Vorwort
Die Satzvektordarstellung war schon immer der Eckpfeiler vieler Verarbeitungsaufgaben in natürlicher Sprache und war schon immer ein heißes Thema im Bereich NLP. BERT-Flow und BERT-Whitening sind eigentlich wie eine Nachbearbeitung, bei der bestimmte Verarbeitungen an der Ausgabe von BERT durchgeführt werden, um sie zu lösen das Anisotropieproblem.
SimCSE „ Simple Contrastive Learning of Sentence Embeddings“, also „Simple Contrastive Sentence Vector Representation Framework“, verwendet ein einfaches kontrastives Lernen , um Satzeinbettungen durchzuführen. Darüber hinaus können Satzvektoren mit besserer Qualität generiert werden, ohne die Daten zu überwachen. Der Artikel ist in EMNLP2021 enthalten.
Papieradresse: https://aclanthology.org/2021.emnlp-main.552.pdf
Codeadresse: https://github.com/princeton-nlp/SimCSE
1. Vergleichendes Lernen
Die Definition von kontrastivem Lernen: mit dem Ziel, ähnliche Daten näher zusammenzubringen und unterschiedliche Daten zu verdrängen, um die Datendarstellung effektiv zu lernen. Der Prozess des vergleichenden Lernens ist wie folgt:
(1) Erstellen Sie anhand eines Bildes einer Katze
(2) Geben Sie diese positive und negative Stichprobengruppe (X, X+, X-) gleichzeitig in ein Modell zur Merkmalsextraktion ein.
(3) Optimieren Sie den Kontrastverlust, bringen Sie den Abstand zwischen X und X+ im Merkmalsraum näher und vergrößern Sie gleichzeitig den Abstand zwischen X und X- im Merkmalsraum.
Durch die vergleichende Lernmethode können die folgenden zwei Ziele erreicht werden :
(1) Ähnliche Bilder liegen im Feature-Raum sehr nahe beieinander, wodurch ähnliche Bilder erreicht werden und ihre Features auch relativ ähnlich sind
(2) Unähnliche Bilder befinden sich im Feature space Der Abstand wird sehr groß sein, was dazu führt, dass diese differenzierten Bilder im Merkmalsraum verstreut werden. Aus einer anderen Perspektive betrachtet werden die Informationen im Merkmalsraum so groß wie möglich sein.
Aus der Perspektive des gesamten Prozesses des kontrastiven Lernens können wir feststellen, dass wir, wenn keine beschrifteten Daten vorliegen, nur eine Datenverbesserung durchführen müssen, um ein positives Stichprobenpaar zu erstellen, und kontrastives Lernen problemlos verwenden können, um nützlichere Merkmalsvektoren zu extrahieren .
2.SimCSE
SimSCE ist eine Methode, die einen kontrastiven Lernrahmen für die Satzeinbettung verwendet. SimCES schlägt zwei kontrastive Lernmethoden, überwacht und unbeaufsichtigt, für die Satzeinbettung vor.
2.1 Unüberwachte Methoden
Bei der unbeaufsichtigten Methode wird die Dropout-Technologie verwendet, um eine Datenverbesserung am Originaltext durchzuführen und so positive Proben für das anschließende kontrastive Lerntraining zu erstellen.
2.1.1 Prozessimplementierung
Die unbeaufsichtigte Methode ist in der folgenden Abbildung dargestellt und der Prozess ist wie folgt.
