
Fondo de tecnología observable.
A partir del primer artículo publicado por Google llamado "Dapper, una infraestructura de seguimiento de sistemas distribuidos a gran escala", más tarde evolucionó hacia tres direcciones principales: métricas (indicadores), seguimiento (seguimiento de enlaces) y registro (registro). Las soluciones observables complementarias son siendo gradualmente aceptados por la industria y convirtiéndose en estándares de facto.
Según la tecnología de solución observable de pila completa anterior, el diagnóstico de un problema ha pasado de no poder iniciarse o depender únicamente de registros a los siguientes pasos:
1. Descubra información anormal de la aplicación y determine módulos anormales a través de varias alarmas preestablecidas proporcionadas por Métricas/Registros
2. Consultar y analizar el módulo de excepción y los registros asociados (Registros) para encontrar la información principal del error.
3. Localice el fragmento de código que causa el problema a través de datos detallados de la cadena de llamadas (Seguimiento).
Con base en el conjunto de soluciones observables mencionado anteriormente, no sólo se pueden localizar rápidamente los problemas y reducir las pérdidas de manera oportuna después de que ocurren, sino que en muchos casos los problemas se pueden descubrir y reparar con anticipación antes de que ocurran fallas importantes.
Monitoreo de puntos ciegos
¿Se pueden resolver todos los problemas de monitoreo en línea de una vez por todas basándose en el conjunto de soluciones observables anterior? De hecho, este no es el caso, especialmente en términos de seguimiento, porque generalmente se basa en soluciones técnicas de Java Agent/SDK para recopilar datos de monitoreo de la cadena de llamadas de los principales marcos de desarrollo de software, como servicios HTTP, servicios RPC, bases de datos y mensajes distribuidos. MQ, etc., y luego, la lógica de procesamiento de restauración de datos de la cadena de llamadas posterior asocia la información de monitoreo con la solicitud específica, de modo que cuando ocurre una excepción en la solicitud, la información de llamada relevante se puede ver a través de los datos de monitoreo recopilados. Además de proporcionar el método de enlace principal por el que pasa una solicitud, la cadena de llamadas también tiene otra función principal: ayudar a identificar ubicaciones lentas y que consumen mucho tiempo en una cadena de llamadas y ayudar con la optimización del código. El proceso de solución de problemas específico se puede utilizar para diagnosticar la lógica de cuello de botella que requiere mucho tiempo en la cadena de llamadas a través de la información detallada de la cadena de llamadas, como se muestra en la siguiente figura:
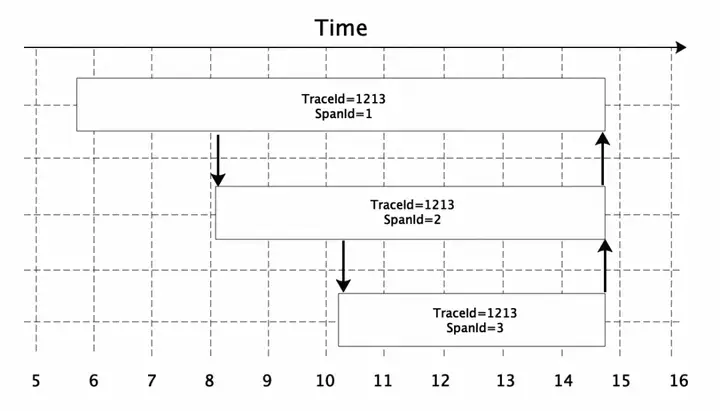
Como se muestra en la figura anterior, una cadena de llamadas sirve como Trace y tiene un TraceId único. El Trace contiene múltiples tramos, cada uno de los cuales representa la llamada a múltiples servicios posteriores, cada uno de los cuales tiene una información de SpanId correspondiente. A través de la figura anterior, puede conocer la situación que requiere mucho tiempo para múltiples servicios por los que pasa una solicitud (se supone que un servicio descendente corresponde a un Span, y algunos sistemas de seguimiento de enlaces pueden ser diferentes), lo que afecta el tiempo de la aplicación. -consumo Localice cuellos de botella y realice la optimización del rendimiento correspondiente.
