1. Introducción: ¿ChatGPT realmente creó una mente?
La última conclusión de la investigación de la Universidad de Stanford causó sensación en el círculo académico tan pronto como se publicó: "La Teoría de la Mente (ToM), que originalmente se pensaba que era exclusiva de los humanos, ha aparecido en el modelo de IA detrás de ChatGPT". La llamada teoría de la mente es la capacidad de comprender los estados mentales de los demás o de uno mismo, incluyendo la empatía, las emociones, las intenciones, etc. En este estudio, el autor descubrió que la versión davinci-002 de GPT3 ya puede resolver el 70% de las tareas de teoría de la mente, lo que equivale a un niño de 7 años.

.En 2023, ante las abrumadoras aplicaciones de IA, los humanos finalmente nos dimos cuenta de que algo había cambiado para siempre. Pero entre esta ola de locura por la IA, sólo una aplicación da realmente miedo: ChatGPT. Dado que la mente no se puede juzgar cuantitativamente, ChatGPT cumple con la definición de inteligencia, como razonamiento, planificación, resolución de problemas, pensamiento abstracto, comprensión de ideas complejas y aprendizaje rápido. Pero ChatGPT básicamente sólo hace una cosa: seguir escribiendo. Cuando damos las primeras N palabras, si un modelo puede decirnos cuál es probablemente la palabra "N+1", pensamos que el modelo ha dominado las leyes básicas del lenguaje.

¿Por qué se puede generar inteligencia simplemente "continuando escribiendo"? La siguiente es una respuesta tomada de Zhihu:
"¿Por qué una capacidad de conversación tan simple hace que ChatGPT parezca capaz de resolver una variedad de tareas? Porque la mayoría de nuestras tareas humanas se basan en el lenguaje. Cuando decimos algo antes, Si conectas las palabras, la tarea se completa Como modelo de lenguaje amplio, el propósito de ChatGPT es "conectar palabras", y conectar palabras puede ayudarnos a completar varias tareas de manera inconsciente". Esto también explica por qué ChatGPT a veces no tiene sentido, no mintió, no No sabía qué estaba bien o mal, sólo quería continuar la conversación sin problemas.
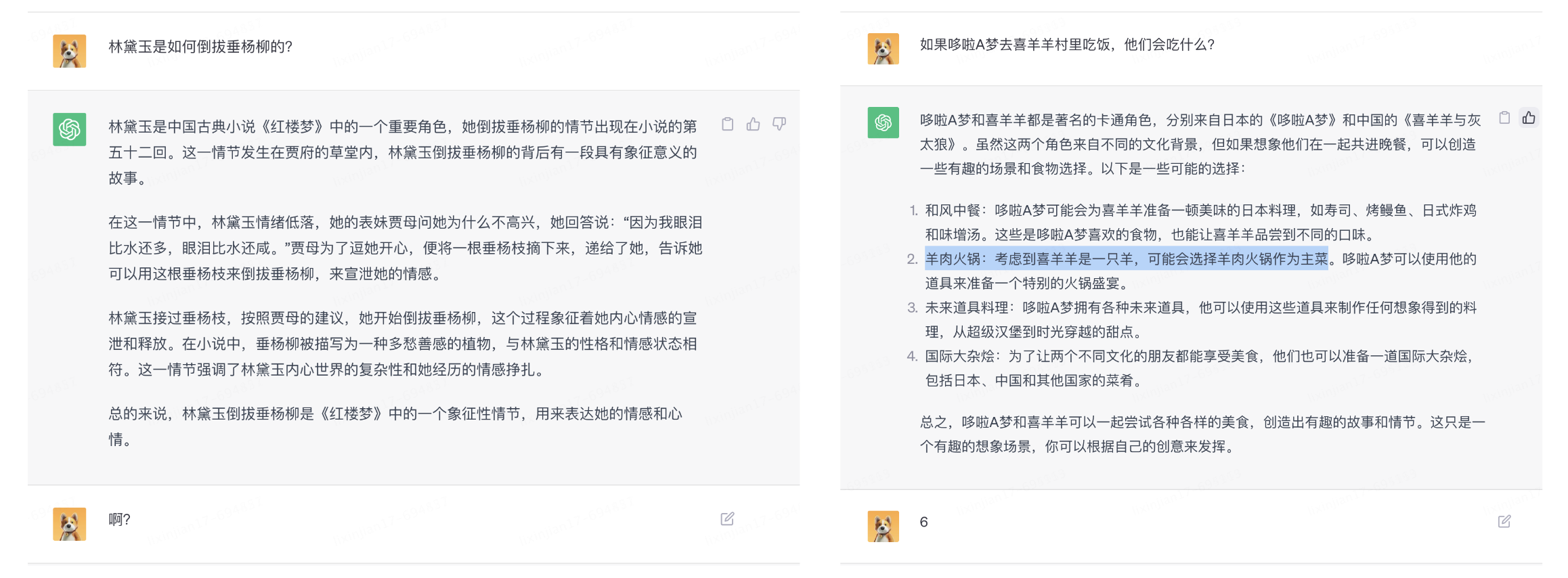
Si es cierto como se mencionó anteriormente, entonces GPT no parece ser tan mágico como imaginamos. Parece ser solo un modelo de lenguaje basado en big data y estadísticas. Predice la siguiente palabra con mayor probabilidad a través del texto masivo que contiene. aprende. Es como si hubiera una "base de datos" con gran capacidad y todas las respuestas se obtienen de esta base de datos.
Pero lo extraño es que ChatGPT puede responder preguntas que no ha estudiado. La más representativa es la suma de seis dígitos que no puede existir en el conjunto de entrenamiento. Obviamente es imposible predecir el siguiente número de mayor probabilidad por medios estadísticos. muchos.
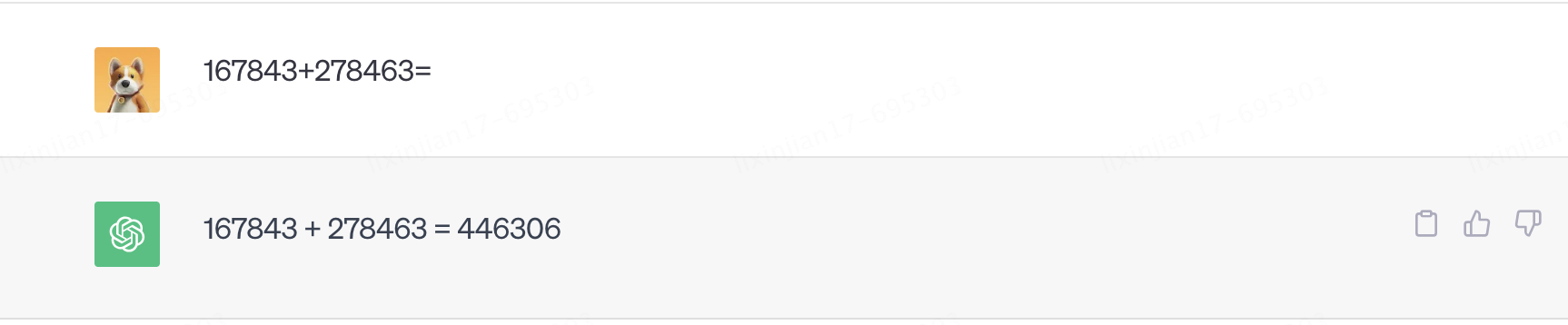
No solo eso, GPT también aprendió la capacidad de aprender ad hoc durante las conversaciones.
