
Autor: Shang Zhuoran (PsiACE)
Estudiante de maestría en la Universidad de Ciencia y Tecnología de Macao, pasante de ingeniería de I+D de Databend
Comprometido Apache OpenDAL (en incubación)

La computación en la nube proporciona servicios de almacenamiento compartido, elásticos y económicos para aplicaciones centradas en datos, lo que proporciona beneficios obvios para los flujos de trabajo de procesamiento de datos modernos: datos masivos, alto acceso simultáneo, gran rendimiento y cada vez más casos. Comience a migrar la pila de tecnología antigua a los datos. arquitectura del lago.
Cuando ponemos el lago de datos en la nube surgen nuevos problemas:
-
Es posible que la antigua tecnología de almacenamiento de datos/análisis de big data no esté diseñada específicamente para el almacenamiento en la nube y de objetos. El rendimiento y la compatibilidad pueden no ser ideales y es necesario invertir muchos recursos en mantenimiento. ¿Cómo proporcionar una tecnología verdaderamente moderna y de bajo costo? ¿Lago de datos de costos?, ¿Servicios de análisis de alto rendimiento y alta calidad?
-
La demanda de gestión de datos no ha hecho más que fortalecerse, planteando requisitos más elevados para la reproducibilidad de los resultados de los análisis y la posibilidad de compartir las fuentes de datos. Cómo proporcionar elasticidad y manejabilidad a los datos, de modo que los científicos de datos, los analistas de datos y los ingenieros de datos colaboren estrechamente de forma lógicamente coherente. ¿vista?
Si tienes preguntas, ¡habrá respuestas!
Databend crea un almacén de datos nativo y verdaderamente entre nubes basado en el almacenamiento de objetos en la nube. Diseñado utilizando el concepto sin servidor, proporciona un motor de consultas de alto rendimiento distribuido, escalable elásticamente y fácil de operar y mantener. Admite datos estructurados y semiestructurados comunes y puede integrarse estrechamente con pilas de tecnología de datos modernas.
lakeFS se dedica a brindar soluciones para compartir y colaborar en datos. Potencie el almacenamiento de objetos con una lógica operativa similar a Git, utilice soluciones de control de versiones para proporcionar una vista lógicamente coherente de los datos, incorpore nombres de sucursales significativos e información de envío en flujos de trabajo de datos modernos y proporcione soluciones para la integración de datos y documentos.
En este artículo, combinaremos los dos y brindaremos un taller simple y claro para ayudarlo a construir rápidamente un flujo de trabajo de datos moderno.
Por qué necesitas Databend
A medida que aumenta la cantidad de datos, los almacenes de datos tradicionales enfrentan enormes desafíos. No pueden almacenar ni procesar cantidades masivas de datos de manera efectiva, y es difícil ajustar de manera flexible los recursos informáticos y de almacenamiento según la carga de trabajo, lo que genera altos costos de uso. Además, el procesamiento de datos es complejo y requiere la inversión de muchos recursos en ETL, y la reversión de datos y el control de versiones también son muy difíciles.
Databend tiene como objetivo resolver estos puntos débiles. Es un almacén de datos en la nube de código abierto, elástico y con reconocimiento de carga desarrollado con Rust, que puede proporcionar capacidades de análisis complejas y rentables para conjuntos de datos a muy gran escala.
-
Compatible con la nube: integra a la perfección varios almacenamientos en la nube, como AWS S3, Azure Blob, CloudFlare R2, etc.
-
Alto rendimiento: Desarrollado en Rust, utilizando SIMD y procesamiento de vectorización para lograr un análisis extremadamente rápido.
-
Flexibilidad económica: Diseño innovador, escalamiento independiente de almacenamiento y computación, optimizando costos y rendimiento.
-
Gestión de datos sencilla: capacidades de preprocesamiento de datos integradas, no se requieren herramientas ETL externas.
-
Control de versiones de datos: proporciona almacenamiento de múltiples versiones similar a Git, que admite consultas, clonaciones y reversiones de datos en cualquier momento.
-
Compatibilidad con datos enriquecidos: admite múltiples formatos y tipos de datos, como JSON, CSV, Parquet, etc.
-
Análisis mejorado con IA: integre funciones de IA para proporcionar capacidades de análisis de datos impulsadas por modelos grandes.
