Article directory
论文: 《SVTR: Scene Text Recognition with a Single Visual Model》
github: https://github.com/PaddlePaddle/PaddleOCR
Solve the problem
Conventional text recognition models include two parts: a visual model for feature extraction and a sequence model for text transcription;
Problem:
Although this model has high accuracy, it is complex and inefficient;
Solution:
The author proposed SVTR, which only has a visual model. Eliminating the need for sequence models;
1. Decoupling image and text patches;
2. The hierarchical stage is executed through mixing, merging, and combining cycles; global and local mixing modules are used to perceive intra-character and inter-character morphology;
SVTR-L is used in English and Chinese recognition High speed and high accuracy;
algorithm
The overall structure of SVTR is shown in Figure 2, and
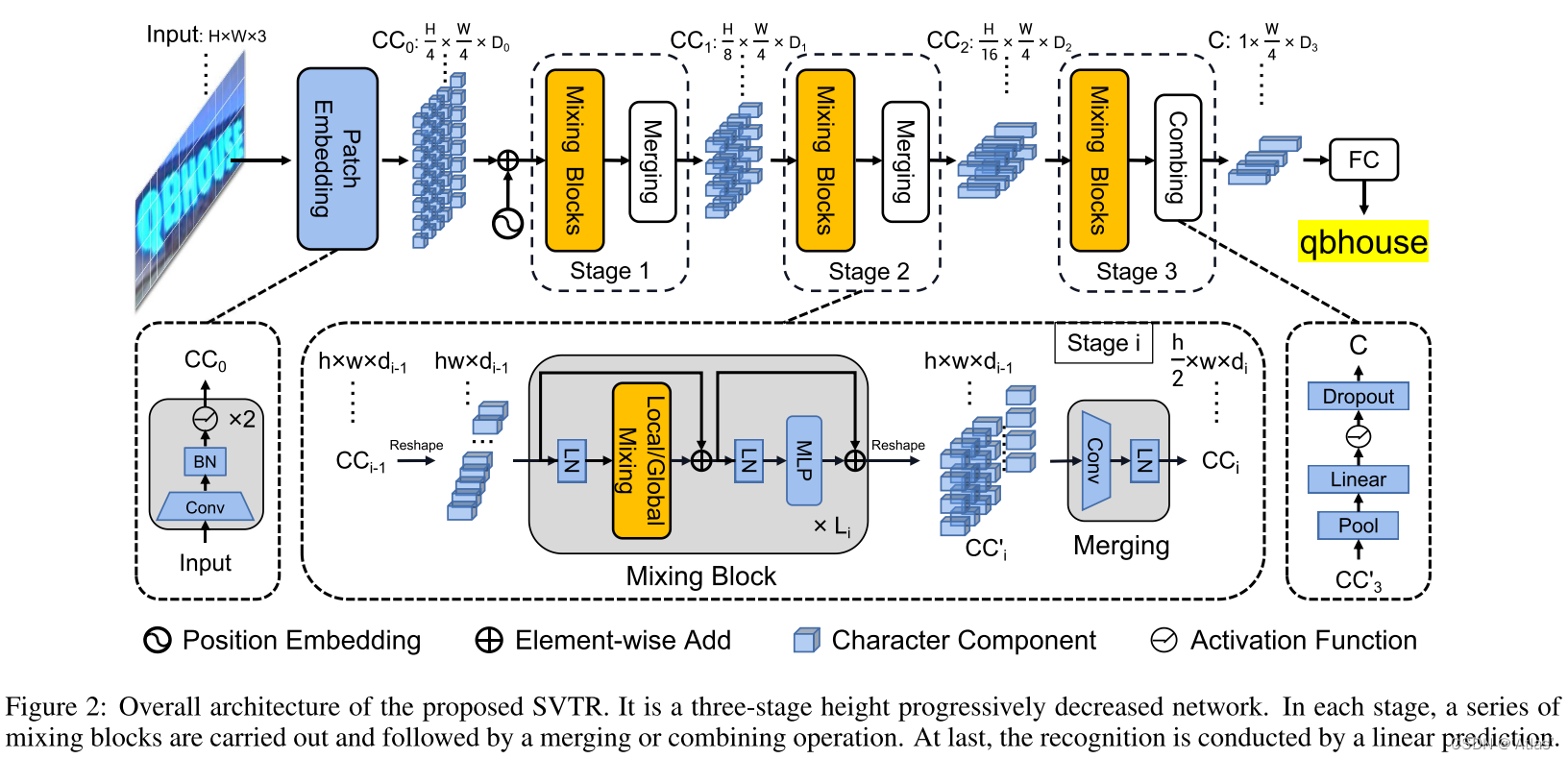
the process is as follows:
1. Input text image H × W × 3 H \times W \times 3H×W×3 , through the patch embedding module, converted toH 4 × W 4 \frac H4 \times \frac W44H×4Wdimensions are D 0 D_0D0patch;
2. Three stages are used to extract features. Each stage consists of a series of mixing blocks and merging or combining;
local and global mixing blocks are used to extract local features of strokes and dependencies between elements;
using this backnobe, different distances can be represented Character element features and dependencies at different scales, this feature size is 1 × W 4 × D 3 1 \times \frac W4 \times D_31×4W×D3, represented by the symbol C;
3. Finally, the character sequence is obtained through the FC layer;
progressive overlap patch embedding
The author did not use kernel=4, stride=4 convolution in vit; instead, he used two kernel=3, stride=2 convolution, as shown in Figure 3; although it increases some calculations, it is beneficial to feature fusion; ablation experiments are shown in 3.3

mixing block
The mixing block is shown in Figure 4.
Local features: encode character morphological features and correlations between different parts of characters;
global features: represent correlations between different characters, and between patches with or without text;

Merging
In order to reduce the amount of calculation and remove redundant representations, Merging is proposed; through kernel=3, stride=(2,1), conv will downsample the height by 2 times; because most texts are horizontal; at the same time, the channel dimension is increased to compensate for the information loss;
Combining & Prediction
Combining
first has a pooling height dimension of 1, followed by a fully connected layer, a nonlinear activation layer and a dropout layer;
The Prediction
linear classifier has N nodes and generates W 4 \frac W44WSequence, ideally, patches of the same character will be transcribed into repeated characters, and patches without text will be transcribed into spaces; N is set to 37 in English, and N is set to 6625 in Chinese; the maximum prediction length of the English model is 25, and the maximum prediction length of the Chinese model is
25 The length is 40.
Structural variants
There are several super parameters in SVTR, such as channel depth, number of heads, number of mixing blocks and the number of local mixing and global mixing in each stage, so there are SVTR-T (Tiny), SVTR-S (Small), SVTR-B (Base) ) and SVTR-L (Large), as shown in Table 1.

experiment
IC13: ICDAR 2013 data set, rule text.
IC15: ICDAR 2015 data set, irregular text.
patch embedding ablation experiment
As shown on the left side of Table 2, the progressive embedding mechanism exceeds the limit by 0.75% and 2.8%, and the effect is obvious in irregular text recognition;

Merging ablation experiment
As shown on the right side of Table 2, the progressively reduced resolution network not only increases the calculation amount but also improves the performance compared to the network that maintains a fixed resolution.
Permutation fusion module ablation experiment
As shown in Table 3,
1. Each strategy has a certain degree of improvement, which is attributed to comprehensive character feature perception;
2. The L6G6 method is the best, with IC13 performance improved by 1.9% and IC15 performance improved by 6.6%.
3. Switching their combinations will trick you, causing the global mixing block to not work, and it may repeatedly focus on local features;

SOTA comparison
Figure 5 shows the relationship between the accuracy of each model and the number of parameters and speed;

Table 4 shows the performance comparison of various methods.

SVTR has good performance in terms of comprehensive time consumption and accuracy;
in conclusion
The image text recognition visual model SVTR proposed in this article proposes multiple fine-grained character features to represent local strokes and the dependencies between characters at multiple scales; therefore, SVTR has a good effect.