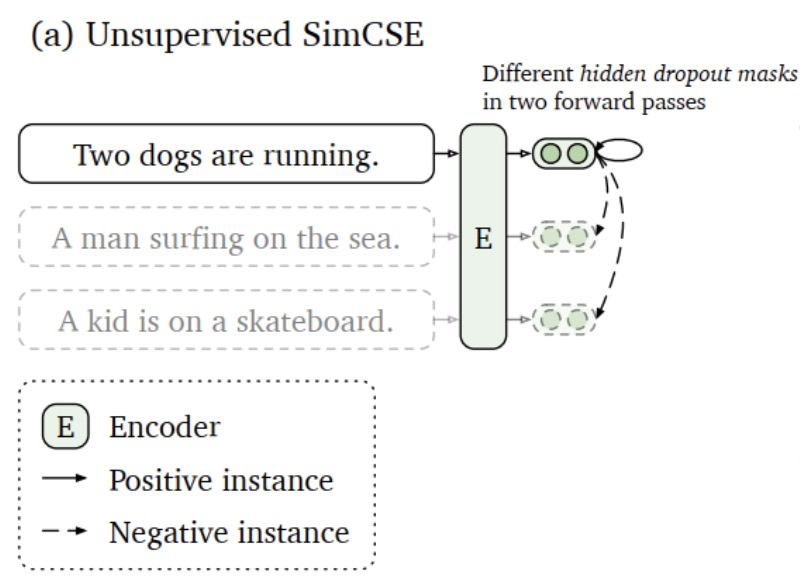
(1) Geben Sie denselben Satz zweimal in das Modell ein und verwenden Sie die Dropout-Technologie, um zwei verschiedene Merkmalsvektoren zu erhalten. Aufgrund der Dropout-Schicht im Modell führt die zufällige Deaktivierung von Neuronen dazu, dass während der Trainingsphase derselbe Satz in das Modell eingegeben wird und die Ausgabe unterschiedlich ist.
(2) In einem Stapel werden die beiden Ausgaben desselben Satzes im Modell als positive Beispiele und die Ausgaben anderer Sätze als negative Beispiele betrachtet.
(3) Optimieren Sie den Kontrastverlust, um die Ähnlichkeit zwischen positiven Beispielen zu erhöhen und die Ähnlichkeit zwischen negativen Beispielen zu verringern.
2.1.2 Verlustimplementierung und detaillierte Erläuterung
Hier wird davon ausgegangen, dass die Eingabe des Probenformats für jede Charge in das Modell wie folgt lautet:
(1) [0,1,2,3,4,5] stellt eine Charge dar, die sechs Proben enthält
(2), wobei 0,1 die darstellt derselbe Satz, wobei 2 und 3 derselbe Satz sind, darunter 4 und 5 derselbe Satz.
Dann ist die Ausgabe y_pred des Modells die Vektordarstellung der sechs Sätze [X0, X1, X2, X3, X4, X5] . Die detaillierte Erläuterung des Vergleichsverlusts lautet wie folgt.
def compute_loss(y_pred, lamda=0.05):
idxs = torch.arange(0, y_pred.shape[0]) # [0,1,2,3,4,5]
#这里[(0,1),(2,3),(4,5)]代表三组样本,
#其中0,1是同一个句子,输入模型两次
#其中2,3是同一个句子,输入模型两次
#其中4,5是同一个句子,输入模型两次
y_true = idxs + 1 - idxs % 2 * 2 # 生成真实的label = [1,0,3,2,5,4]
# 计算各句子之间的相似度,形成下方similarities 矩阵,其中xij 表示第i句子和第j个句子的相似度
#[[ x00,x01,x02,x03,x04 ,x05 ]
# [ x10,x11,x12,x13,x14 ,x15 ]
# [ x20,x21,x22,x23,x24 ,x25 ]
# [ x30,x31,x32,x33,x34 ,x35 ]
# [ x40,x41,x42,x43,x44 ,x45 ]
# [ x50,x51,x52,x53,x54 ,x55 ]]
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
# similarities屏蔽对角矩阵即自身相等的loss
#[[ -nan,x01,x02,x03,x04 ,x05 ]
