Stability AI has released the open source video generation model Stable Video Diffusion, which is based on the company's existing Stable Diffusion text-to-image model and can generate videos by animating existing images.
Main features
- text to video
- image to video
- 14 or 25 frames, 576 x 1024 resolution
- Multi-view generation
- frame interpolation
- Support 3D scenes
- Control cameras via LoRA

Stable Video Diffusion provides two models, namely SVD and SVD-XT. Among them, SVD converts still images into 14-frame 576x1024 video, while SVD-XT increases the number of frames to 24 under the same architecture.
Both can produce video at 3 to 30 frames per second. The white paper shows that the two models are initially trained on a dataset of millions of videos and then "fine-tuned" on smaller datasets on the order of hundreds of thousands to millions.
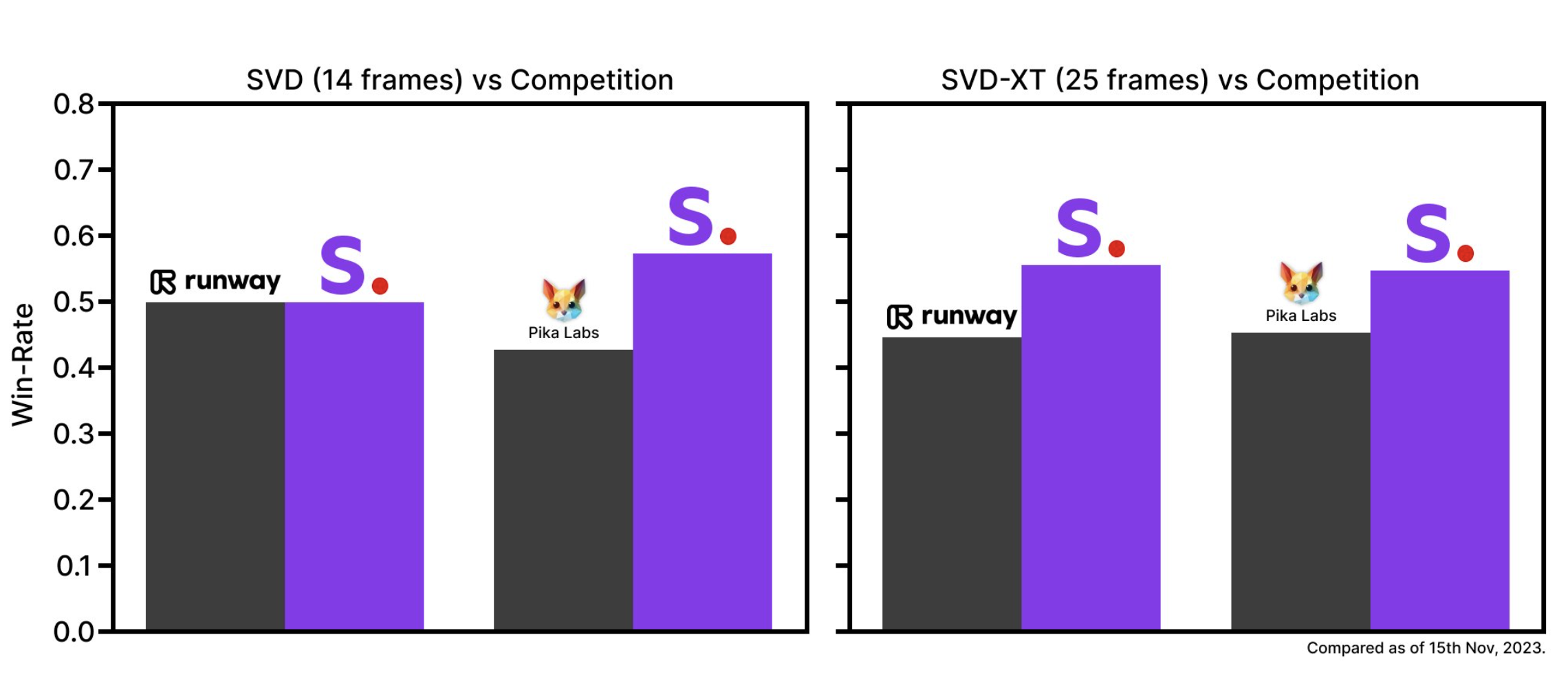
Stability AI says it is developing a new web platform, including a text-to-video interface. This tool will demonstrate the practical application of Stable Video Diffusion in advertising, education, entertainment and other fields.
Open source address