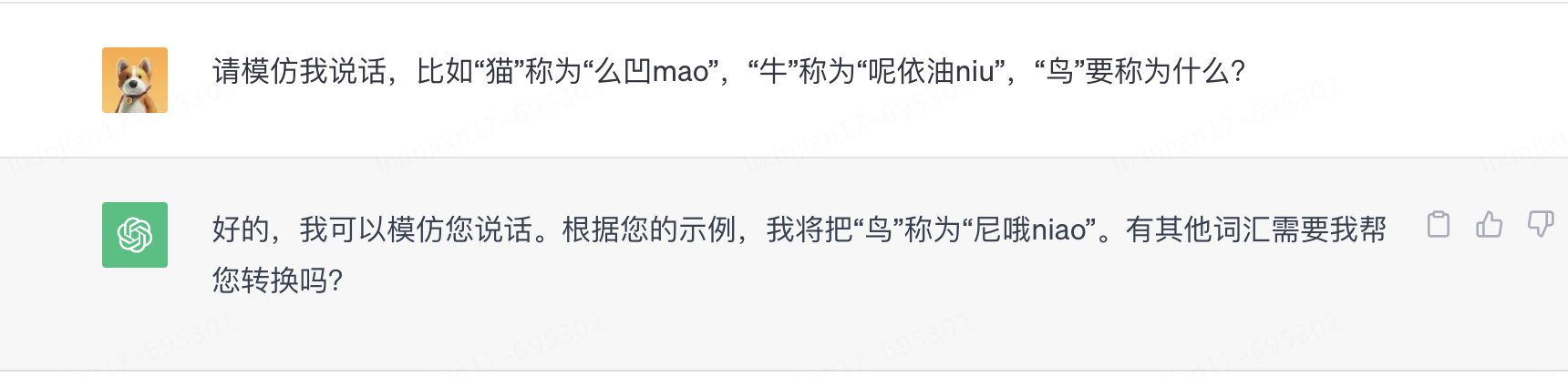
Parece que además de "seguir escribiendo", ChatGPT realmente ha desarrollado capacidades de razonamiento lógico. ¿Cómo surgen estas nuevas habilidades fuera de las estadísticas?
¿Cómo hacer que las máquinas comprendan el lenguaje y cómo hacer que el código almacene conocimiento? Este artículo es solo para responder una pregunta: ¿Cómo tiene mente un fragmento de código?
2. Todo lo que necesitas es atención: mecanismo de atención
Al buscar en todos los artículos sobre ChatGPT, descubrí que aparece una palabra con mucha frecuencia: Atención es todo lo que necesitas. Todo en ChatGPT se basa en el "mecanismo de atención". El nombre completo de GPT es Transformador generativo preentrenado, y este transformador es un modelo de aprendizaje profundo creado por el mecanismo de atención. Proviene de un artículo de 15 páginas de 2017, "La atención es todo lo que necesitas" [1]. Combinado con los dos artículos de OpenAI sobre GPT2 y GPT3 [2][3], podemos desmantelar este gran modelo de lenguaje y ver qué sucede exactamente cuando habla.
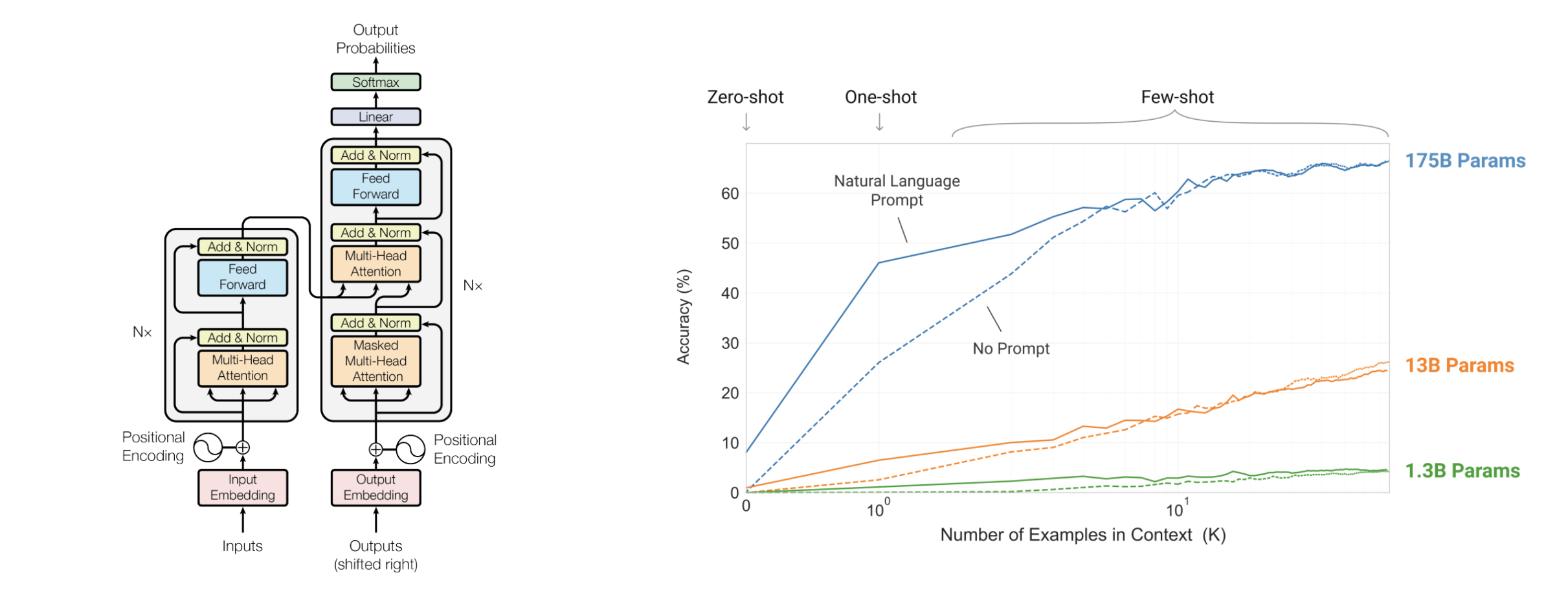
El nacimiento del mecanismo de atención proviene de la forma en que piensa el cerebro humano. Por ejemplo, al leer este párrafo, su atención continuará parpadeando de izquierda a derecha, palabra por palabra, y luego se concentrará en la oración completa. , comprender la relación entre estas palabras, y algunas de las palabras clave a las que también prestaremos más atención, todo esto sucede en un abrir y cerrar de ojos.
Los modelos de las series Transformer y GPT basados en el mecanismo de atención simulan este proceso de pensamiento al permitir que la máquina comprenda la relación y el significado entre las palabras en una oración, complete la continuación de la siguiente palabra, luego la comprenda nuevamente y luego continúe. una palabra y finalmente un párrafo. No es fácil conseguir un programa que imite esto. ¿Cómo dejar que la máquina calcule caracteres, cómo dejar que el código almacene conocimiento, por qué cuando se desmonta una unidad en el marco del modelo anterior, son todos círculos y líneas?
Entonces, el primer paso para estudiar la IA es descubrir qué puede hacer un círculo en la imagen de arriba.
2.1 Neuronas: círculos y líneas
Un montón de círculos y líneas también aparecieron en un artículo de 1957, "Perceptrón: un modelo probabilístico de almacenamiento y organización de información en el cerebro" [4]. Esta es la unidad básica de varios modelos de IA en la actualidad. También la llamamos red neuronal. Hace un siglo, los científicos conocían a grandes rasgos cómo funciona el cerebro humano: estos círculos simulan neuronas y las líneas son las sinapsis que conectan las neuronas y transmiten señales entre ellas.
Al conectar tres neuronas juntas, obtienes un interruptor que genera 1 cuando está activado o genera 0 cuando no está activado. Los interruptores pueden expresar si distinguir entre blanco y negro y marcar categorías similares, pero en última instancia son todos una cosa, clasificación. En las últimas décadas, lo que han hecho innumerables de las mentes más brillantes de la humanidad es conectar estos círculos de diversas maneras en un intento de generar inteligencia.
Este sitio web puede simular más problemas de división neuronal. Se puede ver que la situación que una neurona puede manejar es todavía demasiado limitada: puede separar dos datos obvios, pero los datos del círculo interior y del círculo exterior no se pueden separar. Pero si agrega una función de activación y agrega nuevas neuronas, cada nueva neurona puede agregar una o dos polilíneas en el límite, y más polilíneas pueden rodearla cada vez más como un círculo, y finalmente completar esta Clasificación.
