
Basado en las preguntas comunes de Apache Doris sobre el proceso de lectura y escritura, el mecanismo de coherencia de copia, el mecanismo de almacenamiento, el mecanismo de alta disponibilidad, etc., se clasifica y responde en forma de preguntas y respuestas. Antes de comenzar, primero expliquemos los términos relacionados con este artículo:
-
FE : Frontend, el nodo front-end de Doris. Principalmente responsable de recibir y devolver solicitudes de clientes, metadatos, gestión de clústeres, generación de planes de consultas, etc.
-
BE : Backend, el nodo backend de Doris. Principalmente responsable del almacenamiento y gestión de datos, ejecución del plan de consultas, etc.
-
BDBJE : Oracle Berkeley DB Java Edition.En Doris, BDBJE se utiliza para completar la persistencia de los registros de operaciones de metadatos, la alta disponibilidad de FE y otras funciones.
-
Tableta : La tableta es la unidad de almacenamiento física real de una tabla. Una tabla se almacena en unidades de tabletas en la capa de almacenamiento distribuido formada por BE según particiones y depósitos. Cada tableta incluye metainformación y varios RowSets consecutivos.
-
RowSet : RowSet es una colección de datos de un cambio de datos en la tableta. Los cambios de datos incluyen importación, eliminación, actualización, etc. Registros RowSet por información de versión. Cada cambio generará una versión.
-
Versión : consta de dos atributos: Inicio y Fin, y mantiene información de registro de los cambios de datos. Generalmente se utiliza para representar el rango de versiones de RowSet. Después de una nueva importación, se genera un RowSet con inicio y fin iguales. Después de la compactación, se genera una versión de RowSet por rango.
-
Segmento : Representa segmentos de datos en RowSet. Múltiples segmentos constituyen un RowSet.
-
Compactación : el proceso de fusionar versiones consecutivas de RowSet se denomina compactación y los datos se comprimirán durante el proceso de fusión.
-
Columna clave, columna Valor : en Doris, los datos se describen lógicamente en forma de tabla. Una tabla incluye filas (Fila) y columnas (Columna). La fila es una fila de datos del usuario y la columna se utiliza para describir diferentes campos en una fila de datos. La columna se puede dividir en dos categorías: clave y valor. Desde una perspectiva empresarial, Clave y Valor pueden corresponder a columnas de dimensiones y columnas de indicadores respectivamente. La columna Clave de Doris es la columna especificada en la declaración de creación de la tabla. La columna que sigue a la palabra clave clave única o clave agregada o clave duplicada en la declaración de creación de la tabla es la columna Clave. Además de la columna Clave, el resto es el Valor columna.
-
Modelo de datos : el modelo de datos de Doris se divide principalmente en tres categorías: agregado, único y duplicado.
-
Tabla base : en Doris, llamamos Tabla base a la tabla creada por el usuario a través de la declaración de creación de la tabla. La tabla base almacena los datos básicos almacenados de la manera especificada por la declaración de creación de la tabla del usuario.
-
Tabla ROLLUP : encima de la tabla base, los usuarios pueden crear cualquier cantidad de tablas ROLLUP. Estos datos ROLLUP se generan en función de la tabla Base y se almacenan físicamente de forma independiente. La función básica de la tabla ROLLUP es obtener datos agregados más gruesos basados en la tabla Base, similar a una vista materializada.
P1: ¿Cuál es la diferencia entre la partición Doris y el agrupamiento?
Doris admite dos niveles de partición de datos:
-
La primera capa es Partición, que admite métodos de división de Rango y Lista (similar al concepto de tabla de particiones de MySQL). Varias particiones forman una tabla y la partición puede considerarse como la unidad de gestión lógica más pequeña. Los datos se pueden importar y eliminar solo para una partición.
-
La segunda capa es Bucket (la tableta también se llama cubeta), que admite métodos de división Hash y Random. Cada tableta contiene varias filas de datos y los datos entre tabletas no tienen intersección y se almacenan físicamente de forma independiente. La tableta es la unidad de almacenamiento físico más pequeña para operaciones como el movimiento y la copia de datos.
También puede utilizar solo un nivel de partición. Si no escribe una declaración de partición al crear una tabla, Doris generará una partición predeterminada, que es transparente para el usuario.
La indicación es la siguiente:
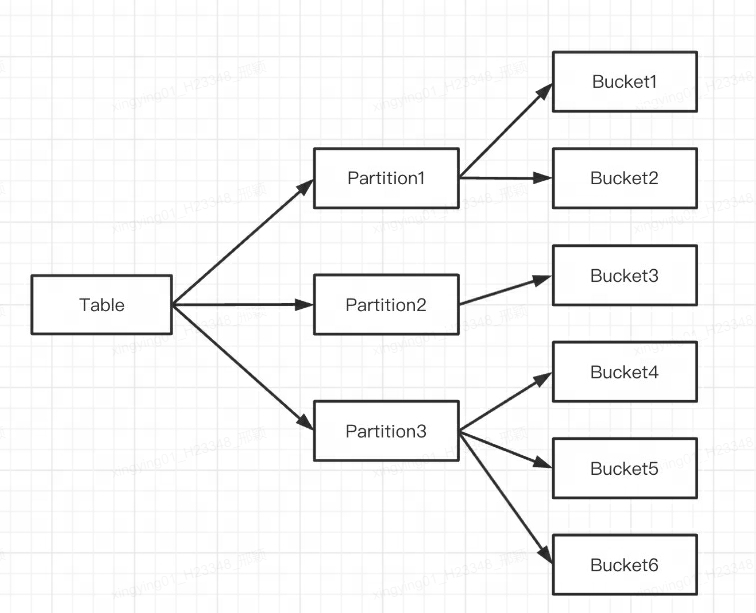
Lógicamente, varias Tabletas pertenecen a diferentes particiones (Partición), una Tableta solo pertenece a una Partición y una Partición contiene varias Tabletas. Debido a que la Tableta se almacena físicamente de forma independiente, se puede considerar que la Partición también es físicamente independiente.
