Ancla DETR (AAAI 2022)
Mejorar:
- Consulta de objeto basada en anclaje propuesta
- Variante de atención propuesta-RCDA
En DETR anterior, la consulta de destino era un conjunto de incorporaciones que se podían aprender. Sin embargo, cada incrustación que se puede aprender no tiene un significado claro (porque se inicializa aleatoriamente), por lo que no hay explicación de dónde terminará concentrada. Además, dado que cada consulta de objeto no se centrará en un área específica , la optimización durante el entrenamiento también es difícil.

Notas sobre la visualización en DETR: (los espacios son una de 100 consultas)

Los tres patrones de predicción aquí pueden ser iguales o diferentes.
modelo sencillo
No hay cambios particularmente grandes con respecto a DETR
6 codificador, 6 decodificador, la esquina inferior derecha son puntos de anclaje
La incrustación de posición se agregará a q y k del decodificador.
consulta de objeto: [100,256] agrega un punto de anclaje, lo codifica en incrustación de posición, reemplaza el oq original
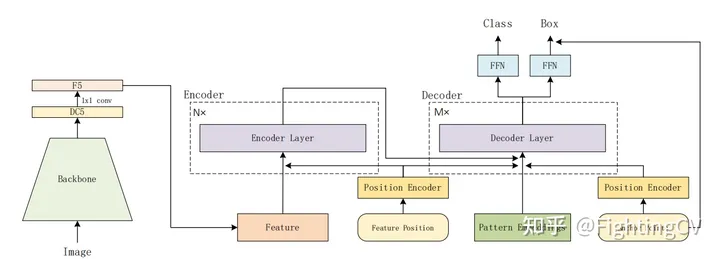
Hay dos formas de generar puntos de anclaje.
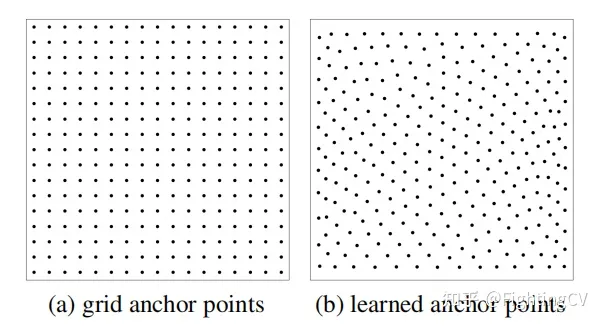
(a) El ancla es fija, el ancho y la altura están distribuidos uniformemente y el muestreo es uniforme.
(b) Primero inicialice aleatoriamente los puntos de un tensor con una distribución uniforme de 0-1 y utilícelo como parámetro de aprendizaje (incrustación), el efecto experimental es bueno.

Convertir punto de anclaje en consulta de objeto

Primero, obtenga los puntos de anclaje aprendidos de [100 (NA), 2] ;
Luego conviértalo en codificación de posición de alta frecuencia [100, 256] a través de sin/cos (la función en el código es pos2posemb2d);
Después de dos capas de aprendizaje MLP (adapt_pos2d en el código), se convierte a Q_P: [Np (patrón), 256].
Existen algunas diferencias entre el código y el artículo, como sigue:

Múltiples predicciones para cada punto de anclaje
Supongamos que hay 100 puntos de referencia y cada punto predice un objetivo. Una imagen real puede tener varios objetivos cerca del mismo punto.
Anchor Detr está diseñado para predecir múltiples modos (3 tipos) para un punto, y los modos Np se configuran para cada punto (Np=3)
Detr original, la consulta de objeto es [100,256] cada uno es [1,256]
Anchor detr agrega una incrustación de patrón, de la siguiente manera:
Q fi = Incrustación ( N p , C ) Q_{f}^{i}=\operatorname{Incrustación}\left(N_{p}, C\right)qFyo=incrustar( nortep,C )
Es decir, cada punto tiene Np (3) patrones, [3, 256]. En el artículo, Np = 300, patrón = 3, que son 900 puntos.
Al final, solo necesita agregar el Q_p del patrón incrustado y el punto de anclaje para obtener la consulta del objeto final. La consulta de Posición del patrón se puede expresar como:
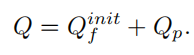
De hecho, la fórmula anterior no se utiliza en el código.
En el código del diagrama de código anterior, el punto de referencia se repite directamente de 300 a 900.
Por favor recuérdame si entiendo algo mal.
El patrón de código es la entrada del primer decodificador y los tgt del detr original son todos 0