-
Impulsado por la comunidad: Tiene una comunidad amigable y en continuo crecimiento y proporciona una plataforma de análisis en la nube fácil de usar.

La imagen de arriba es el diagrama de arquitectura de Databend, tomado de datafuselabs/databend .
Por qué necesitas LakeFS
Dado que el almacenamiento de objetos a menudo carece de atomicidad, reversión y otras capacidades, no se puede garantizar bien la seguridad de los datos y la calidad y la capacidad de recuperación también disminuyen. Para proteger los datos en el entorno de producción, a menudo es necesario utilizar copias aisladas para las pruebas de ensayo, lo que no sólo consume recursos, sino que también dificulta una verdadera colaboración.
Cuando se trata de colaboración, puede pensar en Git, pero Git no está diseñado para la gestión de datos. Además de los inconvenientes de la gestión de datos binarios, el límite de Git LFS en el tamaño de un solo archivo también restringe sus escenarios aplicables.
Nació lakeFS, que proporciona control de versiones de datos de código abierto para lagos de datos: bifurcar, confirmar, fusionar, revertir, como usar Git para administrar el código. Con soporte para entornos de aislamiento de prueba/desarrollo sin copia, verificación de calidad continua, reversión atómica de datos erróneos, repetibilidad y otras características avanzadas, incluso puede verificar fácilmente los flujos de trabajo ETL en datos de producción sin preocuparse por daños a su negocio.

La imagen de arriba muestra el flujo de trabajo de datos recomendado por lakeFS, tomada de https://lakefs.io/ .
Taller: Utilice lakeFS para respaldar su negocio de análisis
En este taller, usaremos lakeFS para crear ramas para el repositorio y usaremos Databend para analizar y transformar los datos preestablecidos.
Dado que el entorno experimental contiene algunas dependencias, el primer inicio puede llevar mucho tiempo. También recomendamos utilizar la combinación de Databend Cloud + lakeFS cloud , para que pueda omitir la parte de configuración del entorno que requiere mucho tiempo y comenzar directamente a experimentar el análisis y la conversión de datos .
Configuración del entorno
Además de lakeFS, el entorno utilizado esta vez también incluirá MinIO como servicio de almacenamiento de objetos subyacente, así como herramientas de ciencia de datos de uso común como Jupyter y Spark. Puede consultar este repositorio de git para obtener más información.
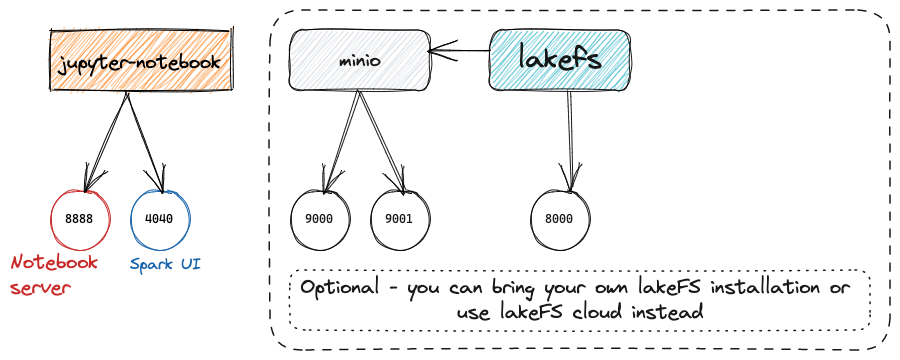
La imagen de arriba es un diagrama esquemático de este entorno experimental, tomado de treeverse/lakeFS-samples .
Repositorio de clones
git clone https://github.com/treeverse/lakeFS-samples.git
cd lakeFS-samples
Inicie el entorno experimental de pila completa
docker compose --profile local-lakefs up
Una vez que se inicia el entorno experimental, puede iniciar sesión en lakeFS y MinIO usando la configuración predeterminada para observar los cambios de datos en los pasos posteriores.
Observación de datos
Durante el proceso de configuración del entorno, se preparará de antemano un repositorio llamado inicio rápido en lakeFS. En este paso, haremos algunas observaciones simples al respecto.
Si utiliza su propio entorno LakeFS + MinIO implementado
- Es posible que primero deba crear manualmente el depósito correspondiente en MinIO.

- Luego cree el repositorio correspondiente en LakeFS y verifique para completar los datos de muestra.

