[Desarrollo empresarial diario] Optimización del rendimiento de la interfaz
cache
caché local
Caché local, la mayor ventaja es应用和cacheDentro del mismo proceso, el almacenamiento en caché de solicitudes es muy rápido, sin una sobrecarga excesiva de la red, etc., cuando una sola aplicación no requiere soporte de clúster o agrupación en clústeres Es más apropiado utilizar el caché local en escenarios donde los nodos no necesitan notificarse entre sí. La desventaja también es que debido a que el caché está acoplado a la aplicación, varias aplicaciones no pueden compartir el caché directamente. Cada aplicación o cada nodo del clúster necesita mantener su propio caché separado, lo que es un desperdicio de memoria.
Los marcos de almacenamiento en caché locales más utilizados incluyen Guava、Caffeine, etc. Todos son paquetes jar separados que se pueden importar directamente al proyecto y utilizar.
Tenemos la flexibilidad de elegir qué marco queremos en función de nuestras necesidades.
@Configuration
public class CaffeineCacheConfig {
@Bean
public Cache<String, Object> caffeineCache() {
return Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterWrite(60, TimeUnit.SECONDS)
// 初始的缓存空间大小
.initialCapacity(100)
// 缓存的最大条数
.maximumSize(1000)
.build();
}
}
El almacenamiento en caché local es adecuado para dos escenarios:
- Los requisitos de puntualidad para el contenido almacenado en caché no son altos y se puede tolerar un cierto retraso, se puede establecer un tiempo de vencimiento más corto y las actualizaciones de invalidación pasiva pueden mantener la actualización de los datos.
- El contenido almacenado en caché no cambiará. Por ejemplo: la relación de mapeo entre el número de pedido y el uid no cambiará una vez creada.
Nota:
- Control del límite superior de entrada de datos de la memoria caché para evitar la parálisis de la aplicación causada por el uso excesivo de la memoria.
- Estrategia de eliminación de datos en memoria.
- Aunque la implementación es simple, existen muchos obstáculos potenciales, es mejor elegir algunos marcos maduros de código abierto.
Caché distribuido
El uso de caché local puede traer fácilmente "estado" a su servidor de aplicaciones y está fácilmente limitado por el tamaño de la memoria.
El caché distribuido se basa en el concepto de distribución, implementación de clústeres, operación y mantenimiento independientes y capacidad ilimitada. Aunque habrá pérdidas de transmisión de red, el retraso de 1 a 2 ms puede ignorarse en comparación con sus muchas ventajas.
Los excelentes sistemas de caché distribuidos son bien conocidosMemcached 、Redis. Al comparar las bases de datos relacionales y el almacenamiento en caché, la brecha en el rendimiento de lectura y escritura es enorme. Redis ya puede lograr esto con un solo nodo.8W+ QPS(系统每秒处理查询的次数) Al diseñar la solución, intente transferir la presión de lectura y escritura de la base de datos al caché para proteger eficazmente la frágil base de datos relacional.
Nota:
- Si la tasa de aciertos de la caché es demasiado baja para resistir la presión, la presión seguirá estando en la capa de almacenamiento posterior.
- El tamaño del espacio de caché debe evaluarse en función de escenarios comerciales específicos para evitar que un espacio insuficiente provoque que se reemplacen algunos datos importantes.
- Coherencia de los datos almacenados en caché.
- El problema de la rápida expansión de la caché.
- La interfaz almacenada en caché RT promedio, RT máximo y RT mínimo.
- QPS en caché.
- Tráfico de salida de la red.
- Número de conexiones de clientes.
base de datos
Subbase de datos y subtabla
El motor de almacenamiento innodb subyacente de MySQL utiliza una estructura de árbol B+, y la estructura de tres niveles admite decenas de millones de almacenamiento de datos.
Por supuesto, la base de usuarios actual de Internet es muy grande. Con una cantidad tan grande de usuarios, generalmente es difícil que una sola tabla satisfaga las necesidades comerciales. Dividir horizontalmente una tabla grande en varias tablas físicas con la misma estructura puede ser un gran beneficio. aliviar las presiones de almacenamiento y acceso.
optimización SQL
Aunque tener subbases de datos y subtablas puede reducir mucha presión en la dimensión de almacenamiento, todavía tenemos que aprender a tener cuidado con nuestros cálculos. Por ejemplo, todas las operaciones de la base de datos se realizan a través de SQL.
