CNN
我的另外一个博客:深度学习——循环神经网络【吴恩达】,是讲解到底什么是CNN,CNN的前向计算和反向传播的,偏理论和计算,可以参考。
1.提出具体问题
对于图片分类来说,想把一张图片输入到模型中做分类,应该是什么样呢?
图片对计算机来说,其实是一个三维的Tensor(超过二维的矩阵),三个维度分别是(高,宽,channel)其中channel代表通道,对于图片来说是R、G、B三个通道。其中每个通道中的没一个点其实都是一个像素值。

我们都知道,输入到神经网络的其实都是向量,所以如果想把图片输入到神经网络,就要转化成向量来计算,那么如何转化成向量?我们已经得到了三个维度的表示,将三个维度展平就能得到一个一维的输入的向量,比如上图(100,100,3),展平之后,是3x100x100的输入向量。其中每一维向量的数值其实就是表示某一个颜色的强度。
如果用之前的Fully Connected Network(全连接网络),那么100x100x3的输入,如果有1000个神经元,每一个神经元都会给所有输入一个权值,那么这个权值就是100x100x3x1000=3x10^7个权值!(这个值非常大)
所以就要考虑使用别的神经网络来做影像辨识。
2.尝试解决问题
如果不想有那么多的权值,就要想可不可以不要每个神经元都输入整个图像的特征呢?
对具体特征提出两个优化
第一个特征:
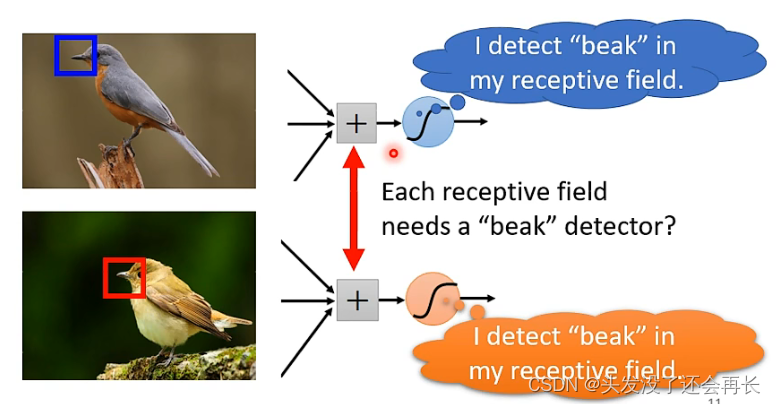
比如下图,要识别一个图像中是不是一只鸟,那么我们发现,只要观察到鸟嘴,鸟爪等关键特征,我们就能识别出来这是一只鸟,所以每一个神经元可以只识别图像的一个局部的特征,而不是把整个图片作为输入。
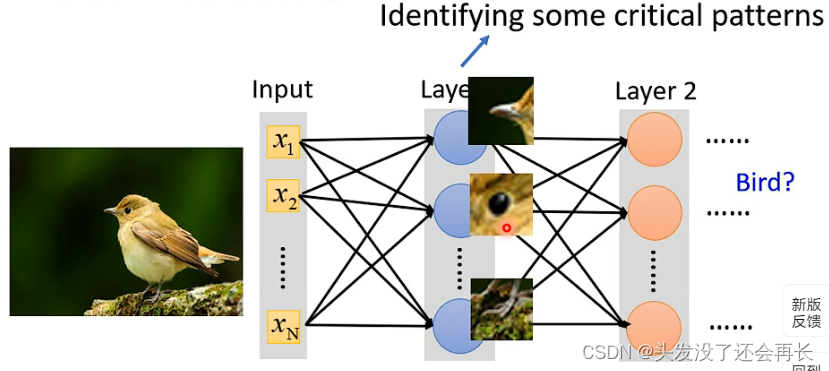
对第一个特征可以这样处理输入:
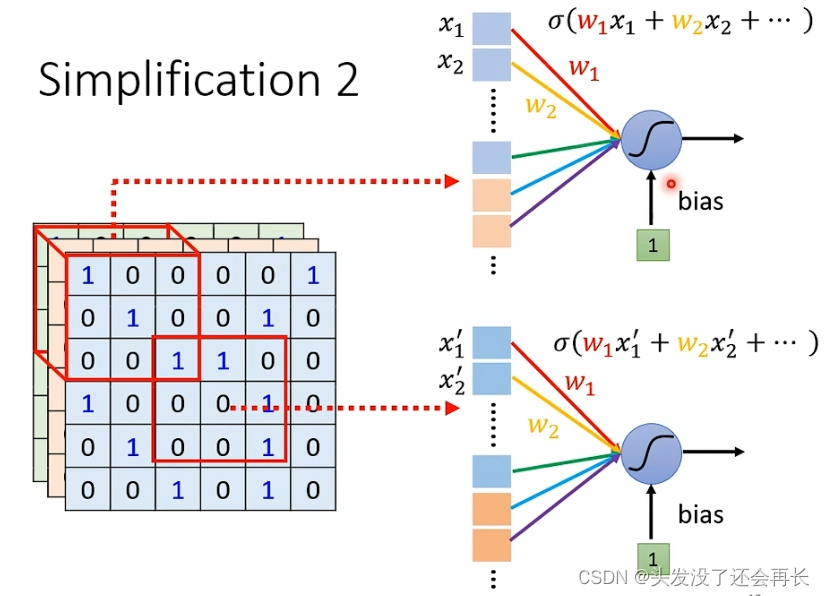