lagoFS
Abra lakeFS ( http://127.0.0.1:8000) en el navegador , ingrese el ID de la clave de acceso y la clave de acceso secreta para iniciar sesión en lakeFS.
Luego abra el repositorio de inicio rápido, podrá ver que ya existen algunos datos predeterminados y también contiene un tutorial predeterminado.

El modo de repositorio de datos de lakeFS casi corresponde a repositorios de código como GitHub, y casi no hay costo de aprendizaje: entre ellos, están los lakes.parquetdatos preparados previamente, y dataen la carpeta lakes.source.mdse introduce la fuente de los datos; scriptsla carpeta contiene el El script, cuyo flujo de trabajo completo se puede _lakefs_actionsencontrar en el directorio, está escrito en un formato similar a GitHub Actions; README.mdcorresponde al archivo fuente de Markdown del tutorial siguiente y imagescontiene todas las imágenes utilizadas.
MiniIO
Dado que utilizamos MinIO como almacenamiento subyacente en el entorno experimental, también se puede encontrar un quickstartdepósito con nombre en MinIO. StorageNamespaceEsto lo determina lakeFS al crear el repositorio .
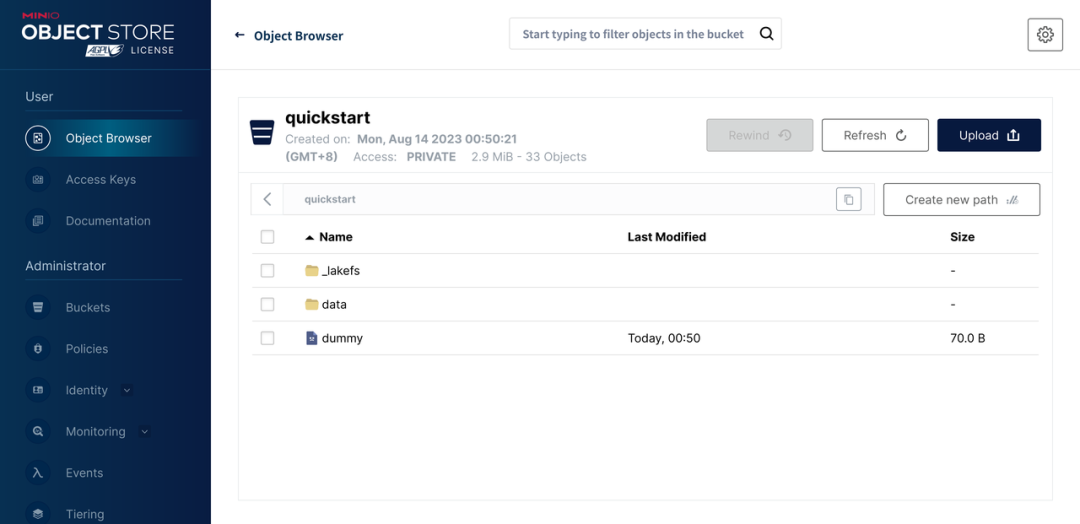
Entre ellos, dummyel archivo se crea al crear un nuevo repositorio de lakeFS para garantizar que tengamos permisos suficientes para escribir en el depósito.
El _lakefsdirectorio solo contiene dos archivos, creados al importar datos de fuentes de datos como S3, para identificar algunas referencias a la ubicación original de los archivos importados.
Los nuevos objetos escritos a través de lakeFS se ubicarán dataen el directorio.
Correspondencia de datos
Abra datael directorio, podemos encontrar algunos archivos, pero es difícil corresponder con los datos en lakeFS.