Un SQL incorrecto puede tener un gran impacto en el rendimiento de la interfaz.
Por ejemplo:
1. Se realiza un cambio de página profundo y el motor de la base de datos tiene que verificar previamente una gran cantidad de datos cada vez.
select * from purchase_record where productCode = 'PA9044' and status=4 order by orderTime desc limit 100000,200
limit 100000,200Esto significa que se escanearán 100.200 filas, se devolverán 200 filas y se descartarán las primeras 100.000 filas. Entonces la velocidad de ejecución es muy lenta. Generalmente, el método de grabación de etiquetas se puede utilizar para optimización, como por ejemplo:
select * from purchase_record where productCode = 'PA9044' and status=4 and id > 100000 limit 200
La ventaja de esta optimización es que llega al índice de clave principal. No importa cuántas páginas haya, el rendimiento es bastante bueno, pero la limitación es que el ID necesita un campo que aumenta continuamente< a i=1> 2. Falta el índice. Hice un escaneo completo de la tabla. 3. Evite consultar una gran cantidad de datos de la base de datos en la memoria a la vez, lo que puede causar memoria insuficiente. Se recomienda utilizar consultas por lotes y paginación.
Trámites comerciales
Paralelización
¿Seleccionar el proceso de negocio, dibujar un diagrama de secuencia y distinguir claramente qué es en serie? ¿Cuáles son paralelos? Aproveche las capacidades de procesamiento paralelo de las CPU multinúcleo.
Como se muestra en la figura siguiente, el procesamiento en serie se utiliza si existe dependencia del contexto; de lo contrario, se utiliza el procesamiento en paralelo.

CompletableFuture de JDK proporciona una API muy rica, con alrededor de 50 métodos para manejar serialización, paralelismo, combinación y manejo de errores, que pueden satisfacer las necesidades de nuestros escenarios.
Asincronización
El tiempo de respuesta RT de una interfaz está determinado por la complejidad de la lógica de negocio interna, si el proceso de ejecución es más simple, la interfaz tomará menos tiempo.
Por lo tanto, un enfoque común es eliminar la lógica no central dentro de la interfaz y ejecutarla de forma asincrónica.
La siguiente imagen es una interfaz de creación de pedidos de comercio electrónico. Crear registros de pedidos e insertarlos en la base de datos es nuestro requisito principal. En cuanto a notificaciones posteriores al usuario, como enviar un mensaje de texto al usuario , etc., si falla, no afecta la finalización del proceso principal.
Separaremos estas operaciones del proceso principal.

Implementación asincrónica, 可以用线程池,也可以用消息队列,还可以用一些调度任务框架.
La práctica comercial común es enviar un mensaje asincrónico al servidor MQ después de que el pedido se realiza con éxito, y el consumidor monitoreará el tema y realizará un consumo asincrónico.
Tecnología de agrupación
Todos hemos usado grupos de conexiones de bases de datos, grupos de subprocesos, etc. Esta es la encarnación de la idea del grupo. El problema que resuelven es evitar la creación repetida de objetos o conexiones. Se pueden reutilizar y evitar pérdidas innecesarias. Después de todo, la creación y la destrucción también ocupa tiempo.
El núcleo de la tecnología de agrupación es la "preasignación" y el "reciclaje" de recursos. Se utilizan tecnologías de agrupación comunes: grupo de subprocesos, grupo de memoria, grupo de conexiones de bases de datos, grupo de conexiones HttpClient, etc.
Varios parámetros importantes del grupo de conexiones: número mínimo de conexiones, número de conexiones inactivas y número máximo de conexiones.
Por ejemplo, cree un grupo de subprocesos:
new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("data-thread-%d").build(),
(r, executor) -> {
(r instanceof BaseRunnable) {
((BaseRunnable) r).rejectedExecute();
}
});
precalculado
La lógica de cálculo de muchas empresas es relativamente compleja, como una página que necesita mostrar el PV de un sitio web, los sobres rojos de la suerte de WeChat, etc.
Si la lógica de cálculo se activa en el momento en que el usuario accede a la interfaz, estos cálculos lógicos suelen llevar mucho tiempo, lo que dificulta cumplir con los requisitos en tiempo real del usuario.
Es decir, la idea de la captación previa es calcular los datos de la consulta con anticipación y colocarlos en el caché. Al acceder a la interfaz, solo necesita leer el caché, lo que mejorará enormemente el rendimiento de la interfaz.
