue siendo vergonzoso cuando el negocio no está ocupado.

Replicación paralela MySQL8.0 basada en conjunto de escritura
Detección de conflictos basada en la clave principal (binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION, si no hay conflicto en la clave principal o una clave única no vacía de la fila modificada, se puede paralelizar)
Algoritmo de detección de transacciones:transaction_write_set_extraction = XXHASH64
MySQL tendrá una variable para almacenar el valor HASH de la transacción enviada. Después del hash, los valores de la clave primaria (o clave única) modificada por todas las transacciones enviadas se compararán con el conjunto de esa variable para determinar si el cambio. de filas entran en conflicto con él, y para determinar las dependencias
Las variables mencionadas aquí se pueden establecer en tamaño a través de esto:binlog_transaction_dependency_history_size
Este tipo de granularidad ha alcanzado el nivel de fila, es decir, la granularidad paralela es más refinada en este momento y la velocidad paralela será más rápida. En algunos casos, no es exagerado decir que el paralelismo del esclavo excede el. maestro ( el maestro es una escritura de un solo subproceso, el esclavo también puede reproducir en paralelo )
En pocas palabras, es una reproducción paralela basada en filas. Diferentes filas en el nivel rc no tendrán conflictos de bloqueo.
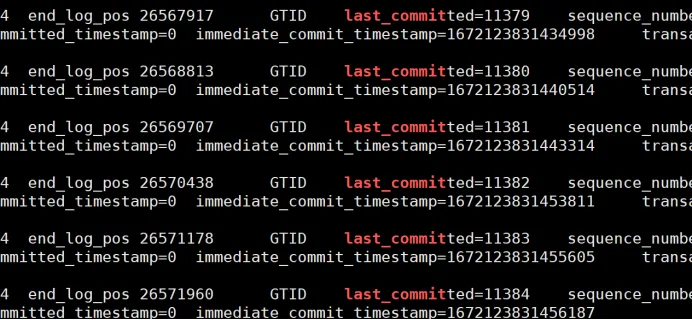
Rendimiento de envío grupal:
Compruebe si el valor last_committed del binlog de la biblioteca principal es coherente, si es coherente, se puede reproducir en paralelo. Si es inconsistente, solo se puede reproducir en serie.
5. Análisis práctico
5.1 Verifique el retraso maestro-esclavo en línea
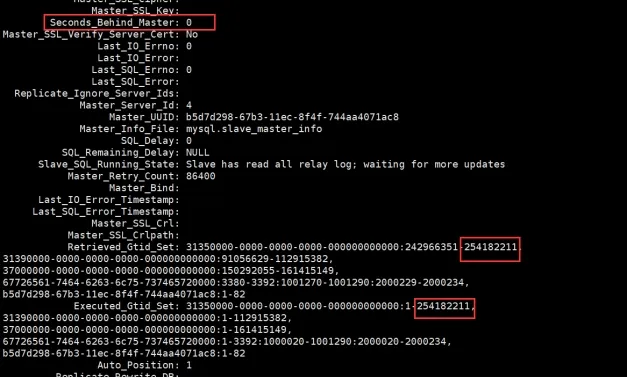
Seconds_Behind_Master: 48828
Se puede ver que el retraso es muy alto, cerca de 14 horas. En este momento, la biblioteca principal también escribe datos constantemente, aproximadamente 6 minutos para un binlog y otro para 500M.
5.2 Ver la configuración de replicación actual
Ver la configuración de la biblioteca esclava:
greatsql> show variables like '%slave%para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 128 |
+------------------------+---------------+
2 rows in set (0.02 sec)
Fenómeno de retraso:
La biblioteca esclava ha estado persiguiendo, lo que indica que no es una gran transacción, pero Seconds_Behind_Masterla demora ha ido aumentando.
Retrieved_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:242966351-253068975,
00000000-0000-0040-0095-5fff003b4b99:91056629-110569633,
00000000-0000-005c-0ced-7bae003b4b99:150292055-160253193,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Executed_Gtid_Set: 00000000-0000-0024-0046-41a8003b4b99:1-252250235,
00000000-0000-0040-0095-5fff003b4b99:1-109120315,
00000000-0000-005c-0ced-7bae003b4b99:1-159504296,
31f4399f-ade5-11ed-a544-00163ebdeb51:1-12,
Auto_Position: 1
En este momento, se sospecha que no hay replicación paralela y es posible que la biblioteca principal no haya configurado el envío grupal (solo una suposición)
5.3 Para una mayor verificación, consulte el binlog de la biblioteca principal
Verifique la configuración de parámetros de la biblioteca principal: aún las reglas enviadas para el grupo
greatsql> show variables like '%binlog_transac%';
+--------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------+----------+
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
+--------------------------------------------+----------+
4 rows in set (0.02 sec)
Mire la configuración del envío grupal: significa que no hay envío grupal.
greatsql> show variables like '%group%delay%';
+-----------------------------------------+-------+
| Variable_name | Value |
+-----------------------------------------+-------+
| binlog_group_commit_sync_delay | 0 |
| binlog_group_commit_sync_no_delay_count | 0 |
+-----------------------------------------+-------+
2 rows in set (0.01 sec)
Después de una verificación adicional, mirando el binlog, encontramos que last_committed es realmente diferente, lo que indica que el paralelismo no es posible.