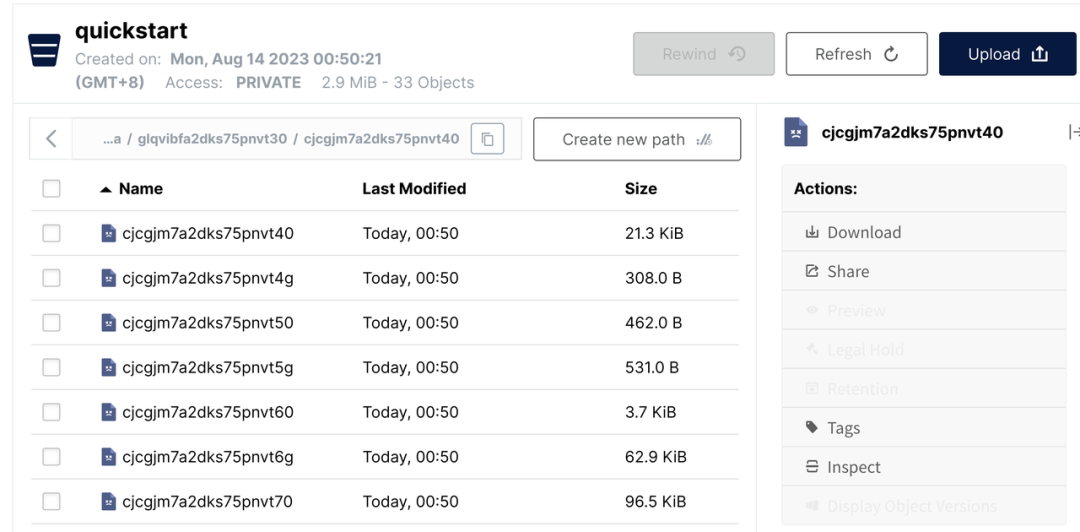
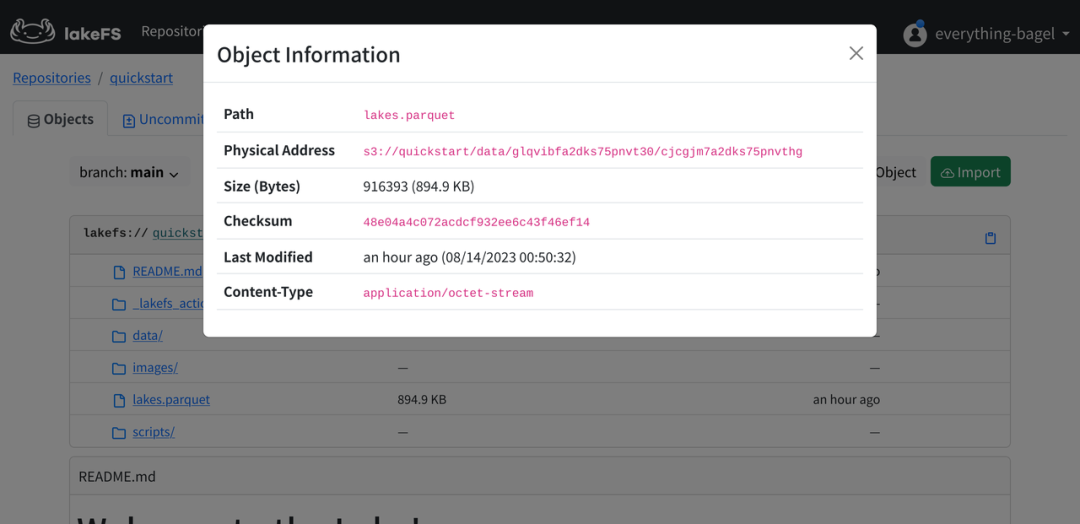
Volvamos a lakeFS, hagamos clic en el ícono de ajustes en el lado derecho del archivo y luego selecciónelo Object Infopara encontrar fácilmente la relación correspondiente.
Análisis y transformación de datos.
En este paso, implementaremos el servicio Databend, montaremos los datos en lakeFS a través de Stage y los analizaremos, y reemplazaremos los archivos de datos denmark-lakesen la rama con los resultados convertidos .lakes.parquet
Implementar Databend
El motor de almacenamiento de Databend también admite funciones avanzadas como viaje en el tiempo y reversión atómica, por lo que no hay necesidad de preocuparse por errores operativos.
