
Artikelverzeichnis
1. Inline-Funktionen
Der Aufruf einer Funktion erfordert die Einrichtung eines Stack-Frames. Register müssen im Stack-Frame gespeichert und nach Abschluss wiederhergestellt werden. All dies ist kostspielig.
int add(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
add(2, 2);
add(3, 2);
add(4, 2);
add(5, 2);
add(1, 2);
return 0;
}
Für die Sprache C kann die Makrooptimierung jedoch für kleine Funktionen verwendet werden, die häufig aufgerufen werden.
Da das Makro während der Vorverarbeitungsphase ersetzt wird, entsteht kein Ausführungsaufwand.
Für das oben Gesagte add函数kann die Verwendung von Makros wie folgt aussehen
#define ADD(x, y) ((x) + (y))
int main()
{
cout << ADD(1, 2) << endl;
cout << ADD(1, 2) << endl
return 0;
}
Aber Makros haben auch Nachteile:
1. Sie können nicht debuggt werden
2. Es gibt keine Überprüfung der Typsicherheit
3. Einige Szenarien sind sehr komplex
und es kann leicht zu Fehlern bei der Definition von Makros kommen.
Es kann aus Versehen so geschrieben werden #define ADD(x + y) x + y; = So Beim Schreiben von Makros treten Fehler auf, sei es ein Ersetzungsfehler oder ein Prioritätsfehler
Daher werden in C++ Inline-Funktionen eingeführt
1. Definition von Inline-Funktionen
Inline-Funktionen fügen den Code der Funktion zur Kompilierungszeit in den Aufrufpunkt ein, anstatt ihn über Funktionsaufrufe auszuführen, wodurch der Overhead von Funktionsaufrufen verringert werden kann.
Inline-Funktionen eignen sich normalerweise für Situationen, in denen der Funktionskörper klein ist und häufig aufgerufen wird. Sie eignen sich jedoch nicht für rekursive Funktionen oder wenn der Funktionskörper groß ist.
Verwenden Sie das Schlüsselwort inline, um eine Funktion als Inline zu deklarieren
内联函数的地址不会进入符号表
Genauer gesagt haben Inline-Funktionen keine Adressen.
2. Deklaration und Definition von Inline-Funktionen
#include <iostream>
using namespace std;
// 定义一个内联函数
inline int add(int a, int b) {
return a + b;
}
int main() {
int x = 5;
int y = 3;
int result = add(x, y);
cout << "Result: " << result << endl;
return 0;
}
3. Funktionen
-
inlineEs handelt sich um eine Optimierungsstrategie des „Tauschs von Raum gegen Zeit“. Es wird empfohlen, dass der Compiler Funktionen in Inline-Funktionen erweitert und Funktionsaufrufe während der Kompilierungsphase durch Funktionskörper ersetzt, um den Funktionsaufruf-Overhead zu reduzieren und die Effizienz der Programmausführung zu verbessern. -
Die Compiler-Paarung ist
inlinenur ein Vorschlag und die Implementierung kann von Compiler zu Compiler variieren. Verschiedene Compiler können unterschiedliche Strategien verwenden, um zu entscheiden, welche Funktionen zu Inline-Funktionen erweitert werden sollen. -
Die Verwendung dekorierter Funktionen
inlinehat Vor- und Nachteile . Der Vorteil besteht darin, dass der Overhead für Funktionsaufrufe reduziert und die Effizienz der Programmausführung verbessert werden kann. Der Nachteil besteht darin, dass die Objektdatei möglicherweise größer wird, da die Funktion an jeder Aufrufstelle erweitert wird. Daher ist es notwendig, abzuwägen, obinlinedie Wahl auf der Grundlage der spezifischen Situation getroffen werden soll.

4.inlineEs wird nicht empfohlen, Deklarationen und Definitionen zu trennen, da eine Trennung zu Verbindungsfehlern führt. Da Inline erweitert ist, gibt es keine Funktionsadresse und der Link wird nicht gefunden.
4. Zu beachtende Punkte zu Inline-Funktionen
- Bei Inline-Funktionen ist es in der Regel besser, Definition und Deklaration zusammenzustellen, da Inline-Funktionen keine Adresse haben. Wenn nur eine Deklaration, aber keine Definition vorhanden ist, wird die Definition beim Aufruf der Inline-Funktion nicht gefunden und es tritt ein Fehler auf
应该在头文件中同时包含内联函数的声明和定义 - Wenn die Deklaration einer Inline-Funktion in einer Header-Datei und die Definition in anderen Quelldateien platziert wird, wird die Definition beim Aufruf der Inline-Funktion möglicherweise nicht gefunden, was zu einem Kompilierungsfehler führt.
- Ob Inline-Funktionen an der Aufrufstelle erweitert werden, wird vom Compiler bestimmt. Selbst wenn eine Funktion inline deklariert wird, gibt es keine Garantie dafür, dass sie erweitert wird. Der Compiler optimiert basierend auf der Komplexität des Funktionskörpers, der Aufrufhäufigkeit und anderen Faktoren und entscheidet, ob die Inline-Funktion erweitert werden soll.