5.4 Establecer parámetros para la biblioteca principal y analizar su binlog nuevamente
se binlog_transaction_dependency_trackingcambiará al WRITESETmodo
greatsql> show variables like '%transaction%';
+----------------------------------------------------------+-----------------+
| Variable_name | Value |
+----------------------------------------------------------+-----------------+
| binlog_direct_non_transactional_updates | OFF |
| binlog_transaction_compression | OFF |
| binlog_transaction_compression_level_zstd | 3 |
| binlog_transaction_dependency_history_size | 25000 |
| binlog_transaction_dependency_tracking | WRITESET |
| kill_idle_transaction | 300 |
| performance_schema_events_transactions_history_long_size | 10000 |
| performance_schema_events_transactions_history_size | 10 |
| replica_transaction_retries | 10 |
| session_track_transaction_info | OFF |
| slave_transaction_retries | 10 |
| transaction_alloc_block_size | 8192 |
| transaction_allow_batching | OFF |
| transaction_isolation | REPEATABLE-READ |
| transaction_prealloc_size | 4096 |
| transaction_read_only | OFF |
| transaction_write_set_extraction | XXHASH64 |
+----------------------------------------------------------+-----------------+
17 rows in set (0.00 sec)
Verifique su binlog nuevamente y vea que muchos de ellos se pueden reproducir en paralelo.

5.5 Optimización completada
Aunque la biblioteca principal está escribiendo en lotes grandes, el retraso se está reduciendo lentamente. Es sólo cuestión de tiempo que se ponga al día. Hoy es 0.
Disfruta de GreatSQL :)
Acerca de GreatSQL
GreatSQL es una base de datos nacional independiente de código abierto adecuada para aplicaciones de nivel financiero. Tiene muchas características principales, como alto rendimiento, alta confiabilidad, alta facilidad de uso y alta seguridad. Puede usarse como un reemplazo opcional de MySQL o Percona Server. y se utiliza en entornos de producción online, completamente gratuito y compatible con MySQL o Percona Server.
Enlaces relacionados: Comunidad GreatSQL Gitee GitHub Bilibili
Gran comunidad SQL:

Sugerencias y comentarios sobre recompensas de la comunidad: https://greatsql.cn/thread-54-1-1.html
Detalles de la presentación del premio del blog comunitario: https://greatsql.cn/thread-100-1-1.html
(Si tiene alguna pregunta sobre el artículo o tiene ideas únicas, puede ir al sitio web oficial de la comunidad para preguntarlas o compartirlas ~)
Grupo de intercambio técnico:
Grupo WeChat y QQ:
Grupo QQ: 533341697
Grupo WeChat: agregue GreatSQL Community Assistant (ID de WeChat:) wanlidbccomo amigo y espere a que el asistente de la comunidad lo agregue al grupo.