
Ob ein Geschäftssystem vom Typ OLTP eine zentralisierte Datenbank oder eine verteilte Datenbank verwenden sollte, ist eine häufig gestellte Frage bei der Transformation inländischer Datenbanken. Sei es für die Entwicklung und Weiterentwicklung der technischen Architektur oder um die notwendige Unterstützung für die langfristige Entwicklung bereitzustellen. Für die langfristige Entwicklung bestehender Unternehmen ist diese Frage von Diskussionsbedeutung. Im Kontext der verteilten Architektur scheint es, dass jede Architektur eine verteilte Befähigung benötigt. Ist das wirklich so? Eine umfassende Analyse und Erläuterung erfolgt im Folgenden.
Autor: Wang Hui
Der Artikel stammt aus dem öffentlichen WeChat-Konto „Basic Technology Research“.
1. Analyse der aktuellen Nutzung
Im Jahr 2022 wird es mehr als 200 inländische Datenbankhersteller geben. Die traditionellen zentralisierten Datenbanken sind hauptsächlich Renmin Jincang und Dameng. Es gibt auch aufstrebende Datenbanken wie polarDB. Zu den verteilten Datenbanken gehören GaussDB, Kingwow, TDSQL, GoldenDB und OceanBase usw. Tatsächlich die meisten Für diese Datenbanken gibt es zwei Bereitstellungsmodi: zentralisiert und verteilt. Das heißt, das Geld, das Sie für verteilte Datenbanken ausgeben, kann auch für die zentralisierte Bereitstellung verwendet werden, die Ihren unterschiedlichen Geschäftsanforderungen gerecht wird.
Hierbei ist zu beachten, dass einige Anbieter verteilter Datenbanken eine zentralisierte Bereitstellung übernehmen und Anwendungen weiterhin eine Verbindung zu Rechenknoten herstellen müssen. Verbinden Sie die folgenden Datenknoten über den Rechenknoten (CN). Dies kann auf die Berücksichtigung einer einheitlichen Architektur zurückzuführen sein und auch darauf, dass der Rechenknoten die automatische Umschaltung erkennen und für die Anwendung transparent sein kann, wenn die Datenbank zwischen aktiv und Standby wechselt. Dadurch wird jedoch unbeabsichtigt eine Analyseebene hinzugefügt, die zu einem gewissen Leistungsverlust führt. Einige Datenbankanbieter stellen über ihre eigenen JDBC/ODBC-Treiber oder VIP eine direkte Verbindung zur Datenbank her und vermeiden so ähnliche Probleme.
Aus Sicht der technischen Architektur sind die in der Finanzbranche verwendeten Datenbanken immer noch hauptsächlich zentralisiert, und verteilte Datenbanken haben in mittleren und großen Finanzinstituten eine starke Ergänzung gebildet. Forschungsdaten aus dem „Financial Industry Database Supply Chain Security Development Report (2022)“ zeigen, dass zentralisierte Datenbanken immer noch 89 % der gesamten Finanzbranche ausmachen, davon 80 % Banken, und die Wertpapier- und Versicherungsbranche mehr als 90 % ausmacht %. Zentralisierte Datenbanken spielen eine wichtige Rolle im Digitalisierungsprozess der Finanztechnologie. Der Gesamtanteil verteilter Datenbanken in der Finanzbranche erreicht 7 %, im Bankensektor übersteigt er 17 % und in der Wertpapier- und Versicherungsbranche ist der Anteil relativ niedrig. Mit anderen Worten: Es ist völlig zufriedenstellend, für die meisten unserer Geschäfte eine zentralisierte Datenbank zu verwenden.
2. Ist eine Verteilung wirklich nötig?
Da eine zentralisierte Datenbank nur über einen Hauptdatenknoten verfügt, bietet sie natürlich die Vorteile einer einfachen Architektur, einer bequemen Bedienung und Wartung, einer guten Kompatibilität und einer hohen Kostenleistung.