# [ x10, -nan,x12,x13,x14 ,x15 ]
# [ x20,x21, -nan,x23,x24 ,x25 ]
# [ x30,x31,x32, -nan,x34 ,x35 ]
# [ x40,x41,x42,x43, -nan,x45 ]
# [ x50,x51,x52,x53,x54 , -nan ]]
similarities = similarities - torch.eye(y_pred.shape[0]) * 1e12
# 论文中除以 temperature 超参
similarities = similarities / lamda
#下面这一行计算的是相似矩阵每一行和y_true = [1,0,3,2,5,4] 的交叉熵损失
#[[ -nan,x01,x02,x03,x04 ,x05 ] label = 1 含义:第0个句子应该和第1个句子的相似度最高,即x01越接近1越好
# [ x10, -nan,x12,x13,x14,x15 ] label = 0 含义:第1个句子应该和第0个句子的相似度最高,即x10越接近1越好
# [ x20,x21, -nan,x23,x24,x25 ] label = 3 含义:第2个句子应该和第3个句子的相似度最高,即x23越接近1越好
# [ x30,x31,x32, -nan,x34,x35 ] label = 2 含义:第3个句子应该和第2个句子的相似度最高,即x32越接近1越好
# [ x40,x41,x42,x43, -nan,x45 ] label = 5 含义:第4个句子应该和第5个句子的相似度最高,即x45越接近1越好
# [ x50,x51,x52,x53,x54 , -nan ]] label = 4 含义:第5个句子应该和第4个句子的相似度最高,即x54越接近1越好
#这行代码就是simsce的核心部分,就是一个句子被dropout 两次得到的向量相似度应该越大
#越好,且和其他句子向量的相似度越小越好
loss = F.cross_entropy(similarities, y_true)
return torch.mean(loss)2.2 Überwachte Lernmethoden
2.2.1 Prozessimplementierung
Bei der überwachten Lernmethode wird mit Hilfe des Textimplikationsdatensatzes (Natural Language Reasoning) das Implikationspaar als Positivbeispiel und das Widerspruchspaar als schwieriges Negativbeispiel für das anschließende vergleichende Lerntraining verwendet. Und das Anisotropieproblem der Einbettung vor dem Training wird durch kontrastives Lernen gelöst, wodurch die räumliche Verteilung gleichmäßiger wird. Wenn überwachte Daten verfügbar sind, können die positiven Proben direkt näher beieinander liegen. Die Modellstruktur ist in der folgenden Abbildung dargestellt:
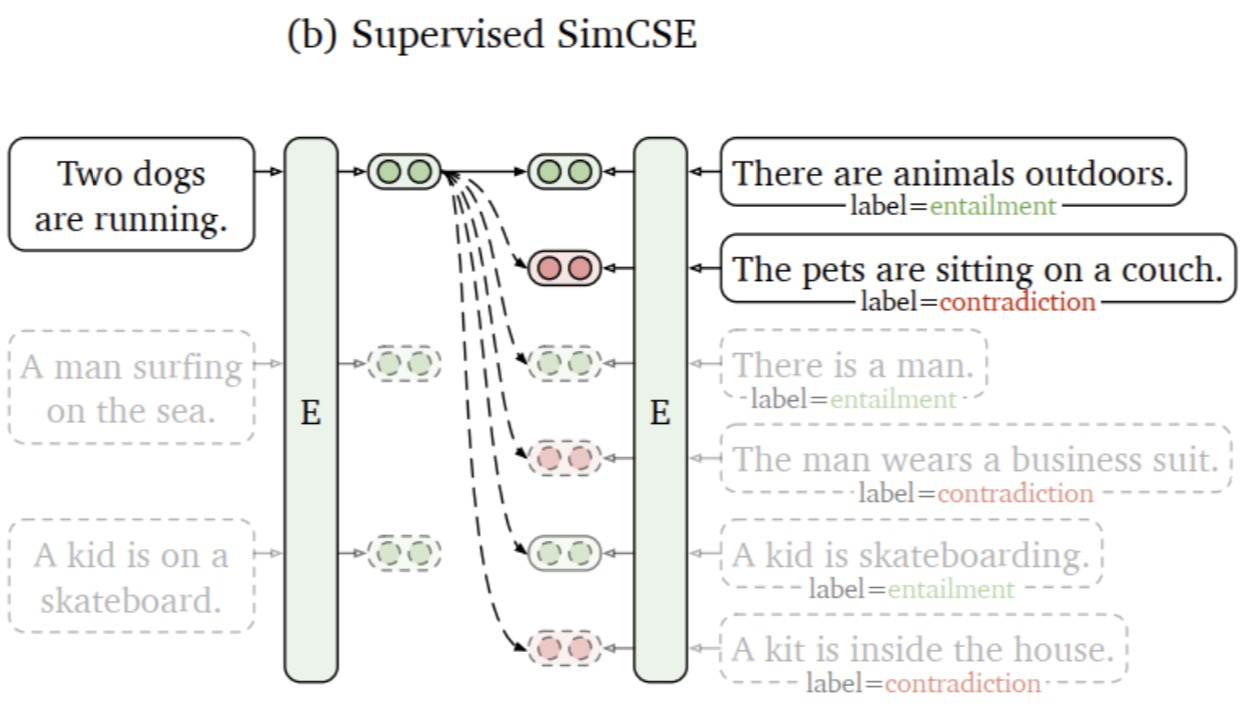
2.2.2 Verlustimplementierung und detaillierte Erläuterung
Hier wird davon ausgegangen, dass die Eingabe des Probenformats für jede Charge in das Modell wie folgt lautet:
(1) [0,1,2,3,4,5] stellt eine Charge dar, die sechs Proben enthält.