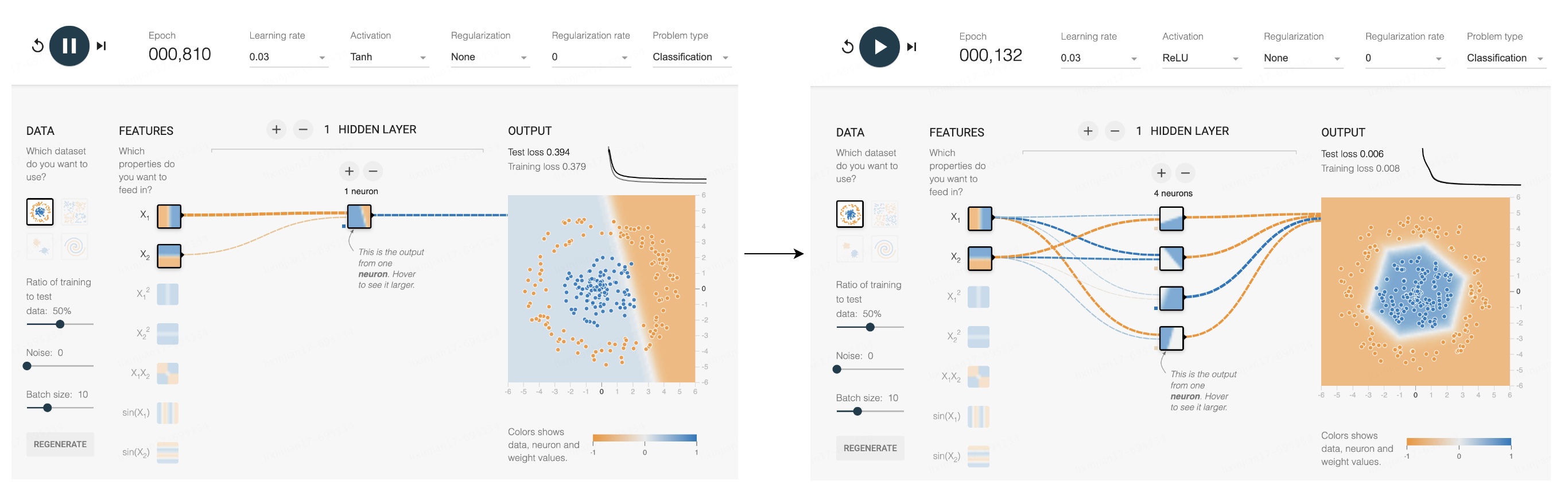
La clasificación puede resolver muchos problemas específicos. Si el eje X y el eje Y de cada punto en la figura anterior representan la edad y el peso de un cachorro respectivamente, entonces estos dos valores se pueden usar para distinguir dos razas diferentes. cuanta más información represente cada punto, más complejo se podrá resolver el problema. Por ejemplo, para una fotografía con 784 píxeles, se pueden utilizar 784 números para representar la clasificación, estos puntos pueden clasificar la imagen. Más líneas, más círculos, esencialmente todo para una mejor clasificación. Esta es la solución de entrenamiento de IA más común en la actualidad, aprendizaje profundo basado en redes neuronales.

Una vez que aprendas a clasificar, lograrás la creación hasta cierto punto.
Es por eso que tantos académicos de la industria se han dado cuenta de que la esencia del aprendizaje profundo son en realidad las estadísticas. A lo largo del camino de círculos y líneas, eventualmente llegarán al final y se convertirán en una herramienta que todos pueden usar. Y si desarmas el modelo de la serie GPT, solo quedarán expuestos estos círculos y líneas. Pero, ¿pueden realmente la clasificación y la estadística imitar el pensamiento humano? Antes de discutir, primero comprendamos los principios subyacentes del modismo Solitario.
2.2 Solitario idiomático
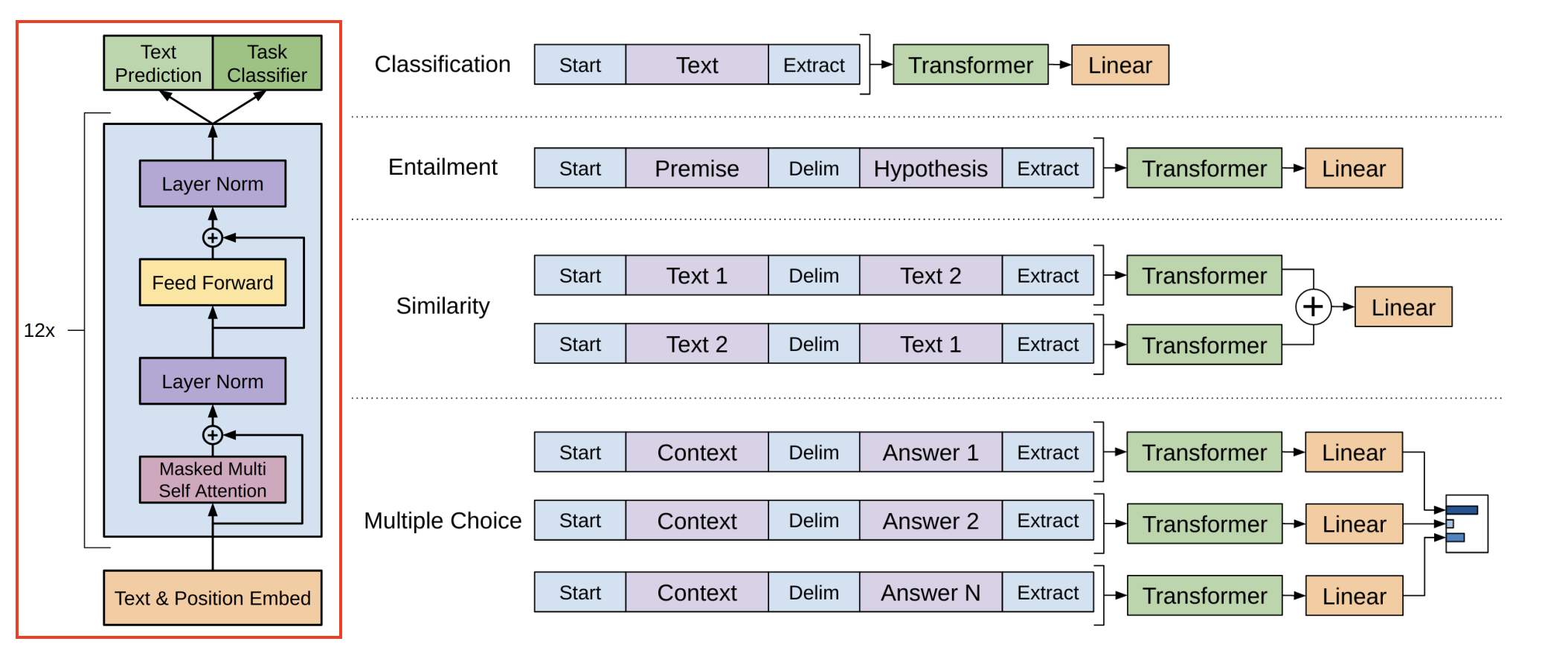
En el artículo original del GPT de primera generación de 2018 [5], podemos ver la estructura del modelo de la serie GPT. Recuerde el mecanismo de atención mencionado anteriormente. Esta capa se llama capa de codificación de atención. Su objetivo es imitar la atención humana y extraer el significado entre las expresiones. Al apilar 12 codificaciones de este tipo, el texto entrará a continuación y lo que salga será el siguiente. palabra predicha por GPT.
Por ejemplo, después de ingresar cómo estás, el modelo generará la siguiente palabra haciendo. ¿Por qué muestra haciendo? A continuación tenemos que descubrir qué pasó en el medio.
Después de ingresar cómo estás, estas tres palabras se convertirán en tres vectores de 1024 dimensiones, y luego a cada vector se le agregará una información de posición, indicando cómo es la primera palabra, dónde es la segunda palabra, y así sucesivamente. Después de eso, ingresarán a la primera capa de codificación de atención y, después del cálculo, se convertirán en tres vectores diferentes de longitud 1024. Luego pasarán a la segunda capa y a la tercera capa, y las 24 capas de codificación de atención las calcularán y procesarán. Todavía se obtienen tres vectores de 1024 de largo y el resultado de la continuación de la siguiente palabra está oculto en el último vector. Los cálculos clave ocurren en estas capas de codificación de atención, que se pueden dividir en dos estructuras: primero calcula la atención de múltiples cabezas y luego calcula la capa completamente conectada. La tarea de la capa de atención es extraer el significado entre las expresiones, mientras que la capa de enlace completo debe responder a estos significados y generar el conocimiento almacenado.