- Die Erweiterung von Inline-Funktionen hängt mit Compiler-Entscheidungen zusammen. Wir können
inlinedas Schlüsselwort verwenden, um vorzuschlagen, dass der Compiler Funktionen in Inline-Funktionen erweitert, aber die tatsächliche Entscheidungsbefugnis liegt beim Compiler.
Fazit: Es wird empfohlen, kurze, häufig aufgerufene kleine Funktionen inline zu definieren.
2. Spielraum für
Die Range-for-Schleife ist eine neue Schleifensyntax, die in C++11 eingeführt wurde, um Durchlaufvorgänge für iterierbare Objekte wie Container und Arrays zu vereinfachen. Es bietet eine präzisere und lesbarere Möglichkeit, iterativ auf Elemente zuzugreifen.
1. Grundlegende Grammatik
Die grundlegende Syntax einer Range-for-Schleife lautet wie folgt:
for (auto element : iterable) {
// 循环体
}
Darunter elementbefindet sich eine Kopie des aktuellen Elements während des Iterationsprozesses, iterablebei dem es sich um ein iterierbares Objekt wie einen Container oder ein Array handelt.
2. Durchqueren Sie den Container
Der Bereich für die Schleife kann problemlos verschiedene Container wie usw. durchlaufen vector. listWir müssen zum Durchlaufen keine Iteratoren oder Indizes mehr verwenden, sondern verwenden direkt eine Range-for-Schleife:
vector<int> nums = {
1, 2, 3, 4, 5};
for (auto num : nums) {
cout << num << " ";
}
// 输出:1 2 3 4 5
3. const und Referenz
Durch die Verwendung constvon Schlüsselwörtern können Range-for-Schleifen auch eine schreibgeschützte Durchquerung implementieren und so die Daten im Container vor Änderungen schützen:
vector<int> nums = {
1, 2, 3, 4, 5};
for (const auto& num : nums) {
cout << num << " ";
}
// 输出:1 2 3 4 5
Im obigen Code numwird es als deklariert const auto&, was den schreibgeschützten Zugriff auf die Elemente im Container anzeigt.
4. Array-Durchquerung
Range for-Schleifen eignen sich auch zum Durchlaufen von Arrays, wodurch der Code prägnanter wird:
int arr[] = {
1, 2, 3, 4, 5};
for (auto e : arr) {
cout << e << " ";
}
// 输出:1 2 3 4 5
5. Benutzerdefinierte Typdurchquerung
begin()Für benutzerdefinierte Typen müssen Sie nur Überladungen von end()Mitgliedsfunktionen oder Nicht-Mitgliedsfunktionen bereitstellen und können zum Durchlaufen eine Range-for-Schleife verwenden. Zum Beispiel:
class MyContainer {
public:
int* begin()
{
return &data[0];
}
int* end()
{
return &data[size];
}
private:
int data[5] = {
1, 2, 3, 4, 5};
};
MyContainer container;
for (auto e : container) {
cout << e << " ";
}
// 输出:1 2 3 4 5
Im obigen Code MyContainerstellt die Klasse bereit begin()und end()funktioniert so, dass das Objekt mithilfe einer Range-for-Schleife wie ein Container durchlaufen werden kann.
Die Range for-Schleife ist eine leistungsstarke und prägnante Funktion in C++, die den Code für iterative Operationen erheblich vereinfachen und die Lesbarkeit des Codes verbessern kann.
6. Nutzungsbedingungen
Der Bereich der for-Schleifeniteration muss sicher sein
Der Bereich eines Arrays ist der Bereich des ersten Elements und des letzten Elements im Array;
Für Klassen sollten begin- und end-Methoden bereitgestellt werden. Begin und end sind der Umfang der for-Schleifeniteration.
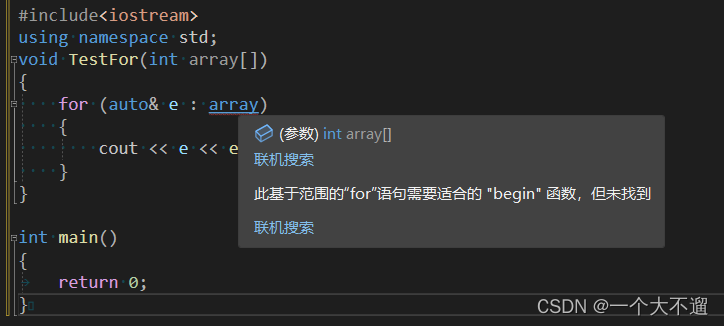
Wenn die Funktion Parameter übergibt, degeneriert das Array zu einem Zeiger.