Aquí utilizamos el servicio Databend de un solo nodo con MinIO como backend de almacenamiento. Para conocer el proceso de implementación general, puede consultarDocumentación oficial de DatabendAlgunos detalles que deben tenerse en cuenta son los siguientes:
-
Dado que implementamos el servicio MinIO en los pasos anteriores, solo necesitamos abrir y
127.0.0.1:9000crear undatabenddepósito llamado. -
A continuación, debe preparar directorios relevantes para registros y metadatos.
sudo mkdir /var/log/databend
sudo mkdir /var/lib/databend
sudo chown -R $USER /var/log/databend
sudo chown -R $USER /var/lib/databend
- En segundo lugar, debido a que el servicio predeterminado
http_handler_portha sido ocupado por el servicio anterior, es necesario editarlodatabend-query.tomly realizar algunos cambios para evitar conflictos:
http_handler_port = 8088
- Además, también necesitamos configurar el usuario administrador de acuerdo con Docs | Configuración de usuarios administradores . Como es solo un taller, aquí elegimos la forma más sencilla, simplemente cancelamos
[[query.users]]el campo y los comentarios del usuario root:
[[query.users]]
name = "root"
auth_type = "no_password"
- Dado que utilizamos MinIO como backend de almacenamiento, debemos
[storage]configurarlo.
[storage]
# fs | s3 | azblob | obs | oss
type = "s3"
# To use S3-compatible object storage, uncomment this block and set your values.
[storage.s3]
bucket = "databend"
endpoint_url = "http://127.0.0.1:9000"
access_key_id = "minioadmin"
secret_access_key = "minioadmin"
enable_virtual_host_style = false
A continuación, puede iniciar Databend normalmente:
./scripts/start.sh
Le recomendamos encarecidamente que utilice BendSQL como cliente. Debido http_handler_portal cambio de puerto, deberá utilizar bendsql -P 8088el servicio Databend para conectarse. Por supuesto, también admitimos múltiples formas de acceso, como MySQL Client y HTTP API.
crear una sucursal
El uso de lakeFS es similar al de GitHub: abra la página de ramas de la interfaz de usuario web , haga clic Create Branchen el botón y cree una denmark-lakesrama llamada.
Crear escenario
Databend puede montar el directorio de datos ubicado en el servicio de almacenamiento remoto a través de Stage. Dado que lakeFS proporciona la API de puerta de enlace de S3, podemos configurar la conexión de acuerdo con los servicios compatibles con s3. Cabe señalar que la URL aquí debe s3://<repo>/<branch>construirse de acuerdo con y ENDPOINT_URLel puerto de lakeFS es 8000.
CREATE STAGE lakefs_stage
URL='s3://quickstart/denmark-lakes/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');
Al ejecutar la siguiente declaración SQL, podemos filtrar los archivos de datos en formato Parquet en el directorio.
LIST @lakefs_stage PATTERN = '.*[.]parquet';

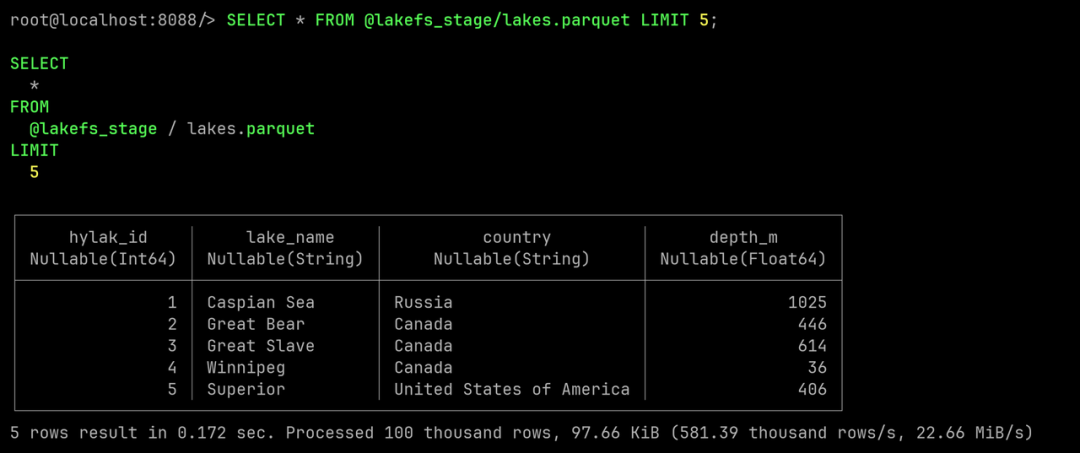
Dado que Databend ya admite la capacidad SELECT form Stage, se pueden realizar consultas básicas sin importar datos.
SELECT * FROM @lakefs_stage/lakes.parquet LIMIT 5;
Cree una tabla y ejecute algunas consultas simples.
Antes de limpiar los datos, importemos los datos a Databend y realicemos algunas consultas simples.