Primero podemos usar cómo como ejemplo. Hay tres parámetros centrales entrenados KQV en la capa de atención, que se utilizan para calcular la correlación entre palabras. Después de multiplicarlos con cada vector, podemos obtener la correlación entre cómo y son. luego calcule la correlación entre cómo y usted, y cómo y cómo de esta manera, puede obtener tres puntajes: cuanto mayor sea el puntaje, más importante es su correlación. Luego multiplica y suma las tres puntuaciones y la tres información válida para convertir how en un nuevo vector de cuadrícula 64. Luego haz la misma operación para are y you para obtener tres nuevos vectores.

Los KQV que participan en esta ronda de cálculo son fijos y hay 16 grupos diferentes de KQV en el modelo. Cada uno de ellos realizará una ronda de cálculo como este y obtendrá 16 grupos diferentes de resultados. Esto se llama atención de múltiples cabezas, que significa que para esta oración hay 16 interpretaciones diferentes de las palabras. Al juntarlos, se obtienen 1024 cuadrículas con la misma longitud que la entrada y luego se multiplican por una matriz de peso W para ingresar al cálculo de la capa de enlace completa.
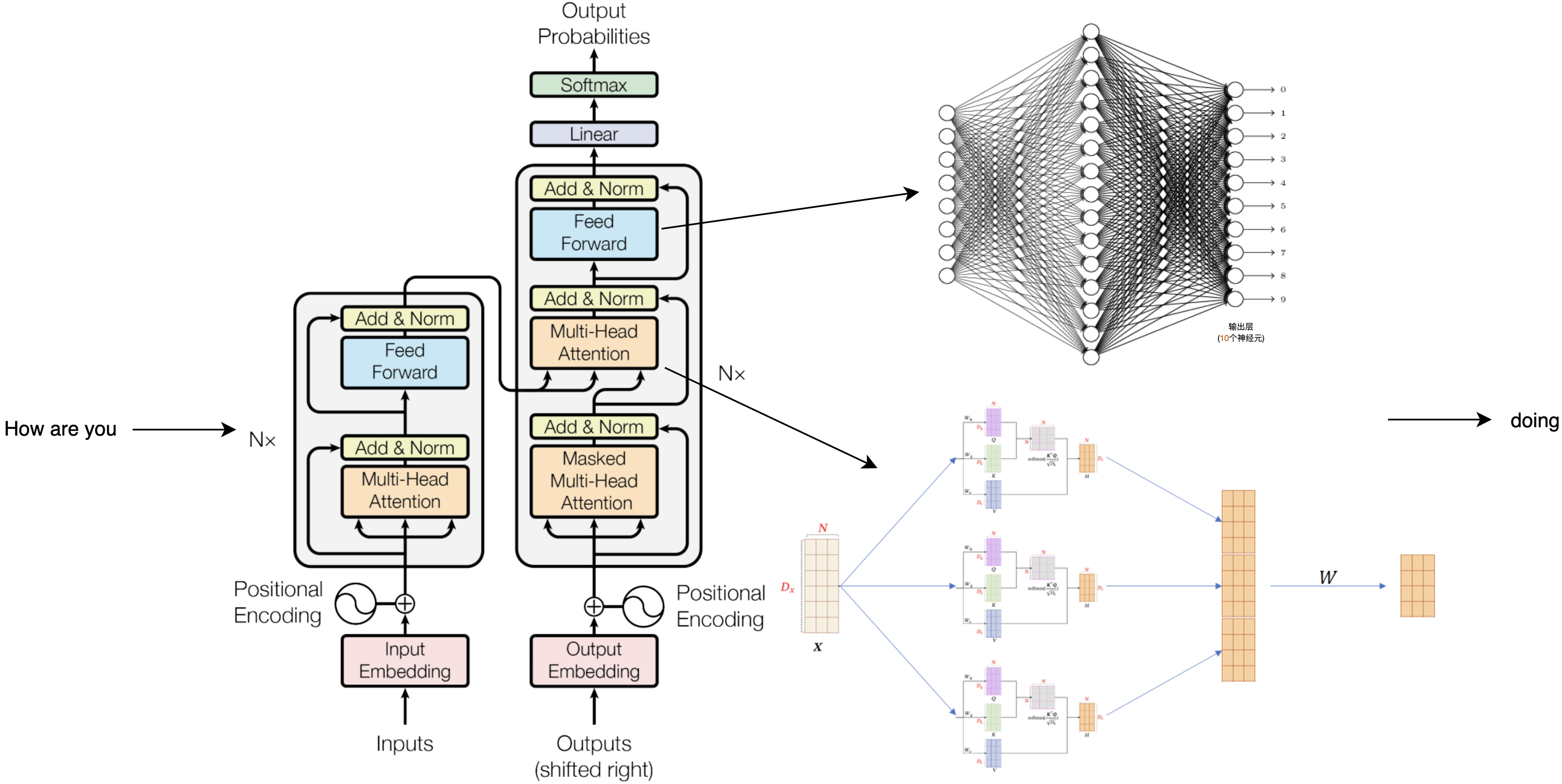
En la capa completamente conectada, hay 4096 neuronas familiares y todavía están haciendo trabajo de clasificación. El cálculo aquí es conectar el vector how convertido por la capa de atención a cada neurona aquí. Cada número en las 1024 cuadrículas se multiplica por el peso de la conexión a la primera neurona. Sumadas, estas neuronas generarán una puntuación de similitud. Al mismo tiempo, cada neurona realiza operaciones similares. La salida de solo unas pocas neuronas es mayor que cero, lo que significa que las neuronas son sensibles a esto. Si conecta los vectores correspondientes a los 1024 números de la cuadrícula, obtendrá un nuevo vector. Después de hacer cálculos similares, obtienen tres cadenas de cuadrícula de 1024 de largo con la misma longitud inicial. Esto es lo que sucede en la capa de codificación de atención. Cada capa posterior sigue el mismo proceso para realizar más cálculos sobre la base de la capa anterior. Incluso si cada capa solo aporta un poco de comprensión, después de calcular 24 capas, todavía hay mucha comprensión y finalmente se obtienen tres. , cada uno de 1024 de largo. La siguiente palabra que generará el modelo se basa en este último vector, que es el vector transformado por usted. Al restaurarlo de 1024 a un número de serie en el rango de 0-50256, podemos ver que este vector de número de serie es el valor más cercano en el vocabulario. En este punto, se puede decir que el modelo ha calculado la siguiente palabra después de cómo estás, que es lo más probable.
Queremos que el modelo continúe escribiendo, así que continuaremos haciendo esto después de cómo estás, lo convertiremos en cuatro vectores, luego lo ingresaremos en el modelo, repetiremos el proceso ahora y obtendremos la siguiente palabra. Uno a uno, un párrafo se hace cada vez más largo hasta que termina y se convierte en el párrafo que vemos: este es el secreto del solitario de texto. ChatGPT solo cambia este modelo de continuación a una interfaz de diálogo. Cada pregunta que hagas se convertirá en el punto de partida para una continuación como esta. Juntos, completaréis un solitario de texto.
2.3 Modelo de lenguaje “grande”
El proceso de cálculo de cada capa que acabo de mencionar es largo, lo cual en realidad está bien. Lo realmente aterrador de GPT es la gran cantidad de parámetros. El tamaño básico de GPT1 es 768. Cada capa tiene más de 7 millones de parámetros. La duodécima capa tiene 115 millones de parámetros. Ya era muy grande en 2018 cuando se lanzó. El tamaño básico del medio GPT que acabamos de abrir es 10241, con un total de 24 capas, cada capa tiene 12 millones de parámetros, que multiplicados son 350 millones de parámetros. En cuanto a la versión GPT3 utilizada por ChatGPT, su número de parámetros es 175 mil millones y el número de capas ha aumentado a 96. GPT4 no anunció su tamaño, algunos medios especularon que es seis veces más grande que GPT3, que es un billón de parámetros. Esto significa que incluso si la memoria de video de una tarjeta gráfica 3090 se aumenta cientos de veces para que pueda instalar el GPT4 de nivel inferior, responder una pregunta simple aún puede requerir 40 minutos de cálculo.
Cuando desmontes todo esto, descubrirás que no hay secretos asombrosos, sólo grandeza, el tipo de grandeza de las maravillas de la civilización, el tipo de grandeza que no tiene nada que decir. Esta es la verdad de la serie GPT, una "gran "modelo de lenguaje. Pero todavía no podemos responder por qué un modelo así puede producir inteligencia, y ahora ha surgido una nueva pregunta: ¿por qué el número de parámetros tiene que ser tan grande?