既然每个神经元都只考虑局部的特征,那么每一个神经元的输入就可以只取图像的某一部分像素(这里称Receptive field)作为输入,比如下图,对于蓝色的神经元,我们只取左上角3x3x3的像素作为输入,展平之后,得到的就3x3x3=27维的向量
同样,每个神经元都可以这么做,不同的神经元的输入的像素是可以重叠的,同样,不同的神经元可以对同一个Receptive field做运算。
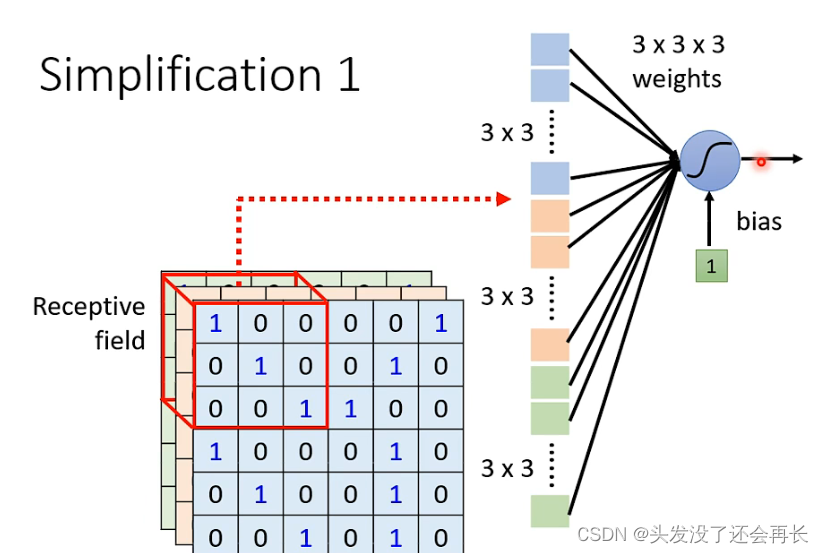
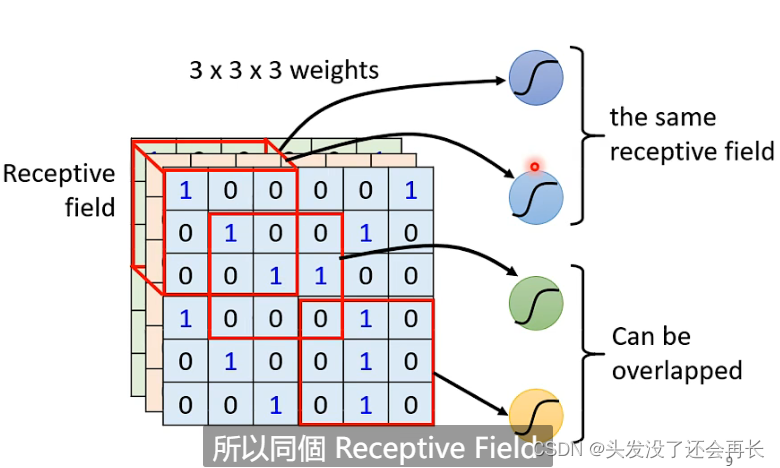
Receptive Filed的大小是可以自己设定的,每个Receptive field也可以只考虑一个channel,但最典型的设定如下:
Receptive Filed考虑所有channel,kernel size是(3x3),每一个Receptive Filed有多个神经元(64),不同Receptive Filed之间是有重叠的(因为有的要观测的特征可能在两个Receptive Filed之间的),超出范围的也要考虑(做padding)
第二个特征:
同样的特征可能出现在图片的不同位置,比如下图,鸟嘴出现在不同的位置,也就是不同的Receptive field,上面已经说过,我们的Receptive field一定是覆盖整张图片的,每一个Receptive field都有多个神经元来检测,那么无论在什么地方的鸟嘴,都一定会落在某个Receptive field内部,会有一组神经元的某个神经元来检测到它
但是,每一个检测鸟嘴的神经元都只一样的,只是所在范围不一样,那么如果每一个范围都有一个检测鸟嘴的神经元,参数就太多了。
对于第二个特征可以这样处理权值:
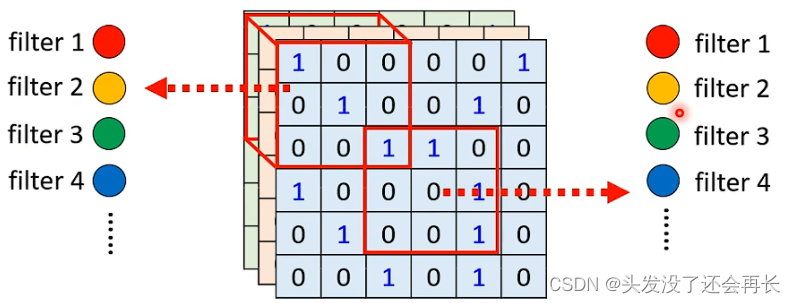
共享参数,我们可以让不同Receptive field的神经元共享参数(就是相同的参数),因为不同的Receptive field神经元的输入是不一样的,所以即使相同的权值,输出也是不一样的。