Lógicamente hablando, la mayor diferencia entre particionar y agrupar es que la agrupación divide aleatoriamente la base de datos, mientras que la partición divide la base de datos de forma no aleatoria.
¿Cómo garantizar múltiples copias de datos?
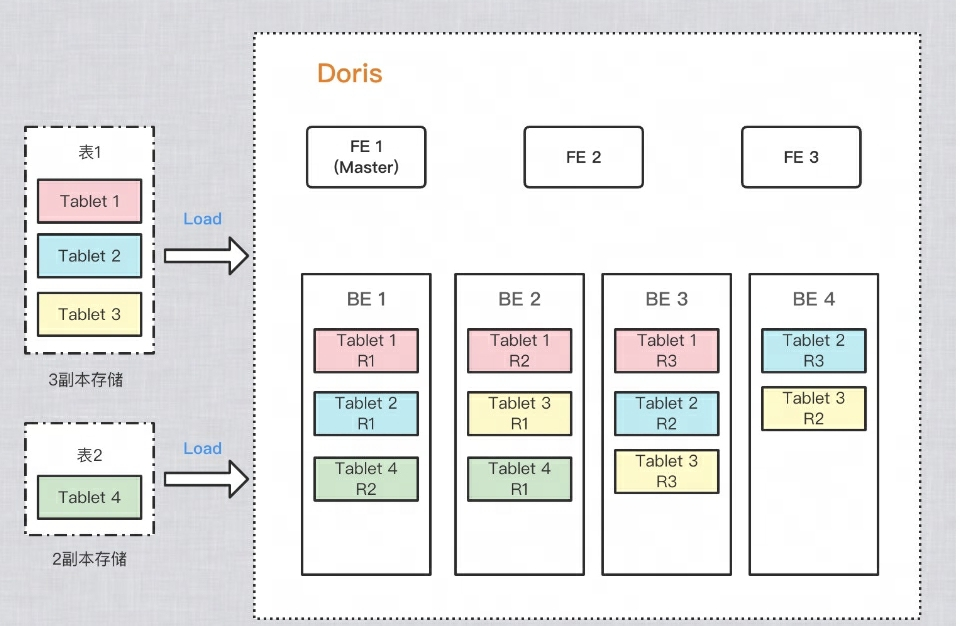
Para mejorar la confiabilidad del almacenamiento de datos y el rendimiento de los cálculos, Doris realiza varias copias de cada tabla para su almacenamiento. Cada copia de datos se llama copia. Doris utiliza la tableta como unidad básica para almacenar copias de datos. De forma predeterminada, un fragmento tiene 3 copias. Al crear una tabla, puede PROPERTIESconfigurar el número de copias en:
PROPERTIES
(
"replication_num" = "3"
);
Como ejemplo en la figura siguiente, se importan dos tablas a Doris respectivamente: la tabla 1 se almacena en 3 copias después de la importación y la tabla 2 se almacena en 2 copias después de la importación. La distribución de datos es la siguiente:
P2: ¿Por qué necesita agrupar?
Para dividir en depósitos y evitar sesgos de datos, dispersar la lectura de IO y mejorar el rendimiento de las consultas, se pueden distribuir diferentes copias de la tableta en diferentes máquinas, de modo que el rendimiento de IO de diferentes máquinas se pueda utilizar por completo durante las consultas.
P3: ¿Cuál es la estructura de almacenamiento y el formato de los archivos físicos?
Cada importación de Doris puede considerarse como una transacción y se generará un RowSet. Y RowSet incluye múltiples segmentos, es decir Tablet-->Rowset-->Segment. Entonces, ¿cómo almacena BE estos archivos?
La estructura de almacenamiento de Doris.
Doris storage_root_pathconfigura la ruta de almacenamiento a través de y los archivos de segmento se almacenan en tablet_idel directorio y son administrados por SchemaHash. Puede haber varios archivos de segmento, que generalmente se dividen según el tamaño y el valor predeterminado es 256 MB. El directorio de almacenamiento y las reglas de nomenclatura de archivos de segmento son:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
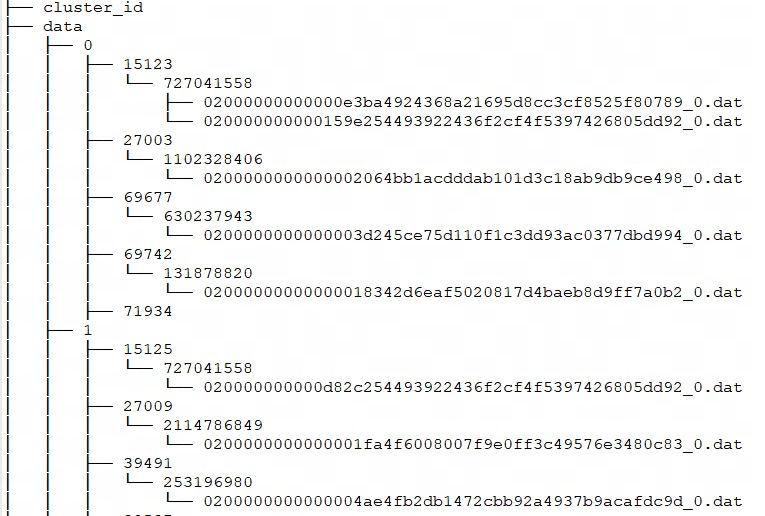
Ingrese storage_root_pathal directorio y podrá ver la siguiente estructura de almacenamiento:
-
${shard}: Eso es 0, 1 en la figura anterior. BE lo crea automáticamente en el directorio de almacenamiento y es aleatorio. Aumentará con el aumento de datos. -
${tablet_id}: Es decir, 15123, 27003, etc. en la figura anterior, que es el ID del depósito mencionado anteriormente. -
${schema_hash}: Es decir, 727041558, 1102328406, etc. en la imagen de arriba. Debido a que la estructura de una tabla se puede cambiar, se genera una para cada versión del esquemaSchemaHashpara identificar los datos de esa versión. -
${segment_id}.dat: El primero esrowset_id, es decir, 02000000000000e3ba4924368a21695d8cc3cf8525f80789 en la figura anterior;${segment_id}es el RowSet actualsegment_id, comenzando desde 0 y aumentando.