Es gibt jedoch auch Probleme wie die Unfähigkeit, die Hardwarebeschränkungen einer einzelnen Maschine zu überwinden, die Unfähigkeit zur horizontalen Erweiterung und das Vorhandensein von Leistungs- und Kapazitätsengpässen.
Wenn also die zentralisierte Datenbank unsere Leistungs- und Kapazitätsanforderungen nicht erfüllen kann, bietet uns die verteilte Datenbank ein gutes technisches Mittel. Wenn wir planen, verteilte Lösungen zur Lösung zentraler Probleme zu wählen, wird empfohlen, dass Sie die folgenden Fragen stellen, bevor Sie darüber nachdenken:
- Ist es möglich, das Problem durch die Optimierung der zentralisierten Datenbank selbst zu lösen, ohne größere Architekturänderungen vorzunehmen, wie z. B. die Optimierung von Parametern, die Optimierung von SQL-Anweisungen, die Optimierung der Geschäftslogik usw.
- Ist es möglich, das Problem durch eine Erhöhung der Host-Ressourcenkonfiguration zu lösen, z. B. durch eine Erhöhung der CPU- und Speichergröße, oder durch die Verwendung einer vertikalen Erweiterungsmethode, z. B. durch den Wechsel von einer virtuellen Maschine zu einer physischen Maschine?
- Kann das Problem durch die Trennung von Speicher und Rechenleistung gelöst werden? Wenn die Kapazität einer einzelnen Maschine die Anforderungen nicht erfüllen kann, können Sie Plug-in-Speicher in Betracht ziehen oder eine Speicher-Rechen-Trennarchitektur übernehmen, um das Problem der begrenzten Festplattenkapazität einer einzelnen Maschine zu lösen .
- Kann es über die Anwendungsschicht gelöst werden, z. B. durch Ändern der Geschäftsarchitektur und Einführung von Microservices oder einer einheitlichen Architektur, d. Diese Methode stellt hohe Anforderungen an Entwickler und hohe Geschäftstransformationskosten, die umfassend berücksichtigt werden müssen.
- Ob Sie die Vor- und Nachteile einer verteilten Architektur vollständig verstehen, ob Sie Vorbereitungen für den Betrieb, die Wartung und die Sicherung verteilter Datenbanken getroffen haben und ob Sie vollständig darüber nachdenken, dass Ihr Geschäft durch verteilte Datenbanken gelöst werden muss.
3. Wann verteilt man es?
Früher gab es ein Sprichwort, dass eine Tabelle mit 20 Millionen Zeilen aufgeteilt werden müsse. Dies galt hauptsächlich für die MySQL-Datenbank. Wenn die OLTP-Typtabelle 2000 W Zeilen überschreitet, wird die Anzahl der B+Baum-Blattschichten durch Formelberechnung auf 4 erhöht, wodurch die Anzahl der E/A-Lesevorgänge erhöht wird. Bei der Aufrüstung der Hardware oder der Implementierung der Caching-Technologie können die Auswirkungen von IO jedoch grundsätzlich ignoriert werden. Daher ist es derzeit üblich, TPS- oder QPS-Indikatoren zu verwenden, um zu bestimmen, ob eine verteilte Transformation erforderlich ist, z. B. wenn der Einzelpunkt-TPS-Engpass 4000 erreicht, QPS 8 W erreicht oder die Datenkapazität 2 TB erreicht. Unter normalen Umständen ist eine horizontale Erweiterung erforderlich, um Leistungs- oder Kapazitätsengpässe zu beheben, was relativ sinnvoll ist. Hier gibt es jedoch keine feste Formel, sondern es ist hauptsächlich erforderlich, Urteile auf der Grundlage Ihrer eigenen Geschäftsszenarien zu fällen. Wir sollten auch die Anforderungen des zukünftigen Geschäftswachstums berücksichtigen, z. B. ob es die Wachstumsanforderungen des Unternehmens in drei bis fünf Jahren erfüllen kann, Spitzenvorhersagen treffen und im Voraus planen, um sekundäre Transformationen zu vermeiden. Sehen Sie sich gleichzeitig die verschiedenen oben genannten Probleme an, um festzustellen, ob sie durch eine verteilte Datenbank gelöst werden müssen.