共享参数的方法可以自己决定,但是典型的处理方法是这样的:
每一个Receptive field都有多个神经元,我们可以假设是64个,每一个神经元都有自己的一组参数filter(一个Receptive field里的不同神经元参数肯定不一样,因为输入一样,参数一样的话,输出也一样了,那两个神经元没什么区别了),不同的Receptive field之间共享,是第一个Receptive field的第一个filter1和第二个Receptive field第一个filter1共享参数,第一个Receptive field的第一个filter2和第二个Receptive field第一个filter2共享参数,以此类推。(下图相同颜色的神经元代表共享参数)
在具体的计算的 时候,就是让每一个filter扫过整张图!也就是卷积运算。
3.总结优化解决问题
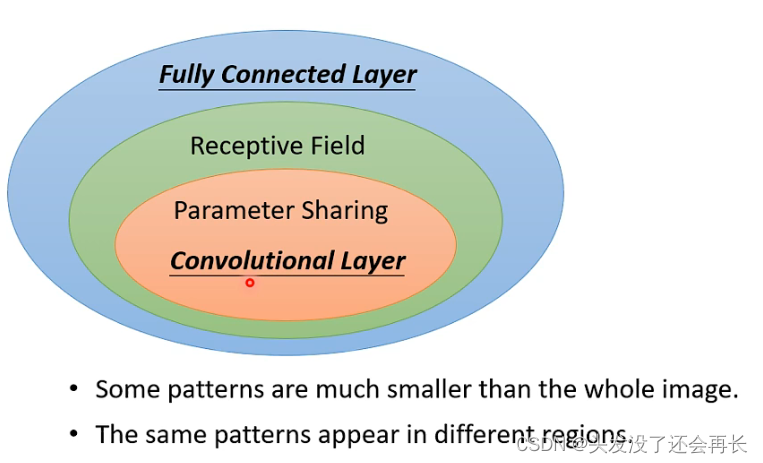
以上两个优化,分别是每个神经元考虑一个Receptive Filed来减小输入参数,不同的Receptive Filed共享相同的参数,共享通过filter实现
这两个优化总结在一起就是:Convolutional Layer
而使用了Convolutional Layer的网络就叫做Convolutional Neural Network(CNN)
补充:
Convolutionnal Layer其实就是计算卷积,关于图像的卷积运算,CSDN很多讲解的很好的博客可以参考,这里不做详细解释。
有多少个filter就会产生多少个channel,每一个filter的高度也要跟输入channel保持一致的,(比如channel是3,filter就是3),每一个channel的大小跟filter和image有关
Q: filter的大小一直是3x3的话,会不会检测不到大范围的pattern?