Primero resumamos la información conocida actualmente. Primero, la red neuronal solo puede hacer una cosa, la clasificación de datos. En segundo lugar, la capa de atención en el modelo GPT es responsable de extraer el significado del discurso, y luego a través de las neuronas del total. capa de enlace Genera el conocimiento almacenado En tercer lugar, cada palabra que dice GPT es ejecutar todas las palabras de la conversación a través del modelo y seleccionar la palabra con la mayor probabilidad de salida. Entonces, ¿de dónde viene el conocimiento que posee GPT? Podemos ver el conjunto de datos de preentrenamiento de ChatGPT en el documento de OpenAI. Son alrededor de 700 GB de texto sin formato de sitios web, libros, código fuente abierto y Wikipedia. Hay un total de 4991 tokens, lo que equivale a 860.000 Viaje al Oeste. . Su proceso de formación consiste en completar la continuación de estos textos masivos ajustando automáticamente cada parámetro del modelo.
En este proceso, el conocimiento se almacena en los parámetros de cada neurona, y luego sus cientos de miles de millones de parámetros y conocimiento almacenado ya no se actualizarán. Así que el ChatGPT que utilizamos es en realidad completamente estático, como un cadáver exquisito. La razón por la que parece recordar lo que acabamos de decir es porque cada vez que sale una nueva palabra, todas las palabras anteriores deben eliminarse. Sal y cuéntala de nuevo. , por lo que incluso lo que se escribe al principio puede afectar el resultado de seguir escribiendo cientos de palabras después. Pero esto también da como resultado que se limite el vocabulario total de cada ronda de diálogo de ChatGPT, por lo que GPT tiene que limitar el nivel de diálogo. Como un genio pez dorado con sólo siete segundos de memoria.
Ahora volvamos a la pregunta mencionada en el prefacio, ¿por qué ChatGPT puede responder preguntas que no existen en Internet y que él no ha estudiado, como una suma de seis dígitos que no puede existir en los datos de entrenamiento, que obviamente no se puede predecir estadísticamente? ¿Cuál es el número de probabilidad más alto y cómo surgen estas nuevas habilidades fuera de la estadística?
En mayo de este año, me inspiré en una nueva investigación de OpenAI, este artículo se llama "Modelo de lenguaje, puede explicar las neuronas en modelos de lenguaje" [6]. En pocas palabras, GPT4 se utiliza para explicar GPT2. Cuando se ingresa texto en GPT2, algunas neuronas en el modelo se activarán. La IA abierta permite que GPT4 observe este proceso, adivine la función de esta neurona, luego observe más texto y neuronas, y adivine más neuronas, para poder explicar el Función de cada neurona en GPT2, pero no sé si GPT4 puede adivinarla con precisión. El método de verificación consiste en permitir que GPT4 construya un modelo de simulación basado en estas conjeturas, imite la reacción de GPT2 después de ver el texto y luego compárelo con los resultados de GPT2 real. Cuanto mayor sea la tasa de coherencia de los resultados, más precisa será la suposición. la función de esta neurona. OpenAI registra los resultados de sus análisis para cada neurólogo en este sitio web .
Por ejemplo, si ingresamos 30, 28, podemos ver la situación de la neurona 28 en la capa 30. GPT4 cree que esta neurona se centra en un tiempo específico. A continuación se muestran varios ejemplos de pruebas. El verde significa que la neurona responde a la palabra. Cuanto más oscuro sea el verde, mayor será la respuesta. Se puede encontrar que incluso si la ortografía es completamente diferente, las neuronas en las capas intermedias de estos modelos ya pueden entender su significado según las palabras y el contexto.

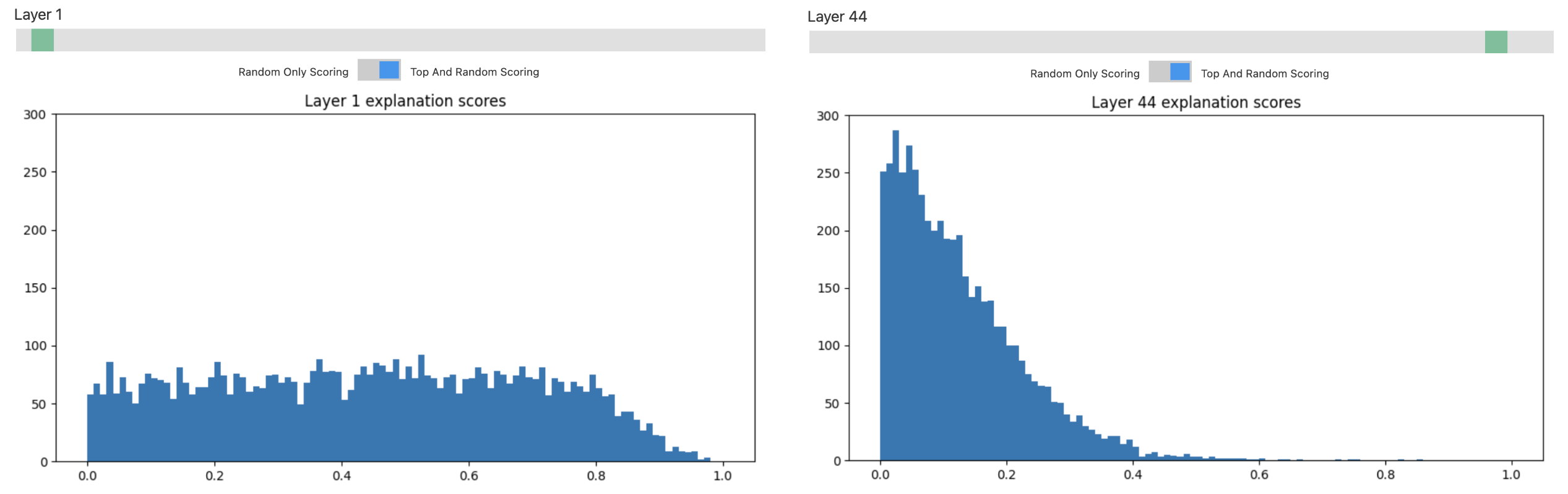
Pero OpenAI también descubrió que sólo aquellas neuronas con capas inferiores son fáciles de entender. La abscisa en este histograma es la precisión de la interpretación de las neuronas y la ordenada es el número de neuronas. Se puede ver que para las neuronas de las primeras capas, casi la mitad puede alcanzar una precisión superior a 0,4. Pero cuanto mayor es el número de capas, más neuronas tienen puntuaciones bajas y la mayoría de las neuronas todavía están en la niebla.
Porque la comprensión del lenguaje es inherentemente difícil de explicar, como esta conversación. Para aquellos de nosotros que somos hablantes nativos de chino, podemos entender rápidamente el significado de este pasaje, pero para una red neuronal, obviamente no es lo suficientemente significativo como para depender de unas pocas neuronas que responden al "significado".
A: "¿Qué quieres decir?" B: "No significa nada. No significa nada". A: "Eres realmente interesante". B: "En realidad, no significa nada más". A: " Entonces lo siento." B: "Lo siento".
GPT parece entender estos significados, ¿cómo lo hace?
2.4 Emergencia - emergencia
"La capacidad de reducir todo a simples leyes fundamentales no implica la capacidad de reconstruir el universo entero a partir de esas leyes." -Philip Anderson.
En 1972, el físico teórico Philip Anderson publicó un artículo titulado "Más es diferente" [7] en Science, sentando las bases para la ciencia compleja. Anderson creía: "El comportamiento de agregados complejos de un gran número de partículas elementales no puede entenderse mediante Una simple extrapolación de las propiedades de unas pocas partículas, en cambio, en cada nivel de complejidad surgen propiedades completamente nuevas, y creo que la investigación necesaria para comprender estos nuevos comportamientos está en la base de En términos de sexo, no es inferior a otros. ".
Mirando retrospectivamente la estructura del modelo del lenguaje, la información continúa fluyendo hacia arriba con la capa de codificación de la atención. Cuanto mayor es el número de capas de neuronas, más capaces son de prestar atención a conceptos abstractos complejos y metáforas indescriptibles. Este artículo llamado "Encontrar neuronas en pajares" [8] también encontró una situación similar: encontraron una neurona utilizada específicamente para determinar si el idioma es francés. Si esta neurona está bloqueada en un modelo pequeño, su capacidad para comprender el francés disminuirá inmediatamente, mientras que si está bloqueada en un modelo grande, puede haber poco efecto. Esto significa que a medida que el modelo crece, es probable que una neurona de función única se divida en múltiples neuronas adaptadas a diferentes situaciones, que ya no serán tan sencillas a la hora de juzgar un solo problema y, por tanto, se volverán más difíciles.