Formato de almacenamiento de archivos de segmentos
El formato de archivo general de Segment se divide en tres partes: área de datos, área de índice y pie de página, como se muestra en la siguiente figura:

-
Región de datos: se utiliza para almacenar la información de datos de cada columna. Los datos aquí se cargan en páginas a pedido. Las páginas contienen los datos de la columna y cada página tiene 64k.
-
Región de índice: Doris almacena los datos de índice de cada columna en la región de índice. Los datos aquí se cargarán de acuerdo con la granularidad de la columna, por lo que se almacenan por separado de la información de datos de la columna.
-
Información de pie de página: contiene información de metadatos del archivo, suma de verificación del contenido, etc.
P4: ¿Cuáles son las limitaciones de DML de los diferentes modelos de mesa de Doris?
-
Actualización: la declaración de actualización actualmente solo admite el modelo CLAVE ÚNICA y solo admite la actualización de la columna Valor.
-
Eliminar: 1) Si el modelo de tabla utiliza una clase agregada (AGREGADO, ÚNICO), la operación Eliminar solo puede especificar las condiciones en la columna Clave; 2) Esta operación también eliminará los datos del Índice acumulativo relacionado con este Índice base.
-
Insertar: todos los modelos de datos se pueden insertar.
¿Cómo implementar Insertar? ¿Cómo se pueden consultar los datos una vez insertados?
-
Modelo AGREGADO : en la fase de inserción, los datos incrementales se escriben en RowSet en el método Append, y en la fase de consulta, el método Merge on Read se utiliza para fusionar. Es decir, los datos se escriben primero en un nuevo RowSet al importar y no se realizará la deduplicación después de la escritura. La clasificación concurrente multidireccional solo se realizará cuando se inicie una consulta. Al realizar la clasificación por combinación multidireccional, duplique los datos se ordenarán y las claves se organizarán juntas y se agregarán. La clave de la versión superior sobrescribirá la clave de la versión inferior y, en última instancia, solo se devolverá al usuario el registro con la versión más alta.
-
Modelo DUPLICADO : Este modelo está escrito de manera similar al anterior y no habrá operaciones de agregación en la fase de lectura.
-
Modelo ÚNICO : Antes de la versión 1.2, este modelo era esencialmente un caso especial del modelo agregado, con un comportamiento consistente con el modelo AGREGADO. Dado que Merge on Read implementa el modelo de agregación , el rendimiento en algunas consultas de agregación es deficiente. Doris introdujo una nueva implementación del modelo Unique después de la versión 1.2, Merge on Write , que marca y elimina datos sobrescritos y actualizados al escribir. Durante la consulta, todos los datos marcados y eliminados se eliminan. Los datos se filtrarán a nivel de archivo. y los datos leídos serán los datos más recientes, lo que elimina el proceso de agregación de datos en la fusión en tiempo de lectura y puede admitir la inserción de múltiples predicados en muchos casos.
En pocas palabras, el flujo de procesamiento de Merge on Write es:
-
Para cada clave, encuentre su posición en los datos base (RowSetid + Segmentid + número de fila) [El árbol de intervalos de clave primaria a nivel de segmento se mantiene en la memoria para acelerar las consultas]
-
Si la clave existe, marque la fila de datos para eliminarla. La información marcada para su eliminación se registra en Eliminar mapa de bits, donde cada segmento tiene su correspondiente Eliminar mapa de bits.
-
Escriba los datos actualizados en el nuevo RowSet, complete la transacción y haga que los nuevos datos sean visibles, es decir, que el usuario pueda consultarlos.
-
Al realizar una consulta, lea Eliminar mapa de bits, filtre las filas marcadas para su eliminación y solo devuelva datos válidos [Para todos los segmentos visitados, consulte según la versión de mayor a menor]
A continuación se presenta la implementación del proceso de escritura y el proceso de lectura.
Proceso de escritura : al escribir datos, primero se creará el índice de clave principal de cada segmento y luego se actualizará Eliminar mapa de bits.