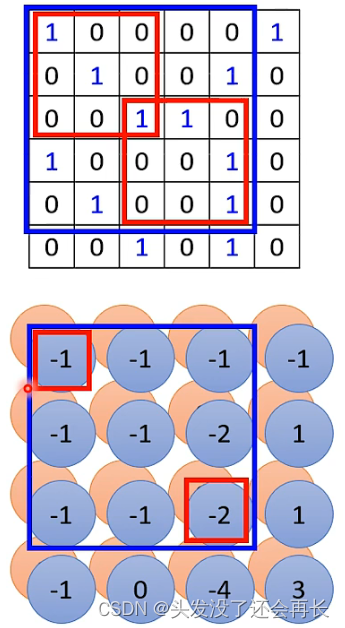
A:并不会,因为第一层的filter检测的是3x3的pattern,得到的结果输入到第二个卷积层,第二个filter还是3x3,但是将上一个结果作为输入,检测的范围其实是5x5的区域(如下图,第二个图像的-1来自第一个图像左上角filter计算的值,第二个图像的-2来自第一个图像右下角filter计算的值,所以第二个filter检测到的是原始图像输入的5x5的pattern),以此类推,只要网络够深,filter即使一直是3x3的,也会检测到足够大的pattern
4.第三个常用的优化
Pooling
依旧是观察图片,如果图片中是一只鸟,我们把做subsampling之后,它看起来还是一只鸟
Pooling这个运算没有要学习的参数,很像网络中的激活函数
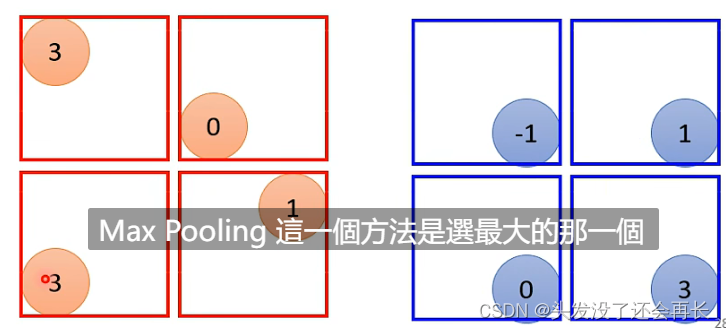
Max Pooling的计算:
在filter之后,会产生一些数字,做Pooling的时候,就把filter产生的结果分组,比如每2x2的数字为一组,Max Pooling就是在每一组挑一个最大值作为这一组的结果,
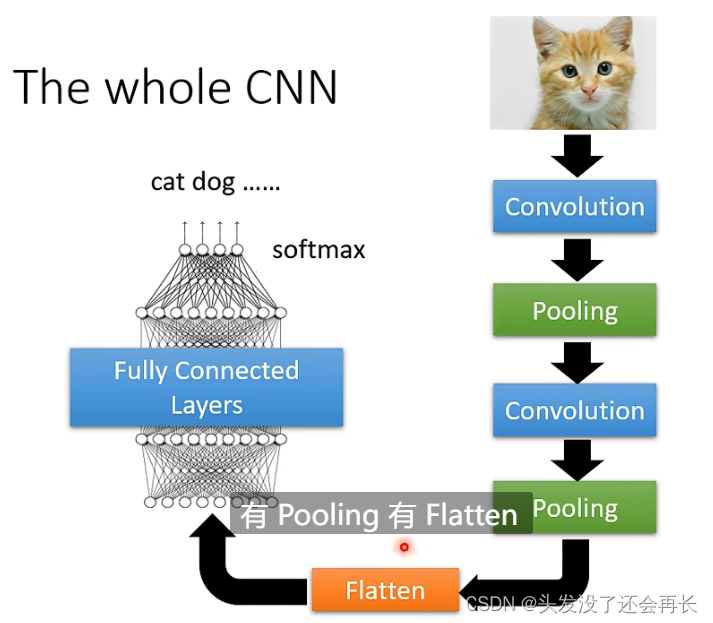
所以Pooling就是会把图片变小(输入变小,但不改变channel数),一般就是一个Convolutional后面一个Pooling,一个Convolutional后面一个Pooling,以此类推,为了得到最后的结果,会做一个操作是Flatten(一个多维的矩阵拉成一维),然后再用一个全连接和softmax输出最终的结果即可。


CNN的其他应用
CNN也可以用在语言和文字处理,但是要考虑文字和语言跟图像是不一样的,所以要考虑如何设计Receptive field来处理。考虑怎么共享参数,这些都要根据语音和文字的特性来设计
CNN的弊端
CNN 不能处理相同的经过放大缩小或者旋转的图片,比如CNN可以识别一张图片是狗,但是当这个图片放大缩小或者旋转之后,他就不能识别了,处理前和处理之后的图片经过Flatten之后,向量的数值是不一样的,所以计算的结果也不同
所以在处理影像的时候会有一个数据增强的方法,就是处理图像本身,它的放大缩小,某一部分也会当做输入来训练网络。