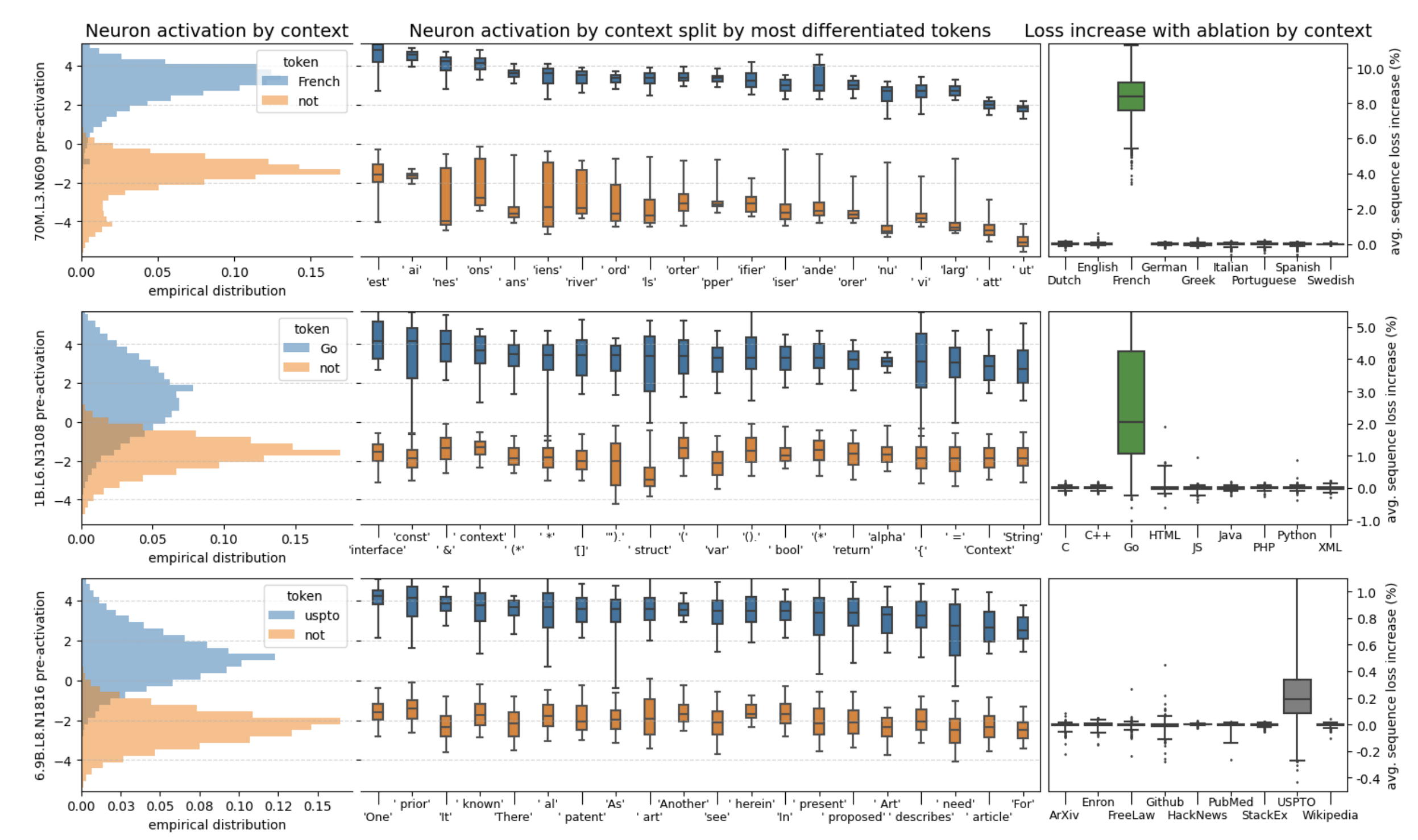
Es comprensible que esta sea la razón por la que OpenAI tiene que hacer el modelo tan grande: solo cuando sea lo suficientemente grande podrá ser lo suficientemente abstracto, y cuando alcance un cierto nivel, el modelo incluso comenzará a tener nuevas capacidades que nunca antes habían aparecido. .
En este artículo titulado "Capacidades emergentes de modelos de lenguaje grandes" [9], los investigadores completaron ocho pruebas de nuevas capacidades para estos modelos de lenguaje de diferentes tamaños. Se puede ver que no eran muy buenos hasta que crecieron, pero una vez que alcanzaron cierto punto crítico, de repente se volvieron buenos y comenzaron a convertirse en una línea recta que corría hacia arriba, como si tuvieran una epifanía en un momento.
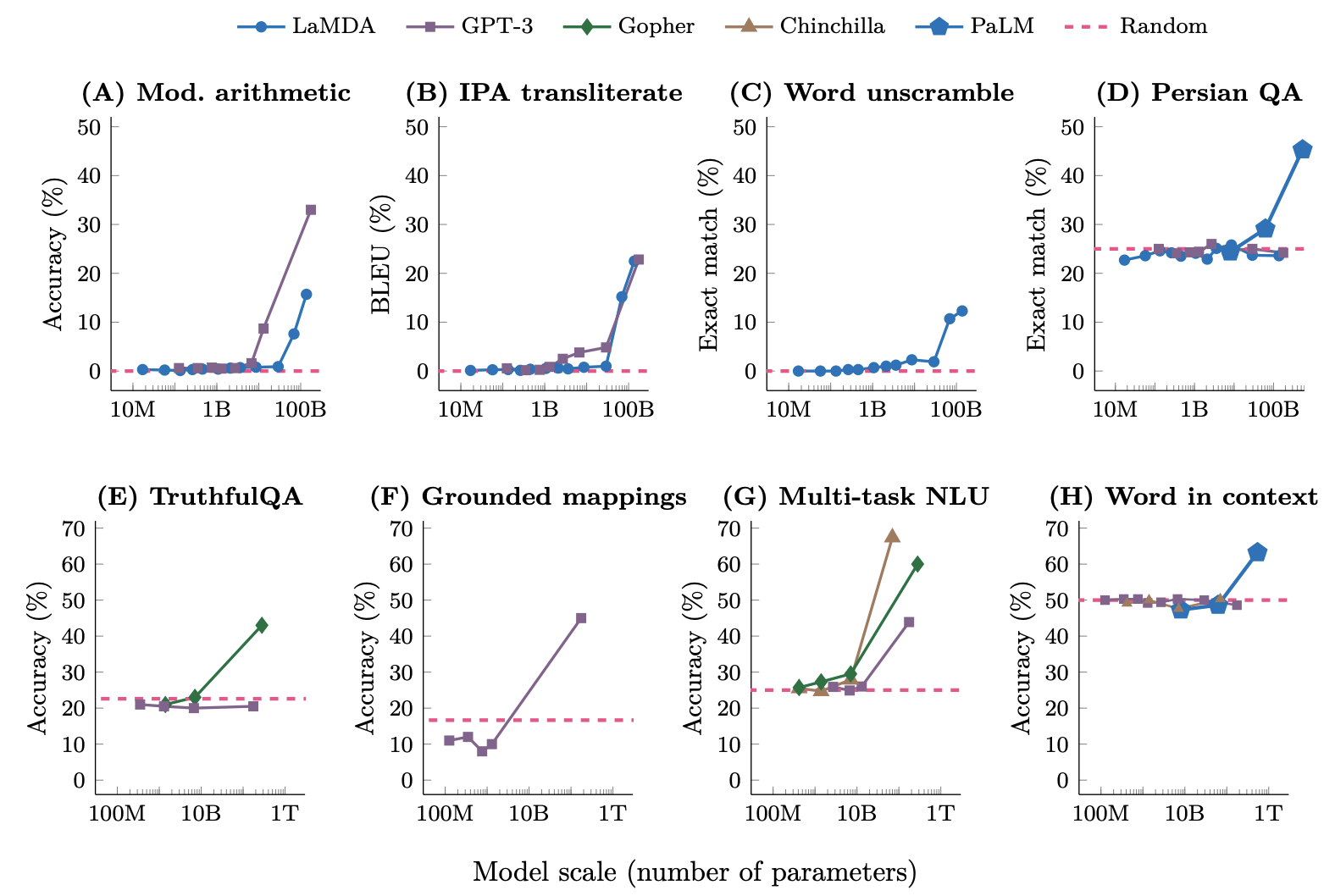
Si observamos nuestra naturaleza y nuestro universo, el nacimiento de un sistema complejo a menudo no crece linealmente, sino que después de que la complejidad se acumula hasta cierto umbral, de repente produce una nueva característica, un nuevo estado que nunca antes había sido único. aparición. Y en este gran modelo de lenguaje con cientos de miles de millones de parámetros parece haber surgido realmente algunas cosas nuevas basadas en la clasificación de datos.