Experimentelle Daten eins (Finden des Wendepunkts)
Die Hardwareressource ist die virtuelle Maschinenumgebung Kunpeng, die auf der ARM-Architektur basiert. Die spezifische Konfiguration ist 16C64G. Der Gewinner ist das Betriebssystem Kirin v10 und eine normale SSD-Festplatte.
Die folgende Abbildung zeigt die Testergebnisse einer inländischen verteilten Datenbank. Die Verteilung beträgt 4 Shards, Einheit: Sekunden.

Für Single-Point-Index-basierte Abfragen gibt es grundsätzlich keine Lücke. Bei vollständigen Tabellenscans und Dual-Table-Assoziationen (die zugehörigen Tabellen umfassen einheitlich 2 Millionen Zeilen und basieren auf Shard-Schlüsseln als Assoziationsbedingungen) beträgt die Zahl bereits etwa das Fünffache wenn die Datenmenge 5 Millionen beträgt. Es gab eine deutliche Verbesserung. Um ehrlich zu sein, habe ich diese Wende etwas früher geschafft. Tatsächlich muss es noch anhand Ihrer eigenen Geschäftsszenarien überprüft werden, um genauer zu sein.
Bei Datenmengen unter 5 Millionen können Sie es je nach Unternehmen selbst testen. Natürlich kann es bei 300 W oder weniger zu einem Wendepunkt kommen. Ich hoffe, dass Sie hier weitere Testergebnisse liefern können. Die experimentellen Daten können aufgrund verschiedener Faktoren gewisse Abweichungen aufweisen. Bitte korrigieren Sie mich. Wir hoffen auch, dass jeder seine Testergebnisse in den Kommentarbereich stellen kann, damit jeder die Leistungswendepunkte verteilter und zentralisierter Systeme überprüfen kann. Dies kann mehr bringen genau Die Datenbasis dient als Referenz für die Auswahl.
Experimentelle Daten zwei
Das folgende Bild ist das Ergebnis eines Stresstests eines Herstellers auf Basis des Sysbench-Tools:

Es ist ersichtlich, dass, wenn die Ressourcennutzung der zentralisierten Datenbank in einer mittelgroßen Konfiguration 75 % erreicht, der maximal erreichbare TPS 4595 beträgt, die Verzögerung 5 ms beträgt und die Parallelität 400 beträgt. Dabei handelt es sich um einen Referenzwert, der die Grundlage für die Aufteilung des oben genannten Basis-TPS bildet, wenn dieser 5.000 übersteigt. Wenn Ihre Ressourcen groß genug sind, kann dieser Wert natürlich größer sein. Aber am genauesten müssen wir unseren TPS-Wert durch Stresstests in der realen Umgebung überprüfen, um ein Urteil zu erhalten.
4. Wie man Distributed sinnvoll nutzt
Wie der Name schon sagt, ist es verteilt, wobei mehrere Personen arbeiten, und bietet die Vorteile hoher Verfügbarkeit, hoher Skalierbarkeit, hoher Leistung und elastischer Expansions- und Kontraktionsfähigkeiten.
Mit zunehmender Anzahl von Datenknoten und Datenbankkomponenten treten zwangsläufig Probleme wie komplexe Architektur, komplexer Betrieb und Wartung sowie hohe Kosten auf. Gleichzeitig unterstützen die meisten verteilten Datenbanken keine speziellen Objekte wie gespeicherte Prozeduren und benutzerdefinierte Funktionen.
Verteilung ist ein zweischneidiges Schwert, und es ist sehr wichtig, wie wir es gut nutzen, ohne Schaden zu nehmen.
