Support Vector Machine ist die sogenannte SVM. Sie bezieht sich auf eine Reihe von Algorithmen für maschinelles Lernen und wird entsprechend den verschiedenen gelösten Problemen in SVC (Klassifizierung) und SVR (Regression) unterteilt.
SVC, Support Vector Classification, ist im Wesentlichen eine Support-Vektor-MaschineSupport-Vektor, wird aber nur zur Klassifizierung verwendet< a i =3>KlassifizierungAufgabe SVR, Support Vector Regression, sein Wesen ist auch eine Support Vector MachineSupport Vector< /span> Diese Spalte ist hauptsächlich eine Zusammenfassung der Klassifizierungsalgorithmen . Hauptsächlich SVC einführenAufgabeRegression, nur für Regression
C-Support Vector Classification (C-Support Vector Classifier) wird basierend auf libsvm implementiert. Die Anpassungszeit steht zumindest in einem quadratischen Zusammenhang mit der Anzahl der Proben und ist bei mehr als zehntausend Proben möglicherweise nicht durchführbar. Erwägen Sie bei großen Datensätzen die Verwendung von LinearSVC oder SGDClassifier, möglicherweise nach Verwendung des Nystroem-Transformators oder anderer Kernel-Approximationsmethoden.
1. Algorithmusidee
Nehmen Sie als Beispiel die Zwei-Klassifizierungsaufgabe. Es gibt zwei verschiedene Arten von Probendaten. Eine neue Probe wird empfangen und klassifiziert. Hier sind einige Kernkonzepte, die in meiner eigenen Umgangssprache beschrieben werden.
Suchen Sie eine Linie, die die Beispieldaten dieser beiden Kategorien teilen kann. Diese Linie wird als Entscheidungsgrenze bezeichnet.
Nehmen Sie die Entscheidungsgrenze als Mittelpunkt und übertragen Sie sie auf beide Seiten. Bis zum Der Abtastpunkt wird berührt, das Intervall zwischen den beiden Linien wird als Rand (Intervall) bezeichnet. Der berührte Abtastpunkt wird als Stützvektor bezeichnet
und wird schließlich< a i=3>Finden Sie größter SpielraumProblem
Entscheidungsgrenze: Finden Sie eine Linie (zweidimensional), die die beiden Datenkategorien trennen kann, oder eine Hyperebene (dreidimensional) usw.
Intervall: Zentrieren Sie die Entscheidung Grenze Auf beiden Seiten verschieben, bis der nächste Abtastpunkt erreicht ist. Der Abstand zwischen diesen beiden Linien ist der Rand (Intervall).
Unterstützungsvektor: Auf beide Seiten verschieben, mit der Entscheidungsgrenze als Mittelpunkt. Diese beiden Linien Die angetroffenen Abtastpunkte werden als Stützvektoren bezeichnet
Hartes Intervall: starres Intervall, das Intervall, das durch strikte Befolgung der Lösungsidee des Algorithmus erhalten wird
Weiches Intervall: flexibles Intervall, wenn Gibt es einen Ausreißer oder Rauschpunkt, kann dieser durch Regularisierung eingeschränkt werden, um eine Konsistenz zu erhalten
Das blaue Rauschen hier sollte zur Fünfeckkategorie gehören, es handelt sich jedoch um eine fünfzackige Sternkategorie im Datensatzbeispiel. Bei diesem Beispiel handelt es sich um einen Rauschpunkt, der sich auf die normale Klassifizierung auswirkt und eliminiert werden muss. Zu diesem Zeitpunkt a Soft-Intervall wird eingeführt, um die Auswirkungen von Lärm zu reduzieren.