Gracias a la capacidad integrada de Infer Schema (estructura de datos inferidos) de Databend, las tablas se pueden crear fácilmente a partir de archivos.
CREATE TABLE lakes AS SELECT * FROM @lakefs_stage/lakes.parquet;

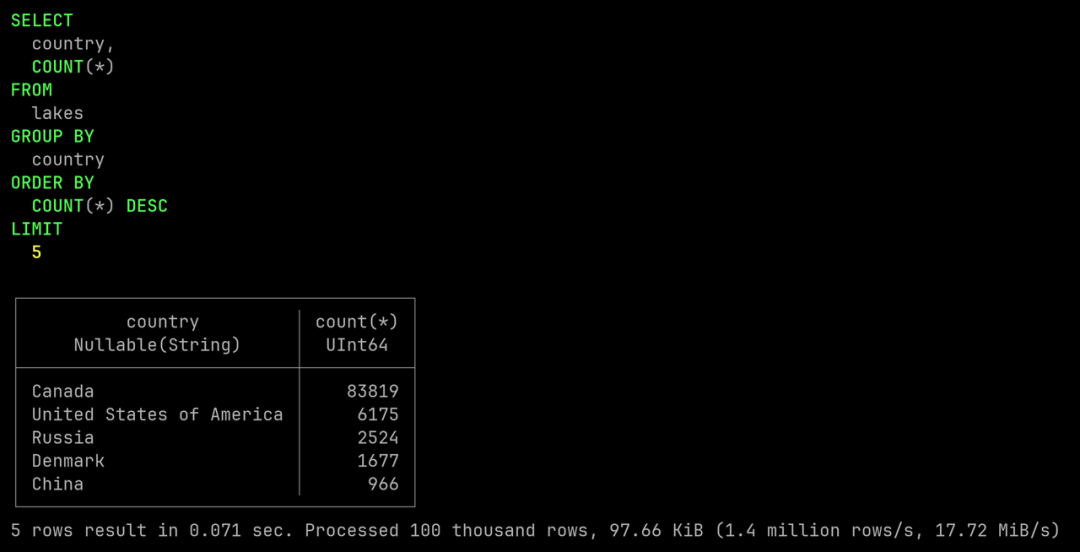
A continuación, enumeremos los 5 países con más lagos.
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
Limpieza de datos
El objetivo de esta limpieza de datos es construir un pequeño conjunto de datos de lagos, conservando únicamente los datos de los lagos daneses. Este objetivo se puede alcanzar fácilmente utilizando DELETE FROMla declaración.
DELETE FROM lakes WHERE Country != 'Denmark';

A continuación, consultemos nuevamente los datos del lago y verifiquemos si solo quedan lagos daneses.
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;

Utilice PRESIGN para escribir los resultados en lakeFS
denmark-lakesEn este paso, debemos reemplazar los archivos Parquet en la rama con los resultados limpios .
Primero, podemos usar COPY INTO <location>la sintaxis para exportar datos al escenario anónimo integrado.
COPY INTO @~ FROM lakes FILE_FORMAT = (TYPE = PARQUET);
A continuación, enumeremos @~los archivos de resultados en esta etapa.
LIST @~ PATTERN = '.*[.]parquet';

Al ejecutar PRESIGN DOWNLOADla declaración, podemos obtener la URL para descargar el archivo de datos resultante:
PRESIGN DOWNLOAD @~/<your-result-data-file>;

Abra una nueva terminal y use curlel comando para completar la descarga del archivo de datos.
curl -O '<your-presign-download-url>'
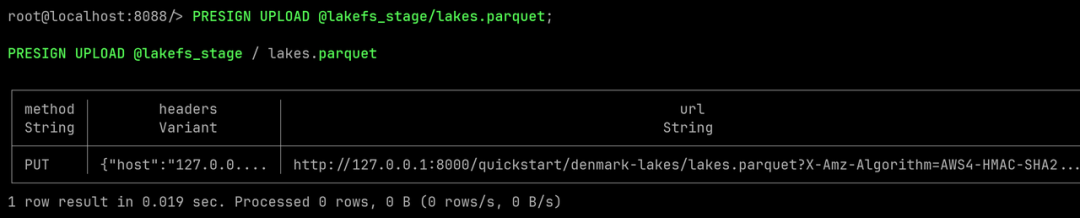
A continuación, utilizando PRESIGN UPLOADla declaración, podemos obtener la URL prefirmada para cargar el archivo de datos. El propósito de usarlo aquí @lakefs_stage/lakes.parquet;es lakes.parquetreemplazarlo con nuestros datos limpios del lago danés.