1. Auswahl des Shard-Schlüssels
Die Wahl des Sharding-Schlüssels ist sehr wichtig. Der Wert des als Sharding-Schlüssel ausgewählten Felds sollte relativ diskret sein, damit die Daten gleichmäßig auf jeden Datenknoten verteilt werden können. Wenn ein einzelnes Feld keine diskreten Bedingungen erfüllen kann, können Sie erwägen, mehrere Felder zusammen als Sharding-Schlüssel zu verwenden. Im Allgemeinen können Sie erwägen, den Primärschlüssel der Tabelle als Sharding-Schlüssel auszuwählen. Wählen Sie beispielsweise die ID-Nummer als Verteilungsschlüssel in der Personalinformationstabelle aus. Und die meisten verteilten Datenbanken unterstützen oder empfehlen keine Änderung von Shard-Schlüsseln.
2. Wahl der Verteilungsmethode
Eine häufige Wahl ist die Hash-Verteilung, die relativ gleichmäßiger verteilt ist. Es gibt auch Partitionen wie Bereich und Liste. Natürlich müssen wir letztendlich eine Auswahl basierend auf bestimmten Geschäftsszenarien treffen. Darüber hinaus müssen einige häufig verwendete Konfigurationsinformationstabellen oder kleine Tabellen für verwandte Abfragen als globale Tabellen definiert werden, um sicherzustellen, dass sie an einem Datenknoten abgerufen werden können, um eine Dateninteraktion zwischen Knoten zu vermeiden.
3. Standardisieren Sie das Schreiben von SQL-Anweisungen
Der Sharding-Schlüssel sollte als Abfragebedingung ausgewählt werden und der Sharding-Schlüssel sollte als Abfragebedingung für die Zuordnung mehrerer Tabellen verwendet werden. Wenn keine Sharding-Schlüssel verwendet werden, findet eine knotenübergreifende Datenübertragung statt. Einige verteilte Datenbanken aggregieren alle Daten zur Zusammenfassung und Korrelationssortierung in Rechenknoten. Wenn die Daten groß sind, werden die Ressourcen der Rechenknoten sofort aufgefüllt, was dazu führt, dass die Datenbank nicht funktioniert nicht in der Lage sein, der Außenwelt zur Verfügung gestellt zu werden. Dienen.
4. Vermeiden Sie eine knotenübergreifende Datenübertragung
Wie oben erwähnt, dient die Verwendung von Abfragebedingungen als Sharding-Schlüssel dazu, eine knotenübergreifende Übertragung weitestgehend zu vermeiden. Da die knotenübergreifende Datenübertragung auf dem Netzwerk basiert, besteht eine große Lücke in der Übertragungs-, Lese- und Schreibleistung des Netzwerks Im Vergleich zur Festplatte wird die Leistung offensichtlich sinken, und es kann sogar Situationen geben, in denen die Ergebnisse nie angezeigt werden.
5. Vermeiden Sie verteilte Transaktionen
Die verteilte Transaktionsverarbeitung hat einen langen Weg. Dies liegt in ihrer Natur. Die meisten Datenbanken werden nach dem 2PC-Prinzip implementiert. Daher müssen wir verteilte Transaktionen weitestgehend vermeiden. Im Allgemeinen sollten sie innerhalb von 10 % aller Transaktionen kontrolliert werden. Zu viele verteilte Transaktionen wirken sich definitiv negativ auf die Leistung aus und bringen auch Herausforderungen für die Konsistenz der Geschäftsdaten mit sich.
