目次
1. 10,000 以内で、5 または 6 で割り切れるが、両方を同時に割り切れない数字を見つけます。
2. リスト内のすべての偶数要素の合計を計算するメソッドを作成します。
5. ユーザーに「2008/08/08」などの日付形式を入力させ、入力した日付形式を「2008-August-8th」に変換します。
6. ユーザーが入力した文字列を受け取り、文字を昇順にソートし、逆順に「cabed」→「abcde」→「edcba」として出力します。
7. ユーザが入力した英語文を受け取り、「hello c Sharp」→「sharp c hello」と逆順に単語を出力します。
8. リクエストアドレス http://www.163.com?userName=admin&pwd=123456 からユーザー名とドメイン名を抽出します。
9. 文字列が別の文字列の部分文字列であるかどうかを判断するにはどうすればよいですか? Find()、index() の 2 層ループは完了していますか? ?
12. 文字列に数字と文字の両方が含まれているかどうかを判断する方法
13. 文字列内の文字のソート(大文字と小文字は関係なくアルファベット順のみ)
15. 頭の中にある本のタイトルを入力し、その文字列の長さを出力します。
16. ユーザーに文を入力して、「彼」のすべての場所を見つけてもらいます。
17. ユーザーに文を入力して、「へへ」のすべての場所を見つけてもらいます。
1. 10,000 以内で、5 または 6 で割り切れるが、両方を同時に割り切れない数字を見つけます。
def func():
for i in range(1, 10000):
if i % 5 == 0 or i % 6 == 0:
if i % 5 == 0 and i % 6 == 0:
continue
print(i)
func()
2. リスト内のすべての偶数要素の合計を計算するメソッドを作成します。
def sum_even(ls):
sum_even = 0
for i in range(0, len(ls), 2):
sum_even += ls[i]
return sum_even
if __name__ == '__main__':
ls = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(f'{ls}中所有偶数下标元素的和为:{sum_even(ls)}')

3. 文字列配列内の各文字列からスペースを削除します。
def cls_space(strings):
for i in range(len(strings)):
strings[i] = strings[i].replace(' ', '')
return strings
if __name__ == '__main__':
strings = input('请输入多个字符串:').split(',')
print(f'您输入的字符串数组:{strings}')
print(f'清除空格后的字符串数组:{cls_space(strings)}')