PRESIGN UPLOAD @lakefs_stage/lakes.parquet;
Abra la terminal y use curlel comando para completar la carga.
curl -X PUT -T <your-result-data-file> '<your-presign-upload-url>'
En este punto, el archivo ha sido reemplazado con los datos limpios. Enumere los archivos Parquet en el escenario nuevamente. Puede ver que el tamaño del archivo y la hora de la última modificación han cambiado.
LIST @lakefs_stage PATTERN = '.*[.]parquet';
Consulte el archivo de datos nuevamente para verificar que se trata de datos limpios.
SELECT country, COUNT(*)
FROM @lakefs_stage/lakes.parquet
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
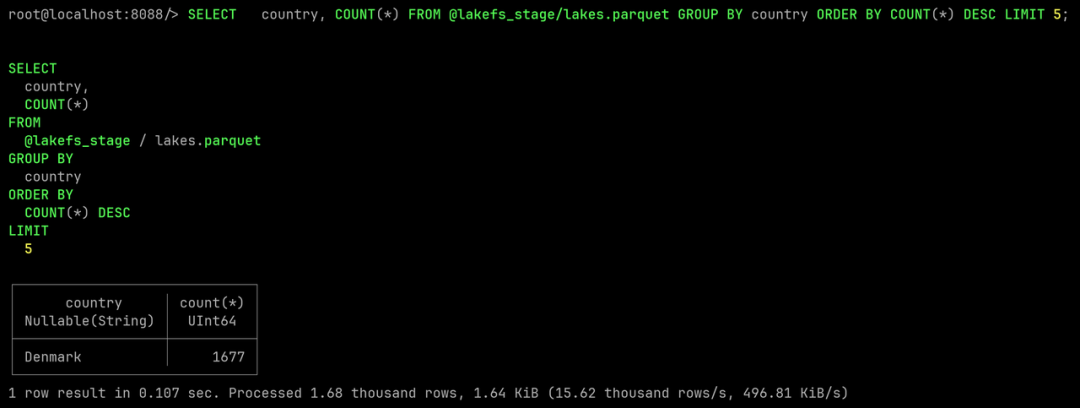
Cometer cambios
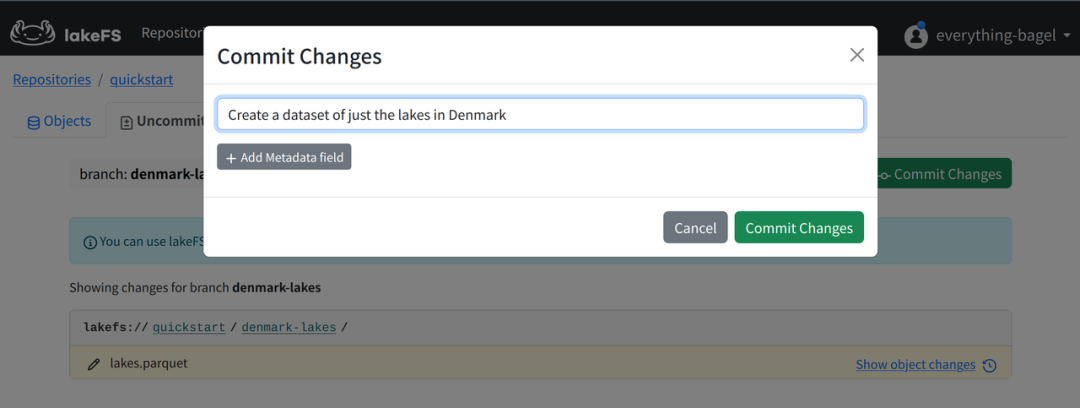
En este paso enviaremos los cambios a lakeFS para guardarlos.
En la interfaz de usuario web de lakeFS, abra la página Cambios no confirmados y asegúrese de que denmark-lakesla rama esté seleccionada.
Haga clic en el botón en la esquina superior derecha Commit Changes, escriba la información de envío y confirme el envío.
