Estructura de red
(Imagen del artículo original: FCOS: detección de objetos de una etapa totalmente convolucional )
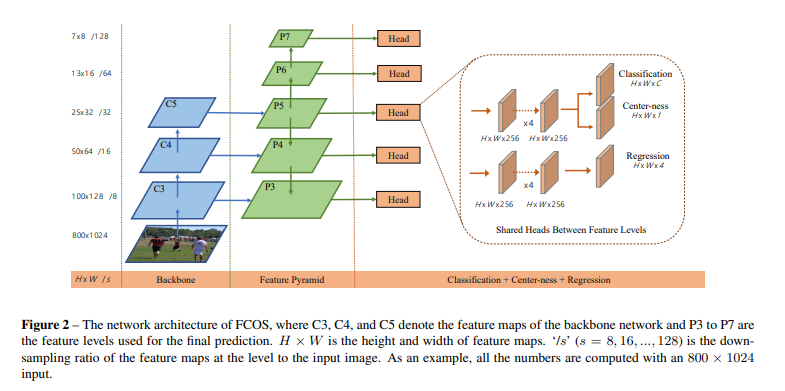
En ResNet50 Backbone, C 3, C 4, C 5 C3, C4, C5C3 , _C4 , _C 5 es el mapa de características de convolución;
en la estructura FPN,P 3, P 4, P 5, P 6, P 7 P3, P4, P5, P6, P7P3 , _P4 , _P 5 ,P6 , _P 7 es el mapa de características final utilizado para la predicción;
en la etapa de predicción,P 3, P 4, P 5, P 6, P 7 P3, P4, P5, P6, P7P3 , _P4 , _P 5 ,P6 , _P 7 comparte unoHead;
Headhay tres ramas, que se utilizan para la clasificación de predicción (80 categorías), el punto central de predicción de regresión a la altura superiort, la altura inferiorb, el ancho izquierdol, el ancho derechory el centro del marco real;
Puntos importantes
De ancla en ancla gratis
Anchoraspecto
- El tamaño del cuadro Anchor es fijo, lo que dificulta la detección de objetivos con cambios de forma y tamaño, y tiene poca escalabilidad.
- El tamaño del cuadro de anclaje tiene un mayor impacto en la precisión de la detección.
- La proporción de anclaje de muestras positivas y negativas es desigual, es decir, la proporción entre no objetivo y objetivo, y el entrenamiento es complicado.
Anchor Free方面

xmin = cx − l ∗ symin = cy − t ∗ sxmax = cx + r ∗ symax = cy + b ∗ s x_{min}=c_x-l*s\\y_{min}=c_y-t*s\\ x_{max}=c_x+r*s\\y_{max}=c_y+b*sXmin=Cx−yo∗symin=Cy−t∗sXmáx _=Cx+r∗symáx _=Cy+b∗s
dentro( xmin , ymin ) (x_{min},y_{min})( xmin,ymin) es la coordenada de la esquina superior izquierda del cuadro de predicción,( xmax , ymax ) (x_{max},y_{max})( xmáx _,ymáx _) es la coordenada de la esquina inferior derecha del cuadro de predicción;

C enterness = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) ∗ min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) Centro ness=\sqrt{\frac{min(l^* ,r^*)}{max(l^*,r^*)}*\frac{min(t^*,b^*)}{max(t^*,b^*)}}Centro _ _ _ _ _ _=máx ( l _∗ ,r∗ )mín ( l∗ ,r∗ )∗máx ( t _∗ ,b∗ )mín ( t∗ ,b∗ )
El centro se utiliza para medir la distancia entre el centro de predicción y el centro del cuadro real. Cuanto más cerca esté del punto central del cuadro real, más cerca estará el valor del valor 1.
Coincidencia de marcos muestrales positivos y negativos
En la serie YOLO, el valor IOU del ancla y el marco real se comparan con el umbral para determinar si debe usarse como muestra positiva. En FCOS se utiliza el método sin anclaje, es decir, no hay cuadro de anclaje.
Otra forma es: siempre que las coordenadas centrales predichas estén dentro del cuadro real, estos puntos centrales predichos se utilizan como muestras positivas y los demás se utilizan como muestras negativas.
Por supuesto, para lograr mejores resultados, el rango se reduce aún más. Si el punto central de predicción cae en (cx − r ∗ s , cy − r ∗ s , cx + r ∗ s , cy + r ∗ s ) (c_x -r* s,c_y-r*s,c_x+r*s,c_y+r*s)( cx−r∗s ,Cy−r∗s ,Cx+r∗s ,Cy+r∗s ) , se considera una muestra positiva, donderestá el hiperparámetro,sque es la relación de escala del mapa de características en relación con la imagen original.
Hay un caso especial: si el punto central previsto cae dentro del rango de dos cuadros reales, el punto central previsto se asignará al cuadro real con el área más pequeña de forma predeterminada.
función de pérdida
L ( { px , y } , { tx , y } , { sx , y } ) = 1 N pos ∑ x , y L cls ( px , y , cx , y ∗ ) + 1 N pos ∑ x , y 1 { cx, y ∗ > 0 } L reg ( tx , y , tx , y ∗ ) + 1 N pos ∑ x , y 1 { cx , y ∗ > 0 } L ctrness ( sx , y , sx , y ∗ ) L( \{p_{x,y}\},\{t_{x,y}\},\{s_{x,y}\})=\frac{1}{N_{pos}}\sum_{x, y}^{}L_{cls}(p_{x,y},c_{x,y}^*)\\+\frac{1}{N_{pos}}\sum_{x,y}^{} 1_{\{c_{x,y}^*>0\}L_{reg}(t_{x,y},t_{x,y}^*)}\\+\frac{1}{N_{pos }}\sum_{x,y}^{}1_{\{c_{x,y}^*>0\}L_{ctrness}(s_{x,y},s_{x,y}^*) }L ({ pagx , y} ,{ tx , y} ,{ sx , y})=nortepos _1x , y∑lc l s( pag.x , y,Cx , y∗)+nortepos _1x , y∑1{ cx , y∗> 0 } Lreg _( tx , y, tx , y∗)+nortepos _1x , y∑1{ cx , y∗> 0 } Lc tr n ess _( sx , y, sx , y∗)
La primera línea es la pérdida de clasificación,
la segunda línea es la pérdida del cuadro delimitador,
la tercera línea es la pérdida de "confianza";
N pos N_ {pos}nortepos _es el número de muestras positivas coincidentes;
px, y p_{x,y}pagx , yRepresenta la puntuación de cada categoría predicha en el mapa de características (x,y);
cx, y ∗ c_{x,y}^*Cx , y∗Representa la etiqueta de categoría real correspondiente en el mapa de características (x,y);
1 { cx , y ∗ > 0 } 1_{\{c_{x,y}^*>0\}}1{
cx , y∗> 0 }Indica que en el mapa de características (x, y), la muestra positiva es 1 y la muestra negativa es 0;
tx, y, tx, y ∗ t_{x,y},t_{x,y}^*tx , y,tx , y∗Representan respectivamente la posición prevista del cuadro delimitador y la información de posición del cuadro real en el mapa de características (x, y);
sx, y, sx, y ∗ s_{x,y},s_{x,y}^*sx , y,sx , y∗Representa el centro previsto y el verdadero centro en el mapa de características (x, y) respectivamente;