Por ejemplo: sincronice los datos del inventario de MySQL para redistribuir periódicamente. Al solicitar la deducción de inventario, primero pase redis setNX deduplicación/tabla de deduplicación de mysql y luego paseredis decrement Disminuya los datos del inventario y luego envíe un mensaje asincrónico al servidor MQ
El consumidor monitorea el tema y lo consume de forma asincrónica en múltiples subprocesos.
1. Reducir el inventario (verificar primero y luego actualizar) y redactar el formulario de pedido, que debe ser el mismo. Si es un nodo único, puede usar synchronized para bloquear y resolver el problema de seguridad del subproceso.
Método de bloqueo incorrecto sincronizado: 锁在事物里面
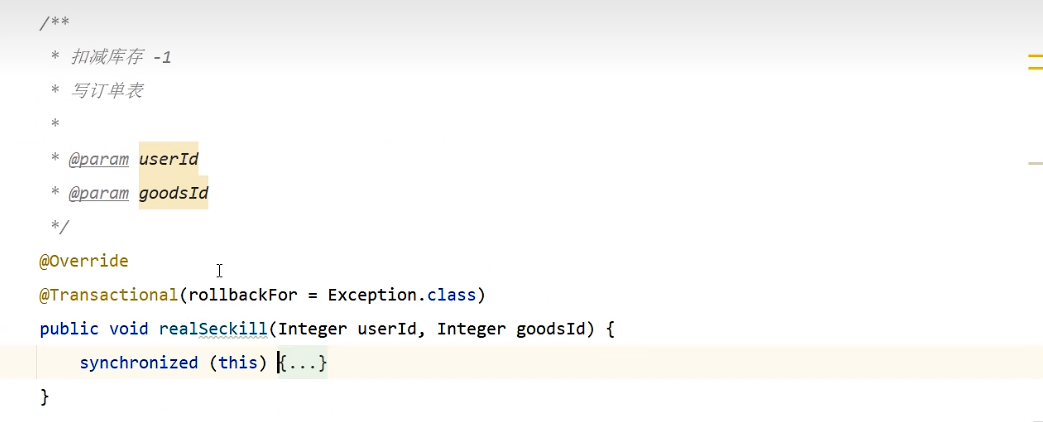
Método de bloqueo correcto sincronizado: 锁在事物外面
2. Si se trata de un multinodo distribuido, se deben agregar bloqueos distribuidos : bloqueo de fila de mysql/bloqueo de redis.
Bloqueo de fila MySQL (bloqueo optimista): extracción descendente, se puede utilizar si la concurrencia no es alta, pero si la concurrencia es alta, causará una gran presión sobre la base de datos. Lo que los programadores deben saber sobre MySQL Advanced Locks (3)
update goods set total_stocks = total_stocks-1 where user_id = ? and total_stocks-1>=0
bloqueo de redis: extracción hacia arriba, bloqueo distribuido redis setnx, la presión se distribuirá a redis y la ejecución del programa para aliviar la presión en db
redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
Determinar si es necesario girar
1. while(true) {} implementa el giro
@Component
@RocketMQMessageListener(topic = "seckillTopic3",
consumerGroup = "seckill-consumer-group3",
consumeMode = ConsumeMode.CONCURRENTLY,
consumeThreadMax = 40
)
public class SeckillListener implements RocketMQListener<MessageExt> {
@Autowired
private GoodsService goodsService;
@Autowired
private StringRedisTemplate redisTemplate;
@Override
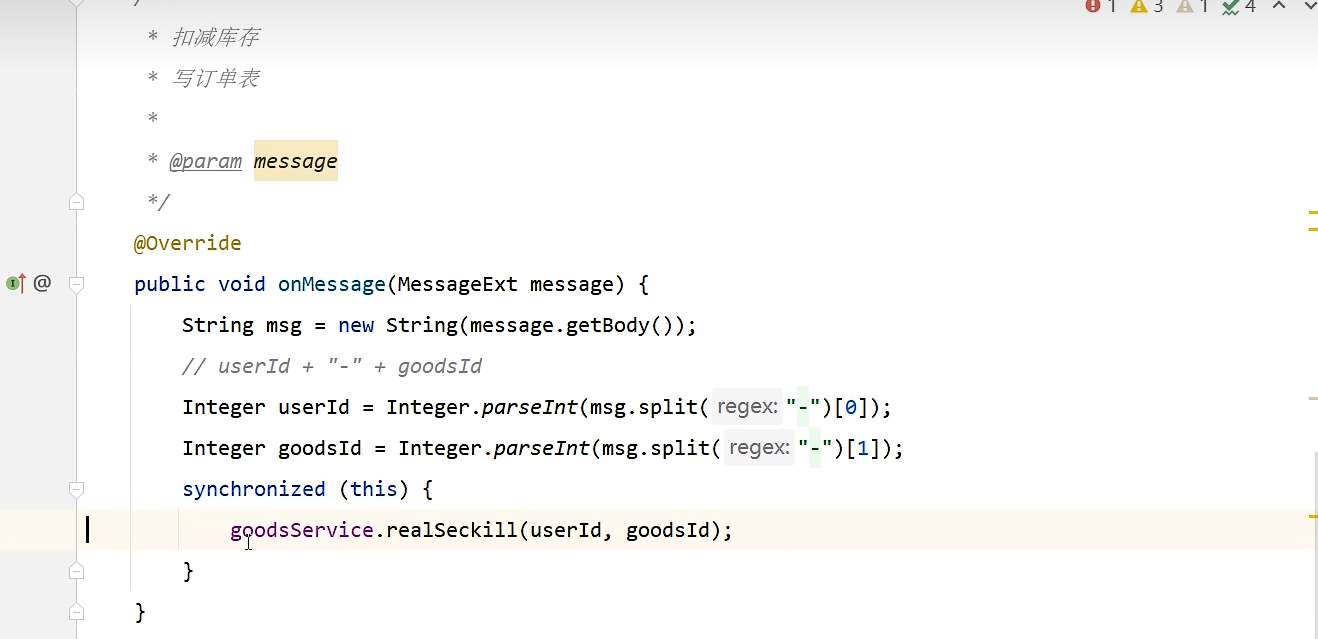
public void onMessage(MessageExt message) {
String msg = new String(message.getBody());
Integer userId = Integer.parseInt(msg.split("-")[0]);
Integer goodsId = Integer.parseInt(msg.split("-")[1]);
while (true) {
// 这里给一个key的过期时间,可以避免死锁的发生
Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));
if (flag) {
// 拿到锁成功
try {
goodsService.realSeckill(userId, goodsId);
return;
} finally {
// 删除
redisTemplate.delete("lock:" + goodsId);
}
} else {
try {
Thread.sleep(200L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2. Llamadas recursivas para implementar giro.
@Override
public void onMessage(MessageExt message) {
String msg = new String(message.getBody());
Integer userId = Integer.parseInt(msg.split("-")[0]);
Integer goodsId = Integer.parseInt(msg.split("-")[1]);
// 这里给一个key的过期时间,可以避免死锁的发生
Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));
if (flag) {
// 拿到锁成功
try {
goodsService.realSeckill(userId, goodsId);
} finally {
// 删除
redisTemplate.delete("lock:" + goodsId);
}
} else {
try {
Thread.sleep(200L);
} catch (InterruptedException e) {
e.printStackTrace();
}
onMessage(message);
}
}
@Service
public class GoodsServiceImpl implements GoodsService {
@Resource
private GoodsMapper goodsMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 行锁(innodb)方案 mysql 不适合用于并发量特别大的场景
* 因为压力最终都在数据库承担
*
* @param userId
* @param goodsId
*/
@Override
@Transactional(rollbackFor = Exception.class)
public void realSeckill(Integer userId, Integer goodsId) {
// update goods set total_stocks = total_stocks - 1 where goods_id = goodsId and total_stocks - 1 >= 0;
// 通过mysql来控制锁
int i = goodsMapper.updateStock(goodsId);
if (i > 0) {
Order order = new Order();
order.setGoodsid(goodsId);
order.setUserid(userId);
order.setCreatetime(new Date());
orderMapper.insert(order);
}
}
}
Modificar inventario
<update id="updateStock">
update goods set total_stocks = total_stocks - 1 ,update_time = now() where goods_id = #{value} and total_stocks - 1 >= 0
</update>
Escribir formulario de pedido
<insert id="insert" keyColumn="id" keyProperty="id" parameterType="cn.zysheep.domain.Order" useGeneratedKeys="true">
insert into `order` (userid, goodsid, createtime
)
values (#{userid,jdbcType=INTEGER}, #{goodsid,jdbcType=INTEGER}, #{createtime,jdbcType=TIMESTAMP}
)
</insert>
granularidad de transacciones
Muchas lógicas comerciales tienen requisitos de transacción y las operaciones de escritura en varias tablas deben garantizar las características de la transacción.