Sin embargo, en el campo de los microservicios distribuidos, debido a la complejidad de los enlaces de llamada, que involucran máquinas cruzadas o incluso salas de máquinas cruzadas, debido a que el sistema de seguimiento general solo puede enterrar los métodos centrales en el marco principal de software de código abierto, cuando el La posición que requiere mucho tiempo aparece en Falta el punto enterrado de rastreo. Cuando se utiliza la lógica empresarial del usuario, habrá un período prolongado de tiempo en la cadena de llamada final que no puede corresponder al método de ejecución de código específico, lo que resulta en la incapacidad de juzgar con precisión el La lógica empresarial requiere mucho tiempo.
El caso específico se puede ver en el siguiente código:
public String demo() throws SQLException {
// 此处耗时1000ms,模拟其他业务耗时逻辑
take1000ms(1000);
// SQL 查询执行操作
stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM table");
return "Hello ARMS!";
}
private void take1000ms(long time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}En la lógica del código anterior, las líneas 6 a 7 son lógica de ejecución relacionada con la conexión de la base de datos. Este tipo de lógica generalmente está cubierta por los sistemas de seguimiento convencionales. Sin embargo, el tiempo comercial específico del cliente en la línea 4 generalmente corresponde a los puntos de monitoreo faltantes. oculto, lo que hace que el consumo de tiempo finalmente se cuente en la demostración del método Spring Boot de la entrada de la capa anterior.
El formulario de visualización final correspondiente en la cadena de llamadas de seguimiento puede ser similar a la figura siguiente: a través de la cadena de llamadas de seguimiento, solo se incluyen el consumo de tiempo de la interfaz externa de la primera capa y el consumo de tiempo de la lógica de ejecución del marco de software conocido. En él se puede conocer, entre los cuales la parte sombreada en gris El código de lógica empresarial del usuario que no está cubierto por el sistema de seguimiento se utiliza como punto ciego de monitoreo. Se desconoce su tiempo real, lo que causa muchos obstáculos para la resolución de problemas en línea. problemas de rendimiento:
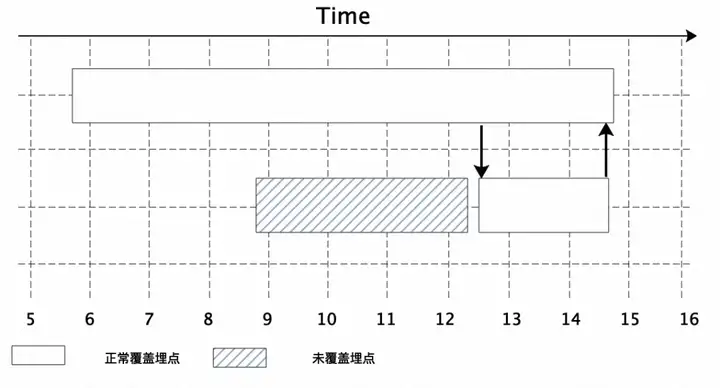
Los problemas anteriores son muy comunes entre los usuarios empresariales y muchas veces solo pueden suspirar y sentirse impotentes.
solución
Con respecto al problema de diagnóstico de las cadenas de llamadas lentas que requieren mucho tiempo cuando el sistema de rastreo carece de puntos enterrados, hasta donde sabe el autor, actualmente existen muy pocas soluciones relevantes en la industria. Los estudiantes familiarizados con Arthas pueden mencionar el comando de rastreo [1]. De hecho , hasta cierto punto, es posible verificar manualmente las ubicaciones específicas de las cadenas de llamadas lentas que consumen mucho tiempo en algunas escenas simples de cadenas de llamadas lentas que se pueden reproducir de manera estable. Pero sus limitaciones también son obvias:
- Alcance limitado
Solo admite el diagnóstico de llamadas lentas en escenarios reproducibles estables y es difícil solucionar problemas de llamadas lentas en escenarios que son difíciles de reproducir, como recolección de basura, contención de recursos y problemas de red.
- Umbral alto de uso
En escenarios de producción reales, la cadena de llamadas puede ser muy compleja. Si debe estar muy familiarizado con el código comercial, puede ejecutar manualmente el comando de seguimiento en un método comercial específico para monitorear el tiempo de solicitud. Si no está familiarizado con el método comercial ejecución o Es difícil utilizar esta herramienta para solucionar algunos escenarios complejos de llamadas asincrónicas.
- Alto costo de la investigación.
De hecho, esta herramienta se puede utilizar para solucionar problemas de llamadas lentas en escenarios comerciales simples de un solo salto, pero en escenarios comerciales complejos de múltiples saltos entre aplicaciones, el proceso de solución de problemas será muy problemático. No solo necesita usar algunas herramientas APM para ubicar la instancia de la aplicación donde se encuentra la llamada lenta específica, sino que también en escenarios donde la pila de métodos de llamada comercial es muy profunda, debe ejecutar comandos relevantes capa por capa y monitorear paso a paso. paso para encontrar la fuente del problema.