Verifique los datos originales en la rama maestra.
denmark-lakesLos datos originales han sido reemplazados con el conjunto de datos más pequeño limpio, volvamos a mainla rama y verifiquemos si los datos originales se han visto afectados.
De manera similar, monte los archivos de datos creando un escenario.
CREATE STAGE lakefs_stage_check
URL='s3://quickstart/main/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');
Luego consulte los datos del lago y enumere los cinco países con la mayor cantidad de lagos.
SELECT country, COUNT(*)
FROM @lakefs_stage_check/lakes.parquet
GROUP BY country
ORDER BY COUNT(*)
DESC LIMIT 5;
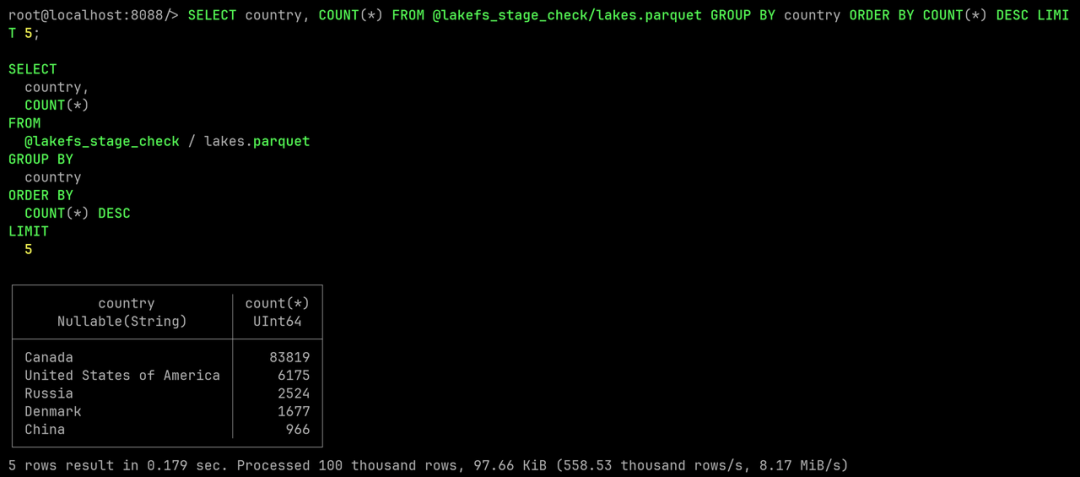
mainTodo en la rama permanece como está y obtenemos un conjunto de datos de lagos daneses limpios sin alterar los datos originales.
Desafío adicional
En este taller, aprendimos cómo crear ramas aisladas para datos y realizamos algunas consultas simples y trabajos de limpieza en Databend.
Si desea desafiar más, puede consultar el tutorial oficial de IakeFS para probar la fusión de ramas y las capacidades de reversión de datos; también puede consultar el tutorial oficial de Databend para experimentar la limpieza de datos y las capacidades de viaje en el tiempo en la etapa de importación de datos.
También damos la bienvenida a la introducción de Databend e IakeFS en entornos de producción para su validación en cargas de trabajo reales.
Acerca de Databend
Databend es un nuevo almacén de datos de código abierto, flexible y de bajo costo basado en el almacenamiento de objetos que también puede realizar análisis en tiempo real. Esperamos contar con su atención y explorar juntos soluciones de almacenamiento de datos nativas de la nube para crear una nueva generación de nube de datos de código abierto.
Nube de Databend: https://databend.cn
Documentación de Databend: https://databend.rs/
Wechat: Noche de citas
GitHub: https://github.com/datafuselabs/databend
Alibaba Cloud sufrió un grave fallo que afectó a todos los productos (ha sido restaurado). El sistema operativo ruso Aurora OS 5.0, una nueva interfaz de usuario, se presentó en Tumblr. Muchas empresas de Internet reclutaron urgentemente programadores de Hongmeng . .NET 8 es oficialmente GA, el último Versión LTS Tiempo UNIX A punto de ingresar a la era de los 1.7 mil millones (ya ingresó), Xiaomi anunció oficialmente que Xiaomi Vela es completamente de código abierto y el kernel subyacente es .NET 8 en NuttX Linux. El tamaño independiente se reduce en un 50%. FFmpeg 6.1 " Se lanza Heaviside". Microsoft lanza una nueva "aplicación para Windows"