Sin embargo, la transacción en sí requiere un rendimiento particularmente intensivo: para finalizarla lo antes posible y no ocupar los recursos de conexión de la base de datos durante mucho tiempo, generalmente necesitamos reducir el alcance de la transacción.
Coloque mucha lógica de consulta fuera de la transacción.
Además, dentro de la transacción, generalmente no se permite el acceso remoto a la interfaz RPC, ya que suele llevar mucho tiempo. Los principales problemas causados son: punto muerto, tiempo de espera de la interfaz, retraso maestro-esclavo, etc.
Lectura y escritura por lotes
La velocidad de procesamiento de la CPU de la computadora actual sigue siendo muy alta y la IO generalmente es un cuello de botella, como la IO del disco y la IO de la red.
¿Existe algún escenario en el que desee verificar los saldos de las cuentas de 100 personas?
Hay dos opciones de diseño:
Opción 1: abra una única interfaz de consulta y la persona que llama la llama 100 veces en un bucle interno.
Opción 2: el proveedor de servicios abre una interfaz de consulta por lotes y la persona que llama solo necesita realizar la consulta una vez.
¿Qué solución crees que es mejor?
La respuesta es evidente: debe ser la opción dos.
Lo mismo ocurre con las operaciones de escritura de bases de datos: para mejorar el rendimiento, generalmente utilizamos actualizaciones por lotes.
Bloquear granularidad
Los bloqueos son generalmente un medio para proteger los recursos compartidos en escenarios de alta concurrencia, pero si la granularidad del bloqueo es demasiado gruesa, afectará seriamente el rendimiento de la interfaz.
Acerca de la granularidad del bloqueo: significa qué tan grande es el rango que desea bloquear. Ya sea synchronized o redis bloqueo distribuido, solo necesita agréguelo en el recurso crítico. Simplemente ciérrelo. Si no involucra recursos compartidos, no hay necesidad de cerrarlo. Al igual que si quiere ir al baño, solo necesita cerrar la puerta del baño, pero hay no es necesario cerrar la puerta del salón.
Controlar el alcance de la cerradura es el punto clave que debemos considerar.
Método de bloqueo incorrecto:
//非共享资源
private void notShare(){
}
//共享资源
private void share(){
}
private int wrong(){
synchronized (this) {
share();
notShare();
}
}
La forma correcta de bloquear:
//非共享资源
private void notShare(){
}
//共享资源
private void share(){
}
private int right(){
notShare();
synchronized (this) {
share();
}
}
regresar lo antes posible
Antes de iniciar la lógica de negocios, juzgue los parámetros o conjuntos necesarios, si no se establecen, devuélvalos/tírelos lo antes posible.
if(CollectionUtils.isEmpty(list)) {
throw new RuntimeException("数据不合法");
}
paso de contexto
Cuando se necesita un dato, si no hay una interfaz RPC para verificarlo, como una interfaz general como la información del usuario.
Debido a que se usará antes, debo haberlo verificado. Pero sabemos que las llamadas a métodos se entregan en forma de marcos de pila. A medida que un método sale de la pila después de la ejecución, las variables locales dentro del método también se reciclan.
Si necesita utilizar esta información nuevamente más adelante, solo podrá verificarla nuevamente.
Si puede definir un objeto de contexto (ThreadLocal) y almacenar y pasar información intermedia, reducirá en gran medida la presión de volver a consultar en el proceso posterior.
espacio para el tiempo
Un ejemplo bien entendido de intercambio de espacio por tiempo es el uso racional del caché. Para algunos datos que se usan con frecuencia y que se modifican con poca frecuencia, puede almacenarlos en caché con anticipación y verificar el caché directamente cuando sea necesario para evitar consultas frecuentes en la base de datos o cálculos repetidos.
Tamaño del espacio de colección
Si sabemos de antemano cuántos elementos almacenará la colección, intente especificar el tamaño al inicializar la colección, especialmente para colecciones con mayor capacidad.
El tamaño inicial de ArrayList es 10. Si excede el umbral, se expandirá 1,5 veces el tamaño, lo que implica copiar datos de la colección anterior a la nueva colección, lo que desperdicia rendimiento.