En resumen, el comando de seguimiento de Arthas se puede utilizar en algunos escenarios simples de llamadas lentas, ¡pero es insuficiente para solucionar problemas de la cadena de llamadas lentas en escenarios complejos!
Con este fin, el equipo de Alibaba Cloud ARMS y el equipo de Alibaba Dragonwell pueden ayudar a los usuarios a restaurar mejor la información de la pila de métodos de la cadena de llamadas a través de tecnología de análisis continuo para resolver mejor este tipo de problema de punto ciego de monitoreo de rastreo.
Capacidades de análisis continuo de ARMS
Como herramienta APM muy conocida en China, ARMS no solo proporciona soluciones observables convencionales para negocios relacionados con rastreo, métricas y registro, sino que también proporciona soluciones listas para usar de creación de perfiles continuos (Continuous Profiling, CP). La creación de perfiles continuos ayuda a monitorear y localizar cuellos de botella en el rendimiento de las aplicaciones al recopilar dinámicamente información de la pila de aplicaciones como CPU/memoria y otros recursos en tiempo real. La arquitectura de las capacidades de análisis continuo proporcionadas actualmente por ARMS se muestra en la siguiente figura:

En el lado del cliente, la tecnología Java Agent proporciona de forma no invasiva capacidades de análisis continuo y recopilación de datos sobre la base de otras capacidades observables. Luego, los datos recopilados se analizan y procesan en el lado del servidor y, finalmente, la consola proporciona a los usuarios funciones listas para usar que incluyen: diagnóstico de CPU, diagnóstico de memoria y funciones de punto de acceso de código.
Diagnóstico de CPU y memoria
Los gráficos de llamas ciertamente son familiares para muchos lectores que han solucionado problemas de rendimiento de aplicaciones. Al observar si hay una parte superior ancha en el gráfico de llamas, se pueden localizar problemas de rendimiento de las aplicaciones. Para muchos desarrolladores, el gráfico de llama mencionado anteriormente generalmente se refiere al gráfico de llama del punto de acceso de la CPU. Representa la situación que requiere mucho tiempo de los métodos ejecutados por la CPU en la aplicación dentro de un período de tiempo. La función de diagnóstico de CPU y memoria proporcionada por ARMS se basa en el análisis continuo de código abierto Async Profiler [2], que admite la recopilación normal de información de pila de métodos de aplicación de CPU y memoria de aplicaciones en condiciones de baja sobrecarga y admite un monitoreo normal simple y eficiente. del escenario de producción CPU y memoria de la aplicación Estado de la aplicación, despídase de la situación en la que es difícil abrir la aplicación con regularidad utilizando herramientas de código abierto y es fácil pasar por alto los escenarios problemáticos que no son fáciles de reproducir.

Puntos de acceso de código
Después de hablar sobre el diagnóstico de CPU y memoria, algunos lectores pueden preguntar: ¿podemos utilizar el método gráfico de llama de pila correspondiente al diagnóstico de CPU para ayudar a resolver el problema de rastrear los puntos ciegos de monitoreo del sistema y ayudar a solucionar problemas de cadenas de llamadas lentas? ¡la respuesta es negativa! Porque el diagnóstico de la CPU consiste en capturar periódicamente la información de la pila de métodos del subproceso de ejecución ejecutado en la CPU y luego convertirla en un gráfico de llama.
Además del estado En ejecución (también llamado En CPU) ejecutado en la CPU, el estado del hilo en el programa de software también tiene otros estados como Bloqueado y En espera (llamados colectivamente Fuera de CPU), y una cadena de llamadas lentas a menudo tiene múltiples estados del hilo La superposición hace que la presentación final demore mucho tiempo. Por lo tanto, el gráfico de llama de la CPU tiene un efecto limitado en escenarios de cadena de llamadas lentas.
Entonces, ¿existe una tecnología de gráficos de llama que no solo pueda describir contenido dentro de la CPU, sino también incluir contenido fuera de la CPU? Luego tenemos que mencionar el gráfico de llamas del reloj de pared (Wallclock). El principio de implementación no es complicado: consiste en seleccionar un grupo de subprocesos entre todos los subprocesos de la aplicación con una frecuencia fija para recopilar la información de la pila de métodos en el momento actual y dibujar el gráfico de llama correspondiente mediante el procesamiento de agregación. Async Profiler también proporciona capacidades relacionadas.