2. Offizielle Website-API
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
Hier gibt es eine ganze Reihe von Parametern. Informationen zur spezifischen Parameterverwendung können Sie anhand der auf der offiziellen Website bereitgestellten Demo lernen und mehr ausprobieren. Hier finden Sie einige häufig verwendete Parameter zur Erläuterung.
Leitfadenpaket:from sklearn.svm import SVC
①Regularisierungsparameter C
Die Stärke der Regularisierung ist umgekehrt proportional zum Regularisierungsparameter C. Die Strafe ist das Quadrat der L2-Regularisierung. C ist ein Gleitkommazahlentyp.
Die spezifischen offiziellen Website-Details lauten wie folgt:

Verwendung
SVC(C=2.0)
②Kernel-Funktionskernel
'linear': lineare Kernelfunktion, schnell; kann nur Datensatzproben verarbeitenlinear trennbar , kann nicht mit linearer Untrennbarkeit umgehen.
'poly': Polynom-Kernelfunktion, die die Dimension von Datensatzproben erhöhen und von niedrigdimensionalen Karten abbilden kann Raum zu hochdimensionalem Raum. Dimensionsraum; viele Parameter, großer Rechenaufwand
'rbf': Gaußscher Kernel Die Funktion kann, genau wie die Polynom-Kernelfunktion, die Dimension der Stichprobe vergrößern; im Vergleich zur Polynom-Kernelfunktion hat sie weniger Parameter; der Standardwert
'< a i=12>Sigmoid< a i=13>': Sigmoid-Kernelfunktion; bei Verwendung der Sigmoid-Kernelfunktion kann SVM ein mehrschichtiges neuronales Netzwerk implementieren ' vorberechnet ': Kernel-Matrix; verwenden Sie die vom Benutzer angegebene Kernel-Funktionsmatrix (n*n) Sie können auch Ihren eigenen Kernel anpassen Funktion und rufen Sie sie dann auf
Die spezifischen offiziellen Website-Details lauten wie folgt:

Verwendung
SVC(kernel='sigmoid')
③Der Grad der Polynomkernfunktion
Die Ordnung der polynomialen Kernelfunktion; dieser Parameter ist nur für die polynomiale Kernelfunktion (poly) nützlich; wenn es sich um einen anderen Kernel handelt Funktionen wird das System diesen Parameter automatisch ignorieren
Die spezifischen offiziellen Website-Details lauten wie folgt:

Verwendung
SVC(kernel='ploy',degree=2)
④Kernkoeffizient Gamma
rbf, poly und sigmoidDer Kernelkoeffizient der Kernelfunktion. Dieser Parameter gilt nur für diese drei Kernelfunktionen. Bitte beachten Sie, dass
' ' Alternativ können auch andere Gleitkommazahlen verwendet werden': Die spezifische Berechnungsformel finden Sie unten auf der offiziellen Website. auto': Standardwert. Die spezifische Berechnungsformel finden Sie unten auf der offiziellen WebsiteSkala
Die spezifischen offiziellen Website-Details lauten wie folgt:

Verwendung
SVC(gamma='auto')
⑤Zufälliger Startwert random_state
Wenn Sie Variablen zum Vergleich steuern müssen, ist es am besten, den Zufallsstartwert hier auf dieselbe Ganzzahl zu setzen.
Die spezifischen offiziellen Website-Details lauten wie folgt:

Verwendung
SVC(random_state=42)
⑥Zum Schluss das Modell bauen
SVC(C=3.0,kernel=‘sigmoid’,gamma=‘auto’,random_state=42)
3. Code-Implementierung
①Guide-Paket
Hier müssen Sie das Modell auswerten, trainieren, speichern und laden. Im Folgenden sind einige erforderliche Pakete aufgeführt. Wenn während des Importvorgangs ein Fehler gemeldet wird, installieren Sie ihn einfach mit pip.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import joblib
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
②Laden Sie den Datensatz
Der Datensatz kann einfach selbst im CSV-Format erstellt werden. Ich verwende hier 6 unabhängige Variablen X und 1 abhängige Variable Y.
fiber = pd.read_csv("./fiber.csv")
fiber.head(5) #展示下头5条数据信息
③Teilen Sie den Datensatz
Die ersten sechs Spalten sind die unabhängige Variable X und die letzte Spalte ist die abhängige Variable Y
Offizielle API häufig verwendeter Split-Dataset-Funktionen:train_test_split
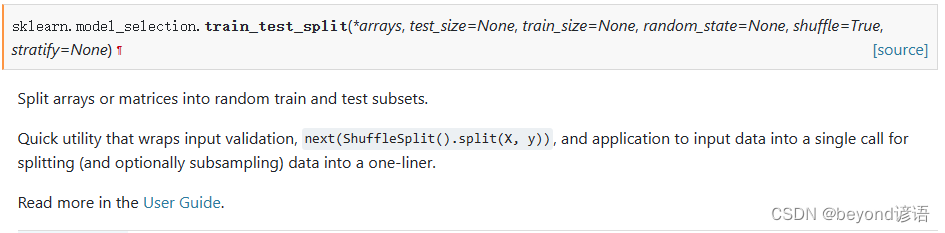
test_size: Anteil der Testset-Daten
train_size: Anteil der Trainingssatzdaten
random_state: Zufälliger Startwert
shuffle: Ob die Daten unterbrochen werden sollen
Weil mein Datensatz hier insgesamt hat 48, Trainingssatz 0,75, Testsatz 0,25, also 36 Trainingssätze und 12 Testsätze
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
X_train, X_test, y_train, y_test = train_test_split(X,Y,train_size=0.75,test_size=0.25,random_state=42,shuffle=True)
print(X_train.shape) #(36,6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12,6)
print(y_test.shape) #(12,)
④Erstellen Sie ein SVC-Modell
Sie können versuchen, die Parameter selbst einzustellen und anzupassen.
svc = SVC(C=3.0,kernel='sigmoid',gamma='auto',random_state=42)
⑤Modelltraining
So einfach ist das: Eine Fit-Funktion kann das Modelltraining implementieren
svc.fit(X_train,y_train)
⑥Modellbewertung
Werfen Sie den Testsatz ein und erhalten Sie die vorhergesagten Testergebnisse
y_pred = svc.predict(X_test)
Überprüfen Sie, ob die vorhergesagten Ergebnisse mit den tatsächlichen Ergebnissen des Testsatzes übereinstimmen. Wenn konsistent, ist es 1, andernfalls ist es 0. Der Durchschnitt ist die Genauigkeit.
accuracy = np.mean(y_pred==y_test)
print(accuracy)
kann auch anhand der Punktzahl ausgewertet werden. Die Berechnungsergebnisse und Ideen sind die gleichen. Sie alle betrachten die Wahrscheinlichkeit, dass das Modell in allen Datensätzen richtig rät. Die Bewertungsfunktion wurde jedoch gekapselt. Natürlich ist die Eingehend Die Parameter sind ebenfalls unterschiedlich. Sie müssen accuracy_score importieren, aus sklearn.metrics import precision_score
score = svc.score(X_test,y_test)#得分
print(score)
⑦Modelltests
Besorgen Sie sich ein Datenelement und bewerten Sie es mit dem trainierten Modell.
Hier sind sechs unabhängige Variablen. Ich werfe sie alle zufälligtest = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
in das Modell. Holen Sie sich das Vorhersageergebnis, prediction = svc.predict(test)
Sehen Sie, was das Vorhersageergebnis ist und ob es mit dem richtigen Ergebnis übereinstimmt, print(prediction)
test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
prediction = svc.predict(test)
print(prediction) #[2]
⑧Speichern Sie das Modell
svc ist der Modellname, der konsistent sein muss
Der folgende Parameter ist der Pfad zum Speichern des Modells
joblib.dump(svc, './svc.model')#保存模型
⑨Laden und verwenden Sie das Modell
svc_yy = joblib.load('./svc.model')
test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据
prediction = svc_yy.predict(test)#带入数据,预测一下
print(prediction) #[4]
Vollständiger Code
Die Modellschulung und -bewertung umfasst nicht ⑧⑨.
from sklearn.svm import SVC
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
svc = SVC(C=3.0,kernel='sigmoid',gamma='auto',random_state=42)
svc.fit(X_train,y_train)#模型拟合
y_pred = svc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = svc.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[23,97215.5,22795.5,2613.09,29.72,1786141.62]])#随便找的一条数据
prediction = svc.predict(test)#带入数据,预测一下
print(prediction)