(2) [(0,1,2),(3,4,5)] stellt zwei Gruppen von Stichproben dar, wobei 0,1 ähnliche Sätze sind, die positive Beispiele darstellen, und 0,2 unterschiedliche Sätze sind, die negative Beispiele darstellen; 3 , 4 ist ein ähnlicher Satz, der ein positives Beispiel darstellt, 3,5 ist ein unähnlicher Satz, der ein negatives Beispiel darstellt. Die Ausgabe y_pred des Modells ist die Vektordarstellung der sechs Sätze [X0,X1,X2,X3,X4,X5] . Die detaillierte Erläuterung des Vergleichsverlusts lautet wie folgt.
def compute_loss(y_pred,lamda=0.05):
row = torch.arange(0,y_pred.shape[0],3,device='cuda') # [0,3]
col = torch.arange(y_pred.shape[0], device='cuda') # [0,1,2,3,4,5]
#这里[(0,1,2),(3,4,5)]代表二组样本,
#其中0,1是相似句子,0,2是不相似的句子
#其中3,4是相似句子,3,5是不相似的句子
col = torch.where(col % 3 != 0)[0].cuda() # [1,2,4,5]
y_true = torch.arange(0,len(col),2,device='cuda') # 生成真实的label = [0,2]
#计算各句子之间的相似度,形成下方similarities 矩阵,其中xij 表示第i句子和第j个句子的相似度
#[[ x00,x01,x02,x03,x04 ,x05 ]
# [ x10,x11,x12,x13,x14 ,x15 ]
# [ x20,x21,x22,x23,x24 ,x25 ]
# [ x30,x31,x32,x33,x34 ,x35 ]
# [ x40,x41,x42,x43,x44 ,x45 ]
# [ x50,x51,x52,x53,x54 ,x55 ]]
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
#这里将similarities 做切片处理,形成下方矩阵
#[[ x01,x02,x04 ,x05 ]
# [x31,x32,x34 ,x35 ]]
similarities = torch.index_select(similarities,0,row)
similarities = torch.index_select(similarities,1,col)
#论文中除以 temperature 超参
similarities = similarities / lamda
#下面这一行计算的是相似矩阵每一行和y_true = [0, 2] 的交叉熵损失
#[[ x01,x02,x04 ,x05 ] label = 0 含义:第0个句子应该和第1个句子的相似度最高, 即x01越接近1越好
# [x31,x32,x34 ,x35 ]] label = 2 含义:第3个句子应该和第4个句子的相似度最高 即x34越接近1越好
#这行代码就是simsce的核心部分,和正例句子向量相似度应该越大
#越好,和负例句子之间向量的相似度越小越好
loss = F.cross_entropy(similarities,y_true)
return torch.mean(loss)Tatsächlich gibt es neben der Konstruktion positiver Beispiele für vergleichendes Lernen durch zweimaliges Abbrechen tatsächlich viele Möglichkeiten, positive Beispiele zu konstruieren. Sie können beispielsweise Synonymersetzung, Rückübersetzung usw. verwenden, die häufig in der Textverarbeitung zum Konstruieren verwendet werden Positive Beispiele. SimCSE Der Autor dachte jedoch daran, Dropout als eine einfache Methode zum Erstellen positiver Stichprobenpaare für kontrastives Lernen zu verwenden, und erzielte bei vielen Datensätzen gute Ergebnisse.
3.Codeaufruf
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
# Tokenize input texts
texts = [
"马云说本周六要来京和高文欣会面",
"马云计划周六在北京会见高文欣",
"马云周六没空"
]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
# Get the embeddings
with torch.no_grad():
embeddings = model(**inputs, output_hidden_states=True, return_dict=True).pooler_output
# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine(embeddings[0], embeddings[1])
cosine_sim_0_2 = 1 - cosine(embeddings[0], embeddings[2])
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[1], cosine_sim_0_1))
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[2], cosine_sim_0_2))

Referenz:
1.https://www.jianshu.com/p/d73e499ec859