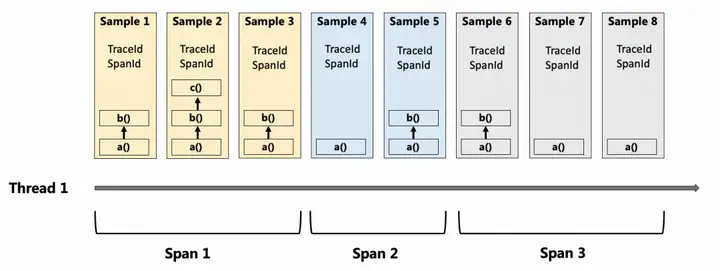
El punto de acceso de código principal de este artículo se basa en la capacidad de reloj de pared del Async Profiler de código abierto. Al correlacionar la información TraceId y SpanId en la cadena de llamadas, proporciona un gráfico de llama de encendido y apagado de la CPU en el nivel de la cadena de llamadas, que Puede monitorear eficazmente los detalles de los puntos ciegos de Tracing, restaurar y ayudar a los usuarios a diagnosticar varios problemas comunes de la cadena de llamadas lentas. El proceso específico es como se muestra en la siguiente figura: Al realizar la asociación o cancelación de información TraceId y SpanId al principio y al final del Span de creación del hilo, la instantánea de pila del método de reloj de pared generada final contiene información relevante y luego a través de la secuencia final continua. análisis de datos Procese, analice y restaure el gráfico de llamas del reloj de pared relacionado con la cadena de llamadas correspondiente para ayudar a localizar el problema de la cadena de llamadas lenta:
Características principales
Las capacidades de análisis continuo proporcionadas actualmente por ARMS tienen las siguientes características en comparación con otras herramientas de diagnóstico de cadena de llamadas lentas o herramientas de análisis continuo de código abierto:
- gastos indirectos bajos
A través de medidas como el muestreo automático basado en el proceso Trace y el análisis del reloj de pared basado en tasas de muestreo asociadas, la capacidad actual del producto de análisis continuo proporcionada por ARMS tiene una sobrecarga de CPU del 5 % y una sobrecarga de memoria fuera del montón de aproximadamente 50 M. La sobrecarga adicional no es obvia y se puede usar normalmente en el entorno de producción.
- granularidad fina
Además de los puntos de acceso de memoria y CPU a nivel de aplicación, también proporciona información de pila de métodos para el nivel de cadena de llamadas al correlacionar la información TraceId y SpanId, lo que puede ayudar de manera efectiva a diagnosticar problemas de cadena de llamadas lentas.
- Seguro, confiable, simple y eficiente
Algunas tecnologías de creación de perfiles continuos de código abierto, como el uso de Arthas para generar gráficos de llama de CPU (la capa inferior también depende de Async Profiler), generalmente se activan y desactivan después de su uso, por lo que incluso si existen riesgos técnicos, no son fáciles de encontrar. . Durante el proceso de desarrollo del producto, todavía descubrimos muchos problemas de riesgo en el uso de tecnologías de código abierto como Async Profiler en el proceso de creación de perfiles continuo. Por ejemplo, la creación de perfiles de memoria puede causar el bloqueo de la aplicación #694 [3] , el gráfico de llamas del reloj de pared puede causar que los subprocesos se bloqueen durante mucho tiempo #769 [4] , etc. Al solucionar estos problemas, las capacidades de nuestros productos serán más seguras y confiables. Además de la seguridad, la capacidad de análisis continuo proporcionada por ARMS guarda automáticamente los datos durante 7 días después de activarse normalmente, para que los usuarios no pierdan el sitio de diagnóstico de cada cadena de llamadas lentas.
Utilice puntos de acceso de código para solucionar problemas de cadenas de llamadas lentas
Activar puntos de acceso de código
1. Inicie sesión en la consola ARMS y seleccione Monitoreo de aplicaciones > Lista de aplicaciones en la barra de navegación izquierda.
2. Seleccione la región de destino en la parte superior de la página de la lista de aplicaciones y luego haga clic en el nombre de la aplicación de destino.
3. Haga clic en Configuración de la aplicación en la barra de navegación izquierda y luego haga clic en la pestaña Configuración personalizada .