Recientemente leí el libro "Fuera de control", que también mencionaba un concepto llamado emergencia, que puede entenderse como inteligencia de enjambre. Una abeja es muy estúpida, pero formando un grupo puede completar muchas decisiones que exceden la inteligencia individual. Por supuesto, no creo que una sola neurona de la IA sea estúpida, pero si este tipo de "conciencia" emerge repentinamente debido a una gran cantidad de iteraciones funcionales y aprendizaje, al igual que la evolución de los seres humanos, de alguna manera tendrán conciencia.. Así como todo en este mundo está hecho de átomos, pero si solo calculamos la interacción entre átomos, nunca podremos entender la química, ni podremos entender la vida. Por lo tanto, si vemos la IA sólo desde una perspectiva reduccionista, como círculos y líneas que sólo realizan divisiones binarias, nunca seremos capaces de comprender la lógica abstracta y las capacidades de razonamiento que surgen de los grandes modelos de lenguaje actuales. Los nuevos niveles vuelven a comprender este asunto.
3. salón chino
En 1980, el profesor de filosofía estadounidense John Searle propuso un famoso experimento mental, la Habitación China, en un artículo titulado "Cerebros mentales y programas" [10]. Coloque a una persona que solo entienda inglés en una habitación cerrada y solo pueda comunicarse con el mundo exterior pasando notas. Hay un manual de conversación en chino escrito en inglés en la habitación y puedes encontrar la respuesta correspondiente a cada frase en chino. De esta manera, la persona en la sala puede tener una conversación fluida en chino con el mundo exterior a través del manual. Parece que sabe chino, pero en realidad no entiende las preguntas que le hacen afuera ni las respuestas que devuelve.
Trató de demostrar a través de la Sala China que no importa cuán inteligente o humano fuera un programa, nunca podría hacer que una computadora tuviera pensamientos, comprensión y conciencia. ¿Es realmente? En este sitio web llamado Enciclopedia de Filosofía de Internet , se pueden ver varios argumentos en torno a la Sala China, y ninguno logra convencerse entre sí.

Estas discusiones se quedan en el nivel ideológico, porque es imposible realizar una sala china si sólo nos basamos en un manual impreso. Hay infinitas posibilidades para una conversación en chino. Incluso si es la misma frase, la respuesta será diferente en diferentes contextos. Esto significa que el manual necesita registrar una infinidad de situaciones, de lo contrario siempre habrá ocasiones en las que no podrá responderse. Pero lo extraño es que ChatGPT realmente se hace realidad. Como programa con sólo 330 GB, ChatGPT logra conversaciones en chino casi ilimitadas con una capacidad limitada, lo que significa que ha completado la compresión del chino sin pérdidas.
Imagina que hay un repetidor como este con sólo 100 MB de espacio y sólo puede reproducir diez canciones. Para escuchar canciones nuevas, debes eliminar las antiguas. Pero ahora hemos descubierto un repetidor mágico. Ahora sólo necesitas cantar la primera línea y este repetidor puede reproducir cualquier canción si continúas escribiendo la forma de onda. ¿Cómo debemos entender este repetidor? Sólo podemos suponer que aprendió a cantar.
4. Compresión: la compresión es sabiduría
Mirando hacia atrás en el proceso de aprendizaje de GPT, lo que hace es lograr la compresión de los 499 mil millones de tokens que ha aprendido a través de sus 175 mil millones de parámetros. En este punto, poco a poco me di cuenta de que era la compresión la que producía la inteligencia.
Jack Ray, miembro principal del equipo del modelo de lenguaje grande OpenAI, mencionó en la conferencia en video que la compresión siempre ha sido nuestro objetivo.

Lo siguiente es mi comprensión de la compresión y la inteligencia. Supongamos que quiero enviarles esta frase: "La compresión es inteligencia".
Podemos pensar en GPT como una herramienta de compresión. Yo la uso para comprimir esta oración. Después de recibirla, puedes usar GPT para descomprimirla. Primero debemos saber cuánta información contiene esta oración. En codificaciones como GBK, un carácter chino requiere dos bytes, es decir, 16 0/1 para expresarse, lo que puede representar 2 elevado a la 16ª potencia, que son 65536 posibilidades. Esta oración tiene un total de 5 caracteres, lo que requiere un total de 80 0 y 1, que son 80 bits. Pero, de hecho, la cantidad de información en esta oración puede ser inferior a 80 bits. En realidad, su verdadero contenido de información se puede calcular mediante una fórmula.
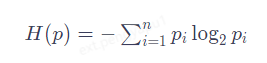
Ésta es la definición de entropía de la información dada por Shannon en 1948. Nos dice que la esencia de la información es una densidad de probabilidad. Aquí podemos entender simplemente P como la probabilidad de que aparezca cada palabra: cuanto menor sea la probabilidad de que aparezca, mayor será la cantidad de información en la oración completa. Si cada palabra en esta oración aparece aleatoriamente sin ninguna regla, entonces la probabilidad de P es 1/65536 y la cantidad de información calculada son los 80 bits originales. Un método de compresión tradicional común es encontrar palabras repetidas, pero es difícil comprimir oraciones que casi no son repetitivas. Más importante aún, el lenguaje normal es regular: la probabilidad de "presionar" seguida de "contraer" es mucho mayor que 1/65536, lo que deja espacio para una mayor compresión de la información. Lo que hace el modelo de lenguaje es encontrar las reglas del lenguaje durante el proceso de compresión y aumentar la probabilidad de que aparezca cada palabra. Por ejemplo, si solo enviamos "compresión" y dejamos que el modelo de lenguaje comience a continuar escribiendo, las siguientes palabras aparecerán en la tabla de probabilidad predicha. Solo necesitamos seleccionar las posiciones de "es decir" y "sabiduría", por ejemplo ( 402, 350). Estos dos números realizan la compresión de información, a partir de esta información el receptor la procesa a partir de la probabilidad del mismo modelo de lenguaje, selecciona la opción correspondiente al número y completa la descompresión. Dos números con un máximo de 5000. Cada número solo necesita 13 dígitos de 0/1 para ser representado. Incluyendo las 2 primeras palabras, solo es necesario enviar un total de 52 dígitos de 0/1. La información se comprime a los 52 originales. /80, que es alrededor del 65 %.
Por el contrario, si el efecto de predicción del modelo de lenguaje es deficiente, la lista de vocabulario del texto posterior seguirá siendo muy larga y no se podrá lograr un buen efecto de compresión. Por lo tanto, se puede encontrar que cuanto mejor sea el efecto de compresión, mejor será el efecto de predicción, lo que también refleja la comprensión del modelo de la información comprimida, y esta comprensión en sí misma es una especie de inteligencia. Para comprimir la tabla de multiplicar lo suficientemente pequeña, necesita entender matemáticas, y si las coordenadas planetarias se comprimen lo suficientemente pequeñas, puede entender la gravedad universal. Hoy en día, los modelos de lenguajes grandes se han convertido en la mejor solución para la compresión sin pérdidas, logrando una tasa de compresión de 14 veces. La mayor importancia de comprimir esta perspectiva es que, en comparación con la aparición misteriosa, nos brinda una solución clara y clara que puede cuantificar la inteligencia de las máquinas. Incluso cuando nos enfrentamos a un experimento mental como la Habitación China, tenemos formas de estudiar qué tan inteligente es la habitación.
Pero, ¿la inteligencia producida por compresión y la mente humana son realmente la misma cosa?