4. 句読点に基づいて文字列を行に分割します。
def enter(fh, string):
tmp = string.split(f'{fh}')
for i in range(len(tmp)):
print(tmp[i])
if __name__ == '__main__':
string = input('请输入一段带有标点符号的字符串:')
fh = input('请输入换行标志符号:')
enter(fh, string)
5. ユーザーに「2008/08/08」などの日付形式を入力させ、入力した日付形式を「2008-August-8th」に変換します。
def swich_date(one_date):
tmp = one_date.split('/')
print(f'{tmp[0]}年-{int(tmp[1])}月-{int(tmp[2])}日')
if __name__ == '__main__':
one_date = input('请输入“年/月/日”格式的日期:')
swich_date(one_date)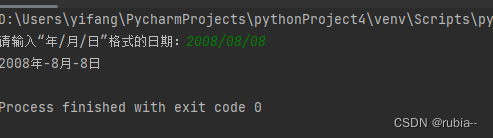
6. ユーザーが入力した文字列を受け取り、文字を昇順にソートし、逆順に「cabed」→「abcde」→「edcba」として出力します。
def sort_reverse(str):
tmp = list(str)
tmp.sort(reverse=True)
str_1 = ''.join(tmp)
return str_1
if __name__ == '__main__':
str = input('请输入一个英文字符串:')
print(f'您输入的字符串为:{str}')
print(f'逆序排序后的字符串为:{sort_reverse(str)}')
7. ユーザが入力した英語文を受け取り、「hello c Sharp」→「sharp c hello」と逆順に単語を出力します。
def sentence_reverse(sentence):
tmp = sentence.split(' ')
tmp.reverse()
senrence = ' '.join(tmp)
return senrence
if __name__ == '__main__':
sentence = input('请输入一句英文:')
print(f'逆序输出:{sentence_reverse(sentence)}')
8. リクエストアドレス http://www.163.com?userName=admin&pwd=123456 からユーザー名とドメイン名を抽出します。
url = 'http://www.163.com?userName=admin&pwd=123456'
ls = url.split('?')
domain = ls[0].split('/')[2]
ls_1 = ls[1].split('&')
username = ls_1[0].split('=')[1]
print(f'域名:{domain}')
print(f'域名:{username}')
9. 文字列が別の文字列の部分文字列であるかどうかを判断するにはどうすればよいですか? Find()、index() の 2 層ループは完了していますか? ?
str_a = input('请输入字符串a:')
str_b = input('请输入字符串b:')
# 使用find()方法:
flag = str_a.find(str_b)
if flag == -1:
print('字符串b不是字符串a的子串')
else:
print('字符串b是字符串a的子串')
# 使用index()方法:
try:
flag = str_a.index(str_b)
except ValueError:
print('字符串b不是字符串a的子串')
else:
print('字符串b是字符串a的子串')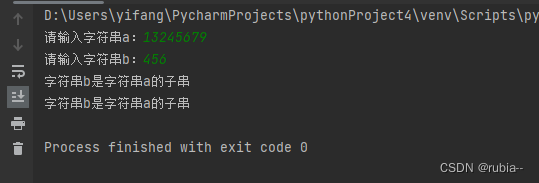
10. 数字を含まない文字列をランダムに生成する方法
import random
def random_letter():
ls = []
str_max = int(input('请输入随机字符串长度的最大值:'))
str_len = random.randint(1, str_max)
for i in range(str_len):
ls.append(chr(random.randint(ord('a'), ord('z'))))
strs = ''.join(ls)
return strs
if __name__ == '__main__':
print(random_letter())
11. 数字と文字を含む文字列をランダムに生成する方法
import random
def random_letter():
letter = chr(random.randint(ord('a'), ord('z')))
return letter
def random_num09():
num = random.randint(0, 9)
return num
if __name__ == '__main__':
ls = []
str_max = int(input('请输入随机字符串长度的最大值:'))
str_len = random.randint(1, str_max)
for i in range(str_len):
flag = random.randint(0, 1)
if flag == 0:
ls.append(str(random_num09()))
else:
ls.append(random_letter())
strs = ''.join(ls)
print(strs)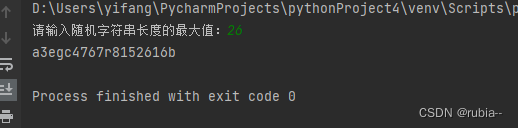
12. 文字列に数字と文字の両方が含まれているかどうかを判断する方法
def num_alpha(str):
flag_num = 0
flag_alpha = 0
for i in str:
if i.isdigit():
flag_num = 1
break
for i in str:
if i.isalpha():
flag_alpha = 1
break
if flag_num == 1 and flag_alpha == 1:
return True
else:
return False
if __name__ == '__main__':
str = input('请输入一个字符串:')
if num_alpha(str):
print('该字符串中既有数字又有字母')
else:
print('该字符串不满足既有数字又有字母')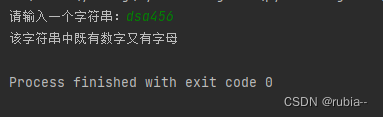
13. 文字列内の文字のソート(大文字と小文字は関係なくアルファベット順のみ)
def alp_sort(str):
ls = list(str)
ls_upper = []
for i in range(len(str)):
if ls[i].isalpha:
if ls[i].isupper():
ls_upper.append(ls[i])
ls[i] = ls[i].lower()
ls.sort()
for i in ls_upper:
flag = ls.index(i.lower())
ls[flag] = ls[flag].upper()
str = ''.join(ls)
return str
if __name__ == '__main__':
str = input('请输入一段字符串:')
print(f'排序后的字符串:{alp_sort(str)}')
14. 文字が回文文字列であるかどうかを判断する
def isHuiWen(str):
ls_1 = list(str)
ls_2 = list(str)
ls_2.reverse()
if ls_1 == ls_2:
print('该函数是回文字符串')
else:
print('该函数不是回文字符串')
if __name__ == '__main__':
str = input('请输入一个字符串:')
isHuiWen(str)
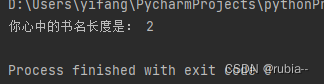
15. 頭の中にある本のタイトルを入力し、その文字列の長さを出力します。
def length(book_name):
l = len(book_name)
print("你心中的书名长度是:", l)
length("活着")
16. ユーザーに文を入力して、「彼」のすべての場所を見つけてもらいます。
def find_all(string, sub):
start = 0
pos = []
while True:
start = string.find(sub, start)
if start == -1:
return pos
pos.append(start)
start += len(sub)
print(find_all('今天真的呵呵呵呵呵呵呵呵呵呵', '呵'))

17. ユーザーに文を入力して、「へへ」のすべての場所を見つけてもらいます。
def find_all(string, sub):
start = 0
pos = []
while True:
start = string.find(sub, start)
if start == -1:
return pos
pos.append(start)
start += len(sub)
print(find_all('今天真的呵呵欧呵呵欧呵呵欧呵呵欧呵呵', '呵呵'))

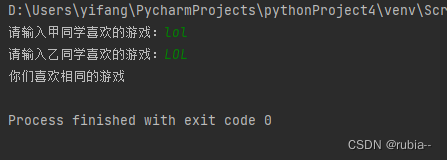
18. 2 人の生徒が好きなゲーム名を入力し、それらが一致しているかどうかを判断します。同じであれば、2 人の好きなゲームが同じであることを出力します。同じでない場合は、2 人の好きなゲームが異なることを出力します。 「lol」と入力すると、「LOL」は同じゲームを表します
a = input('请输入甲同学喜欢的游戏:')
b = input('请输入乙同学喜欢的游戏:')
if a.lower() == b.lower():
print('你们喜欢相同的游戏')
else:
print('你们喜欢不同的游戏')
19. ユーザーに文を入力して、その文に悪があるかどうかを判断させます。悪がある場合は、この形式に置き換えて出力します。たとえば、「老牛は非常に邪悪です」、出力後は「ラオ」になります。丹生さんはとても**ですよ」
a = input("请输入一句话:")
for i in range(0, len(a)-1):
if a[i] == "邪":
if a[i+1] == '恶':
a = a.replace("邪", "*")
a = a.replace("恶", "*")
break
print(a)