4. Después de encender el interruptor maestro del punto de acceso de memoria y CPU , encienda el interruptor del punto de acceso del código y configure la dirección IP de la instancia de la aplicación que se habilitará o la dirección del segmento de red al que pertenece un grupo de instancias.
5. Haga clic en Guardar en la parte inferior de la página .
Ver datos del punto de acceso del código a través de llamadas de interfaz
1. Inicie sesión en la consola ARMS y seleccione Monitoreo de aplicaciones > Lista de aplicaciones en la barra de navegación izquierda.
2. Seleccione la región de destino en la parte superior de la página de la lista de aplicaciones y luego haga clic en el nombre de la aplicación de destino.
3. Haga clic en Llamada de interfaz en la barra de navegación izquierda , seleccione la interfaz de destino en el lado derecho de la página y luego haga clic en la pestaña Consulta de cadena de llamadas .
4. Haga clic en el enlace TraceId de destino en la pestaña Consulta de cadena de llamadas .
5. Haga clic en el ícono de la lupa en la columna de detalles. Primero, puede hacer clic en la pestaña de la pila de métodos para ver la información de la pila de métodos que se muestra usando la herramienta de seguimiento. Puede ver que solo contiene lógica de ejecución relacionada con MariaDB, y su parte frontal No se registró el tiempo comercial.
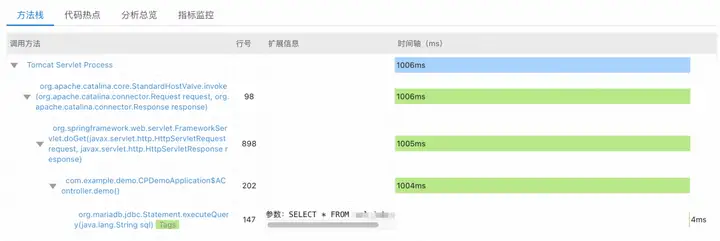
6. A continuación, haga clic en la pestaña Code Hotspots . Puede ver en el gráfico de llamas a la derecha que, además de la pila de métodos relacionados con MariaDB (correspondiente a la llama más a la derecha y más aguda en el gráfico de llamas en el lado derecho de la figura siguiente) También incluye java.El consumo de tiempo de 990 ms asociado con lang.Thread.sleep() (debido al análisis continuo para obtener la pila de métodos de subprocesos según el muestreo, puede haber algunas desviaciones).

El lado izquierdo de la figura es una lista que requiere mucho tiempo de todos los métodos involucrados en esta llamada, y el lado derecho es un gráfico de llama dibujado con toda la información de la pila de métodos del método correspondiente. Entre ellos, la columna Auto muestra el consumo de tiempo del método en sí. Para solucionar problemas de la lógica del código activo específico, puede ubicar los métodos comerciales que consumen mucho tiempo enfocándose en la columna Yo o mirando directamente las llamas más anchas en la parte inferior del gráfico de llamas a la derecha. El alto consumo de tiempo en la capa superior generalmente es un cuello de botella en el rendimiento del sistema, como el método java.lang.Thread.sleep () en la figura anterior. Para obtener más detalles de uso, consulte la documentación del usuario [5] relacionada con esta función .
Enlaces relacionados:
[1] comando de rastreo
https://arthas.aliyun.com/en/doc/trace.html
[2] Perfilador asíncrono
https://github.com/async-profiler/async-profiler
[3] #694
https://github.com/async-profiler/async-profiler/issues/694
[4] #769
https://github.com/async-profiler/async-profiler/issues/769
[5] Documentación de usuario
Autor: Cheng Pu, Yi Bo
Este artículo es contenido original de Alibaba Cloud y no puede reproducirse sin permiso.
Alibaba Cloud sufrió un grave fallo que afectó a todos los productos (ha sido restaurado). El sistema operativo ruso Aurora OS 5.0, una nueva interfaz de usuario, se presentó en Tumblr. Muchas empresas de Internet reclutaron urgentemente programadores de Hongmeng . .NET 8 es oficialmente GA, el último Versión LTS Tiempo UNIX A punto de ingresar a la era de los 1.7 mil millones (ya ingresó), Xiaomi anunció oficialmente que Xiaomi Vela es completamente de código abierto y el kernel subyacente es .NET 8 en NuttX Linux. El tamaño independiente se reduce en un 50%. FFmpeg 6.1 " Se lanza Heaviside". Microsoft lanza una nueva "aplicación para Windows"