5. Escribe al final
Si quieres preguntar cuál es la mayor diferencia entre GPT y el habla humana en este momento, creo que la respuesta es que no puede mentir. Para el modelo del lenguaje, hablar y pensar son lo mismo, simplemente expresa su proceso de pensamiento y sus actividades mentales palabra por palabra. GPT nunca responde "No lo sé" porque no sabe que no lo sabe. Esta es la ilusión de la IA. Parece una tontería grave. Solo quiere continuar la conversación. Si es correcta o no. no es tan importante. El método para optimizar este problema también es muy simple. Solo necesita agregar una oración más cuando haga la pregunta "Pensemos paso a paso". Analice paso a paso y deje que GPT piense algunos pasos más como un humano. Para él, significa explicar el proceso de pensamiento. Paso a paso, esta habilidad también se llama Cadena de Pensamiento. El psicólogo Daniel Kahneman divide el pensamiento humano en dos tipos: el Sistema 1 es intuitivo, rápido e insensible, mientras que el Sistema 2 requiere el uso activo del conocimiento, la lógica y la capacidad intelectual para pensar. El primero es pensamiento rápido, tal como podemos decir ochenta y nueve setenta y dos, noventa y nueve y ochenta y uno, mientras que el segundo es pensamiento lento. Por ejemplo, si quieres responder cuánto es 72 por 81, debes enumerar el proceso y calcularlo paso a paso. La existencia de la cadena de pensamiento significa que el modelo de lenguaje grande finalmente tiene capacidades de razonamiento. Y para ello, nuestro cerebro ha evolucionado durante 600 millones de años. Podemos ver el funcionamiento más antiguo de las redes neuronales en medusas de 600 millones de años. La medusa tiene neuronas en la región exterior de sus antenas y en la región central de su boca. Cuando los tentáculos detectan la comida, las neuronas aquí se activarán y luego transmitirán la señal a las neuronas del centro, y los tentáculos enrollarán la comida y la llevarán a la boca. A lo largo de los años, nuestro cerebro ha ido creciendo capa a capa basándose en redes neuronales.
Lo primero que evolucionó fue el cerebro reptil, que se parece un poco al cerebro de una rana: controla los latidos del corazón, la presión arterial, la temperatura corporal y otras cosas que nos impiden morir. Luego está el cerebro paleontológico, que gobierna nuestros instintos animales. Las emociones de hambre, miedo, ira y el deseo de reproducirse provienen del control del sistema límbico. La delgada capa de unos dos milímetros en el lado más externo es una nueva estructura, la neocorteza, que sólo ha evolucionado en los últimos millones de años: aquellas partes de las que los humanos estamos orgullosos, como el lenguaje, la escritura, la visión, el oído y el movimiento. y Aquí ocurre el pensamiento, pero todavía sabemos muy poco sobre la neocorteza. Lo que se sabe actualmente es que aquí hay alrededor de 20 mil millones de neuronas, y hay alrededor de 10 millones de neuronas y 50 mil millones de conexiones entre neuronas en cada centímetro cuadrado de la neocorteza. Sólo se extrae una pequeña porción de tres centímetros cuadrados de neocórtex del exterior del cerebro humano, que ya es similar a la terriblemente grande cantidad de parámetros de ChatGPT. La razón por la que nuestros cerebros necesitan tantas neuronas es porque GPT solo necesita predecir la siguiente palabra, y nuestras neuronas siempre necesitan predecir lo que sucederá en el mundo el próximo segundo.
La investigación en neurociencia en las últimas décadas ha descubierto que, además de las señales sinápticas que activan las neuronas, también hay una gran cantidad de señales de picos dendríticos responsables de la predicción. Si una neurona en un estado predictivo recibe una señal lo suficientemente fuerte y prominente, puede activarse antes que una neurona en un estado no predictivo, inhibiendo así a otras neuronas. Esto significa que hay un modelo detallado del mundo almacenado en los 20 mil millones de neuronas de nuestra neocorteza, y nuestro cerebro nunca deja de hacer predicciones. Por lo tanto, cuando vemos algo, en realidad estamos viendo un modelo construido por nuestro cerebro de antemano y, si coincide con nuestra predicción, no sucederá nada. Una vez que la predicción sea incorrecta, se activará una gran cantidad de otras neuronas, lo que nos permitirá notar el error y actualizar el modelo a tiempo. Entonces cada error tiene su valor. Es a través de innumerables errores de predicción y cogniciones actualizadas que realmente entendemos el mundo.
Ahora puedo intentar responder la pregunta original: puede que GPT aún no tenga mente, pero ya tiene inteligencia. Es un modelo de lenguaje "grande", un clasificador con millones de círculos y líneas conectadas entre sí, un maestro de chat que realiza un solitario de texto prediciendo la siguiente palabra, un pez dorado genial que extrae significado continuamente y una herramienta para miles de personas. El repetidor con compresión sin pérdidas de miles de millones de palabras es un asistente que siempre responde positivamente a las personas, independientemente de si tienen razón o no. Puede ser otro punto de acceso tecnológico en rápida decadencia, o puede ser el último invento importante de la humanidad. Desde el Go, la pintura, la música hasta las matemáticas, el lenguaje y la codificación, cuando la IA comienza a superar gradualmente aquellas cosas que simbolizan la inteligencia y la creatividad humanas, el mayor impacto en la humanidad no es sólo el miedo a la sustitución de puestos de trabajo, sino también una duda más profunda sobre uno mismo. ¿Es la mente humana mucho más superficial de lo que pensamos? No lo creo.
Una máquina puede ser un repetidor maravillosamente preciso, pero un ser humano puede ser un repetidor propenso a errores. Los defectos y errores definen quiénes somos. Cada inconsistencia, cada incomprensión, cada silencio, pausa y mirada fija vale más que una respuesta irreflexiva.
referencias
[1] Vaswani, Ashish y otros. "Atención es todo lo que necesitas." Avances en sistemas de procesamiento de información neuronal 30 (2017).
[2] Radford, Alec, et al. "Los modelos de lenguaje son aprendices multitarea sin supervisión". Blog de OpenAI 1.8 (2019): 9.
[3] Brown, Tom y otros. "Los modelos de lenguaje aprenden con pocas posibilidades". Avances en sistemas de procesamiento de información neuronal 33 (2020): 1877-1901.
[4] Rosenblatt, F. "El perceptrón: un modelo probabilístico para el almacenamiento y organización de la información en el cerebro ". Psychoological Review, 65 (1958): 386–408.
[5] Radford, Alec, et al. "Mejorar la comprensión del lenguaje mediante preentrenamiento generativo". (2018).
[6] Bills, Steven, et al. "Los modelos de lenguaje pueden explicar las neuronas en los modelos de lenguaje". URL https://openaipublic . gota. centro. ventanas. net/neurona-explicador/papel/índice. html.(Fecha de acceso: 14.05.2023) (2023).
[7] Anderson, Philip W. "Más es diferente: simetría rota y la naturaleza de la estructura jerárquica de la ciencia". Ciencia 177.4047 (1972): 393-396.
[8] Gurnee, Wes, et al. "Encontrar neuronas en un pajar: estudios de casos con sondeo disperso". Preimpresión de arXiv arXiv:2305.01610 (2023).
[9] Wei, Jason y otros. "Habilidades emergentes de grandes modelos lingüísticos". Preimpresión de arXiv arXiv:2206.07682 (2022).
[10] Searle, John R. "Mentes, cerebros y programas". Ciencias del comportamiento y del cerebro 3.3 (1980): 417-424.
El autor del marco de código abierto NanUI pasó a vender acero y el proyecto fue suspendido. La primera lista gratuita en la App Store de Apple es el software pornográfico TypeScript. Acaba de hacerse popular, ¿por qué los grandes empiezan a abandonarlo? Lista de octubre de TIOBE: Java tiene la mayor caída, C# se acerca Java Rust 1.73.0 lanzado Un hombre fue alentado por su novia AI a asesinar a la Reina de Inglaterra y fue sentenciado a nueve años de prisión Qt 6.6 publicado oficialmente Reuters: RISC-V La tecnología se convierte en la clave de la guerra tecnológica entre China y Estados Unidos. Nuevo campo de batalla RISC-V: no controlado por ninguna empresa o país, Lenovo planea lanzar una PC con Android.Autor: JD Retail Li Xinjian
Fuente: Comunidad de desarrolladores de JD Cloud Indique la fuente al reimprimir