Atención desacoplada fila-columna
¡Lo que se reduce es la sobrecarga de memoria! ! ! !
El mecanismo de atención de descomposición fila-columna acelera la convergencia y la longitud q es 900, lo que reduce la memoria y la sobrecarga de memoria.

El token de entrada del transformador original (H*W) se aplanará en una entrada unidimensional
Ax (W), calculado primero en la dimensión de la fila
Ay (H), realizando la operación Ay
Ay y Z realizan una suma ponderada en la dimensión de altura.
QK realiza descomposición en filas y columnas, V no se descompone [Nq, H*W]
Atención original: Nq * H * W * M (cabeza)
RCDA:
Hacha:Nq * W * M
Es: Nq*H*M
Solo necesita comparar los tamaños de las dos matrices. El lado derecho de la figura es la fórmula de proporción. Después de comparar las dos dimensiones, queda W * M/C. Se supone que W es 32 (DC5), M=8 , C = 256. Eso es lo mismo, mira C y W*M.
DC5 significa que se agrega una convolución de agujero a la última etapa de la red troncal (resnet50 predeterminada) y se reduce una capa de agrupación para duplicar la resolución.
experimento
1. Comparación de la memoria y AP de diferentes atenciones lineales
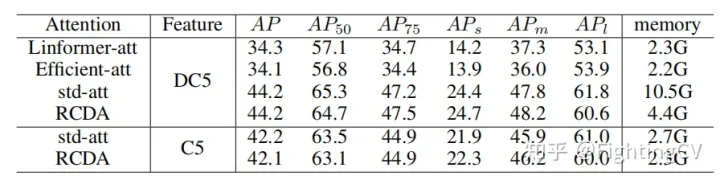
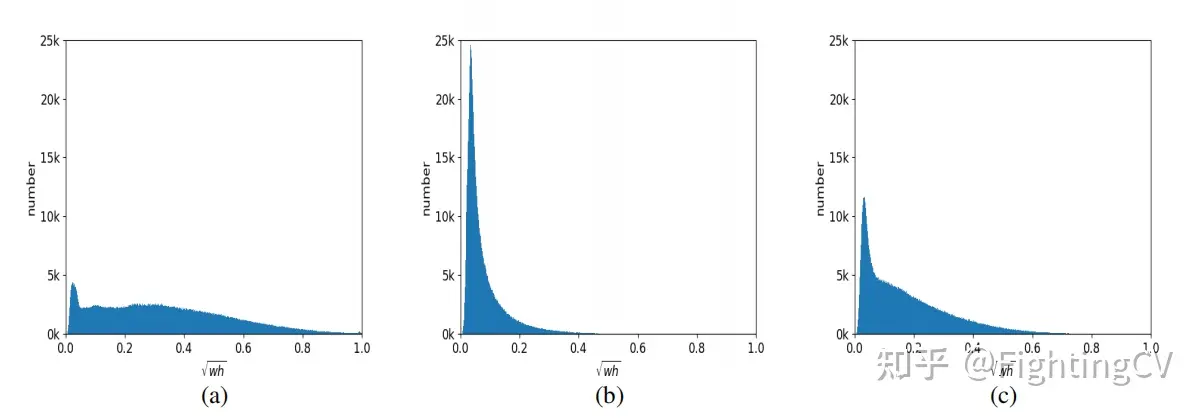
2. El modo a suele ser para objetos grandes, el modo b es para objetos pequeños y el modo c es más equilibrado.
referencia
https://www.bilibili.com/video/BV148411M7ev/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d