#include<iostream>
using namespace std;
void TestFor(int array[])
{
for (auto& e : array)
{
cout << e << endl;
}
}
int main()
{
return 0;
}
3. Auto-Schlüsselwort
1. Automatische Typinferenz
Verwenden Sie das Schlüsselwort auto, um den Typ einer Variablen automatisch abzuleiten, ohne den Typ explizit anzugeben. Der Compiler leitet den Typ einer Variablen anhand ihres Initialisierungsausdrucks ab.
auto num = 10; // 推断num的类型为int
auto name = "John"; // 推断name的类型为const char*
auto prices = {
1.99, 3.49, 2.99 }; // 推断prices的类型为std::initializer_list<double>
Die Verwendung des Schlüsselworts auto kann den Code vereinfachen, das wiederholte Schreiben von Typen reduzieren und die Lesbarkeit des Codes verbessern.
typeidSie können den Objekttyp und die Verwendung sehen typeid(c).name(), aus denen Sie den Typ der Variablen drucken können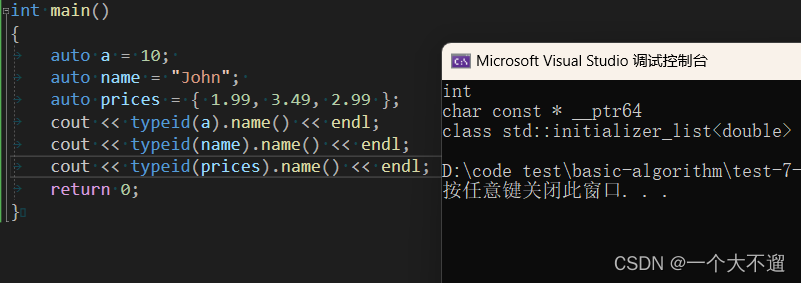
2. Inferenz des Funktionsrückgabewerttyps
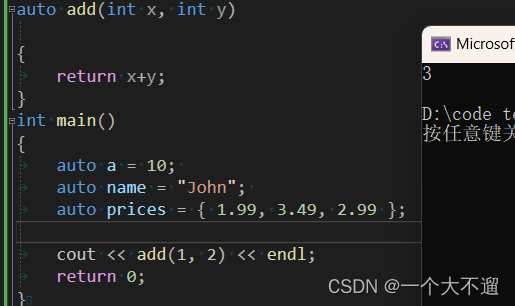
Durch die Verwendung des Schlüsselworts auto kann der Compiler auf den Rückgabewerttyp einer Funktion schließen. Dies ist besonders nützlich für Funktionen, die komplexe Typen zurückgeben oder generische Programmierung beinhalten.
auto add(int a, int b) {
return a + b;
}
auto compute() {
// 复杂类型的计算逻辑
return result;
}
Hier leitet der Compiler den Rückgabewerttyp der Funktionen Add und Compute basierend auf dem tatsächlich zurückgegebenen Wert ab.
4. Automatische Aufmerksamkeit
1.auto kann nicht unabhängig definiert werden
2.auto kann kein Array definieren
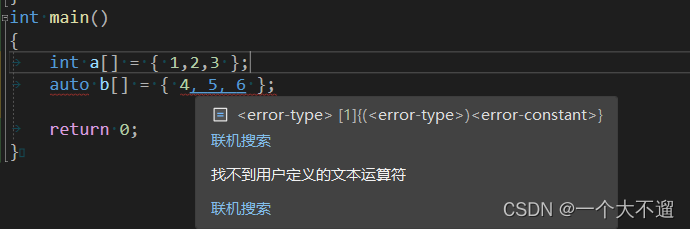
3.auto kann keine Funktionsparameter akzeptieren ,
Da der Compiler den Typ von Auto nicht ableiten kann, gibt es keine Grundlage.
Aber in Versionen nach C++11 kann auto als Parameter verwendet werden

4. nullptr (C++11)
Für c ist der Nullzeiger NULL und ein Makro.
In C++98/03 kann nur NULL verwendet werden; nach C++11 wird nullptr empfohlen.
NULL(stddef.h):
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
Tatsächlich ist NULL ein Makro, also 写成 int* p = 0·kann man es auch sagen
Aber besondere Umstände
#include<iostream>
using namespace std;
void f(int a)
{
cout << "f(int)" << endl;
}
void f(int* ptr)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
return 0;
}
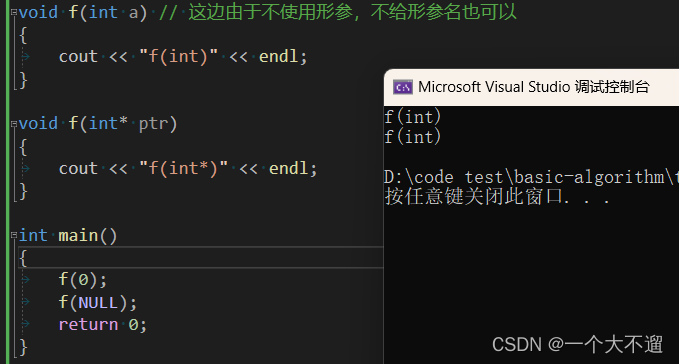
Ersetzen Sie NULL durch nullptr

5. Zusammenfassung
Dieses Mal fassen wir hauptsächlich die Eigenschaften von Inline-Funktionen, die Verwendung des Schlüsselworts auto, die Verwendung von range for und die Reparatur von nullptr zusammen.