5. Vertiefende Analyse: Handelt es sich beim Vertrieb um eine Datenbanklösung oder eine Anwendungslösung?
Die verteilte Implementierung kann durch Datenbanken (verteilte Datenbanken) oder durch Anwendungen gelöst werden. Die meisten Entwickler, insbesondere Finanzinstitute wie traditionelle Industrien oder städtische Geschäftsbanken, verfügen über weniger Entwicklungskapazitäten als große Banken und eine begrenzte Personalgröße. Sie ziehen es vor, dass die Datenbank mehr Dinge erledigt. B. die Implementierung verteilter Transaktionen und Datenaufteilung, und ist für Entwickler so transparent wie möglich. Daher werden sie direkt verteilte Datenbanken verwenden und die unten gezeigte einheitliche Architektur als Beispiel nehmen:
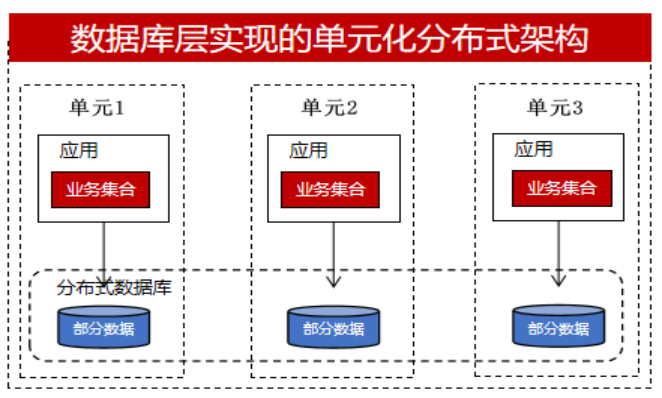
Einige wichtige Geschäftssysteme oder Teams mit bestimmten Entwicklungskapazitäten werden jedoch eine Implementierung auf der Anwendungsebene in Betracht ziehen. Sie möchten mehr Kontrolle erlangen. Wenn in einer verteilten Transaktion eine Anomalie auftritt und diese auf Datenbankebene implementiert wird, ist dies eine Black Box für den Entwickler. Er kann sich nur auf die verteilten Transaktionsverarbeitungsfunktionen der Datenbank freuen. und sie können nicht eingreifen. . Wenn es jedoch auf der Geschäftsebene implementiert wird, können sie die aus Nachrichtenwarteschlangen, TCC, Saga usw. erhaltenen Protokollinformationen verwenden und den Datenkompensationsmechanismus verwenden, um die entsprechende Verarbeitung durchzuführen. Daher erreichen sie eine Verteilung in der Anwendungsschicht und die Datenbank übernimmt einen zentralisierten Ansatz. Jede Datenbank speichert einen Teil der Geschäftsdaten mit einer einheitlichen Architektur, wie in der folgenden Abbildung dargestellt:
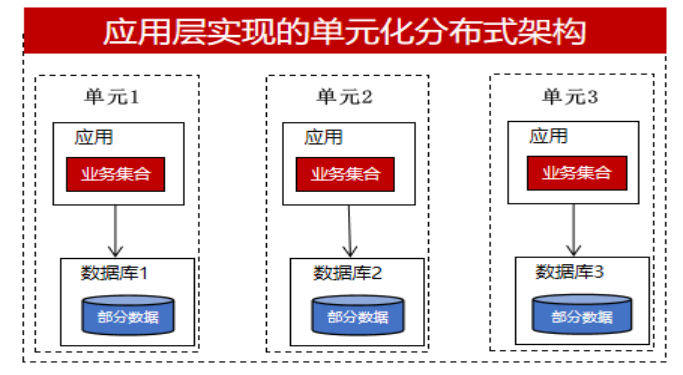
Die Unterschiede zwischen zentralisierten und verteilten Datenbanken bei der Implementierung verteilter Methoden lassen sich wie folgt zusammenfassen:
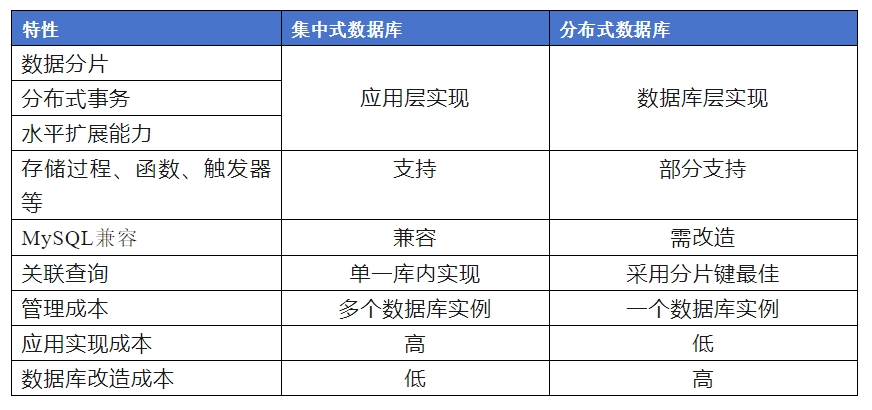
Bei Verwendung einer zentralisierten Datenbank stellt die Anwendungsschicht höhere Anforderungen an verteilte Anwendungen, um verteilte Eigenschaften zu erreichen. Auf Datenbankebene gibt es jedoch relativ wenige Änderungen, da die Kompatibilität zentralisierter Datenbanken besser ist als die verteilter.
