먼저 구조체 메모리 정렬을 수행하는 이유는 CPU가 컴퓨터의 비트 수에 따라 고정된 블록 크기로 데이터를 읽는다는 것입니다. 64비트 호스트 CPU는 한 번에 8바이트 블록을 읽고, 32비트 호스트 CPU는 한 번에 4바이트 블록을 읽습니다. 호스트가 고정된 블록 크기를 읽는다는 것을 알고 다음과 같은 시나리오를 가정해 보겠습니다. 32비트 시스템에서 4바이트의 데이터가 두 개의 블록에 분산되어 있습니다. 바이트가 바이트 2~5에 분산되어 있다고 가정합니다. 즉, 0- 3은 첫 번째 블록이고 4-7은 두 번째 블록입니다. 이러한 4바이트의 데이터에 대해 두 개의 블록을 꺼내야 하므로 CPU 읽기 효율성이 어느 정도 감소합니다. 위 데이터의 첫 번째 블록에서 2-3바이트를 직접 버리고 두 번째 블록에 모두 넣으면 CPU는 해당 데이터를 한 번만 읽으면 되며 이는 컴퓨터의 전반적인 효율성을 어느 정도 향상시킵니다. 하지만 공간이 낭비된다는 사실도 알 수 있습니다. 공간과 시간의 교환이 가치 있다는 것이 실습을 통해 입증되었습니다.
여기에서 CPU가 읽는 블록의 크기를 시스템 기본 정렬 바이트 번호 또는 라고 합니다. < a i=4>정렬 계수 비율. 구조체 메모리 정렬에는 네 가지 주요 규칙이 있습니다. 규칙 1: 첫 번째 멤버의 시작 주소는 0입니다. (첫 번째 멤버 오프셋)규칙 2:구조체 내부 멤버의 시작 주소는 시스템의 기본 정렬 바이트보다 작은 정수입니다. 그리고 멤버의 크기. (일반 멤버 정렬)규칙 3:구조체가 중첩된 경우 구조 멤버의 시작 주소는 구조 멤버 내에서 가장 큰 멤버 크기입니다. 정수 배수 , 점유된 주소는 구조체 멤버 자체의 크기에 따라 계산됩니다. (구조체 유형 멤버 정렬)규칙 4:구조체의 모든 내부 멤버가 정렬된 후 전체 구조를 정렬합니다. 구조가 차지하는 전체 메모리 크기는 구조에서 가장 큰 변수 유형 중 더 작은 변수 유형과 시스템의 기본 정렬 바이트 수의 정수 배수여야 합니다. (전체적으로 구조가 정렬되어 있습니다)
위의 설명을 보면, 멤버가 있을 때 규칙 1이 반드시 사용되고, 멤버 수가 2보다 크거나 같을 때 규칙 2가 반드시 사용되고, 멤버 수가 2 이상일 때 규칙 3이 반드시 사용되는 것을 알 수 있습니다. 구조체가 구조체 내부에 중첩되어 있을 때 사용합니다.사용, Rule 4는 무조건 사용됩니다.
따라서 가장 일반적인 두 가지 상황은 다음과 같습니다. 1. 규칙 1, 규칙 2 및 규칙 4가 함께 사용됩니다. 2. 네 가지 규칙을 모두 사용하십시오.
메모리 정렬을 위해 규칙 1, 규칙 2 및 규칙 4를 사용하세요.
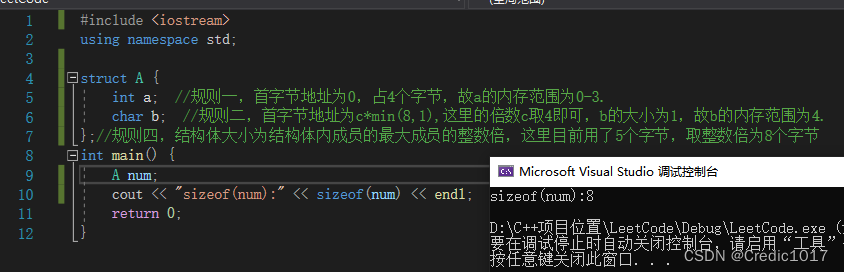
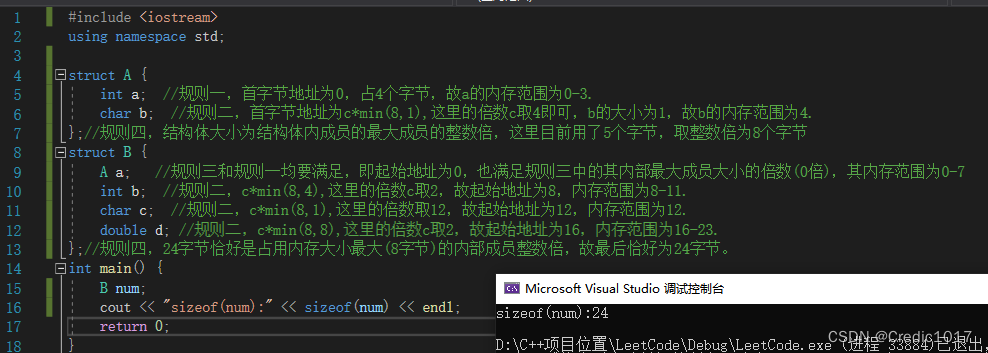
네 가지 규칙을 모두 사용하세요.
참고 블로그: https://www.csdn.net/tags/NtDaUg2sMjUzNTItYmxvZwO0O0OO0O0O.html