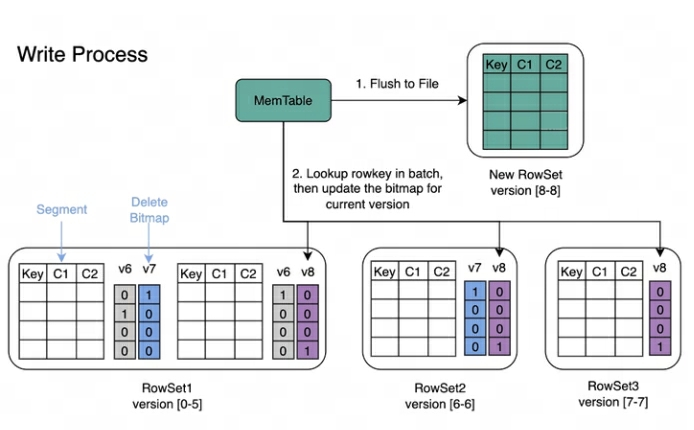
Proceso de lectura : El proceso de lectura de Bitmap se muestra en la siguiente figura. De la imagen podemos saber:
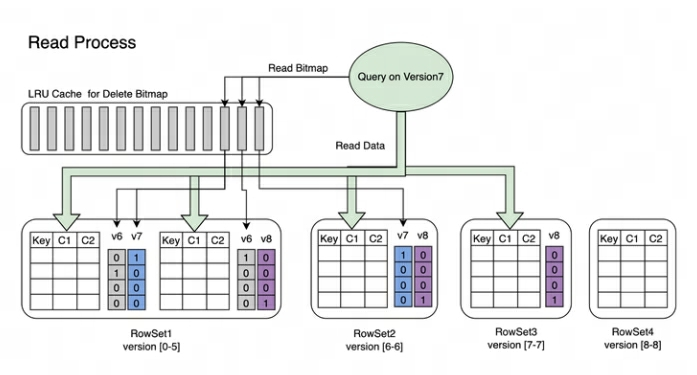
-
Una Consulta que solicite la versión 7 solo verá datos correspondientes a la versión 7.
-
Al leer los datos de RowSet5, los mapas de bits generados por las modificaciones de V6 y V7 se fusionarán para obtener el DeleteBitmap completo correspondiente a la versión 7, que se utiliza para filtrar los datos.
-
En el ejemplo anterior, la importación de la versión 8 cubre un dato en el Segmento2 de RowSet1, pero la consulta que solicita la versión 7 aún puede leer los datos.
¿Cómo se implementa la actualización?
El proceso de actualización del modelo ÚNICO es esencialmente Seleccionar+Insertar.
-
La actualización utiliza la lógica de filtrado Where propia del motor de consulta para filtrar las filas que deben actualizarse de la tabla que se va a actualizar y, en función de esto, mantener Eliminar mapa de bits y generar datos recién insertados.
-
Luego ejecute la lógica de inserción, el proceso específico es similar a la lógica de escritura del modelo ÚNICO mencionada anteriormente.
P5: ¿Cómo se implementa la eliminación de Doris? ¿Se generará también un RowSet? ¿Cómo eliminar los datos correspondientes?
-
La eliminación de Doris también generará un conjunto de filas. En el modo DELETE, los datos en realidad no se eliminan, pero se registran las condiciones de eliminación de datos. Almacenado en metainformación. Al ejecutar Base Compaction, las condiciones de eliminación se fusionarán en la versión Base.
-
Doris también admite LOAD_DELETE bajo el modelo UNIQUE KEY, que permite la eliminación de datos mediante la importación por lotes de las claves que se eliminarán y puede admitir capacidades de eliminación de datos a gran escala. La idea general es agregar un identificador de estado de eliminación al registro de datos y la clave eliminada se comprimirá durante el proceso de compactación. La compactación es el principal responsable de fusionar múltiples versiones de RowSet.
P6: ¿Qué índices tiene Doris?
Actualmente, Doris admite principalmente dos tipos de índices:
-
Índices inteligentes integrados, incluidos índices de prefijos e índices ZoneMap.
-
Los índices secundarios creados manualmente por los usuarios incluyen índices invertidos, índices Bloomfilter, índices Ngram Bloomfilter e índices Bitmap.
El índice ZoneMap es una información de índice que se mantiene automáticamente para cada columna en formato de almacenamiento de columnas, incluido Min/Max, el número de valores nulos, etc. Esta indexación es transparente para el usuario.
¿Qué nivel es el índice?
-
Ahora todos los índices en Doris son locales de nivel BE, como el índice invertido, el índice Bloomfilter, el índice Ngram Bloomfilter y el índice Bitmap, el índice de prefijo y el índice ZoneMap, etc.
-
Doris no tiene un Índice Global. En un sentido amplio, las particiones + claves de depósito también se pueden considerar globales, pero son relativamente generales.
¿Cuál es el formato de almacenamiento del índice?
En Doris, los datos de índice de cada columna se almacenan uniformemente en la región de índice del archivo de segmento. Los datos aquí se cargan de acuerdo con la granularidad de la columna, por lo que se almacenan por separado de la información de datos de la columna. Aquí tomamos como ejemplo el índice de prefijo del índice de clave corta.
El índice de prefijo de índice de clave corta es un método de índice basado en la clasificación de claves (CLAVE AGREGADA, CLAVE UNIQ y CLAVE DUPLICADA) para consultar rápidamente datos en función de una columna de prefijo determinada. El índice de índice de clave corta aquí también adopta una estructura de índice dispersa. Durante el proceso de escritura de datos, se generará un elemento de índice cada cierto número de filas. Este número de filas es la granularidad del índice, que por defecto es 1024 filas y es configurable. El proceso se muestra a continuación:
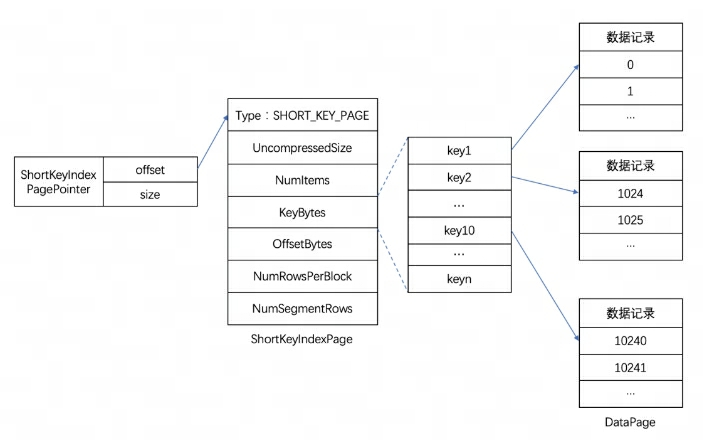
Entre ellos, KeyBytes almacena los datos del elemento de índice y OffsetBytes almacena el desplazamiento del elemento de índice en KeyBytes.
El índice de clave corta utiliza los primeros 36 bytes como índice de prefijo de esta fila de datos. Cuando se encuentra un tipo VARCHAR, el índice del prefijo se trunca directamente. El índice de clave corta utiliza los primeros 36 bytes como índice de prefijo de esta fila de datos. Cuando se encuentra un tipo VARCHAR, el índice del prefijo se trunca directamente.
¿Cómo llega el proceso de lectura al índice?
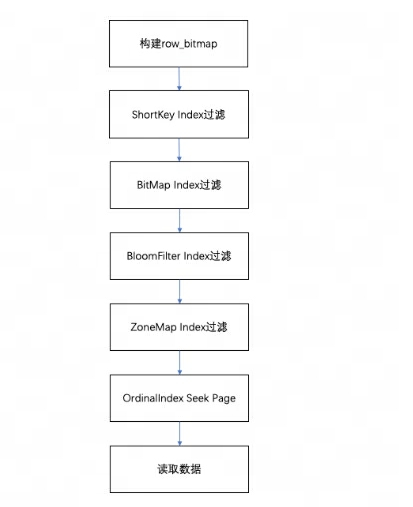
Al consultar los datos en un segmento, de acuerdo con las condiciones de consulta ejecutadas, los datos primero se filtrarán según el índice del campo. Luego lea los datos, el proceso general de consulta es el siguiente:
-
Primero, se construirá uno de acuerdo con el número de filas en el segmento
row_bitmappara indicar qué datos deben leerse. Todos los datos deben leerse sin utilizar ningún índice. -
Cuando la clave se utiliza en las condiciones de consulta de acuerdo con la regla del índice de prefijo, el índice ShortKey se filtrará primero y el rango de números de fila Oordinal que puede coincidir en el índice ShortKey se combinará en
row_bitmap. -
Cuando hay un índice de índice de BitMap en el campo de la columna en la condición de consulta, el número de fila ordinal que cumple las condiciones se encontrará directamente de acuerdo con el índice de BitMap y se cruzará con el mapa de bits de fila para filtrar. El filtrado aquí es preciso: si la condición de consulta se elimina más adelante, este campo no se filtrará para índices posteriores.
-
Cuando el campo de la columna en la condición de consulta tiene un índice BloomFilter y la condición es equivalente (eq, in, is), se filtrará de acuerdo con el índice BloomFilter. Aquí, se recorrerán todos los índices, el BloomFilter de cada página Se pueden filtrar y se pueden encontrar las condiciones de la consulta. Todas las páginas.
row_bitmapFiltre la intersección del rango de números de fila ordinales en la información del índice y . -
Cuando hay un índice de ZoneMap en el campo de la columna en la condición de consulta, se filtrará de acuerdo con el índice de ZoneMap. Aquí, también se ejecutarán todos los índices para encontrar todas las páginas que la condición de consulta puede cruzar con el ZoneMap.
row_bitmapFiltre la intersección del rango de números de fila ordinales en la información del índice y . -
Después de generar
row_bitmap, busque la página de datos específica a través del índice ordinal de cada columna en lotes. -
Lea los datos de la página de datos de columnas de cada columna en lotes. Al leer, para páginas con valores nulos, determine si la fila actual es nula según el mapa de bits del valor nulo. Si es nulo, rellénelo directamente.
P7: ¿Cómo realiza Doris la compactación?
Doris usa Compaction para agregar incrementalmente archivos RowSet para mejorar el rendimiento. La información de versión de RowSet está diseñada con dos campos, Inicio y Fin, para representar el rango de versiones del Rowset fusionado. Las versiones de inicio y fin de un conjunto de filas acumulativo no fusionado son iguales. Durante la compactación, los RowSets adyacentes se fusionarán para generar un nuevo RowSet, y la información de inicio y fin de la versión también se fusionarán para formar una versión más grande. Por otro lado, el proceso de compactación reduce en gran medida la cantidad de archivos RowSet y mejora la eficiencia de las consultas.
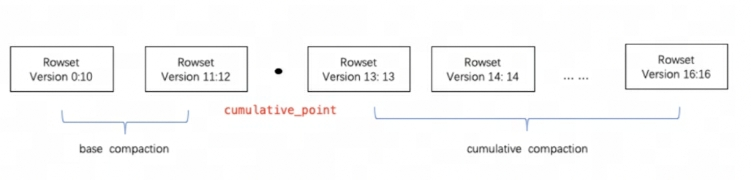
Como se muestra en la figura anterior, las tareas de compactación se dividen en dos tipos, compactación base y compactación acumulativa. cumulative_pointEs la clave para separar las dos estrategias.
Se puede entender así:
-
cumulative_pointA la derecha hay un RowSet incremental que nunca se ha fusionado, y las versiones de inicio y fin de cada RowSet son iguales; -
cumulative_pointA la izquierda está el RowSet fusionado, la versión inicial y la versión final son diferentes. -
Los procesos de tareas de Compactación base y Compactación acumulativa son básicamente los mismos, la única diferencia radica en la lógica de seleccionar el InputRowSet que se fusionará.
¿En qué clave se basa la compactación?
-
En un segmento, los datos siempre se almacenan en el orden de clasificación de la clave (CLAVE AGREGADA, CLAVE UNIQ y CLAVE DUPLICADA), es decir, la clasificación de la clave determina la estructura física del almacenamiento de datos y determina el orden de la estructura física de los datos de las columnas.
-
Entonces, el proceso de compactación de Doris se basa en CLAVE AGREGADA, CLAVE UNIQ y CLAVE DUPLICADA.
P8: ¿Cómo implementa Doris la replicación de datos entre clústeres?
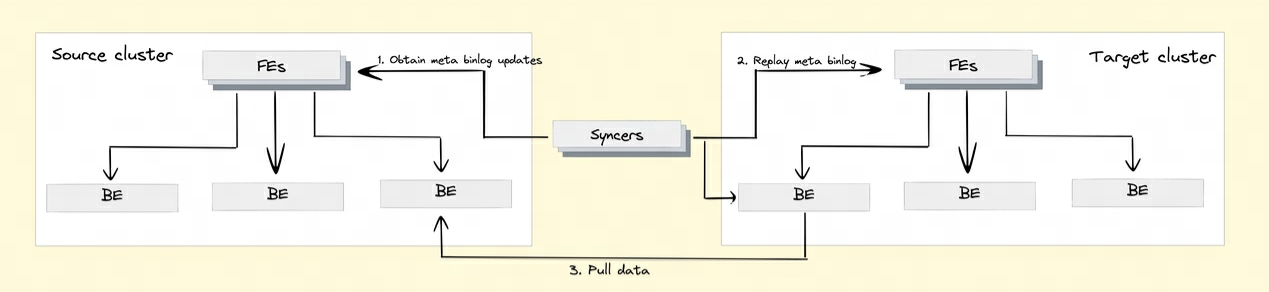
Para implementar la función de replicación de datos entre clústeres, Doris introdujo el mecanismo Binlog. Los registros y operaciones de modificación de datos se registran automáticamente a través del mecanismo Binlog para lograr la trazabilidad de los datos, y la reproducción y recuperación de datos también se pueden lograr según el mecanismo de reproducción Binlog.
¿Cómo se registra Binlog?
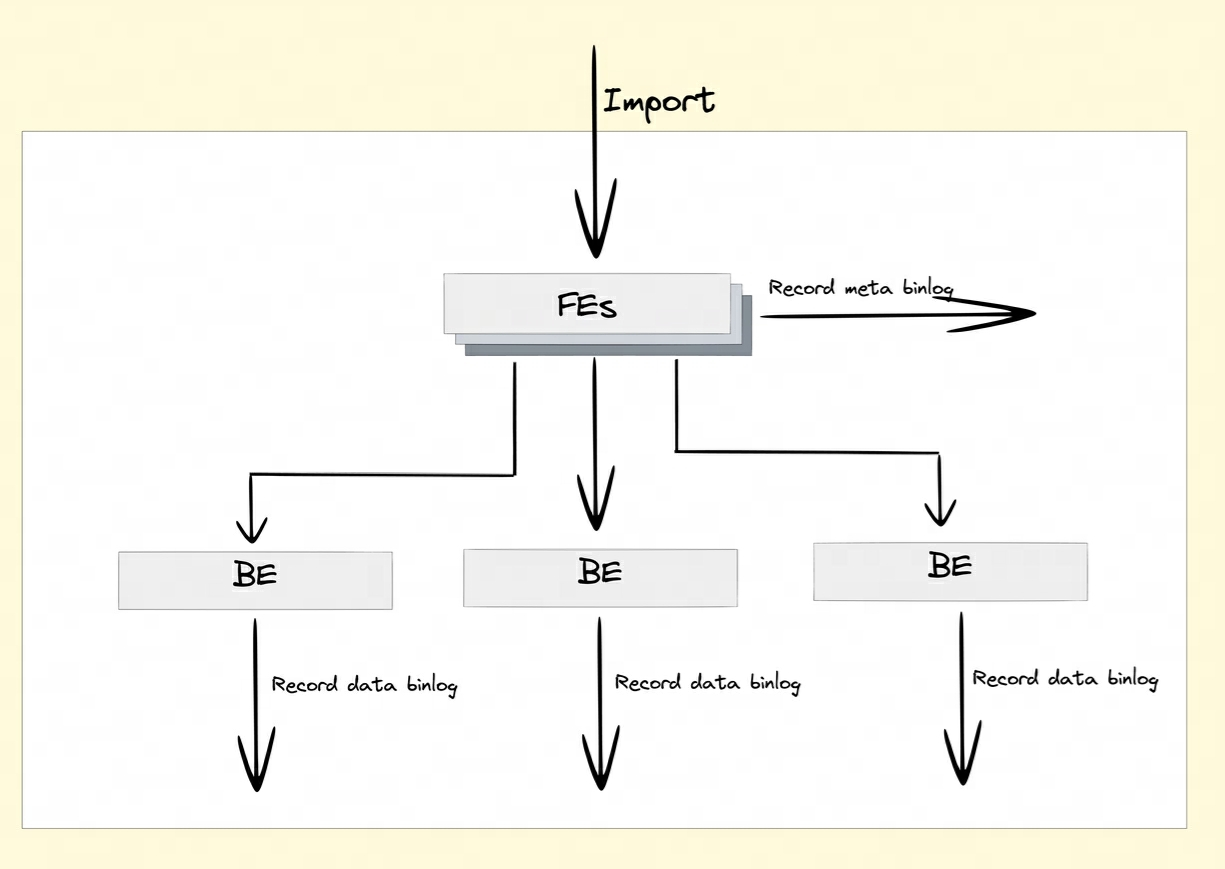
Después de activar el atributo Binlog, FE y BE conservarán los registros de modificación de las operaciones DDL/DML en Meta Binlog y Data Binlog.
-
Meta Binlog: Doris ha mejorado la implementación de EditLog para garantizar el orden del registro. Al construir una secuencia creciente de LogID, cada operación se registra con precisión y se mantiene en orden. Este mecanismo de persistencia ordenado ayuda a garantizar la coherencia de los datos.
-
Binlog de datos: cuando FE inicia una transacción de publicación, BE realizará la operación de publicación correspondiente. BE escribirá la información de metadatos de esta transacción que involucra RowSet en el prefijo
rowset_metaKV y la conservará en el meta almacenamiento. Después del envío, los archivos de segmento importados serán vinculado a la carpeta Binlog.
Generación de binlog:
Reproducción de datos BInlog:
P9: La mesa de Doris tiene múltiples copias. ¿Cómo garantizar múltiples copias durante la fase de escritura? ¿Existe un concepto maestro-esclavo? ¿Es necesario devolver el éxito de escritura después de la mayoría?
-
Las 3 copias de Doris BE no tienen el concepto de maestro-esclavo y utilizan el algoritmo Quorum para garantizar la escritura de múltiples copias.
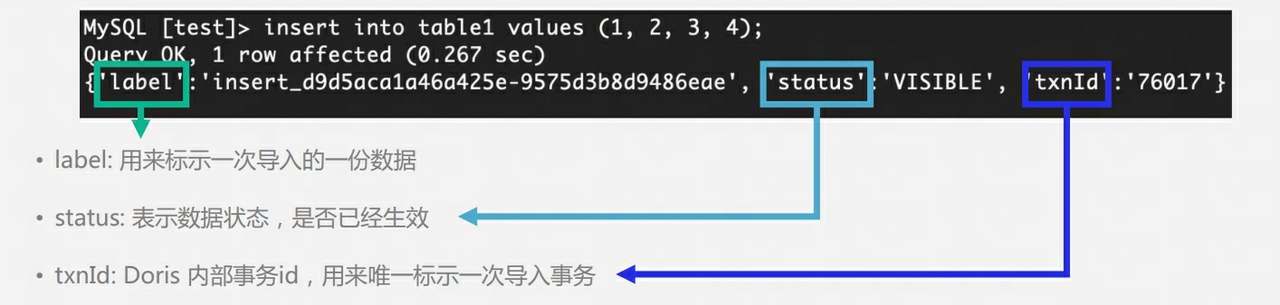
-
Durante el proceso de escritura, FE determinará si el número de copias de cada tableta que escribe datos con éxito excede la mitad del número total de copias de la tableta. Si el número de copias de cada tableta que escribe datos con éxito excede la mitad del número total de tabletas copias (más exitosas), entonces la transacción de confirmación es exitosa y el estado de la transacción se establece en COMPROMETIDO; el estado COMPROMETIDO indica que los datos se han escrito correctamente, pero los datos aún no son visibles y la tarea de Publicar versión debe continuar Después de eso, la transacción no se puede revertir.
-
FE tendrá un hilo separado para ejecutar Publicar versión para la transacción de confirmación exitosa. Cuando FE ejecuta Publicar versión, enviará solicitudes de Publicar versión a todos los nodos Ejecutor BE relacionados con la transacción a través de Thrift RPC. La tarea Publicar versión se ejecuta de forma asincrónica en cada Nodo BE ejecutor. Importe los datos al RowSet generado y conviértalo en una versión de datos visible.
¿Por qué existe un mecanismo de publicación ? Similar a MVCC, si no existe un mecanismo de publicación, los usuarios pueden leer datos que aún no se han enviado.
¿Qué pasará si la tabla tiene 3 copias y solo se escribe correctamente 1 copia ? En este momento, la transacción será ABORTADA
¿Qué sucederá si la tabla tiene 3 copias y solo 2 copias se escriben correctamente ? En este momento, la transacción se COMPROMETE y Doris FE realizará inspecciones y monitoreos regulares de la tableta. Si se encuentra una anomalía en la copia de la tableta, se realizará un clon. Se generará una tarea para clonar una nueva copia.
¿Por qué el usuario ejecuta la consulta inmediatamente después de ejecutar Insertar en y el resultado puede estar vacío ? La razón es que la transacción aún no se ha publicado.
P10: ¿Cómo garantiza el FE de Doris una alta disponibilidad?
A nivel de metadatos, Doris utiliza el protocolo Paxos y el mecanismo Memoria + Punto de control + Diario para garantizar un alto rendimiento y una alta confiabilidad de los metadatos.
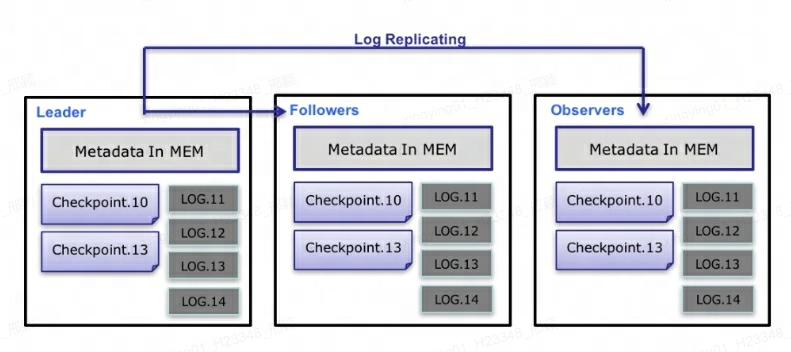
El proceso específico del flujo de datos de metadatos es el siguiente :
-
Sólo Leader FE puede escribir metadatos. Después de que la operación de escritura modifique la memoria del líder, se serializará en un registro y
key-valuese escribirá en BDBJE en formato . La clave es un número entero continuo ylog idel valor es el registro de operaciones serializado. -
Después de escribir el registro en BDBJE, BDBJE copiará el registro a otros nodos FE no líderes de acuerdo con la política (escritura mayoritaria/escritura total). El nodo FE no líder modifica su propia imagen de memoria de metadatos reproduciendo registros para completar la sincronización de metadatos con el nodo líder.
-
La cantidad de registros en el nodo Leader alcanza el umbral (100.000 de forma predeterminada) y cumple con el ciclo de ejecución del hilo de Checkpoint (60 segundos de forma predeterminada). Checkpoint leerá el archivo de imagen existente y los registros posteriores, y reproducirá una nueva copia de imagen de metadatos en la memoria. Luego, la copia se escribe en el disco para formar una nueva imagen. La razón para regenerar una copia de la imagen en lugar de escribir la imagen existente como Imagen es principalmente porque escribir en la Imagen y agregar un bloqueo de lectura bloqueará la operación de escritura. Por lo tanto, cada Checkpoint ocupará el doble de espacio en la memoria.
-
Una vez generado el archivo de imagen, el nodo líder notificará a otros nodos no líderes que se ha generado la nueva imagen. Non-Leader extrae activamente el archivo de imagen más reciente a través de HTTP para reemplazar el archivo local anterior.
-
Para los registros en BDBJE, los registros antiguos se eliminarán periódicamente una vez que se complete la imagen.
explicar :
-
Cada actualización de metadatos se escribe primero en el archivo de registro del disco, luego se escribe en la memoria y, finalmente, se realiza un control periódico en el disco local.
-
Es equivalente a una estructura de memoria pura, lo que significa que todos los metadatos se almacenarán en caché en la memoria, lo que garantiza que FE pueda restaurar rápidamente los metadatos después de una falla sin perder metadatos.
-
Los tres de Líder, Seguidor y Observador constituyen un servicio confiable. Cuando falla un solo nodo, tres son básicamente suficientes, porque después de todo, el nodo FE solo almacena una copia de metadatos y su presión no es grande, así que si Cuando hay Demasiados FE consumirán recursos de la máquina, por lo que en la mayoría de los casos tres son suficientes para lograr un servicio de metadatos de alta disponibilidad.
-
Los usuarios pueden usar MySQL para conectarse a cualquier nodo FE para acceder a lectura y escritura de metadatos. Si la conexión es a un nodo no líder, el nodo reenviará la operación de escritura al nodo líder.
Sobre el Autor
Invisible (Xing Ying) es ingeniera senior de kernel de bases de datos en NetEase, ha estado involucrada en el desarrollo del kernel de bases de datos desde que se graduó y actualmente se dedica principalmente al desarrollo, mantenimiento y soporte comercial de MySQL y Apache Doris. Como colaborador del kernel de MySQL, informó más de 50 errores y elementos de optimización para MySQL, y se incorporaron múltiples envíos a la versión MySQL 8.0. Apache Doris Active Contributor, que se une a la comunidad de Apache Doris desde 2023, ha enviado y fusionado docenas de compromisos para la comunidad.
Una escuela secundaria compró un "dispositivo de catarsis interactivo inteligente", que en realidad es un caso para Nintendo Wii. TIOBE Lenguaje de programación del año 2023: C# Kingsoft WPS falló El experimento Rust de Linux fue exitoso, ¿puede Firefox aprovechar la oportunidad... 10 predicciones sobre Código abierto Seguimiento del incidente de mujeres ejecutivas que despidieron empleados: el presidente de la compañía llamó a los empleados "reincidentes" y cuestionó "currículums académicos falsos". El artefacto de código abierto LSPosed anunció que dejaría de actualizarse. El autor dijo que sufrió una gran Número de ataques maliciosos 2024 "La batalla del año" en el círculo frontal: React no puede cavar agujeros. ¿Necesitas completarlo con documentos? Se lanza oficialmente el kernel de Linux 6.7. La era "post-código abierto" está aquí: la licencia no es válida y no puede servir al público en general. Las ejecutivas fueron despedidas ilegalmente. Los empleados hablaron y fueron atacados por oponerse al uso de herramientas EDA pirateadas para fichas de diseño.