Bei Verwendung einer verteilten Datenbank muss die Anwendung keine verteilten Funktionen implementieren und ist für die Anwendung transparent. Allerdings weist die verteilte Datenbank eine schlechte Kompatibilität auf oder unterstützt sogar keine speziellen Objekte wie gespeicherte Prozeduren und Funktionen. Dies erfordert eine Anpassung der Anwendung die Datenbank.
6. Zusammenfassung
Bei einem Roundtable-Forum zum Thema Datenbankinnovation sagte ein Lehrerkollege, dass eine zentralisierte Datenbank wie ein Schaf sei, fügsam und leicht zu verwalten, während eine verteilte Datenbank ein wildes Pferd sei, widerspenstig und schwer zu kontrollieren. Das erinnert mich an Song Dongyes „Dong „In dem Lied „Miss“ heißt es: „Ich habe mich in ein wildes Pferd verliebt, aber in meinem Haus gibt es kein Grasland, was mich verzweifelt macht ...“. Das wilde Pferd der verteilten Datenbank kann gezähmt werden und Sie durch die Prärie galoppieren lassen, andernfalls wird es Sie leiden und kämpfen lassen. Tatsächlich hoffen die meisten Entwickler immer noch, dass die Datenbank mehr leistet, die Entwickler weniger Änderungen vornehmen und die Datenbank transparenter, einfacher und noch intelligenter wird.
Abschließend möchte ich sagen, dass unsere inländische Datenbank noch einen langen Weg vor sich hat. Tatsächlich sind Kunden mehr an der Verbesserung grundlegender Funktionen interessiert als an der Hinzufügung neuer Funktionen. Wenn wir in der Kernspeicher-Engine der Datenbank und der Ökologie gute Arbeit leisten können, werden wir dieses Thema in der OLTP-Datenbank nicht ausführlich diskutieren.
Sollte der Artikel eine ungenaue oder unprofessionelle Formulierung enthalten, korrigieren Sie mich bitte. Vielen Dank.
Weitere technische Artikel finden Sie unter: https://opensource.actionsky.com/
Über SQLE
SQLE ist eine umfassende SQL-Qualitätsmanagementplattform, die die SQL-Prüfung und -Verwaltung von der Entwicklung bis zur Produktionsumgebung abdeckt. Es unterstützt gängige Open-Source-, kommerzielle und inländische Datenbanken, bietet Prozessautomatisierungsfunktionen für Entwicklung, Betrieb und Wartung, verbessert die Online-Effizienz und verbessert die Datenqualität.
SQLE erhalten
| Typ | Adresse |
|---|---|
| Repository | https://github.com/actiontech/sqle |
| dokumentieren | https://actiontech.github.io/sqle-docs/ |
| Neuigkeiten veröffentlichen | https://github.com/actiontech/sqle/releases |
| Entwicklungsdokumentation für das Datenaudit-Plug-in | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |